用于改进的关键词检测的技术的制作方法
用于改进的关键词检测的技术
本技术是pct国际申请号为pct/us2017/047389、国际申请日为2017年08月17日、进入中国国家阶段的申请号为201780051396.4,题为“用于改进的关键词检测的技术”的申请的分案申请。相关美国专利申请的交叉引用
1.本技术要求于2016年9月23日提交的名称为“technologies for improved keyword spotting(用于改进的关键词检测的技术)”的美国发明专利申请序列第15/274,498号的优先权。
背景技术:
2.计算设备的自动语音识别具有广泛的应用,包括向计算设备提供口头命令或口述文档(诸如口述医疗记录中的条目)。在某些情况下,可能需要关键词检测,例如,如果正在搜索一段语音数据是否存在特定词或一组词。
3.关键词检测通常通过执行语音识别算法来完成,该算法被定制为仅匹配关键词并忽略或拒绝关键词列表之外的词。关键词检测器的输出可以仅是匹配的关键词,没有为不匹配关键词的语音数据提供任何输出。
附图说明
4.在附图中通过示例的方式而非限制的方式示出了本文中所描述的概念。为了说明的简单和清晰起见,在附图中所示出的要素不一定按比例绘制。在认为适当的情况下,在附图当中已经重复了参考标记以表示相应或相似的元件。
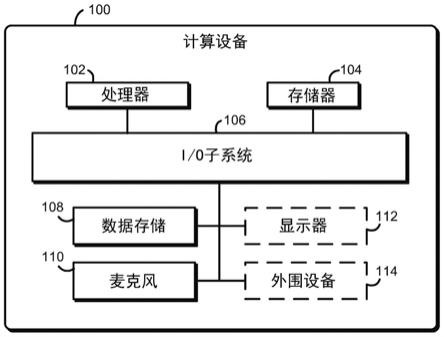
5.图1是用于关键词检测的计算设备的至少一个实施例的简化框图;
6.图2是可由图1的计算设备建立的环境的至少一个实施例的框图;
7.图3是用于训练用于关键词检测的自动语音识别算法的方法的至少一个实施例的简化流程图,该算法可以由图1的计算设备执行;以及
8.图4是一种可以由图1的计算设备执行的用于具有关键词定位的自动语音识别的方法的至少一个实施例的简化流程图。
具体实施方式
9.虽然本发明的概念容易得出多种修改和替代形式,但通过附图中示例的方式示出本发明的特定实施例,并在本文中进行详细描述。然而,应当理解的是,并不旨在将本公开的概念限制于所公开的特定形式,相反,本发明旨在涵盖与本公开和所附权利要求书一致的所有修改、等效物以及替代物。
10.说明书中对“一个实施例”、“实施例”、“示意性实施例”等等的引用表示所描述的实施例可包括特定特征、结构或特性,但是每个实施例可以包括或不必包括特定的特征、结构或特性。此外,此类短语不一定是指同一实施例。进一步地,当结合实施例来描述特定特征、结构或特性时,应当认为,无论是否明确地描述,结合其他实施例来实现此类特征、结构
或特性在本领域的技术人员的知识范围内。另外,应当认识到,“a、b和c中的至少一者”形式的列表内所包括的项可以指(a);(b);(c);(a和b);(a和c);(b和c);或(a、b、和c)。类似地,以“a、b或c中的至少一者”的形式来列出的项可以指(a);(b);(c);(a和b);(b和c);(a或c)或(a、b和c)。
11.在一些情况下,可以在硬件、固件、软件或其任何组合中实现所公开的实施例。所公开的实施例还可以被实现为由一种或多种瞬态或非瞬态机器可读(例如,计算机可读)存储介质承载或存储在其上的指令,所述指令可以由一个或多个处理器读取和执行。机器可读存储介质可以体现为任何存储设备、机制、或者用于以机器可读的形式(例如,易失性或非易失性存储器,媒体盘或其他媒体设备)存储或传输信息的其他物理结构。
12.在附图中,可以以特定的布置和/或排序示出一些结构或方法特征。然而,应当理解的是,可能不需要这样特定的布置和/或排序。相反,在一些实施例中,这类特征可以以不同于说明性附图中所示的方式和/或顺序来布置。另外,在特定的附图中包括结构性特征或方法特征并不意味着暗示在所有实施例中都需要这种特征,并且在某些实施例中,可以不包括这种特征或者这种特征可以与其他特征相组合。
13.现参见图1,一种说明性的计算设备100包括麦克风108,该麦克风108用于捕获来自计算设备100的用户的语音数据。计算设备100使用统计语言模型对语音数据执行自动语音识别算法,该统计语言模型已经被修改以用于优先匹配关键词列表中的词。自动语音识别算法的输出转录本包括语音数据中的所有转录的词,包括与关键词匹配的词以及与关键词不匹配的词。然后,计算设备100基于输出转录本采取动作,例如,通过执行用户给出的命令,基于关键词解析输出转录本,或者基于所匹配的关键词确定用户的意图。
