一种DSP多通道降啸叫处理的实现方法及系统和芯片与流程
一种dsp多通道降啸叫处理的实现方法及系统和芯片
技术领域
[0001]
本发明涉及一种音频处理方法及系统和芯片,尤其涉及的是一种dsp指定多通道降啸叫处理的实现方法及系统和芯片的改进。
背景技术:
[0002]
在现有技术的消除啸叫处理技术中,一般使用的是移频技术,根据啸叫可能发生的频点或实际已经发生啸叫的频点(需要传感器感知信号),将相应的啸叫频点进行指定频率点分贝下降调整,从而从能量上降低拾音时谐振的可能性,从而实现对啸叫的控制和调整。
[0003]
然而,对音频处理系统来说,啸叫的分贝值相当于天花板,对于一个话筒到音箱的通道来说,由于存在啸叫就需要降低分贝,因而其他需要提升分贝的频点也需要同步下调,因此由于啸叫存在而进行的调整就不能将音量提高到更高的程度,而只能采用较低的分贝能量状态进行播放,这样就会因为啸叫导致整个音频播放系统的音量不足,而导致听者对播放音质的感受下降。
[0004]
与此同时,现有技术中存在多通道的情形,例如大型的会议室的话筒音频系统,可能需要多个话筒的同步工作;现有技术中一般是将多个话筒的声音进行混合,形成一个通道后发送给后续dsp(digital signal process,数字信号处理器芯片)进行防止啸叫的处理,例如因为需要降低某个啸叫频点的分贝而做出整个音量的全频点降低调整。
[0005]
针对一个通道的处理时,通常会采用带通减啸叫频点/移频器/压限器等方式进行处理。自动啸叫频点处理的设备统称反馈抑制器,反馈抑制器工作流程如下:在啸叫产生时通过dsp频谱分析算法fft实时分析出啸叫频点,用eq对这个啸叫点实时进行衰减并保存或暂存,从而达到抑制啸叫的目的。架构由信号采集话筒/话放/adc/dsp/dac等结构完成。因fft占用资源量大,受dsp资源限制一般反馈抑制器只能做成单通道或双通道。若要做成多通道处理形态,只能采用高成本的dsp芯片,非常难于满足资源的需求。
[0006]
然而,由于多个话筒的朝向和环境的复杂境况导致相互影响的情形极为复杂,在拾取的声音混合后会形成复杂的音量参数特点,导致啸叫频点不唯一,甚至在遇到话筒移动的场景中(例如无线话筒甚至多个无线话筒在会场内的移动),dsp的处理就非常困难,往往只能根据某一个啸叫频点进行处理,而无法整体上进行更好的全面处理,例如自动,实时等。
[0007]
在音频处理领域,利用fft(fast fourier transform,快速傅里叶变换模块)可以对获取的音频信号进行处理,fft一般设置在dsp中,但fft的资源占用过大,往往会导致dsp的处理能力不够,无法针对会议需求进行更多的通道处理。而dsp中除了fft之外的功能主要是eq等占用资源少的功能和算法处理,并不需要太多资源,而fft一旦运行,就经常会导致dsp内的资源紧缺,无法应对多通道的处理,更不用说针对复杂环境已经变化状态下的多通道处理要求。
[0008]
因此,现有技术还存在缺陷,而有待于改进和发展。
技术实现要素:
[0009]
本发明的目的在于提供一种dsp指定多通道降啸叫处理的实现方法及系统和芯片,针对现有技术中dsp的多通道处理,实现其针对啸叫频点的统一处理能力扩展,并提升其针对啸叫多频点的处理能力。
[0010]
本发明的技术方案如下:
[0011]
一种dsp多通道指定降啸叫处理的实现方法,其系统是由同一dsp音频处理器控制的至少一个指定输入麦克风,以及至少指定一个输出音箱组成的回路系统;
[0012]
系统运行包括以下步骤:
[0013]
