一种基于神经网络的声带病变检测装置
本发明涉及神经网络检测技术领域,尤其是涉及一种基于神经网络的声带病变检测装置。
背景技术:
在日常生活中,人与人之间为了良好的沟通,都需要利用说话来进行信息交互,因此,嗓音是传达信息、社交活动和交流感情必不可少的工具。随着社会的进发展,经济的繁荣,人们交往和沟通的频繁,嗓音作为一种十分便捷的信息传递手段,无疑成为现代通信及信息时代越来越重要的工具,但如此同时,也伴随着声带病变的发病率的上升。嗓音的检查一直为耳鼻喉科医生、言语病理学家所重视。
对嗓音状况的调查表明,我国患有声带病变的人数众多,涉及到生理和工作环境等许多原因。声带病变包括声带肥厚、声带小结及声带麻痹等,声带肥厚指声带肿胀或增厚,声带小结为两侧声带前、中1/3交界处所发生的对称性小结,两者均属慢性喉炎所致;声带麻痹,为喉运动性神经疾病,多因神经损伤造成。三者都以声嘶为临床主要表现。此外临床上还常见有声带息肉、声带水肿等疾病。
对于此类疾病的医学研究及诊断,还大多采用传统方法来进行,例如喉镜检查,动态镜检查,肌电图描记等,但这些方法一来非常不方便,二来都为侵入性的检查方法,容易对患者造成一定的痛苦及损伤,并且对身体状况和配合度都有较高要求。这些检测方法往往比较依赖于临床医生的个人经验,一旦无法对喉部及声带的病变做出早期预诊,非常容易耽误治疗。
技术实现要素:
为解决现有技术的不足,实现提高检测的效率、舒适度和准确性的目的,本发明采用如下的技术方案:
一种基于神经网络的声带病变检测装置,包括依次连接的采集模块、降噪模块、特征提取模块和神经网络模型,所述采集装置采集用户在一个时间段的声音信号,所述降噪模块对声音信号进行降噪预处理,所述特征提取模块对预处理好的声音信号进行特征提取,所述神经网络模型采用efficientnet神经网络模型,对提取到的特征进行训练,再通过采集模块采集到的用户声音信号,经降噪模块预处理后,由特征提取模块提取的特征作为输入,通过训练好的神经网络模型完成对声带病变的分类和识别。
进一步的,所述efficientnet神经网络模型的公式如下:
其中w,d,r为系数,w表示卷积核的大小,决定了感受野大小,d表示神经网络深度,r表示分辨率大小,xi为输入张量,
进一步的,efficientnet神经网络的规范化复合调参使用了一个复合系数
s.t.α*β2*γ2≈2(α≥1,β≥1,γ≥1)
其中,α,β,γ为常数,通过网格搜索获得,
进一步的,所述efficientnet神经网络模型,使用tensorflow框架运行efficientnet神经网络,efficientnet神经网络利用复合系数统一缩放模型的所有维度,达到精度最高、效率最高,包括stem、blocks、con2d、globalaveragepooling2d和dense。
进一步的,所述降噪模块是lms自适应滤波器,对采集到的声音信号进行降噪,将输入信号序列定义为xi(n),期望输出信号为d(n),定义误差信号为:
其中ωi为权系数,m为输入信号维数,通过寻找最优的权系数ωi,使得误差信号e(n)最小。
进一步的,所述权系数的迭代公式为:
求收敛因子μ和梯度因子以求得最优解,收敛因子μ控制收敛的速率,其取值范围为
进一步的,所述特征提取模块提取声音信号的基频类特征、振幅类特征、含噪类特征。
进一步的,所述基频类特征是嗓音基频,即嗓音的第一谐波,通过嗓音频率或周期来描述嗓音信号的稳定度,通过基频标准差来衡量基频总体稳定程度,整体反应声带振动的稳定性。
进一步的,所述振幅类特征是振幅,描述嗓音信号的振幅稳定性程度。
进一步的,所述含噪类特征包括:nne、nhr、vtt和spi,描述能量分布情况,所述nne是总的声学能量减去谐波能量;所述nhr用于计算频率带宽1500hz—4500hz中非谐波成分能量与频率带宽70hz—4500hz中谐波成分能量的比值;所述vtt用于计算频率带宽2800hz—5800hz中非谐波成分能量与频率带宽70hz—450hz中谐波成分能量的比值;所述spi用于计算频率带宽70hz—1600hz中谐波成分能量与频率带宽1600hz—4500hz中谐波成分能量的比值。
本发明的优势和有益效果在于:
本发明通过深度学习的方法来对声带疾病进行早期检测,为患者带来便捷,同时深度学习有利于提高精准度,通过efficientnet模型,可以更好的通过嗓音的特征来对用户是否患有声带疾病做出检测,在非侵入性检测提高舒适度的同时,既能减少用户就医的时间,又能提高准确度。