14.说明性计算设备100可以体现为能够执行本文所描述的功能的任何类型的计算设备。例如,计算设备100可以体现为或者另外包括在(但不限于)以下设备中:智能电话、蜂窝电话、可穿戴计算机、嵌入式计算系统、芯片上系统(soc)、平板计算机、笔记本计算机、膝上型计算机、服务器计算机、台式计算机、手持设备、消息传送设备、相机设备、多处理器系统、基于处理器的系统、消费电子设备和/或任何其他计算设备。
15.说明性计算设备100包括处理器102、存储器104、输入/输出(i/o)子系统106、数据存储108和麦克风110。在一些实施例中,计算设备100的一个或多个说明性组件可以结合在另一组件中,或者以其他方式形成另一组件的一部分。例如,在一些实施例中,存储器104或其多个部分可以结合在处理器102中。
16.处理器102可以体现为能够执行本文中所描述的功能的任何类型的处理器。例如,处理器102可以体现为(多个)单核或多核处理器、单插槽或多插槽处理器、数字信号处理器、图形处理器、微控制器或者其他处理器或处理/控制电路。类似地,存储器104可以体现为能够执行本文中所描述的功能的任何类型的易失性或非易失性存储器或数据存储设备。在操作中,存储器104可存储在计算设备100操作期间使用的各种数据和软件,如操作系统、应用、程序、库和驱动程序。存储器104经由i/o子系统106通信地耦合至处理器102,所述i/o子系统106可以体现为用于促进与计算设备100的处理器102、存储器104、以及其他组件的输入/输出操作的电路系统和/或组件。例如,i/o子系统106可以体现为或以其他方式包括用于促进输入/输出操作的存储器控制器中枢、输入/输出控制中枢、固件设备、通信链路(即,点到点链路、总线链路、线、电缆、光导、印刷电路板迹线等)和/或其他组件和子系统。
在一些实施例中,i/o子系统106可以形成芯片上系统(soc)的一部分并且可以与计算设备100的处理器102、存储器104以及计算设备100的其他组件一起结合在单个集成电路芯片上。
17.数据存储108可以体现为被配置用于对数据进行短期或者长期存储的任何类型的一个或多个设备。例如,数据存储设备108可以包括任何一个或多个存储器设备和电路、存储器卡、硬盘驱动器、固态驱动器或者其他数据存储设备。
18.麦克风110可以体现为能够将声音转换为电信号的任何类型的设备。麦克风110可以基于任何类型的合适的声音捕获技术,例如电磁感应、电容变化和/或压电。
19.当然,在一些实施例中,计算设备100可以包括通常在计算设备100中找到的附加组件,诸如显示器112和/或一个或多个外围设备114之类的附加组件。外围设备114可以包括键盘、鼠标、通信电路等。
20.显示器112可以体现为可以向计算设备100的用户显示信息的任何类型的显示器,例如液晶显示器(lcd)、发光二极管(led)显示器、阴极射线管(crt)显示器、等离子显示器、图像投影仪(例如,2d或3d)、激光投影仪、触摸屏显示器、抬头显示器和/或其他显示技术。
21.现参见图2,在使用中,计算设备100可以建立环境200。说明性环境200包括自动语音识别算法训练器202、语音数据捕获器204、自动语音识别器206、语音解析器208和辅助代理210。环境200的各种组件可以被体现为硬件、固件、软件或其组合。这样,在一些实施例中,环境200的组件中的一个或多个可以体现为电气设备的电路系统或集合(例如,自动语音识别算法训练器电路202、语音数据捕获器电路204、自动语音识别器电路206等)。
22.应当理解,在这样的实施例中,自动语音识别算法训练器电路202、语音数据捕获器电路204、自动语音识别器电路206等可以形成处理器102、i/o子系统106、麦克风110和/或计算设备100的其他组件中的一个或多个的一部分。另外,在一些实施例中,说明性组件中的一个或多个可以形成另一个组件的一部分和/或说明性组件中的一个或多个可以彼此独立。此外,在一些实施例中,环境200的组件中的一个或多个可以体现为虚拟化硬件组件或模拟架构,该虚拟化硬件组件或模拟架构可以由处理器102或计算设备100的其他组件建立和维护。