a、由dsp音频处理器控制至少一个输出音箱输出预先设置的环境校准音源进行环境反馈;
[0014]
b、由与所述dsp音频处理器通信连接的fft检测控件模块从指定一输入麦克风中获取环境中反馈声场的均衡信号源,得到环境和系统整体的反馈后的校准音源信号进行频谱分析。
[0015]
c、将所述频谱分析结果中的均衡量值进行均衡处理,并通过所述dsp音频处理器控制对应话筒和对应音箱所在环境反馈的频响曲线,使得所控制频响曲线能量较高的频点保持较低或不变的能量输出。
[0016]
所述的dsp多通道降啸叫处理的实现方法,其中,所述步骤c之后还包括步骤:
[0017]
d、将所述步骤c中的处理频点模式予以固定,由于可以指定任意特定麦克风和特定音箱使得设备可以同时处理几个不同房间的不同啸叫环境,区别于目前一机一地的处理方法。
[0018]
所述的dsp多通道降啸叫处理的实现方法,其中,a中的测试环境音频和fft检测控件模块设置在所述dsp音频处理器之外的mcu中,并通过所述dsp音频处理器的输入和输出引脚与所述fft检测控件模块所在的mcu通信连接。
[0019]
所述的dsp多通道降啸叫处理的实现方法,其中,所述输入麦克风与所述输出音箱分别设置有多个并可以任意改变输入输出的内部路径,并且每一路话筒都是单独处理。
[0020]
所述的dsp多通道降啸叫处理的实现方法,其中,所述步骤a到步骤c依照预定频率反复执行和调整。
[0021]
所述的dsp多通道降啸叫处理的实现方法,其中,所述fft检测控件模块通过单片机实现。
[0022]
一种实现任一dsp多通道降啸叫处理实现方法的系统,其中,测试环境音频和fft检测控件模块设置在所述dsp音频处理器之外的mcu中,并通过所述dsp音频处理器的输入和输出引脚与所述fft检测控件模块所在的mcu通信连接。
[0023]
一种实现任一dsp多通道降啸叫实现方法的芯片,其中,所述fft检测控件模块设置在所述dsp音频处理器的外部,并通过所述dsp音频处理器的输入和输出引脚与所述fft检测控件模块通信连接;并且将所述fft检测控件模块与所述dsp音频处理器封装在一起,并将所述dsp音频处理器与所述输入麦克风连接的输入引脚和与所述输出音箱的输出引脚分别引出作为所述芯片的对应输入输出引脚。
[0024]
本发明所提供的一种dsp多通道降啸叫处理的实现方法及系统和芯片,由于采用了将fft检测控件模块设置在所述dsp音频处理器的外部,减少了对dsp音频处理器的资源
占用,并可以利用音箱对预先设定的校准音频播放,以及麦克风对环境声音信号的拾取,交给所述fft检测控件模块进行处理后,由所述dsp音频处理器的eq处理,实现在减少啸叫频点能量的基础上,尽可能大的提升其他频点的音量,从而实现了播放音质的提升,同时由于输入输出路径可以任意控制,所以可以同时控制多个房间的啸叫处理。
附图说明
[0025]
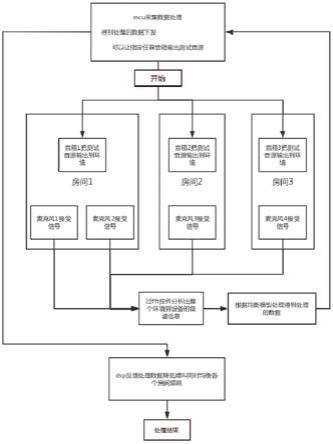
图1为本发明dsp多通道降啸叫处理的实现方法及系统和芯片的逻辑结构示意图。
[0026]
图2为本发明所述dsp多通道降啸叫处理的实现方法及系统和芯片硬件结构示意图。
具体实施方式
[0027]
以下对本发明的较佳实施例加以详细说明。
[0028]
本发明所提供的一种dsp多通道降啸叫处理的实现方法及系统和芯片,如图1和图2所示的,主要针对多通道的音频处理系统,当然在极端的情况下,也可以仅针对单通道进行处理,也就是仅有一个麦克风的情况。在通常的情况下,所述音频处理系统是针对多通道处理,也就是具有多个输入麦克风的输入通道,输出的音箱通常设置也是多个,但在播放时,每个麦克风输入的信号经过处理之后,是通过所有的输出音箱进行播放的。