附图说明
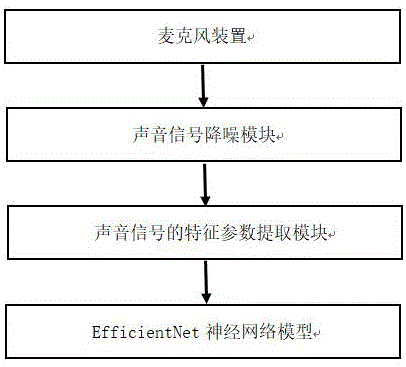
图1是本发明中检测装置结构示意图。
具体实施方式
以下结合附图对本发明的具体实施方式进行详细说明。应当理解的是,此处所描述的具体实施方式仅用于说明和解释本发明,并不用于限制本发明。
采用深度学习的方法来对声带疾病进行早期检测,能为患者带来许多便捷。深度学习是机器学习的分支,是一种以人工神经网络为架构,对数据进行表征学习的算法。深度学习广泛应用在各个领域,例如计算机视觉、语音识别、自然语言处理、音频识别与生物信息学等领域。efficientnet模型是谷歌2019年推出的,它具有很独特的特点,例如:利用残差神经网络增大神经网络的深度,通过更深的神经网络实现特征提取,改变每一层提取的特征层数,实现更多层的特征提取,得到更多的特征,提升宽度,通过增大输入图片的分辨率也可以使得网络可以学习与表达的东西更加丰富,有利于提高精准度。那么通过efficientnet模型,就可以很好的通过嗓音的特征来对用户是否患有声带疾病做出判断,既能减少用户就医的时间,又能提高准确度。
如图1所示,一种基于efficientnet神经网络的声带病变检测装置,包括麦克风装置、声音信号降噪模块、声音信号的特征参数提取模块和efficientnet神经网络模型。
1、麦克风装置,采集用户在一个时间段的声音信号;具体地,将麦克风装置放置于用户身边,按下开关即可使用麦克风阵列采集用户的声音信息;
2、声音信号降噪模块,对声音信号进行降噪预处理;具体地,采用lms自适应滤波器对采集到的声音信号进行降噪,将输入信号序列定义为xi(n),期望输出信号为d(n),定义误差信号为:
其中ωi为权系数,m为输入信号维数,lms算法的本质就是寻找最优的权系数ωi,使得误差信号e(n)最小,权系数的迭代公式为:
求收敛因子μ和梯度因子以求得最优解,收敛因子μ控制收敛的速率,其取值范围为
3、声音信号的特征参数提取模块,对处理好的声音信号进行特征提取;具体地,提取声音信号的基频类特征、振幅类特征、含噪类特征。嗓音基频就是嗓音的第一谐波,此类特征通过嗓音频率或者周期来描述嗓音信号的稳定度,通过基频标准差来衡量基频总体稳定程度,能整体反应声带振动的稳定性。振幅和基频一样是描述嗓音信号的基本量,振幅类特征主要描述嗓音信号的振幅稳定性程度。含噪类特征描述的是能量分布情况,如nne是指总的声学能量减去谐波能量,nhr计算的是频率带宽1500hz—4500hz中非谐波成分能量与频率带宽70hz—4500hz中谐波成分能量的比值,vtt计算的是频率带宽2800hz—5800hz中非谐波成分能量与频率带宽70hz—450hz中谐波成分能量的比值,spi计算的是频率带宽70hz—1600hz中谐波成分能量与频率带宽1600hz—4500hz中谐波成分能量的比值。
4、efficientnet神经网络模型,使用efficientnet神经网络对提取到的特征进行训练;具体地,使用tensorflow框架运行efficientnet神经网络,efficientnet利用复合系数统一缩放模型的所有维度,达到精度最高效率最大高,它一共由stem+16个blocks+con2d+globalaveragepooling2d+dense组成。其中包括w,d,r三个系数,w表示卷积核的大小,决定了感受野大小;d表示神经网络深度;r表示分辨率大小。
神经网络的数学公式如下:
其中:xi为输入张量,
efficientnet的规范化复合调参方法使用了一个复合系数
s.t.α*β2*γ2≈2(α≥1,β≥1,γ≥1)
其中,α,β,γ为常数,可以用过网格搜索获得。而
使用训练好的模型完成对声带病变的分类和识别;具体地,将采集到的用户声音信号预处理后提取出的特征作为输入,模型识别后给出声带病变分类。
以上实施例仅用以说明本发明的技术方案,而非对其限制;尽管参照前述实施例对本发明进行了详细的说明,本领域的普通技术人员应当理解:其依然可以对前述实施例所记载的技术方案进行修改,或者对其中部分或者全部技术特征进行等同替换;而这些修改或者替换,并不使相应技术方案的本质脱离本发明实施例技术方案的范围。
- 还没有人留言评论。精彩留言会获得点赞!