23.自动语音识别算法训练器202被配置成训练自动语音识别算法。在说明性实施例中,自动语音识别算法训练器202获取被标记的训练数据(即,具有相应的转录本的训练语音数据),该被标记的训练数据用于训练隐马尔可夫模型并生成声学模型。在一些实施例中,训练数据可以是来自特定领域(诸如在医学或法律领域)的数据,并且一些或所有关键词可以对应于来自该领域的术语。说明性自动语音识别算法采用声学模型以用于将语音数据与音素匹配,并且还采用统计语言模型,该模型用于基于不同词的序列(诸如,不同长度的n元语法(例如,一元语法、二元语法、二元语法))的使用频率的相对可能性将语音数据和对应的音素与词匹配。说明性统计语言模型是大词汇量语言模型,并且可以包括多于、少于1,000、2,000、5,000、10,000、20,000、50,000、100,000、200,000、500,000和1,000,000个词或是1,000、2,000、5,000、10,000、20,000、50,000、100,000、200,000、500,000和1,000,000个词中的任何一个。在说明性实施例中,自动语音识别算法训练器202包括统计语言关键词增强器214,该关键词增强器214被配置为利用关键词语言模型来增强统计语言模型,该关键词语言模型使用第二隐马尔可夫模型来匹配关键词列表中的词。统计语言关键词增强器
214可以通过在统计语言模型和关键词语言模型之间执行线性内插来增强统计语言模型。在说明性实施例中,自动语音识别算法训练器202修改大词汇量语言模型以用于当语音数据能够合理匹配统计语言模型中的关键词之一或一些相似词中的一个词时,优先匹配关键词而不是那些相似词。为此,自动语音识别算法训练器202对关键词进行加权,对关键词的加权要高于大词汇量语言模型的对应词的权重。关键词可以包括关键短语,该关键短语是多于一个词,并且自动语音识别算法可以将关键短语视为单个词(即使它们不止一个词)。关键词的数量可以多于、少于1、2、5、10、20、50、100、200、500、1000、2000和5000个词或短语或者是1、2、5、10、20、50、100、200、500、1000、2000和5000个词或短语中的任何一个。
24.在其他实施例中,替代具有相应的不同语音识别训练过程的隐马尔可夫模型或者除了具有相应的不同语音识别训练过程的隐马尔可夫模型之外,可以使用不同的语音识别算法。例如,语音识别算法可以基于神经网络,包括深度神经网络和/或递归神经网络。应当理解,在一些实施例中,计算设备100可以接收已经由不同计算设备训练的自动语音识别算法的一些参数或全部参数,并且不需要自行执行一些或全部训练。
25.语音数据捕获器204被配置成使用麦克风110捕获语音数据。语音数据捕获器204可以连续地、不断地、周期性地或根据用户的命令(诸如用户按下按钮以开始语音识别)捕获语音数据。
26.自动语音识别器206被配置成执行自动语音识别算法,该自动语音识别算法由自动语音识别算法训练器202对语音数据进行训练。自动语音识别器206产生输出转录本,以供例如计算设备100的应用使用,该输出转录本包括关键词列表中存在的词以及关键词列表中不存在的词两者。在说明性实施例中,由自动语音识别器206产生的输出转录本包括匹配的各个关键词以及单独的完整抄本两者。在一些实施例中,输出转录本可以仅包括转录文本,而没有哪些词是关键词的任何特定指示。
27.语音解析器208被配置成解析输出转录本以基于特定应用确定语义含义。在一些实施例中,语音解析器208可以使用匹配的关键词来确定输出转录本的一部分的上下文。例如,在一个实施例中,用户可以将条目口述至医疗记录中,并且可以说,“根据2015年10月20日的过敏反应,向john smith开出10毫升处方,保险id:7503986,索赔号:450934。”匹配的关键词可以是“处方”、“保险id”和“索赔id”。语音解析器208可以使用匹配的关键词来确定输出转录本的每个部分的语义上下文,并确定医疗条目的参数,例如处方(,10ml)、保险id(7503986)、索赔id(450934)等。
