音频移调的制作方法
1.本公开一般涉及音频处理领域,以及具体地,涉及音频移调的设备、方法以及计算机程序。
背景技术:
2.有很多可用的音频内容,例如,以光盘(cd)、磁带、可以从互联网下载的音频数据文件的形式,但也以视频的音轨的形式,例如存储在数字视频盘等上。
3.当音乐播放器正在播放现有音乐数据库中的歌曲时,听众可能想要跟着唱。自然地,听众的声音将与录音中呈现的原始艺术家的声音叠加并且可能会干扰它。这可能会妨碍或扭曲听众自己对歌曲的理解。因此,卡拉ok系统以原始歌曲记录的音乐音调提供歌曲的回放,供卡拉ok歌手跟着回放唱歌。这会迫使卡拉ok歌手达到超出其能力的音高范围,即太高或太低。这可能导致卡拉ok歌手付出高歌唱努力才能达到原曲的音高范围,并且因此卡拉ok歌手可能无法忍受长时间的唱歌或可能会损伤他的声带。这也可能导致卡拉ok用户不得不调整他的音高以减少他的努力并保住他的声带,以及因此,表演的整体质量可能会很差。
4.尽管通常存在音频移调的技术,但是通常期望改进用于音频内容的移调的方法和装置。
技术实现要素:
5.根据第一方面,本公开提供了一种电子设备,包括电路,该电路被配置为通过音频源分离将第一音频输入信号分离为第一人声信号和伴奏,并且按照基于音高比的移调值对音频输出信号移调,其中,音高比基于对第一人声信号的第一音高范围与第二人声信号的第二音高范围的比较。
6.根据第二方面,本公开提供了一种方法,包括:通过音频源分离将第一音频输入信号分离为第一人声信号和伴奏,并且按照基于音高比的移调值对音频输出信号移调,其中,该音高比基于对第一人声信号的第一音高范围与第二人声信号的第二音高范围的比较。
7.在从属权利要求、下面的描述和附图中阐述了进一步的方面。
附图说明
8.参照附图通过实例的方式说明实施方式,其中:
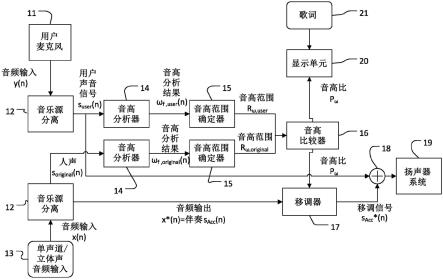
9.图1示意性地示出了卡拉ok系统基于音频源分离和音高范围估计自动移调音频信号的处理的第一实施例;
10.图2示意性地示出了借助于诸如音乐源分离(mss)的盲源分离(bss)的音频上混/再混的一般方法;
11.图3更详细地示出了在图1中的音高分析器中执行的音高分析处理的实施例;
12.图4示意性地示出了描述图1的音高范围确定器的处理的流程图;
13.图5示意性地示出了音高分析结果的曲线图;
14.图6示意性地示出了描述图1的音高范围比较器的处理的流程图;
15.图7示意性地示出了描述图1移调器处理的流程图;
16.图8示意性地示出了基于音频源分离和音高范围估计对音频信号进行移调的卡拉ok系统的处理的第二实施例;
17.图9示意性地描述了图8歌唱努力确定;
18.图10示意性地示出了图8的移调值确定;
19.图11示意性地示出了基于音频源分离和音高范围估计对音频信号进行移调的卡拉ok系统的处理的第三实施例;
20.图12示意性地示出了基于音频源分离和音高范围估计对音频信号进行移调的卡拉ok系统的处理的第四实施例;
21.图13示意性地示出了基于音频源分离和音高范围估计对音频信号进行移调的卡拉ok系统的处理的第五实施例;以及
22.图14示意性地描述了可实现如上所述的音高范围确定和移调的处理的电子设备的实施例。
具体实施方式
23.在参照图1至图14详细描述实施例之前,先进行一些一般性解释。
24.实施例公开了一种电子设备,包括电路,该电路被配置为通过音频源分离将第一音频输入信号分离为第一人声信号和伴奏,并且按照基于音高比的移调值对音频输出信号移调,其中,该音高比基于对第一声音信号的第一音高范围与第二人声信号的第二音高范围的比较。
25.电子设备可以例如是任何音乐或电影再现设备,如卡拉ok盒、智能手机、pc、tv、合成器、调音台等。
26.电子设备的电路可以包括处理器,该处理器例如可以是cpu、存储器(ram、rom等)、内存和/或存储器、接口等。电路可以包括或可以连接到输入设备(鼠标、键盘、相机等)、输出设备(显示器(例如,液晶、(有机)发光二极管等))、扬声器等,(无线)接口等,因为它通常用于电子设备(计算机、智能手机等)。此外,电路可包括或可以连接用于感测静止图像或视频图像数据的传感器(图像传感器、相机传感器、视频传感器等)。
