基于深度学习网络的麦克风信号回声消除模型构建方法
1.本发明涉及麦克风回声消除技术领域,具体涉及基于深度学习网络的麦克风信号回声消除模型构建方法。
背景技术:
2.语音是现代通信的重要载体,随着远程工作的日益普及,电话会议系统的使用也显著增加,回声引起的通话质量下降是语音和视频通话语音质量降低的主要原因之一,虽然基于数字信号处理的声学回aec模型已经被用于在通话中,但在实验室仿真测试环境以外,它们的性能可能会降低,特别是针对部分双讲的场景下。
3.由于有一个代表回声源的远端参考信号,所以传统方法中,自适应滤波器是用于回声消除,常用的自适应滤波算法包括最小均方算法lms、归一化最小均方算法等,然而,即便经过自适应滤波,通常仍然会有一些残余的回声,虽然在大多数情况下,它的能量比语音要小得多,但它也会被人耳所感知到,这些残余回声包括由于估计偏差而引入的线性残余,和由音频设备产生的非线性残余分量。对于线性残余,可以通过参数更多的滤波器进一步抑制,但对于非线性残余,传统的自适应方法很难有效处理。
技术实现要素:
4.为解决上述问题,本发明联合归一化最小均方算法与基于crn模型的深度学习网络实时回声消除算法,提出基于深度学习网络的麦克风信号回声消除模型构建方法。
5.为了达到上述目的,本发明所采用的技术方案是:
6.基于深度学习网络的麦克风信号回声消除模型构建方法,包括以下步骤:
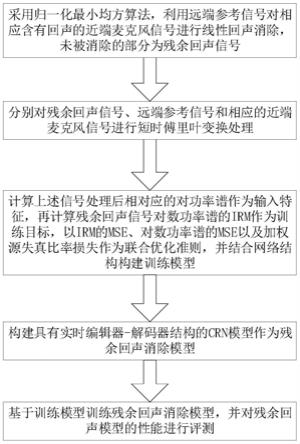
7.步骤(a),采用归一化最小均方算法,并利用代表回声源的远端参考信号对相应含有回声的近端麦克风信号进行线性回声消除,而未被消除的部分回声为残余回声信号;
8.步骤(b),分别对残余回声信号、远端参考信号和相应的近端麦克风信号进行短时傅里叶变换处理;
9.步骤(c),计算上述信号经短时傅里叶变换处理后相应的对数功率谱作为输入特征,再计算残余回声信号对数功率谱的理想比率掩模irm作为训练目标,以irm的均方误差mse、对数功率谱的均方误差mse以及加权源失真比率损失作为联合优化准则,并结合网络结构构建训练模型;
10.步骤(d),将经过归一化最小均方算法处理的近端麦克风信号和远端参考信号作为输入,构建具有实时编码器-解码器结构的crn模型作为残余回声消除模型;
11.步骤(e),基于训练模型训练残余回声消除模型,并对残余回声消除模型的性能进行评测。
12.前述的基于深度学习网络的麦克风信号回声消除模型构建方法,步骤(a)中所述归一化最小均方算法权重的迭代更新计算方式如公式(1)所示:
[0013][0014]
公式(1)中,为算法权重,e(n)为误差信号,即近端麦克风信号和算法输出之间的差值,x(n)为远端参考信号,x
t
(n)的上标t表示转置,表示n+1时刻估计的算法权重。
[0015]
前述的基于深度学习网络的麦克风信号回声消除模型构建方法,步骤(c)中所述理想比率掩模irm利用干净语音信号和干扰音信号幅值信息,计算干净语音信号和干扰信号之间的能量比,获得介于0到1之间的一个掩膜,用于反映各个时频单元上干净语音信号和干扰信号的比例。
[0016]
前述的基于深度学习网络的麦克风信号回声消除模型构建方法,步骤(c)中所述加权源失真比率损失用于反映语音失真的带权重损失,且对不同尺度的语音幅度敏感。
[0017]
前述的基于深度学习网络的麦克风信号回声消除模型构建方法,步骤(d)中所述crn模型构成包括4层卷积解码器、4层反卷积解码器和1层门控循环单元网络构成。
[0018]
前述的基于深度学习网络的麦克风信号回声消除模型构建方法,所述理想比率掩模irm计算方式如公式(2)所示:
[0019][0020]
公式(2)中,s表示干净语音信号的幅值谱,n表示干扰信号的幅值谱,β为可调节尺度因子,β取值为0.5。
[0021]
前述的基于深度学习网络的麦克风信号回声消除模型构建方法,所述加权源失真比率损失的计算方式如公式(3)、公式(4)所示:
[0022][0023][0024]
公式(3)与公式(4)中,loss
sdr
表示源失真比率损失函数,loss
wsdr
表示加权源失真比率损失函数,y
clean
表示残余回声信号,y
est
表示预估残余回声信号,x表示原始输入信号,所述预估残余回声信号为irm作用于近端麦克风信号获得。
[0025]
前述的基于深度学习网络的麦克风信号回声消除模型构建方法,所述门控循环单元网络的输入维度为残余回声信号和远端参考信号的对数功率谱,输入维度为f
×
t
×
2;
[0026]
