一种带有人声的音乐的风格迁移方法与流程
本发明属于数据处理技术领域,特别涉及一种带有人声的音乐的风格迁移方法。
背景技术:
过去三年来,神经风格迁移已经持续成长为了一个蓬勃发展的研究领域。这一研究领域内越来越多的活动受到了科学挑战和工业需求的推动。风格迁移在包括社交、辅助用户创作和娱乐应用都有着广阔的应用前景。
音乐风格迁移是风格迁移算法的另一个领域的尝试。由于音乐是基于时间的片段并且音乐的成分较多,故提取特征较为复杂,特征之间的连接较为复杂紧密。目前学术界将图像大多数算法都是直接将应用在图像风格迁移的算法直接应用在音乐风格迁移之上并且大部分音乐都是乐器演奏的纯乐曲。但是这些算法算法在带有人声的通俗音乐取得的效果却不尽人意。当前大量的歌曲被翻唱为各种不同风格的版本,但是歌手的翻唱数量远远不能达到人们对于不同风格翻唱歌曲的需求,故研究一个适用于带有人声的流行音乐风格迁移的模型对计算机音乐领域具有重要意义。
技术实现要素:
为了克服以上缺陷。本发明提供一种带有人声的音乐的风格迁移方法,基于cyclegan和wavenet解码器,解决目前音乐的风格转换领域。大部分的图像风格转换算法在音乐的风格转换上表现糟糕。在带有人声的音乐的风格转换,算法表现的更加糟糕的问题。为达此目的:
本发明提供一种带有人声的音乐的风格迁移方法,模型基于cyclegan和wavenet解码器。模型处理流程如下,其特征在于;
(1),获取原始音乐文件通过时频分析来提取音频的cqt特征和梅尔频谱特征;
(2),将两层谱图进行合并将提取的cqt特征和梅尔频谱特征合并为两层输入进cyclegan模型;
提取的cqt特征和梅尔频谱特征合并的合并原则如下:
(21)假定对同一个音频进行时频处理,并且采用相同的窗口长度、窗函数以及步长。得到的cqt特征矩阵大小为n×m,得到的梅尔频谱特征矩阵大小为t×m;
(22)如果n≥t,那么以cqt特征矩阵作为第一层,梅尔频谱特征矩阵作为第二层。对于前t行来说,cqt特征矩阵和梅尔频谱特征矩阵一一对齐。对于梅尔频谱特征矩阵缺少的部分进行零填充;
(23)如果n<t,那么以梅尔频谱特征矩阵作为第一层,cqt特征矩阵作为第二层,对于前n行来说,cqt特征矩阵和梅尔频谱特征矩阵一一对齐。对于cqt特征矩阵缺少的部分进行零填充;
(24)最终得到输入矩阵的大小为max(t,n)×m;
(3),通过cyclegan对补全后的谱图进行风格迁移,将cyclegan产生出转换后的梅尔频谱特征和cqt特征;
风格迁移的cyclegan的网络结构是将反卷积用最近邻差值代替和正则卷积替代
风格迁移的cyclegan采用的损失函数如下:
(31)假设我们要将风格为a的音乐迁移到风格为b的音乐,设这两个音乐的所在域为域x和域y,g为生成器,f为判别器,pdata(x)为x域的音乐片段,且x从pdata(x)中采样,pdata(y)为y域的音乐片段,且y从pdata(y)中采样首先添加x→y的对抗性损失函数如下:
(32)添加y→x的对抗性损失函数如下:
(33)添加循环一致性损失:
(34)为了保留谱图的颜色成分,添加identityloss:
(35)故总的损失函数如下:
l(g,f,dx,dy)=lgan(g,dy,x,y)+lgan(f,dx,y,x)+λ1lcyc(g,f)+λ2lidentity(g,f)
(4),通过wavenet解码器对cyclegan迁移后的谱图进行解码,从而生成音频,将两层特征输入进事先训练好的wavenet解码器产生音频;
wavenet解码器的输入谱图特征进行全局归一化处理:
对于所有的输入谱图的数据,采用如下对数变换进行全局归一化
ln(1+x/8);
x定义为输入的谱图数据的矩阵;
