基于音素级分析抑制音素影响的合成语音检测方法与流程
本发明涉及模式识别,语音信号处理领域,具体是一种使用f-ratio对真实语音和合成语音的音素特征进行分析的方法,用于更高效地鉴别语音的真假。
背景技术:
利用人的个性化生物特征进行个人身份鉴别如今已经被广泛地应用于生产和生活当中。个性化生物特征是指包括指纹、虹膜以及声纹在内的在一定时间内具有持续的唯一性的,且能够反映出个体与个体之间差异的生理特性。其中声纹识别(voiceprintrecognition)技术也被称为说话人识别(speakerrecognition)技术,它可以根据一段音频来判断音频中说话人的身份信息。声纹识别技术相较于指纹识别、人脸识别和虹膜识别等技术具有一定的优势。例如,实现成本低、操作简单等。声纹识别既不需要像指纹识别那样要用到专用的设备,也不需要像人脸识别那样要进行特定的动作,只需要简单地说一句话就可以进行身份鉴别。因此,声纹识别技术具有较高的用户认可度,市场占有率已经达到了15.8%,并且不断呈现出上升的趋势。
但是最近随着语音合成(speechsynthetic)技术和语音转换(voiceconversion)技术的日益成熟,很多不法分子可以利用这些技术轻易地模仿出目标说话人声学特征,进而攻破声纹识别系统的防御,盗取他人的信息和财产等。为了保护声纹识别系统不受到合成语音或转换语音的攻击,对于这些欺诈攻击的检测(spoofingattackdetection)技术的需求变得日益强烈起来。这项技术的研究对于声纹识别系统的推广和使用起着至关重要的作用。
目前,语音方面的国际顶级会议interspeech每隔两年会举办针对自动说话人识别欺诈攻击与防御对策的挑战赛(automaticspeakerverificationspoofingandcountermeasureschallenge)。分析各支参赛队伍的策略,可以发现国内外对于这一课题的研究主要分为两个方面,分别是基于前端语音特征分析方面的研究以及基于后端分类器方面的研究。在特征方面,目前比较常用的特征包括经过常数q变换得到的常数q倒谱系数(constantqcepstralcoefficients,cqcc)和使用线性滤波器处理得到的线性滤波器倒谱系数(linear-frequencycepstralcoefficient,lfcc)等;在分类器方面,除了高斯混合模型(gaussianmixturemodel,gmm)、线性判别分析(lineardiscriminantanalysis,lda)以及支持向量机(supportvectormachine,svm)等传统的机器学习中经典的分类器之外,一些目前比较热门的深度神经网络模型也被应用于这项任务当中,比如卷积神经网络(convolutionalneuralnetworks,cnn)以及循环神经网络(recurrentneuralnetwork,rnn)等。
gajansuthokumar等人在2019年的一篇研究中表明,语音发音过程中的不同音素在进行欺诈攻击鉴别时,具有不同的辨别能力,其中轻音音素的鉴别能力普遍高于浊音音素。
技术实现要素:
为克服现有技术的不足,本发明旨在研究真实语音和欺诈语音在不同音素上的区别,提高自动说话人系统欺诈攻击检测的效果。为此,本发明采取的技术方案是,基于音素级分析抑制音素影响的合成语音检测方法,使用f-ratio对不同真实语音和欺诈语音中的不同音素的各个频段进行分析,f-ratio称为方差比检验,是通过比较类内和类间的方差,来发现各分类中的差异分布情况,通过所述分析找出更有利于鉴别真实语音和欺诈语音的频率范围,增加该频段上的滤波器密度,得到新的特征,并用该特征分别训练真实语音和欺诈语音的高斯混合模型gmm,将待识别的音频提取特征后分别输入两个模型,最后将两个模型的结果用最大似然比打分,得到最终的识别结果。
具体步骤如下:
步骤一,数据准备:
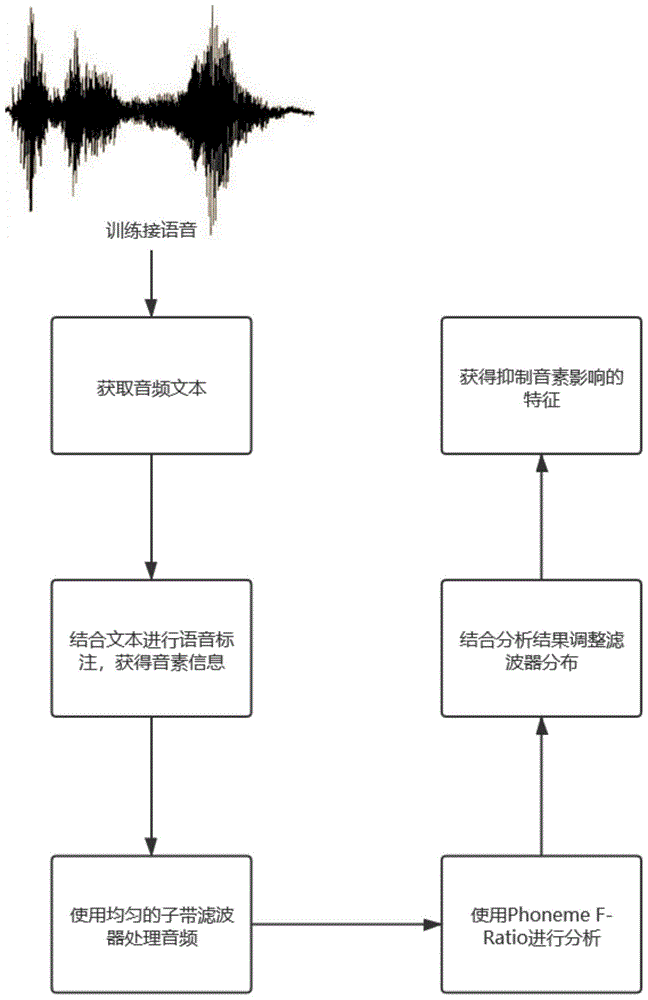
首先,对语音数据进行标注,即获取音频中的每个音素以及它们的起始时间信息,然后分别对真实语音和欺诈语音中的各个音素进行研究,使用均匀的子带滤波器来处理语音音频中的每一帧,进而获得不同音素的每一帧上各个频带的数据;
步骤二,数据分析:
对上一步获取到的数据使用音素级的f-ratio方法进行分析,某个频段上的f-ratio值用来表征该频段在鉴别真实语音和欺诈语音时的能力,f-ratio的值越大,表示这一频道上携带的可供鉴别的信息更多,鉴别能力越强,之后根据所有频道上的f-ratio值,对结果做归一化,然后以各个音素的帧数为权值,对音素的每个频带上归一化的数据做加权平均,最终得到抑制了音素影响后各个频带上的鉴别能力,结果越大表示鉴别能力越强;
步骤三,提取特征:
根据第二步的实验结果,在鉴别能力较强的区域,增加滤波器的个数,起到增加滤波器在这些区域中的密度的作用,再使用这些滤波器对经过分帧、加窗和短时傅里叶变换后的语音信号进行滤波,最后经过离散余弦变换dct得到抑制音素影响的新特征;
步骤四,模型训练
将训练集中的音频提取特征作为输入,分别训练真实语音和欺诈语音的高斯混合模型gmm;
步骤五,打分确认
将待测语音提取到的特征分别输入进真实语音和欺诈语音的模型中进行打分,再用最大似然比分类法得出最终的结果。
步骤二,数据分析具体步骤如下:
使用基于音素的f-ratio分析方法pf(phonemef-ratio)对不同音素中的各个频段进行分析,pf的分析思路为计算某一音素k在第l个滤波器上不同方法之间的方差与同一方法内部的方差之比,值越高就说明不同方法在这一区域的差异性越大,pf的具体计算公式如下:
其中,t表示方法种类,ntk表示第t个类型中第k个音素的帧数;
之后对得到的pf值进行归一化处理,即可得到第l个滤波器频带上音素的f-ratio贡献率pfc(phonemef-ratiocontribution),其计算公式如下:
其中l为均匀的子带滤波器个数;计算得到的pfc可以反映出不同音素中,用于鉴别欺诈语音的信息的频率分布,接下来对各音素的pfc根据其帧数进行加权平均,得到整体f-ratio值gf(generalf-ratio),其计算公式如下:
其中p是所有音素的总数,n为所有音素的总帧数,n的计算公式如下:
对计算出的gf再进行归一化处理,可以得到抑制音素影响的欺诈攻击信息分布pessdid(phonemeeffectsuppressedspoofdetectioninformationdistribution),其计算公式如下:
这里滤波器l的pessdid的值越高,说明该滤波器的频段上的可以用于鉴别欺诈攻击的信息越多。
步骤三,提取特征步骤中:
除了滤波器分布的区别外,其他特征提取的过程包括:使用滤波器前的步骤包括预加重、分帧和加窗,再经过短时傅里叶变化,得到每一帧的频谱特征,之后用滤波器对频谱特征进行处理,处理后再经过dct变换,得到最终的特征。
