一种基于语音识别的控制方法及装置与流程
本申请涉及语音识别与控制技术领域,尤其涉及一种基于语音识别的控制方法及装置。
背景技术:
近二十年来,语音识别技术取得显著进步,开始从实验室走向市场。人们预计,未来10年内,语音识别技术将进入工业、家电、通信、汽车电子、医疗、家庭服务、消费电子产品等各个领域。
目前的语音识别,主要将双方交谈内容完整记录下来,还无法对实时谈话中的指令进行实时响应。
技术实现要素:
有鉴于此,本申请实施例提供了一种基于语音识别的控制方法及装置,可以在用户在谈话时智能调取会谈内容中的控制指令,用于对智能设备进行控制。
为解决上述技术问题,本申请实施例是这样实现的:
本申请实施例提供的一种基于语音识别的控制方法,所述方法包括:
获取对话语音信息;
对所述对话语音信息进行语音识别,获得不同用户的语音信息;
对所述不同用户的语音信息进行语义分析,获得文字信息;
提取所述文字信息中的关键词;
在关键词指令库中对所述关键词进行匹配,根据匹配结果确定所述关键词对应的控制指令信息;
基于所述控制指令信息对设备进行控制。
可选的,所述对话语音信息为拾音设备发送的对话语音信息。
可选的,所述对所述对话语音信息进行语音识别,获得不同用户的语音信息,具体包括:
采用声纹识别对所述对话语音信息进行语音识别,获得不同用户的语音信息。
可选的,在对所述不同用户的语音信息进行语义分析,获得文字信息之前,所述方法还包括:
对所述语音信息进行语种识别;
根据语种识别结果调取对应的语义分析策略;
对所述不同用户的语音信息进行语义分析,获得文字信息,具体包括:
利用所述语义分析策略对所述不同用户的语音信息进行语义分析,获得文字信息。
可选的,在对所述不同用户的语音信息进行语义分析,获得文字信息之后,提取所述文字信息中的关键词之前,还包括:
获取所述文字信息的预设长度的起始字符串;
根据所述起始字符串判断所述文字信息是否用于触发控制指令;
提取所述文字信息中的关键词,具体包括:
若所述文字信息用于触发控制指令,提取所述文字信息中的关键词。
可选的,所述控制指令信息用于调取信号源、监控、程序或文件。
可选的,所述基于所述控制指令信息对设备进行控制后,所述方法还包括:当在预设时间内没有语音输入时,关闭基于控制指令信息控制设备的功能,当有语音输入时,自动唤醒基于控制指令信息控制设备的功能。
可选的,在关键词指令库中对所述关键词进行匹配,具体包括:
从关键词指令库中检索所述关键词对应的大屏幕显示场景,所述关键词指令库中存储关键词与大屏幕显示场景之间的映射关系。
可选的,所述确定所述关键词对应的控制指令信息后,所述基于所述控制指令信息对设备进行控制前,所述方法还包括:当所述控制指令信息为多个时,若在预设时间段内,存在相互矛盾或者完全反向的控制指令时,丢弃相互矛盾的控制指令信息。
可选的,所述控制指令信息为多个,所述基于所述控制指令信息对设备进行控制,具体包括:
按照执行逻辑顺序将多个所述控制指令信息进行组合;
将组合后的所述多个所述控制指令信息转化为机器控制命令;
将所述机器控制命令发送至相应设备。
本申请实施例提供的一种基于语音识别的控制装置,其特征在于,所述设备包括:
语音获取模块,用于获取对话语音信息;
语音识别模块,用于对所述对话语音信息进行语音识别,获得不同用户的语音信息;
语义分析模块,用于对所述不同用户的语音信息进行语义分析,获得文字信息;
关键词提取模块,用于提取所述文字信息中的关键词;
关键词匹配模块,用于在关键词指令库中对所述关键词进行匹配,根据匹配结果确定所述关键词对应的控制指令信息;
设备控制模块,用于基于所述控制指令信息对设备进行控制。
本申请实施例提供的一种存储介质,其上存储有计算机可读指令,所述计算机可读指令可被处理器执行以实现上述的基于语音识别的控制方法。
本申请实施例采用的上述至少一个技术方案能够达到以下有益效果:
本申请实施例提供的方法自动获取对话语音信息,提取出其中的关键词,并根据关键词确定控制指令信息,使得用户通过说话方式即可对各种指定设备进行操作。由此可见,本申请提供的方法可以在用户实时谈话过程中响应对话语音信息进行指定设备控制。
本方法可以在用户对话时自然实时操作指定设备或程序,无需唤醒,支持直接调取信号源、监控、程序或文件。
本方法对所述对话语音信息进行语音识别,获得不同用户的语音信息,因此可以支持多人在实时对话中发布控制指令。
另外,本方法还对语音信息的语种进行识别,然后再进行语义分析,因此可以支持多语言调取信号源、监控、程序或文件。
附图说明
此处所说明的附图用来提供对本申请的进一步理解,构成本申请的一部分,本申请的示意性实施例及其说明用于解释本申请,并不构成对本申请的不当限定。后文将参照附图以示例性而非限制性的方式详细描述本申请的一些具体实施例。附图中相同的附图标记标示了相同或类似的部件或部分,本领域技术人员应该理解的是,这些附图未必是按比例绘制的,在附图中:
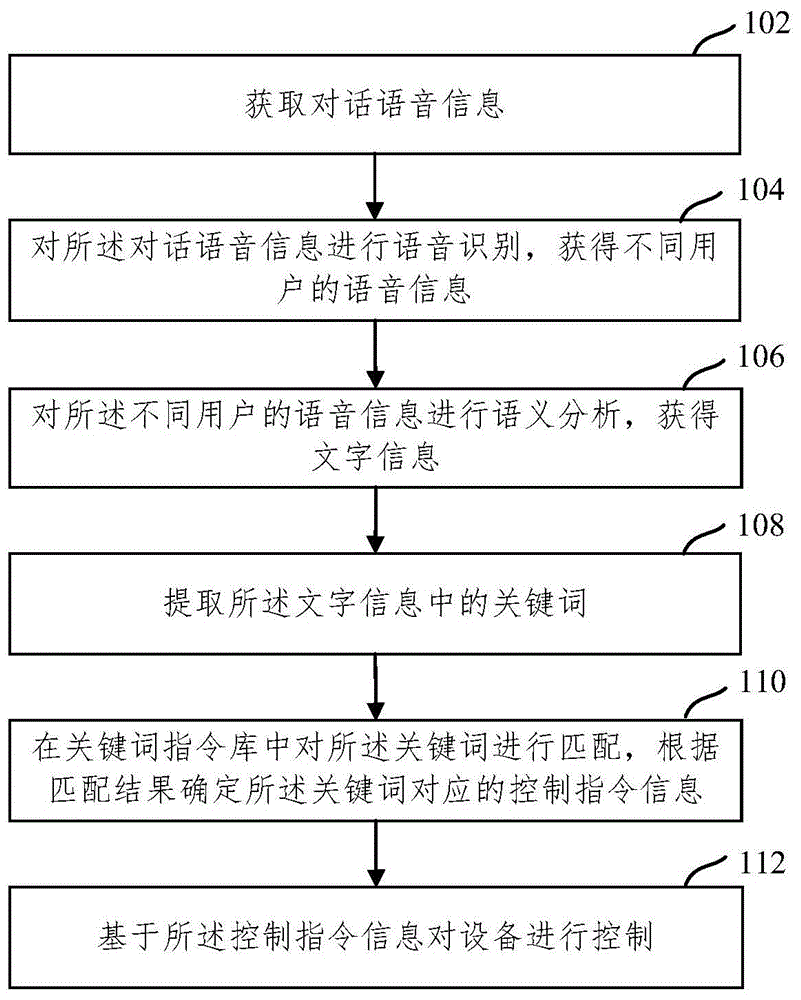
图1为本申请实施例提供的一种基于语音识别的控制方法的流程示意图;
图2为本申请实施例提供的对应于图1的一种基于语音识别的控制装置的结构示意图。
具体实施方式
为了使本技术领域的人员更好地理解本申请方案,下面将结合本申请实施例中的附图,对本申请实施例中的技术方案进行清楚、完整地描述。显然,所描述的实施例仅仅是本申请一部分的实施例,而不是全部的实施例。基于本申请中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都应当属于本申请保护的范围。
对于一些智能控制设备,比如计算机、大屏幕等,往往需要单独进行控制才可以,比如采用鼠标或者遥控器等。对于在进行会议的过程中,如果能在聊天的模式中自动的控制智能设备,能够大大的提高用户的便利性。本方案就提供了一种可以通过采集对话语音信息从而自动对智能设备进行控制的方法,对话时,通过不同拾音设备或者声纹识别,将多个正在说话的用户语音区分开,并将语音信息采集后传送到语义分析模块进行解析,语义分析模块将根据语音特点自动翻译成对应语言的文字,并将文字发送到关键词提取模块中。关键词通过和预设的相应语言的预设关键词指令库进行搜索并匹配,并将匹配成功的一系列指令发送到设备控制模块。其中,智能设备可以是显示器,显示屏等,显示器或者显示屏可以有多个。