27.输入信号可以是任意类型的音频信号。它可以是模拟信号、数字信号的形式,它可以来源于压缩盘、数字视频盘等,它可以是数据文件,如波形文件、mp3文件等,并且本公开不限于输入特定格式的音频内容。例如,输入音频内容可以为具有第一声道输入音频信号和第二声道输入音频信号的立体声音频信号,但本公开不限于具有两个音频声道的输入音频内容。在其他实施例中,输入音频内容可以包括任意数目的声道,如5.1音频信号的再混音等。
28.输入信号可以包括一个或多个源信号。具体地,输入信号可以包括几个音频源。音频源可以是产生声波的任何实体,例如,乐器、声音、人声、人工生成的声音,如来自合成器的声音等。
29.输入音频内容可以表示或包括混合音频源,这意味着对于输入音频内容的所有音
频源,声音信息不是单独可用的,而是不同音频源的声音信息,例如,至少部分重叠或混合。
30.伴奏可以是由于将人声信号从音频输入信号中分离而产生的残余信号。例如,音频输入信号可以是包括人声、吉他、键盘和鼓的乐曲,并且伴奏信号可以是将人声信号从音频输入信号中分离出来之后剩余的包括吉他、键盘以及鼓的信号。
31.移调可以是将乐曲的音调按一定的音程改变,或者根据音程将整首乐曲移到不同的调上。
32.音高比可以是两个音高之间的比率。通过音高比的移调可以意味着根据由两个音高之间的比率限定的半音值的数目,将乐曲的音高的调值转换成两个音高之间的比率,或者将整首乐曲调到不同的调上。
33.盲源分离(bss),也称为盲信号分离,是将一组源信号从一组混合信号中分离出来。盲源分离(bss)的一个应用是将音乐分离到单个乐器音轨中,这样就可以对原始内容进行上混或重混。
34.在下文中,术语重混合、上混,以及下混可以指在源自混合输入音频内容的分离音频源信号的基础上生成输出音频内容的整个处理,而术语“混合”可以指分离的音频源信号的混合。因此,分离的音频源信号的“混合”可以导致输入音频内容的混合音频源的“重混”、“上混”或“下混”。
35.在音频源分离中,包括多个源(例如,乐器、声音等)的输入信号被分解成分离物。音频源分离可以是无监督的(称为“盲源分离”,bss)或部分监督的。“盲”意味着盲源分离不一定具有关于原始源的信息。例如,它可能不一定知道原始信号包含多少个源,或者输入信号的哪个声音信息属于哪个原始源。盲源分离的目的是在不知道原始信号分离的情况下,对原始信号分离进行分解。盲源分离单元可以使用本领域技术人员已知的任何盲源分离技术。在(盲)源分离中,可以搜索在概率或信息论意义上最小相关或最大独立的源信号,或者基于非负矩阵因式分解,可以找到对音频源信号的结构约束。用于执行(盲)源分离的方法是本领域技术人员已知的并且是基于,例如,主成分分析、奇异值分解、独立成分分析、非负矩阵分解、人工神经网络等。
36.虽然,一些实施例使用盲源分离来生成分离的音频源信号,本公开不限于其中不使用进一步信息来分离音频源信号的实施例,但在一些实施例中,使用进一步的信息用于分离音频源信号的生成。这样的进一步信息可以是,例如,关于混合过程的信息、关于包括在输入音频内容中的音频源的类型的信息、关于包括在输入音频内容中的音频源的空间位置的信息等。
37.电路可以被配置成基于至少一个经滤波的分离源执行重混或上混,并且基于通过盲源分离获得的其他分离源,获得重混或上混信号。重混或上混可以被配置成执行分离的源(此处是“人声”)的重混或上混,此处的“人声”和“伴奏”产生混合或上混信号,可以发送到扬声器系统。重混或上混可以进一步被配置成执行一个或多个分离源的歌词替换,以产生重混或上混信号,该信号可以被发送到扬声器系统的一个或多个输出声道。
38.根据一些实施例,所述电路可以进一步被配置成基于第一人声信号的第一音高分析结果来确定第一人声信号的第一音高范围,并且基于第二人声信号的第二音高分析结果来确定第二人声信号的第二音高范围。
39.根据一些实施例,其中,伴奏包括除了第一人声信号之外的音频输入信号的所有