本发明的特点及有益效果是:
本发明使用f-ratio的方法,对声纹识别系统面对的欺诈攻击语音与真实语音在不同音素上的差异进行了分析,找到了有助于鉴别欺诈语音的信息在频率上的分布。根据分析结果,通过改进滤波器设计出了一个可以抑制不同音素在识别任务中的影响的新特征。在asvspoof2019的测试集上进行初步实验,得到的等错误率(equalerrorrate,eer)为4.16%,相较于常用的lfcc特征(基线系统eer为8.09%)在错误率上有了48.58%的提升。
附图说明:
图1为基于f-ratio分析的抑制音素影响的欺诈攻击检测特征提取流程图。
图2为基于f-ratio分析得到的抑制音素影响的滤波器分布示意图。
具体实施方式
本发明的目的在于研究真实语音和欺诈语音在不同音素上的区别,使用f-ratio的方法对每个因素的不同频段进行对比分析,找出每个因素更有利于鉴别欺诈语音的频段,进而加大特征提取是在这些频段上的滤波器密度,最后得到一个更为鲁棒的个性化特征,提高自动说话人系统欺诈攻击检测的效果。
实现本发明目的的技术解决方案为:
基于f-ratio分析的抑制音素影响的合成语音检测方法。使用f-ratio对不同真实语音和欺诈语音中的不同音素的各个频段进行分析,找出更有利于鉴别真实语音和欺诈语音的频率范围,增加该频段上的滤波器密度,得到新的特征,并用该特征分别训练真实语音和欺诈语音的高斯混合模型(gmm),将待识别的音频提取特征后分别输入两个模型,最后将两个模型的结果用最大似然比打分,得到最终的识别结果。
系统的实现包括以下步骤:
步骤一,数据准备:
首先,对语音数据进行标注,即获取音频中的每个音素以及它们的起始时间等信息。然后分别对真实语音和欺诈语音中的各个音素进行研究。使用均匀的子带滤波器来处理语音音频中的每一帧,进而获得不同音素的每一帧上各个频带的数据。
步骤二,数据分析:
对上一步获取到的数据使用f-ratio的方法进行分析,某个频段上的f-ratio值可以用来表征该频段在鉴别真实语音和欺诈语音时的能力,f-ratio的值越大,表示这一频道上携带的可供鉴别的信息更多,鉴别能力越强。之后根据所有频道上的f-ratio值,对结果做归一化,然后以各个音素的帧数为权值,对音素的每个频带上归一化的数据做加权平均,最终得到抑制了音素影响后各个频带上的鉴别能力,结果越大表示鉴别能力越强。
步骤三,提取特征:
根据第二步的实验结果,在鉴别能力较强的区域,适当增加滤波器的个数,起到增加滤波器在这些区域中的密度的作用。再使用这些滤波器对经过分帧、加窗和短时傅里叶变换后的语音信号进行滤波,最后经过离散余弦变换(dct)得到抑制音素影响的新特征。
步骤四,模型训练
将训练集中的音频提取特征作为输入,分别训练真实语音和欺诈语音的gmm模型。
步骤五,打分确认
将待测语音提取到的特征分别输入进真实语音和欺诈语音的模型中进行打分,再用最大似然比分类法得出最终的结果。
下面结合附图来描述本发明实施的基于f-ratio分析的抑制音素影响的合成语音检测方法,主要包含以下步骤:
步骤一,数据准备:
为了验证本发明的效果,在asvspoof2019比赛的数据库上进行欺诈攻击检测实验。asvspoof2019数据库,包括训练集,开发集和测试集三部分,其中训练集和开发集中包括了7种语音合成和语音转换的欺诈攻击算法,而测试集中包括了12种与训练集和开发集中不同的欺诈攻算法。数据库中所有音频的采样率均为16khz。由于赛方并未提供数据库中音频对应的文本信息,这里我们使用了一套语音识别系统,对训练集中的25380个音频中的说话内容进行了识别。之后通过语音标注的工具,对这些音频中的音素信息进行了提取。然后使用均匀的子带滤波器来处理语音音频中的每一帧,进而获得不同音素的每一帧上各个频带的数据。
步骤二,数据分析:
这里使用基于音素级f-ratio(phonemef-ratio,pf)的方法对不同音素中的各个频段进行分析,pf的分析思路为计算某一音素k在第l个滤波器上不同方法之间的方差与同一方法内部的方差之比,值越高就说明不同方法在这一区域的差异性越大,pf的具体计算公式如下:
其中,t表示方法种类,这里只分成了真实语音和欺诈语音两种,所以t为2;ntk表示第t个类型中第k个音素的帧数;
之后对得到的pf值进行归一化处理,即可得到第l个滤波器频带上音素的f-ratio贡献率(phonemef-ratiocontribution,pfc),其计算公式如下:
其中l为均匀的子带滤波器个数;计算得到的pfc可以反映出不同音素中,用于鉴别欺诈语音的信息的频率分布。接下来为了抑制不同音素的差异在说话人识别过程中影响,对各音素的pfc根据其帧数进行加权平均,得到整体f-ratio值(generalf-ratio,gf),其计算公式如下:
其中p是所有音素的总数,n为所有音素的总帧数,n的计算公式如下:
对计算出的gf再进行归一化处理,可以得到抑制音素影响的欺诈攻击信息分布(phonemeeffectsuppressedspoofdetectioninformationdistribution,pessdid),其计算公式如下:
这里滤波器l的pessdid的值越高,说明该滤波器的频段上的可以用于鉴别欺诈攻击的信息越多。
步骤三,提取特征:
根据上一步得到的分布情况,我们进行本发明提出的新特征的滤波器设计,其中在信息较多的频段适当增加滤波器的个数,在信息较少的频段,适当减少滤波器的个数,调整后的滤波器可见附图-2。除了滤波器分布的区别外,其他特征提取的过程与传统方法相同,使用滤波器前的步骤包括预加重、分帧和加窗,再经过短时傅里叶变化,得到每一帧的频谱特征,之后用滤波器对频谱特征进行处理,处理后再经过dct变换等,可以得到最终的特征。
步骤四,模型训练
训练模型时,对于训练集中的语音,不再需要进行语音标注,直接用新的特征提取方法对原始音频进行处理即可。根据训练集中音频的真假标签,将得到的特征分别用于训练真实语音的gmm模型和欺诈语音的gmm模型。
步骤五,打分确认
将待测音频进行分帧等处理后提取出新的特征后,将特征分别输入到真实语音和欺诈语音的gmm模型中进行打分。具体方法是,将一个音频的每一帧逐个输入给一个gmm模型,得到一个相似度的打分,然后将所有帧的结果取平均,作为该音频在该gmm模型中的打分结果。最后用最大似然比的方法,计算待测音频在两个模型中的得分,然后得出最终的结果。
实验的结果采用等错误率(eer)进行评估,等错误率表示错误接收率(far)与错误拒绝率(frr)相等时的错误率。
以上所述仅为本发明的较佳实施例,并不用以限制本发明,凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!