28.辅助代理210被配置成用于执行与计算设备100的用户的对话以辅助某些任务。辅助代理210包括信度状态管理器216,该信度状态管理器216存储与用户和计算设备100之间的对话的当前状态有关的信息,诸如用户的当前讨论主题或当前意图之类的信息。信度状态管理器216包括关键词分析器218。当输出转录本与关键词匹配时,关键词分析器218可以响应于匹配该关键词而更新当前信度状态,并且可以在不等待下一个转录词的情况下这样做。在说明性实施例中,关键词分析器218可查阅先前的转录,并更新和校正任何歧义(诸如通过查阅自动语音识别算法的词网格(word lattice)并基于关键词的存在搜索可能更适合的匹配)。
29.现在参见图3,在使用中,计算设备100可以执行用于训练自动语音识别算法的方
法300。方法300在框302中开始,其中计算设备训练自动语音识别算法。在说明性实施例中,计算设备100在框304中使用隐马尔可夫模型训练声学模型,并在框306中训练统计语言模型。基于被标记的训练数据完成训练。在一些实施例中,在框308中,计算设备100可以利用领域专用的训练数据(诸如来自医学或法律领域的数据)来训练自动语音识别算法。除了训练基于隐马尔可夫模型的算法之外或代替训练基于隐马尔可夫模型的算法,在一些实施例中,计算设备100可以在框310中训练基于神经网络的自动语音识别算法。
30.在框312中,计算设备100用关键词增强语言模型。在说明性实施例中,在框314中,计算设备100通过在统计语言模型和关键词语言模型之间进行内插来这样做。
31.现在参见图4,在使用中,计算设备100可以执行用于执行自动语音识别算法的方法400。该方法在框402中开始,其中计算设备100判定是否要识别语音。计算设备100可以连续地、不断地,周期性地和/或当计算设备100的用户指示时执行语音识别。在一些实施例中,计算设备100可以使用语音检测算法连续地监视语音的存在,并且当语音检测算法检测到语音时,执行语音识别。如果计算设备决定不执行语音识别,则方法400循环回到框402。如果计算设备100判定执行语音识别,则方法400前进到框404。
32.在框404中,计算设备100捕获来自麦克风110的语音数据。应当理解,在一些实施例中,语音数据可以替代地由不同的计算设备捕获,并且通过一些通信手段(如互联网)被发送到计算设备100。
33.在框406中,计算设备100对捕获到的语音数据执行自动语音识别。计算设备100在框408中基于声学模型识别语音数据的音素,并且在框410中基于统计语言模型识别词和关键词。
34.在框412中,计算设备100生成输出转录本。在说明性实施例中,输出转录本包括匹配的各个关键词以及单独的完整转录本两者。在一些实施例中,输出转录本可以仅包括转录文本,而没有哪些词是关键词的任何特定指示。然后,输出转录本可由计算设备100进一步处理或使用(诸如通过提供给计算设备100的应用)。
35.在框414中,计算设备1000解析输出转录本。在框416中,计算设备100基于识别的关键词来标识输出转录本的一部分的上下文。
36.在框418中,在一些实施例中,计算设备100可以响应于匹配关键词来更新辅助代理的信度状态。在说明性实施例中,计算设备100可查阅与用户先前的对话的转录,并更新和校正任何歧义(诸如通过查阅自动语音识别算法的词网格并基于关键词的存在搜索可能更适合的匹配)。在一些实施例中,计算设备100可以在不等待下一个转录词的情况下更新当前信度状态,即使计算设备100的典型行为是在对输出转录采取任何操作之前等待下一个完整句子、下一个静默和/或类似情况。示例
37.以下提供了本文中所公开的设备、系统及方法的说明性示例。所述设备、系统及方法的实施例可以包括以下所描述的示例中的任何一个或多个、以及任何组合。
38.示例1包括一种用于自动语音识别的计算设备,该计算设备包括:自动语音识别算法训练器,该自动语音识别算法训练器用于获取统计语言模型以用于自动语音识别算法,其中统计语言模型包括大词汇量语言模型,该大词汇量语言模型已被修改用于优先匹配多个关键词中存在的词;语音数据捕获器,该语音数据捕获器用于接收计算设备的用户的语