其中f为频率维度,通过计算512点stft得到f的值为257,t为时间维度,选取窗长为512点的hanning窗,重叠长度为256点。
[0027]
前述的基于深度学习网络的麦克风信号回声消除模型构建方法,步骤(e),训练残余回声消除模型,并对残余回声消除模型的性能进行评测,其中在残余回声消除模型的训练阶段,设置门控循环单元gru网络d输入维度中t值为200帧,测试阶段使用完整音频的帧长,编码器通过设置卷积步长为2对频率维度下采样提取音频特征,其采样过程中,设置卷
积核大小为3
×
1用于保证算法的实时性,每一层卷积层还包括一层ln层和relu非线性层,经过4层编码器,通道数由2逐层扩展至16、16、32、32,频率维度f由257逐层降至129、65、33、17,解码器通过与解码器相同的反卷积层使得频率维度f逐渐恢复,并将通道逐渐收缩,最终生成与输入近端麦克风信号对数谱维度相同的irm,通过跳跃连接将编码器与解码器对应层之间的输出与输入在通道维度上进行堆叠,融合浅层与深层的信息,由于irm的值域为[0,1],则最后一层的激活函数选择sigmoid。
[0028]
前述的基于深度学习网络的麦克风信号回声消除模型构建方法,步骤(e),训练残余回声消除模型,并对残余回声消除模型的性能进行评测,其中在残余回声消除模型评测阶段,评测指标为评估pesq和erle的数值,pesq的得分范围为-0.5至4.5,pesq的得分与语音质量成正比,erle为回声返回衰减增益用于在单讲条件下反映麦克风信号能量与回声消除后剩余能量的比值,erle值与回声消除效果成正比。
[0029]
本发明的有益效果是:本发明采用归一化最小均方算法消除由多路径和房间声学冲激响应引入的线性回声,然后利用残余回声信号和近端麦克风信号计算irm作为训练目标,并将经过归一化最小均方算法处理的近端麦克风信号和远端参考信号作为输入,构建具有实时编码器-解码器结构的crn模型;最后,将预估残余信号从近端麦克风信号中减去重构语音,本发明联合归一化最小均方算法与基于crn模型的深度学习网络实时回声消除算法,可以提高麦克风回声消除的性能,具有良好的应用前景。
附图说明
[0030]
图1是本发明基于深度学习网络的麦克风信号回声消除模型构建方法的流程图。
具体实施方式
[0031]
下面将结合说明书附图,对本发明作进一步的说明。
[0032]
如图1所示,本发明基于深度学习网络的麦克风信号回声消除模型构建方法,包括以下步骤:
[0033]
步骤(a),采用归一化最小均方算法,并利用代表回声源的远端参考信号对相应含有回声的近端麦克风信号进行线性回声消除,而未被消除的部分回声为残余回声信号;
[0034]
前述的步骤(a)中归一化最小均方算法权重的迭代更新计算方式如公式(1)所示:
[0035][0036]
公式(1)中,为算法权重,e(n)为误差信号,即近端麦克风信号和算法输出之间的差值,x(n)为远端参考信号,x
t
(n)的上标t表示转置,表示n+1时刻估计的算法权重;
[0037]
步骤(b),分别对残余回声信号、远端参考信号和相应的近端麦克风信号进行短时傅里叶变换处理;
[0038]
步骤(c),计算上述信号经短时傅里叶变换处理后相应的对数功率谱作为输入特征,再计算残余回声信号对数功率谱的理想比率掩模irm作为训练目标,以irm的均方误差mse、对数功率谱的均方误差mse以及加权源失真比率损失作为联合优化准则,并结合网络
结构构建训练模型,联合优化指联合多种损失函数对模型进行优化,利用多个学习准则提高模型性能;
[0039]
前述的步骤(c)中理想比率掩模irm利用干净语音信号和干扰音信号幅值信息,计算干净语音信号和干扰信号之间的能量比,获得介于0到1之间的一个掩膜,用于反映各个时频单元上干净语音信号和干扰信号的比例;
[0040]
其中,理想比率掩模irm计算方式如公式(2)所示:
[0041][0042]
公式(2)中,s表示干净语音信号的幅值谱,n表示干扰信号的幅值谱,β为可调节尺度因子,β取值为0.5;
[0043]
前述的步骤(c)中加权源失真比率损失用于反映语音失真的带权重损失,且对不同尺度的语音幅度敏感加权源失真比率损失表示为weighted-sdr loss训练模型;
[0044]
其中,加权源失真比率损失的计算方式如公式(3)、公式(4)所示:
[0045][0046][0047]
公式(3)与公式(4)中,loss
sdr
表示源失真比率损失函数,loss
wsdr
表示加权源失真比率损失函数,y
clean
