一种基于神经网络的语义识别系统的制作方法
[0001]
本发明涉及语义识别系统领域,具体涉及一种基于神经网络的语义识别系统。
背景技术:
[0002]
语义识别是对文本或者录音进行文字的转换,转换成操作者直观看到的语言文字,便于人们了解所要传达的意思,语义识别前期需要对语种进行识别。
[0003]
语种识别的目的在于自动确定一段语音所属的语言种类.作为相关语音应用的一种前端处理技术,语种识别在多语种语音识别、信息检索和服务、跨语种通信系统和机器翻译等领域中有着广泛应用.语种识别中的一个重要问题是如何得到语音段的有效表示,这主要涉及前端特征提取和后端建模两方面的内容.对于给定语音段,音素学方法首先利用音素识别器得到语音段的符号串特征,然后建立相应的n-gram语言模型表示.声学方法对语音段提取梅尔倒谱参数或移位差分倒谱参数等作为前端特征,并利用混合高斯模型表示语音段信息。
[0004]
近年很多研究工作采用区分性训练、因子分析或全差异空间建模等机器学习领域中的成熟方法,提高后端建模的区分性和鲁棒性,使得语种识别性能得到一定提高。
[0005]
但是上述方法对短时语音段和方言的识别准确率还是过低,从而影响后期语义的识别,仍远不能满足实际应用的需求。
技术实现要素:
[0006]
本发明提出了一种基于神经网络的语义识别系统,解决了现有语义识别系统对短时语音段和方言的识别准确率还是过低,从而影响后期语义的识别,仍远不能满足实际应用的需求的问题。
[0007]
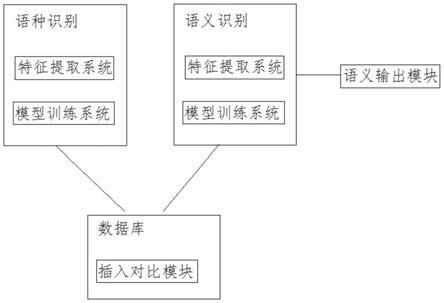
本发明的技术方案是这样实现的:一种基于神经网络的语义识别系统,包括特征提取系统、模型训练系统、语义分割模块和语义组合模块;所述特征提取系统用于提取语言的特征信息,将语音段所有帧的音素状态后验概率取均值,得到该语音段的数据;所述模型训练系统采用 svm 区分性建模方法,对此可对比 svm 在采取不同核条件下的识别性能;基于输出层语音段表示服从直方图分布的假设,实现对语种的识别;所述语义分割模块将所述特征提取系统提取的语音段进行分割,独立分段翻译出单独语义;所述语义组合模块将单独语义进行组合,组合出含有语义的语句,从而实现语义的识别。
[0008]
优选的,所述模型训练系统在实现语种的识别后,通过与传统的音素识别结合支持向量机语种识别方法进行对比实验,以此对比音素状态级信息和音素级信息的有效性。
[0009]
优选的,所述语义分割模块对所述语音段进行分割时,采用区域生长法对语音段进行分割。
[0010]
优选的,所述语义分割模块进行分割后还包括对分割后的语音段进行二次特征提取,提取方法采用的方法为颜色直方图或灰度共生矩。
[0011]
优选的,还包括数据库,所述数据库用于存储应用场景数据和语法规则数据。
[0012]
优选的,所述数据库中还包括插入对比模块,所述插入对比模块与所述语义组合模块相匹配,当所述语义组合模块组合出含有语义的话语时,通过插入对比模块中的场景数据和语法规则模块对语句进行限定,选取最优语句。
[0013]
优选的,还包括语义输出模块,所述语义输出模块采用e702t音频模块,用于语音播放输出最优语句。
[0014]
本发明的有益效果是,本发明通过设置特征提取系统、模型训练系统、语义分割模块和语义组合模块;其中特征提取系统、模型训练系统构成语种的识别单独系统,语义分割模块和语义组合模块构成语义输出系统。
[0015]
特征提取系统用于提取语言的特征信息,将语音段所有帧的音素状态后验概率取均值,得到该语音段的数据;模型训练系统采用 svm 区分性建模方法,对此可对比 svm 在采取不同核条件下的识别性能;基于输出层语音段表示服从直方图分布的假设,实现对语种的识别。
[0016]
语义分割模块将特征提取系统提取的语音段进行分割,独立分段翻译出单独语义;语义组合模块将单独语义进行组合,组合出含有语义的语句,从而实现语义的识别,并且通过在语音段进行分割时,还可以进行二次特征提取,提高语义输出的准确性。
[0017]
申请通过设置独立的语种识别系统和语义识别系统,逐步实现对文本语义的输出,大大提高语义识别的准确性。
附图说明
[0018]
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
[0019]
图1为本发明基于神经网络的语义识别系统的原理框图;图2为本发明中语义分割模块的工作原理框图。
具体实施方式
[0020]
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
[0021]
参照图1-2,于神经网络的语义识别系统,包括特征提取系统、模型训练系统、语义分割模块和语义组合模块;特征提取系统用于提取语言的特征信息,将语音段所有帧的音素状态后验概率取均值,得到该语音段的数据;模型训练系统采用 svm 区分性建模方法,对此可对比 svm 在采
取不同核条件下的识别性能;基于输出层语音段表示服从直方图分布的假设,实现对语种的识别;语义分割模块将特征提取系统提取的语音段进行分割,独立分段翻译出单独语义;语义组合模块将单独语义进行组合,组合出含有语义的语句,从而实现语义的识别。
[0022]
模型训练系统在实现语种的识别后,通过与传统的音素识别结合支持向量机语种识别方法进行对比实验,以此对比音素状态级信息和音素级信息的有效性。
[0023]
语义分割模块对语音段进行分割时,采用区域生长法对语音段进行分割。
[0024]
语义分割模块进行分割后还包括对分割后的语音段进行二次特征提取,提取方法采用的方法为颜色直方图或灰度共生矩。
[0025]
还包括数据库,数据库用于存储应用场景数据和语法规则数据,其中场景数据包括不同的地域、不同的环境;本申请语法规则数据采用中文语法规则,但是为了保证本实施例应用的范围更加广泛,数据库上可以外接输入端口,实现对数据库的不断完善,在发现新的应用场景,或者在本系统使用者处于不同的地域时,输出的最优语句也会采用不同的语言进行输出,此时需要录入不同输出语言作为语法规则数据。
[0026]
数据库中还包括插入对比模块,插入对比模块与语义组合模块相匹配,当语义组合模块组合出含有语义的话语时,通过插入对比模块中的场景数据和语法规则模块对语句进行限定,选取最优语句,语义组合模块在对语义进行合成时,面对不同含有的多个词汇,合成的语句也会有多个,通过添加应用场景和语法,这样就能通过条件筛选最优语句。
[0027]
还包括语义输出模块,语义输出模块采用e702t音频模块,用于语音播放输出最优语句,e702t音频模块主要由arm+dsp构架,专注于网络音频传输的控制模块,具有10/100m 以太网接口,可通过网络进行单向mp3音频流和双向语音传输。
[0028]
以上仅为本发明的较佳实施例而已,并不用以限制本发明,凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1