部分。
40.根据其中音频输出信号可以是伴奏的一些实施例。
41.根据一些实施例,其中,音频输出信号可以是音频输入信号。
42.根据一些实施例,其中,音频输出信号可以是伴奏和第一人声信号的混合。
43.根据一些实施例,其中,可以进一步配置为将伴奏分离成多个乐器。
44.根据一些实施例,第二音频输入信号可以被分离成第二人声信号以及剩余信号。
45.根据一些实施例,该电路可以进一步被配置成基于第二人声信号来确定歌唱努力,其中,移调值基于歌唱努力以及音高比。
46.根据一些实施例,歌唱努力可以基于第二人声信号的第二音高分析结果以及第二人声信号的第二音高范围。
47.根据一些实施例,该电路可以进一步被配置成基于抖动值和/或rap值和/或闪烁值和/或apq值和/或噪声谐波比和/或软发声指数来确定歌唱努力。
48.根据一些实施例,该电路可以进一步被配置成基于音高比对音频输出信号移调,使得移调值对应于半音的整数倍。
49.移调值可以四舍五入到上限或四舍五入到下限,以达到半音的下一个整数倍。因此,伴奏可以按照半音的整数倍移调。
50.根据一些实施例,该电路可以包括被配置成捕获第二人声信号的麦克风。
51.根据一些实施例,该电路可以进一步被配置成从真实音频记录中捕获第一音频输入信号。
52.与计算机生成的声音相比,真实音频记音频记录可录可以是例如使用麦克风记录的任何重新编码的音乐。真实以存储在合适的音频文件中,如wav、mp3、aac、wma、aiff等。这意味着音频输入可以是实际音频,即来自例如一歌曲的商业表演的未准备的原始音频。
53.实施例公开了一种方法,包括通过音频源分离将第一音频输入信号分离成第一人声信号和伴奏,并且基于音高比按照移调值对音频输出信号移调,其中,该音高比基于对第一人声信号的第一音高范围与第二人声信号的第二音高范围的比较。
54.实施例公开了一种计算机程序,包括指令,该指令在处理器上执行时使得处理器执行方法,该方法包括通过音频源分离将第一音频输入信号分离成第一人声信号和伴奏,并且基于音高比按照移调值对音频输出信号移调,其中,该音高比基于对第一人声信号的第一音高范围与第二人声信号的第二音高范围的比较。
55.现在参照附图描述实施例。
56.图1示意性地示出了卡拉ok系统基于音频源分离和音高范围估计自动移调音频信号的处理的第一实施例。从单声道或立体声音频输入13接收的音频输入信号x(n),包含多个源(参见图2中的1、2、
…
、k),并被输入到音乐源分离12处理,并被分解成分离信号(见图2中的分离源2以及残余信号3),此处分为分离源2,即原始人声s
original
(n),以及残余信号3,即伴奏s
acc
(n)。在下面的图2中描述了音乐源分离2的处理的示例性实施例。音频输出信号为x
*
(n)等于伴奏s
acc
(n),并且音频输出信号为x
*
(n)传输到移调器17,并且原始人声s
original
(n)被传输到信号加法器18和音高分析器14,音高分析器14估计原始人声s
original
(n)的音高分析结果ω
f,original
(n)(图3中更详细)。音高分析结果ω
f,original
(n)被输入到音高范围估计器15,音高范围估计器15对原始人声s
original
(n)的音高范围r
ω,original
进行估计
(在图4中更详细地描述)。音高范围r
ω,original
被输入到音高比较器16中。用户的麦克风11获取音频输入信号y(n),该信号被输入到音乐沥分离1212的处理,并分解成分离信号(见图2中的分离沥2以及残余信号3),此处为分离源2,即用户人声s
user
(n),以及在下文中不需要的残余信号3。用户人声s
original
(n)被传输到音高分析器14,音高分析器14估计用户人声s
original
(n)的音高分析结果ω
f,user
(n)(更详细地见图3)。音高分析结果ω
f,user
(n)被输入到音高范围估计器15,音高范围估计器15估计用户人声s
user
(n)的音高范围r
ω,user
(在图4中更详细地描述)中。音高范围r