以下结合附图,详细说明本申请各实施例提供的技术方案。
图1为本申请实施例提供的一种基于语音识别的控制方法的流程示意图。从程序角度而言,流程的执行主体可以为搭载于应用服务器的程序或应用客户端。
如图1所示,该流程可以包括以下步骤:
步骤102:获取对话语音信息。
在该步骤中,获取对话语音信息可以是实时获取的。对于采集对话语音信息的设备可以是一个,也可以是多个。当采集设备是多个的时候,可以将多个语音采集设备设置在多个不同的位置,以便于从不同角度去采集对话语音信息。
其中,对话语音信息是预设时间内的语音信息,可以包括一个人的语音信息,还可以包括两个,或者多个人的语音信息。
步骤104:对所述对话语音信息进行语音识别,获得不同用户的语音信息。
现代科学研究表明,声纹不仅具有特定性,而且有相对稳定性的特点。成年以后,人的声音可保持长期相对稳定不变。实验证明,无论讲话者是故意模仿他人声音和语气,还是耳语轻声讲话,即使模仿得惟妙惟肖,其声纹却始终不同。因此,在该步骤中,可以采用各个对话者的声纹不同来区别不同用户的语音信息,从而确定对话过程中有几个人同时发言,并将不同用户发言的语音截成相对的语音段,分别进行存储,需要注意的是,在存储语音信息时,可以将发音的时间信息相应存储。
在该步骤中,语音识别可以通过多种手段,例如:1、基于语言学和声学的方法,2、随机模型法,3、利用人工神经网络的方法,4、概率语法分析。
步骤106:对所述不同用户的语音信息进行语义分析,获得文字信息。
在该步骤中,对于不同用户的语音信息进行语义分析,把语音变为文字信息。需要注意的时候,由于不同的用户可能同时发言,会出现语音重叠的部分,此时需要根据重叠部分前后语音的语义合理推理重叠部分的语音。另外,还可以采用语音重叠技术进行语音拆分,然后再进行语义分析。
在一些情况下,语义分析可以采用现有的语义分析模块。
步骤108:提取所述文字信息中的关键词。
对于智能设备控制,往往存在一些关键的词语,如果“打开显示器”“切换屏幕”“调取xx场景”等,可以提取这些关键词,忽略一些语气助词,或者其他一些与智能设备控制无关的信息。其中,可以预先对关键词进行设定。
步骤110:在关键词指令库中对所述关键词进行匹配,根据匹配结果确定所述关键词对应的控制指令信息。
在关键词指令库中存储了关键词与控制指令的映射关系,例如,关键词和大屏幕显示场景之间的映射关系,通过关键词检索到其对应的大屏幕显示场景,从而调取相应的显示场景上屏。
步骤112:基于所述控制指令信息对设备进行控制。
基于步骤110确定的控制指令信息,可以将该控制指令信息发送给屏幕控制器来对显示屏幕进行具体的控制。
需要注意的是,该控制指令信息可以是原始的指令信息,还可以是基于控制指令信息进行的变形,如形式和格式的不同。
图1中的方法,通过提取对话信息中的控制指令,自动实时操作指定设备或程序,无需唤醒,提高用户的操作便利性。
基于图1的方法,本申请实施例还提供了该方法的一些具体实施方式,下面进行说明。