音数据;以及自动语音识别器,该自动语音识别器用于对语音数据执行自动语音识别算法,以产生输出转录本,其中输出转录本包括多个关键词中的一个或多个关键词和不在多个关键词中的一个或多个词。
39.示例2包括示例1的主题,并且其中,已经被修改以用于优先匹配多个关键词中存在的词的该大词汇量语言模型包括第一隐马尔可夫模型和第二隐马尔可夫模型,该第一隐马尔可夫模型用于匹配大词汇量中存在的词,该第二隐马尔可夫模型用于匹配多个关键词中存在的词。
40.示例3包括示例1和2中任一项的主题,并且其中,多个关键词的权重高于统计语言模型的其余部分的对应权重,使得统计语言模型优先匹配多个关键词。
41.示例4包括示例1-3中任一项的主题,并且其中,统计语言模型由大词汇量语言模型和关键词语言模型的线性内插形成。
42.示例5包括示例1-4中任一项的主题,并且其中,多个关键词包括少于五十个词,并且大词汇量包括多于一千个词。
43.示例6包括示例1-5中任一项的主题,并且其中,用于接收语音数据包括利用计算设备的麦克风捕获语音数据。
44.示例7包括示例1-6中任一项的主题,并且还包括语音解析器,该语音解析器用于基于所述一个或多个关键词来标识输出转录本的一部分的上下文;以及根据输出转录本的部分的上下文来解析输出转录本。
45.示例8包括示例1-7中任一项的主题,并且其中,用于获取统计语言模型以用于自动语音识别算法包括:用于针对大词汇量来训练统计语言模型并且利用关键词语言模型来增强统计语言模型,使得统计语言模型优先匹配多个关键词。
46.示例9包括示例1-8中任一项的主题,并且其中,已经使用领域专用的训练数据来训练统计语言模型。
47.示例10包括示例1-9中任一项的主题,并且进一步包括:辅助代理,该辅助代理用于响应于一个或多个关键词的匹配来更新辅助代理的信度状态。
48.示例11包括示例1-10中任一项的主题,并且其中,用于响应于匹配一个或多个关键词来更新信度状态包括:在不等待语音数据的下一个被识别的词的情况下更新交互上下文。
49.示例12包括示例1-11中任一项的主题,并且其中,用于响应于匹配一个或多个关键词来更新信度状态包括:搜索自动语音识别算法的词网格并基于一个或多个关键词找到词网格与语音数据的更好匹配。
50.示例13包括示例1-12中任一项的主题,并且其中多个关键词中的至少一个关键词是包括两个或更多个词的关键短语。
51.示例14包括一种由计算设备进行自动语音识别的方法,该方法包括:由计算设备获取统计语言模型以用于自动语音识别算法,其中统计语言模型包括大词汇量语言模型,该大词汇量语言模型已被修改用于优先匹配多个关键词中存在的词;由计算设备接收计算设备的用户的语音;以及由该计算设备对语音数据执行自动语音识别算法,以产生输出转录本,其中输出转录本包括多个关键词中的一个或多个关键词和不在多个关键词中的一个或多个词。
52.示例15包括示例14的主题,并且其中,已经被修改以用于优先匹配多个关键词中存在的词的该大词汇量语言模型包括第一隐马尔可夫模型和第二隐马尔可夫模型,该第一隐马尔可夫模型用于匹配大词汇量中存在的词,该第二隐马尔可夫模型用于匹配多个关键词中存在的词。
53.示例16包括示例14和15中任一项的主题,并且其中,多个关键词的权重高于统计语言模型的其余部分的对应权重,使得统计语言模型优先匹配多个关键词。
54.示例17包括示例14-16中任一项的主题,并且其中,统计语言模型由大词汇量语言模型和关键词语言模型的线性内插形成。
55.示例18包括示例14-17中任一项的主题,并且其中,多个关键词包括少于五十个词,并且大词汇量包括多于一千个词。
56.示例19包括示例14-18中任一项的主题,并且其中,接收语音数据包括:利用计算设备的麦克风捕获语音数据。
57.示例20包括示例14-19中任一项的主题,并且进一步包括:由计算设备并且基于一个或多个关键词标识输出转录本的一部分的上下文;以及由计算设备基于输出转录本的部分的上下文来解析输出转录本。
58.示例21包括示例14-20中任一项的主题,并且其中,获取统计语言模型以用于自动语音识别算法包括:针对大词汇量训练统计语言模型并利用关键词语言模型来增强统计语言模型使得统计语言模型优先匹配多个关键词。