ω,user
被输入到音高比较器16中。音高范围估计器16(在图5中更详细地描述)接收原始人声s
original
(n)的音高范围r
ω,original
和用户人声s
user
(n)的音高范围r
ω,user
,并且输出原始人声s
original
(n)的平均音高范围r
ω,original
的音高与用户人声s
user
(n)的平均音高范围r
ω,user
的音高之间的音高比。音高比p
ω
输入到移调器17中(在图6中更详细地描述)。在这种情况下,移调器17接收等于音高比p
ω
的移调值transpose_val作为输入,并且音频输出信号为x
*
(n)(=伴奏s
acc
(n))以及将音频输出信号x
*
(n)(=伴奏s
acc
(n))按音高比p
ω
移调。移调器输出移调伴奏以及将其输入信号加法器18。信号加法器18接收移调伴奏和原始人声s
original
(n)并将它们相加,以及将相加的信号输出到扬声器系统19。音高比p
ω
被进一步输出到显示单元20,在显示单元20中将该值呈现给用户。显示单元20进一步接收用户人声s
user
(n)的歌词并将它们呈现给用户。
57.在图1的实施例中,对音频输入信号y(n)执行实时音频源分离。音频输入信号y(n)是例如卡拉ok信号,其包括用户人声和背景声音。背景声音可以是可以由卡拉ok歌手的麦克风捕获的任何噪声,例如人群的噪声等。音频输入信号y(n)通过人声分离算法在线处理,以提取并潜在地从背景声音中移除用户人声。uhlich、stefan等人发表的论文“improving music source separation based on deep neural networks through data augmentation and network blending”中描述了实时人声分离的示例,2017年international conference on acoustics,speech and signal processing(icassp),ieee,2017,其中双向lstm层被单向层取代。
58.对音频输入信号x(n)执行实时音频源分离。音频输入信号x(n)例如是应在进行的卡拉ok演唱的歌曲,其包括原始人声以及伴奏。音频输入信号x(n)可以通过人声分离算法在线处理,以提取并可能从播放声音中移除用户人声,或当音频输入信号x(n)例如存储在音乐库中时,可以预先处理音频输入信号x(n)。在预先处理音高分析的情况下,也可以预先执行音高范围估计。为了进行预先处理,需要对卡拉ok歌曲数据库中的每首歌曲针对音高范围进行分析。
59.存在可以进行手动移调的卡拉ok盒。然而,大多数卡拉ok歌手(也称为卡拉ok用户)不知道音高范围是否足以满足他们的能力以及因此伴奏s
acc
(n)的自动在线移调有很大的优势。
60.在一个实施例中,音频输入x(n)是midi文件(更多细节见下面图7的描述)。在这种情况下,卡拉ok系统通过midi合成器对的每个midi轨道的伴奏s
acc
(n)进行移调。
61.在另一实施例中,音频输入x(n)是录音,例如wav文件、mp3文件、aac文件、wma文件、aiff文件等。这意味着音频输入x(n)是实际的音频,意思是未经准备的原始音频,例如来自歌曲的商业表演。卡拉ok素材不需要任何人工准备,并且可全自动、在线处理以及提供
良好的质量和高真实感,因此在该实施例中不需要预先准备的音频/midi素材。
62.分析卡拉ok歌手的音高范围和演唱努力(见图8),卡拉ok系统使用人声/乐器分离算法(见图2)从卡拉ok歌手的麦克风或原始歌曲(由原始歌手演唱)获得干净的人声记录。
63.虽然在图1中音高分析单元和移调器单元在功能上被分离,但是它们在两个阶段都自动执行,并结合起来,从而实现最小的移调因素和与原始录音的偏差,同时最大限度地减少歌手的疲劳和努力。该系统本质上优化了卡拉ok环节的歌手和听众的表演体验。