[0029]
本发明所述dsp多通道降啸叫处理的实现方法及系统中,设置了fft检测控件模块111,用来针对麦克风113的输入音频信号进行频谱分析,以及dsp音频处理器112,用来对音频进行eq处理后通过所述音箱114进行播放。在可替换的技术方案中,所述麦克风可以通过类似于麦克风的音频传感器进行音频信号拾取。通常,音频处理系统对麦克风的拾取音频只能统一进行处理(通过eq功能,equalizer指均衡器),而在感知到某个啸叫点时,就整体下调各频点的能量输出,这种针对啸叫的处理方式导致因为啸叫的能量输出导致整体音频能量不足,整体音频输出时的能量不足,从而形成音频处理的天花板效应,其他非啸叫的频点也无法达到最大的能量(分贝)输出。
[0030]
在本发明所述dsp多通道降啸叫处理的实现方法及系统和芯片中,所述dsp音频处理器的处理模式可以有多种,例如还可以根据频点与音量的关联关系,并将各频点能量的均衡值为中心线,将能量过低的频点进行提升,能量过高的频点进行降低(中心线以及提升或降低的数值还可以通过比较算法实现增益或减损比例),由此可以打开“天花板”,可以在后续使用中允许音量调整的空间更大(现有技术的啸叫往往是因为音量调大时某个频点出现啸叫谐振)。
[0031]
本发明所述dsp多通道降啸叫处理的实现方法及系统中,利用将所述fft检测控件模块设置在所述dsp音频处理器的外部,而只通过输入和输出引脚与所述dsp音频处理器进行通信连接,从而减少了对dsp音频处理器的资源占用和处理能力限制。所述fft检测控件模块独立可以通过采用与所述dsp音频处理器类似的单片机或mcu实现,先由所述dsp音频处理器控制至少一个输出音箱播放预先设置的校准音频文件,较佳的是,通过所述多个输出音箱进行针对校准音频文件的播放。
[0032]
所述fft检测控件模块将来自至少一个麦克风拾取的音频信号进行频谱分析处理,并分析得到能量较高的频点,这些频点是首先会发生啸叫的频点,针对这些频点的能量
进行降低。
[0033]
然后通过所述dsp音频处理器中的基本功能(eq),将已经降低了可能发生啸叫的频点的音频文件进行整体的能量提升后,发送給输出音箱进行播放。从而实现了在控制啸叫的基础上,最大限度的提升音频输出的能量分贝。
[0034]
本发明所述校准文件预先录制并对应设置相应的频谱模式,所述音频校准文件预先可以存储在所述dsp音频处理器中或者所述fft检测控件模块中,或者另外的独立存储单元。在更为先进的处理模式中,还可以设置直接从所述麦克风拾取的任何音频文件进行分析,并可以按照预先设定的频次周期进行定期的自动检测和调整。在更佳的实施例中,所述dsp音频处理器对输入麦克风的控制还可以设置采用更为实时的检测频率,以便适应移动的话筒,在话筒位置改变时可以实时的调整可能发生啸叫的频点,并尽最大可能的提升除啸叫频点之外的其他频点的能量分贝。
[0035]
本发明所述实现方法包括了以下步骤:
[0036]
a、由dsp音频处理器控制至少一个输出音箱播放预先设置的校准音频文件;
[0037]
b、由与所述dsp音频处理器通信连接的fft检测控件模块从至少一输入麦克风中获取输入针对所述校准音频的输入信号,并进行频谱分析;
[0038]
c、将所述频谱分析结果中能量较高的频点进行单独能量降低,并通过所述dsp音频处理器控制所述输入信号提升各频点的能量输出,并控制所述能量较高的频点保持较低或不变的能量输出。
[0039]