(5),通过评价指标来对生成的音频进行评价,先对风格转换音乐的评估和对风格转换质量进行评估,最后对风格迁移算法进行综合评估;
对于步骤(5)进行风格转换音乐的评估,具体流程如下;
首先给定训练集,其中包括,音乐,对音乐质量的打分,然后输入神经网络进行训练,通过训练好的音乐质量判定器对风格转换后的音乐进行打分;
对越步骤(5)进行风格转换质量进行评估,具体流程如下;
给定训练集,其中包括各种风格的音乐和各个音乐的标签,训练音乐风格分类器,
对转换后的音乐用上述音乐风格分类器进行训练,分别统计音乐风格转换成功和失败的次数
对风格迁移算法进行综合评估,具体流程如下;
定义aqr为平均音乐质量,tr为平均风格迁移率,forward表示cyclegan的前向转换,backward表示cyclegan的后向转换,其中λ为cyclegan的前向转换所占比重,通过上述两个分类器和下面的公式分别计算平均音乐质量和风格迁移成功率;
tce=λ*aqrforward*trforward+(1-λ)*aqrbackward*trbackward
计算的得到的tce即为风格迁移算法的综合评判指标。
作为本发明进一步改进,步骤(1)中音乐文件为wav,mp3格式的音乐文件。
作为本发明进一步改进,步骤(3)进行风格迁移的cyclegan损失函数中循环一致性损失和identityloss
的权重λ1和λ2的设置,采用如下策略:
(211)对于λ1的设置,采用恒定值;
(212)对于λ2的设置,采用我们提出的非线性衰减,假设算法一共要迭代t步,那么在第n步,λ2为:
本发明提供一种带有人声的音乐的风格迁移方法,具有如下特点;
1)本申请通过风格转化算法对带有人声的音乐进行转换,具有较好的的转换能力,可以达到较好转换效果;
2)本发明能够满足人们对于不同风格翻唱歌曲的需求;
3)本发明提出的identityloss非线性衰减的方法相比原始的线性衰减有更高的风格迁移能力;
4)本发明用最近邻插值代替反卷积也有效的去除了产生音频的间接性噪音,显著提高了音频质量。
5)本发明提出了一种可以评价风格迁移算法的效果的指标,该指标摒弃了人为判断的主观性,能够客观公正的评价算法效果。
附图说明
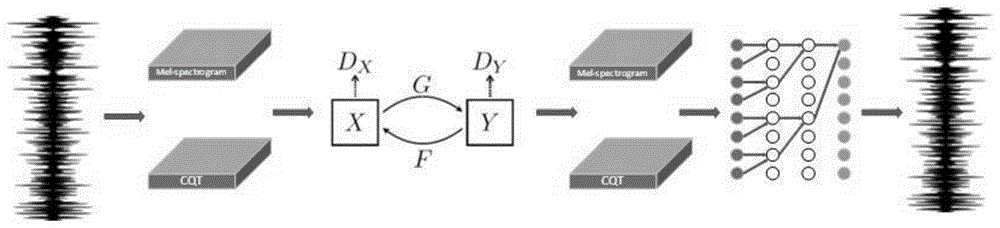
图1是本发明的整体模型架构图;
图2是采用反卷积生成的带有人声的音频图;
图3是采用最近邻插值生成带有人声的音频图。
具体实施方式
下面结合附图与具体实施方式对本发明作进一步详细描述:
本发明提供一种带有人声的音乐的风格迁移方法,基于cyclegan和wavenet解码器,解决目前音乐的风格转换领域。大部分的图像风格转换算法在音乐的风格转换上表现糟糕。在带有人声的音乐的风格转换,算法表现的更加糟糕的问题。
本发明的整体模型架构图如图1所示,采用反卷积生成的带有人声的音频图如图2所示,采用最近邻插值生成带有人声的音频图如图3所示,本专利发明的算法在计算机编程环境上进行了实验,通过实验我们验证了我们算法的正确性和可行性。具体的配置实施方式如下。
(1)训练集
选择一个开放且易于访问的音乐数据集。通常这个数据集要包含若干种类型的音乐片段,且该数据集要包含上万的音乐样本。假设选择的音乐数据集中,一共包含6种音乐风格,每个音乐片段的长度为30s,采样率为22050。由于网络限制,我们将一个30s的片段分成6个大约5s的片段输入进cyclegan进行风格迁移。
(2)音乐质量分类器和音乐风格分类器训练
通过数据集和神经网络训练音乐流派分类器。
对训练集中的音乐数据片段添加不同程度的噪声,噪声分为十个等级。噪声可以通过往波形中随机添加不同范围的随机数,然后将这些数据输入进特定神经网络进行分类。通过这个音乐质量评估器来对转换后的音乐进行打分。