64.此外,上述卡拉ok系统的优点在于人声/乐器分离的低延迟处理允许为在线音高分析以及移调。此外,人声分离允许准确分析音高范围以及确定歌唱努力。此外,人声/乐器分离处理真实音频,不限于midi卡拉ok歌曲,因此音乐更加真实。再进一步地,人声/乐器分离能够改善真实音频记录的移调质量。借助于音频源分离的音频重混/上混
65.图2示意性地示出了借助于盲源分离(bss)例如音乐源分离(mss)的音频上混/重混的一般方法。首先,执行音频源分离(也称为“脱混”),将源音频信号1,此处是音频输入信号x(n),包括多个声道i以及来自多个音频源源1、源2、
…
、源k(例如,乐器、声音等)的音频,分成“分离信号”,此处,对于每个声道i,分成分离源2(例如人声so(n))和残余信号3(例如伴奏sa(n)),其中,k是整数并且表示音频源的数目。此处的残余信号是从输入音频信号中分离人声后获得的信号。即,残余信号是对于输入音频信号去除人声之后的“剩余”音频信号。在此处的实施例中,源音频信号1是具有两个声道i=1和i=2的立体声信号。随后,分离源2和残余信号3被再混并呈现为新的扬声器信号4,此处是包括五个声道4a至4e的信号,即5.0声道系统。音频源分离处理(参见图1中的104)例如可以按照uhlich、stefan等人发表的论文中更详细的描述来实现。“improving music source separation based on deep neural networks through data augmentation and network blending”2017年ieee international conference on acoustics,speech and signal processing(icas sp),ieee,2017年。
66.由于音频源信号的分离可能是不完美的,例如,由于音频源的混合,除了分离的音频源信号2a至2d之外,还产生残余信号3(r(n))。残余信号可以例如表示输入音频内容与所有分离音频源信号的总和之间的差。每个音频源发出的音频信号在输入音频内容1中由其各自记录的声波表示。对于具有多于一个音频通道的输入音频内容,例如立体声或环绕声输入音频内容,音频源的空间信息也包括在输入音频内容中或由输入音频内容表示,例如由不同的音频通道中包含的音频源信号的比例表示。将输入音频内容1分离成分离音频源信号2a至2d和残余3的分离,是在盲源分离物或其它能够分离音频源的技术的基础上进行的。
67.在第二步骤中,分离信号2a至2d和可能的残余3被重混并渲染为新的扬声器信号4,此处是包括五个声道4a至4e的信号,即5.0声道系统。基于分离的音频源信号和残余信号,通过基于空间信息将分离的音频源信号和残余信号进行混合来生成输出音频内容。输出音频内容在图2中以附图标记4为例说明和表示。
68.在第二步骤中,将分离信号和可能的残余信号重混并渲染为新的扬声器信号4,此处的信号包括五个声道4a至4e的信号,即5.0声道系统。基于分离的音频源信号和残余信号,通过基于空间信息将分离的音频源信号和残余信号进行混合来生成输出音频内容。输出音频内容在图2中以附图标记4为例说明和表示。
69.音频输入x(n)和音频输入y(n)可以通过图2中描述的方法分离,其中音频输入y(n)被分离成用户人声s
user
(n)和非使用的背景声音,并且音频输入x(n)被分离成原始人声s
user
(n)和伴奏s
acc
(n)。伴奏s
acc
(n)被进一步分离成各自的轨道,例如鼓、钢琴、弦乐等(参见图11)。人声的分离使得伴奏和人声的处理方式都有了很大的改进。
70.从音频输入y(n)中去除伴奏的另一种方法例如是串扰消除法,即从麦克风信号中同相减去伴奏的参考信号,例如使用自适应滤波。
71.如果音频输入y(n)的母带录制可用,可以使用另一种方法来分离音频输入y(n),请详细了解音频输入y(n)(即歌曲)是如何制作的。在这种情况下,主干(stems)需要在没有人声的情况下重混,并且人声需要在没有伴奏的情况下重混。在这个处理中,在母带制作处理中使用了大量的主干,例如,分层人声、多麦克风提取、应用效果等。
72.音高分析