59.示例22包括示例14-21中任一项的主题,并且其中,已经使用领域专用的训练数据来训练统计语言模型。
60.示例23包括示例14-22中任一项的主题,并且进一步包括:由计算设备的辅助代理响应于匹配一个或多个关键词而更新辅助代理的信度状态。
61.示例24包括示例14-23中任一项的主题,并且其中,由辅助代理响应于匹配一个或多个关键词而更新信度状态包括:由辅助代理在不等待语音数据的下一个被识别的词的情况下更新交互上下文。
62.示例25包括示例14-24中任一项的主题,并且其中,由辅助代理响应于匹配一个或多个关键词而更新信度状态包括:搜索自动语音识别算法的词网格并且基于一个或多个关键词找到词网格与语音数据的更好匹配。
63.示例26包括示例14-25中任一项的主题,并且其中多个关键词中的至少一个关键词是包括两个或更多个词的关键短语。
64.示例27包括一种或多种计算机可读介质,该可读介质包括存储于其上的多条指令,当所述指令被执行时,使得计算设备执行权利要求14-26中任一项的方法。
65.示例28包括一种用于具有高精度时间戳的传感器值的低功率捕获的计算设备,该计算设备包括:用于获取统计语言模型以用于自动语音识别算法的装置,其中统计语言模型包括大词汇量语言模型,该大词汇量语言模型已经被修改以用于优先匹配多个关键词中存在的词;用于接收计算设备的用户的语音数据的装置;以及用于对语音数据执行自动语音识别算法以产生输出转录本的装置,其中输出转录本包括多个关键词中的一个或多个关键词以及不在多个关键词中的一个或多个词。
66.示例29包括示例28的主题,并且其中,已经被修改以用于优先匹配多个关键词中
存在的词的该大词汇量语言模型包括第一隐马尔可夫模型和第二隐马尔可夫模型,该第一隐马尔可夫模型用于匹配大词汇量中存在的词,该第二隐马尔可夫模型用于匹配多个关键词中存在的词。
67.示例30包括示例28和29中任一项的主题,并且其中,多个关键词的权重高于统计语言模型的其余部分的对应权重,使得统计语言模型优先匹配多个关键词。
68.示例31包括示例28-30中任一项的主题,并且其中,统计语言模型由大词汇量语言模型和关键词语言模型的线性内插形成。
69.示例32包括示例28-31中任一项的主题,并且其中,多个关键词包括少于五十个词,并且大词汇量包括多于一千个词。
70.示例33包括示例28-32中任一项的主题,并且其中,用于接收语音数据的装置包括:用于利用计算设备的麦克风捕获语音数据的装置。
71.示例34包括示例28-33中任一项的主题,并且进一步包括用于基于所述一个或多个关键词来标识输出转录本的一部分的上下文的装置;以及用于基于输出转录本的部分的上下文来解析输出转录本的装置。
72.示例35包括示例28-34中任一项的主题,并且其中,用于获取统计语言模型以用于自动语音识别算法的装置包括:用于针对大词汇量训练统计语言模型的装置,以及用于利用关键词语言模型来增强统计语言模型使得统计语言模型优先匹配多个关键词的装置。
73.示例36包括示例28-35中任一项的主题,并且其中,已经使用领域专用的训练数据来训练统计语言模型。
74.示例37包括示例28-36中任一项的主题,并且进一步包括:用于由计算设备的辅助代理响应于匹配一个或多个关键词而更新辅助代理的信度状态的装置。
75.示例38包括示例28-37中任一项的主题,并且其中,用于由辅助代理响应于匹配一个或多个关键词而更新信度状态的装置包括:用于由辅助代理在不等待语音数据的下一个被识别的词的情况下更新交互上下文的装置。
76.示例39包括示例28-38中任一项的主题,并且其中,用于由辅助代理响应于匹配一个或多个关键词而更新信度状态的装置包括:用于搜索自动语音识别算法的词网格的装置,以及用于基于一个或多个关键词找到词网格与语音数据的更好匹配的装置。
77.示例40包括示例28-39中任一项的主题,并且其中多个关键词中的至少一个关键词是包括两个或更多个词的关键短语。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1