在一个或多个实施例中,步骤102中的所述对话语音信息为拾音设备发送的对话语音信息。其中,拾音设备可以为多个,不同拾音设备可以采用相同参数的拾音头,也可以采用不同参数的拾音头。可以根据拾音设备放置位置的不同而进行选择。
在一个或多个实施例中,所述对所述对话语音信息进行语音识别,获得不同用户的语音信息,具体可以包括:采用声纹识别对所述对话语音信息进行语音识别,获得不同用户的语音信息。
声纹识别是生物识别技术的一种,也称为说话人识别,包括说话人辨认和说话人确认。声纹识别就是把声信号转换成电信号,再用计算机进行识别。不同的任务和应用会使用不同的声纹识别技术,如缩小刑侦范围时可能需要辨认技术,而银行交易时则需要确认技术。
声纹识别有两个关键问题,一是特征提取,二是模式匹配。特征提取的任务是提取并选择对说话人的声纹具有可分性强、稳定性高等特性的声学或语言特征。与语音识别不同,声纹识别的特征必须是“个性化”特征,而说话人识别的特征对说话人来讲必须是“共性特征”。
对于模式识别,有以下几大类方法:
(1)模板匹配方法:利用动态时间弯折(dtw)以对准训练和测试特征序列,主要用于固定词组的应用(通常为文本相关任务);
(2)最近邻方法:训练时保留所有特征矢量,识别时对每个矢量都找到训练矢量中最近的k个,据此进行识别,通常模型存储和相似计算的量都很大;
(3)神经网络方法:有很多种形式,如多层感知、径向基函数(rbf)等,可以显式训练以区分说话人和其背景说话人,其训练量很大,且模型的可推广性不好;
(4)隐式马尔可夫模型(hmm)方法:通常使用单状态的hmm,或高斯混合模型(gmm),是比较流行的方法,效果比较好;
(5)vq聚类方法(如lbg):效果比较好,算法复杂度也不高,和hmm方法配合起来更可以收到更好的效果;
(6)多项式分类器方法:有较高的精度,但模型存储和计算量都比较大。
在一个或多个实施例中,在对所述不同用户的语音信息进行语义分析之前,获得文字信息,所述方法还可以包括:
对所述语音信息进行语种识别;
根据语种识别结果调取对应的语义分析策略;
对所述不同用户的语音信息进行语义分析,获得文字信息,具体包括:
利用所述语义分析策略对所述不同用户的语音信息进行语义分析,获得文字信息。
在一个对话中有时候可能出现不同的语言,此时在进行语义分析之前,可以对语音信息进行语种识别,然后再采用对应的语义分析策略进行分析,以便于选择合适的语义分析策略,减少工作量。这种方式,还可以支持多语言调取信号源、监控、程序或文件。
在一个或多个实施例中,在对所述不同用户的语音信息进行语义分析,获得文字信息之后,提取所述文字信息中的关键词之前,还可以包括:
获取所述文字信息的预设长度的起始字符串;
根据所述起始字符串判断所述文字信息是否用于触发控制指令;
提取所述文字信息中的关键词,具体包括:
当所述文字信息用于触发控制指令时,提取所述文字信息中的关键词。
在该实施例中,无需重复唤醒词,通过判断起始字符串来判断是否之后是交互控制指令。若语种为汉字,起始字符串如果是“打开”“监控”“调取”“切换”等等,则可以认为是用于触发控制指令。
其中,用于触发控制指令的起始字符串也可以根据控制指令进行预设和实时更新。
在一个或多个实施例中,所述控制指令信息用于调取信号源、监控、程序或文件。