表示残余回声信号,y
est
表示预估残余回声信号,x表示原始输入信号,预估残余回声信号为irm作用于近端麦克风信号获得,需要进行逆短时傅里叶变换得到最终的时域波形;
[0048]
步骤(d),将经过归一化最小均方算法处理的近端麦克风信号和远端参考信号作为输入,构建具有实时编码器-解码器结构的crn模型作为残余回声消除模型;
[0049]
前述的步骤(d)中crn模型构成包括4层卷积解码器、4层反卷积解码器和1层门控循环单元网络构成;
[0050]
具体的,门控循环单元网络的输入维度为残余回声信号和远端参考信号的对数功率谱,输入维度为f
×
t
×
2;
[0051]
其中f为频率维度,通过计算512点stft得到f的值为257,t为时间维度,选取窗长为512点的hanning窗,重叠长度为256点;
[0052]
步骤(e),基于训练模型训练残余回声消除模型,并对残余回声消除模型的性能进行评测;
[0053]
前述的步骤(e)中在残余回声消除模型的训练阶段,设置门控循环单元gru网络d输入维度中t值为200帧,测试阶段使用完整音频的帧长,编码器通过设置卷积步长为2对频率维度下采样提取音频特征,其采样过程中,设置卷积核大小为3
×
1用于保证算法的实时性,每一层卷积层还包括一层ln层和relu非线性层,经过4层编码器,通道数由2逐层扩展至16、16、32、32,频率维度f由257逐层降至129、65、33、17,解码器通过与解码器相同的反卷积层使得频率维度f逐渐恢复,并将通道逐渐收缩,最终生成与输入近端麦克风信号对数谱维
度相同的irm,通过跳跃连接将编码器与解码器对应层之间的输出与输入在通道维度上进行堆叠,融合浅层与深层的信息,由于irm的值域为[0,1],则最后一层的激活函数选择sigmoid;
[0054]
前述的步骤(e)中在残余回声消除模型评测阶段,评测指标为评估pesq和erle的数值,pesq的得分范围为-0.5至4.5,pesq的得分与语音质量成正比,erle为回声返回衰减增益用于在单讲条件下反映麦克风信号能量与回声消除后剩余能量的比值,erle值与回声消除效果成正比。
[0055]
为充分测试残余回声消除模型性能,实验设置在icassp 2021aec challenge数据集上进行,训练数据集提供了10000条包含单讲、双讲以及多种非线性失真条件下的样本,每个样本包括远端语音、回声信号、近端语音和近端麦克风信号片段,其中,训练集选择9000条样本,测试集分别选择训练集中的500条双讲样本和500条单讲样本计算指标,数据集使用librivox数据集中提取的12000条100小时的音频语音,并生成远端和近端信号,回声信号随机选择不同的房间脉冲响应产生,部分样本中,远端信号会由一个非线性函数处理来模拟扬声器的失真,远端信号从-10db到10db均匀采样的信号/回声比与近端信号合成,如表1所示:
[0056]
表1
[0057][0058]
其中,single表示单讲样本,double为双讲样本,nearend mic表示近端麦克风信号;
[0059]
数据表示不同算法在单讲和双讲下的pesq和erle数值,单讲的理想干净语音是静音,因而无法计算单讲pesq,故采用/,另一方面,erle只适用于单讲条件,因而不计算双讲条件下的erle,故采用/;
[0060]
根据表1中的数据,结合归一化最小均方算法与crn模型进行回声消除,获得的pesq和erle数值最高,则语音质量以及回声消除效果最好。
[0061]
综上,本发明采用归一化最小均方算法消除由多路径和房间声学冲激响应引入的线性回声,然后利用残余回声信号和近端麦克风信号计算irm作为训练目标,并将经过归一化最小均方算法处理的近端麦克风信号和远端参考信号作为输入,构建具有实时编码器-解码器结构的crn模型;最后,将预估残余信号从近端麦克风信号中减去重构语音,本发明联合归一化最小均方算法与基于crn模型的深度学习网络实时回声消除算法,可以提高麦克风回声消除的性能,具有良好的应用前景。
[0062]
以上显示和描述了本发明的基本原理、主要特征及优点,本行业的技术人员应该了解,本发明不受上述实施例的限制,上述实施例和说明书中描述的只是说明本发明的原理,在不脱离本发明精神和范围的前提下,本发明还会有各种变化和改进,这些变化和改进都落入要求保护的本发明范围内。本发明要求保护范围由所附的权利要求书及其等效物界定。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1