本发明所述dsp多通道降啸叫处理的实现方法及系统中,所述fft检测控件模块在接受到麦克风的拾取音频信号后会进行相应的识别,并根据识别后的频谱分析结果,形成针对本环境的处理模式,并发送給dsp音频处理器,依照该识别后的处理模式进行后续的音频处理。较好的是,可以设置预定的频次,例如每隔一小时一次,或者每次开机时进行一次识别处理,以防止环境有改变的情况下可能会导致啸叫的频点发生变化,这样通过及时更新可以调整在新出现的啸叫频点进行降能量分贝的同时尽可能将其他的能量分贝提升,从而提升音频处理后的音质效果。
[0040]
本发明实现上述dsp多通道降啸叫处理的实现方法及系统的芯片中,还将所述fft检测控件模块以及所述dsp音频处理器进行封装,并将所述dsp音频处理器与所述输入麦克风连接的输入引脚和与所述输出音箱的输出引脚分别引出作为所述芯片的对应输入输出引脚,从而形成本发明所述芯片装置。形成芯片的好处是可以将芯片直接替代复杂的电路单元,从而实现更好的应用到实际产品中。
[0041]
例如,在应用本发明所述dsp多通道降啸叫处理的实现方法及系统和芯片产品中,出现了一种可以将fft检测控件模块以及所述dsp音频处理器或者封装两者的芯片设置在一体式的话筒中,也即在话筒上至少设置存储用于播放的音频校准文件,可以在所述话筒上同时设置输出音箱,或者通过有线或无线连接,通过本空间环境内的输出音箱进行播放,并通过本话筒进行拾音和做相应的频谱分析处理。
[0042]
对某个房间或空间来说,声场有其独特的特点,所以啸叫的发生不单纯是因为音响系统本身的原因,更多的原因在于声场环境的特征形成了谐振的频点,而在大部分的环境情况下,啸叫的特征频点一般不止一个,现有技术中由于是被动的进行调整,也就是在发生啸叫后才进行移频处理,往往很难快速直接且真正有效地解决啸叫问题。
[0043]
而本发明可以通过预先的校准音频播放,在很短的时间内将环境反馈特点进行固定,并将频谱分析后确定的调整模式方案下发给dsp音频处理器,在之后该通道的音频处理就都可以采用该同样的处理,从而保证了音响的效果(在整个房间或环境没有大的改变前,例如房屋结构空间改变或家具的大的位置或空间改变前,整个环境的音频特点是保持稳定的)。
[0044]
本发明将fft检测控件模块设置在dsp音频处理器之外的好处是,可以随意设置叠加多个dsp音频处理器,例如一个dsp音频处理器有八个通道,可以连接八个话筒,而叠加多个dsp就可以随意扩展通道,连接更多倍的话筒。每个通道都可以按照上述调控方式进行预先调整和设置,可以实现自动化地预先处理,并使整个音响系统更加均衡,音量可以调整地更大,音色更饱满而且基本消除啸叫。
[0045]
本发明所述dsp多通道降啸叫处理的实现方法及系统和芯片可以应用到不同的应用场景,包括会议、娱乐的卡拉ok等,可以形成不同的音响处理系统,实现大量多个输入通道的并行输入,而不会形成啸叫。
[0046]
本发明采用了主动式反馈抑制器的工作方式,其是先期介入并提前分析,预置可能出现的啸叫频点,达到正常使用下不会啸叫的目的。其工作流程和架构如下:在设备正常使用前,发出预先设定的校准音频文件噪声,话筒拾取到音频信号通过fft做频谱分析,能量较高和较低的频点通过eq进行衰减和提升并保存,从而达到啸叫抑制目的自动均衡扩声链(房间/话筒/功放/音箱)的目的,可定义为主动式反馈抑制器或自动均衡器。
[0047]
应当理解的是,对本领域普通技术人员来说,可以根据上述说明加以改进或变换,而所有这些改进和变换都应属于本发明所附权利要求的保护范围。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1