在一个或多个实施例中,所述基于所述控制指令信息对设备进行控制后,所述方法还包括:当在预设时间内没有语音输入时,关闭基于控制指令信息控制设备的功能,当有语音输入时,自动唤醒基于控制指令信息控制设备的功能。
在控制设备中,可以设置一个功能,当有语音输入时,开启通过语音信息自动控制智能设备的功能,如控制智能显示器。当一段时间内没有语音输入时,可以关闭相应的功能,以防止误动作。
在一个或多个实施例中,在关键词指令库中对所述关键词进行匹配,具体可以包括:从关键词指令库中检索所述关键词对应的大屏幕显示场景,所述关键词指令库中存储关键词与大屏幕显示场景之间的映射关系。
在该实施例中,对于设备的控制可以是大屏幕,可以对大屏幕上的显示场景进行控制,此时可以在关键词指令库中存储关键词与大屏幕显示场景之间的映射关系,然后根据关键词对应的大屏幕显示场景来对大屏幕进行控制。
在一个或多个实施例中,所述确定所述关键词对应的控制指令信息后,所述基于所述控制指令信息对设备进行控制前,所述方法还包括:当所述控制指令信息为多个时,若在预设时间段内,存在相互矛盾或者完全反向的控制指令时,丢弃相互矛盾的控制指令信息。
例如,在30秒内,同一个发布人发布了两个完全相反的控制指令,或者相同的控制指令,同一个人或者不同的人,短时间内多次发布,则后面发布的控制指令可以忽略或者丢弃,即不进行处理,从而避免资源浪费。
例如,在间隔小于1s的矛盾或反向控制指令将被忽略,避免在连续输入关键词的情况下造成的系统冲突。
在一个或多个实施例中,所述控制指令信息为多个,所述基于所述控制指令信息对设备进行控制,具体可以包括:
按照执行逻辑顺序将多个所述控制指令信息进行组合;
将组合后的所述多个所述控制指令信息转化为机器控制命令;
将所述机器控制命令发送至相应设备。
基于同样的思路,本申请实施例还提供了上述方法对应的装置。图2为本申请实施例提供的对应于图1的一种基于语音识别的控制装置的结构示意图。
如图2所示,该装置可以包括:
语音获取模块202,用于获取对话语音信息;
语音识别模块204,用于对所述对话语音信息进行语音识别,获得不同用户的语音信息;
语义分析模块206,用于对所述不同用户的语音信息进行语义分析,获得文字信息;
关键词提取模块208,用于提取所述文字信息中的关键词;
关键词匹配模块210,用于在关键词指令库中对所述关键词进行匹配,根据匹配结果确定所述关键词对应的控制指令信息;
设备控制模块212,用于基于所述控制指令信息对设备进行控制。
基于同样的思路,本申请实施例还提供了一种存储介质,其上存储有计算机可读指令,所述计算机可读指令可被处理器执行以实现上述的基于语音识别的控制方法。
最后应说明的是:以上各实施例仅用以说明本申请的技术方案,而非对其限制;尽管参照前述各实施例对本申请进行了详细的说明,本领域的普通技术人员应当理解:其依然可以对前述各实施例所记载的技术方案进行修改,或者对其中部分或者全部技术特征进行等同替换;而这些修改或者替换,并不使相应技术方案的本质脱离本申请各实施例技术方案的范围。
- 还没有人留言评论。精彩留言会获得点赞!