(3)音乐风格转换器训练
通过开源包librosa提取cqt特征和梅尔频谱特征。然后对两层特征进行合并。
假定对同一个音频进行时频处理,并且采用相同的窗口长度、窗函数以及步长。得到的cqt特征矩阵大小为n×m,得到的梅尔频谱特征矩阵大小为t×m。
如果n≥t,那么以cqt特征矩阵作为第一层,梅尔频谱特征矩阵作为第二层。对于前t行来说,cqt特征矩阵和梅尔频谱特征矩阵一一对齐。对于梅尔频谱特征矩阵缺少的部分进行零填充。如果n<t,那么以梅尔频谱特征矩阵作为第一层,cqt特征矩阵作为第二层。对于前n行来说,cqt特征矩阵和梅尔频谱特征矩阵一一对齐。对于cqt特征矩阵缺少的部分进行零填充。最终得到输入矩阵的大小为max(t,n)×m
进一步的,步骤(2)进行风格迁移的cyclegan采用的损失函数如下:
假设我们要将风格为a的音乐迁移到风格为b的音乐,设这两个音乐的所在域为域x和域y,g为生成器,f为判别器,pdata(x)为x域的音乐片段,且x从pdata(x)中采样,pdata(y)为y域的音乐片段,且y从pdata(y)中采样首先添加x→y的对抗性损失函数如下:
添加y→x的对抗性损失函数如下:
添加循环一致性损失:
为了保留谱图的颜色成分,添加identityloss:
故总的损失函数如下:
l(g,f,dx,dy)=lgan(g,dy,x,y)+lgan(f,dx,y,x)+λ1lcyc(g,f)+λ2lidentity(g,f)
进一步的,对于步骤(2)进行风格迁移的cyclegan损失函数中循环一致性损失和identityloss
的权重λ1和λ2的设置,采用如下策略:
对于λ1的设置,采用恒定值。
对于λ2的设置,采用我们提出的非线性衰减,假设算法一共要迭代t步,那么在第n步,λ2为:
进一步的,对于步骤(3)进行的风格迁移的cyclegan的网络结构,将反卷积用最近邻差值代替和正则卷积替代。
进一步的,对于步骤(3)的wavenet解码器的输入谱图特征进行全局归一化处理:
对于所有的输入谱图的数据,采用如下对数变换进行全局归一化
ln(1+x/8)
x定义为输入的谱图数据的矩阵;
网络结构采用wavenet的标准结构,可以参考:
实验采用的wavenet解码器的扩张率为2k(k表示网络处于第几层)。对于所有的带洞卷积和因果卷积层,我们都使用了大小为3的卷积核。对于所有的残差块来说,远跳连接和残差连接的长度都为256。除此之外,每个残差层都包含一个relu非线性。
(4)算法效果评价
由于音乐流派种类多,边界模糊,且音乐具有时间特性,一首歌曲可能包含多个不同风格的片段,为了更好的评判此风格迁移算法的效果,我们摒弃了人为主观性。迁移后的音乐风格按照分类器的分类结果标注。在实验的多组数据中,我们选择了如下6组和其逆过程进行评价。评价的指标有aqr,tr,tce。
其中aqr由音乐质量评估器进行打分,然后计算每种风格转换域的平均打分。tr表示用分类器判断经过风格转换后的音乐是否成功的迁移到新的音乐域,然后计算每种风格转换域的平均成功率。对于tce,我们考虑到要同时考虑音乐质量和风格迁移率。故tce的计算参考公式:
tce=λ*aqrforward*trforward+(1-λ)*aqrbackward*trbackward
forward表示cyclegan的前向转换,backward表示cyclegan的后向转换,其中λ为cyclegan的前向转换所占比重。
以上所述,仅是本发明的较佳实施例而已,并非是对本发明作任何其他形式的限制,而依据本发明的技术实质所作的任何修改或等同变化,仍属于本发明所要求保护的范围。
- 还没有人留言评论。精彩留言会获得点赞!