73.图3更详细地示出了在图1中的音高分析器13中执行的音高分析处理的实施例。如图1所述,分别对原始人声s
original
(n)和用户人声s
original
(n)进行音高分析,以得到音高分析结果ωf(n)。具体地,对人声300,即对人声信号,执行信号帧化301的处理s(n),以获得帧化的人声sn(i)。快速傅立叶变换(fft)频谱分析302的处理被执行于帧化的人声上sn(i),以获得fft谱s
ω
(n)。对fft频谱s
ω
(n)执行音高测量分析303,以获得音高测量结果r
p
(ωf)。
74.在信号帧化301处,一个带窗的帧,如成帧化的人声sn(i)可以通过以下公式获得
75.s
π
(i)=s(n+i)h(i)
76.其中,s(n+i)表示离散化音频信号(i表示样本编号,因此代表时间)被移位了n样品,h(i)是围绕时间n(分别为样本n)的帧化函数,例如本领域技术人员熟知的汉明(hamming)函数。
77.在fft频谱分析302处,将每个帧化的人声转换成相应的短期功率谱。短期功率谱s(ω)如在离散傅立叶变换中获得的,也称为功率谱密度,其可以通过以下公式获得
[0078][0079]
其中,sn(i)是窗口帧中的信号,例如如上文所限定帧化的人声sn(i),ω是频域中的频率,|s
ω
(n)|是短期功率谱s(ω)的分量,并且n是窗口帧中的样本数目,例如,在每个帧化的人声中。
[0080]
音高测量分析303可以例如如der-jenq liu和chin-teng lin发表的论文中所描述的那样实施,“fundamental frequency estimation based on the j oint time-frequency analysis of harmonic spectral structure”,eee transactions on speech and audio processing,第9卷,第6期,第609至621页,2001年9月:
[0081]
通过以下方式从帧窗口sn的功率谱密度s
ω
(n)获得每个基频候选ωf的音高测量r
p
(ωf)
[0082]rp
(ωf)=re(ωf)ri(ωf)
[0083]
其中,re(ωf)是基频候选的能量测量ωf,,以及ri(ωf)是基频候选的脉冲测量ωf。
[0084]
基频候选ωf的能量测量re(ωf)由下式给出
[0085][0086]
其中k(ωf)是基频候选ωf的谐波数目,h
in
(nωf)是与基频候选ωf的谐波lωf相关的内部能量,并且e是总能量,其中
[0087]
内部能量
[0088][0089]
是由内部窗长度w
in
界定的光谱曲线下的面积,并且总能量是光谱曲线下的总面积。
[0090]
基频候选ωf的脉冲测量ri(ωf)由下式给出
[0091][0092]
其中ωf是基频候选,k(ωf)是基频候选ωf的谐波数目,h
in
(lωf)是基频候选的内部能量,与谐波nωf有关以及h
out
(lωf)是外部能量,与谐波lωf有关。
[0093]
外部能量
[0094][0095]
是由外部窗的长度w
out
界定的光谱曲线下的面积。
[0096]
用于帧窗sn的音高分析结果通过以下公式获得
[0097][0098]
其中是用于窗口s(n)的基频,以及r
p
(ωf)是由音高测量分析303获得的用于基频候选ωf的音高测量,如上所述。
[0099]
在样本n处的基频是指示在人声信号中s(n)样本n处的人声的音高的音高测量结果。
[0100]
再进一步地,对音高测量结果执行低通滤波器(lp)304以获得音高分析结果ωf(n)305.
[0101]
低通滤波器305可以是m阶的因果离散时间低通有限脉冲响应(fir)滤波器,由下式给出
[0102][0103]
其中,ai是对于0≤i≤m在第i瞬间处的脉冲响应值。在该m阶的因果离散时间fir滤波器e
p
(n)中,输出序列的每个值都是最近输入值的加权和。
[0104]
滤波器参数m以及ai可以根据技术人员的设计选择来选择。例如,a0=1为了归一化目的。参数m可以例如在长达1秒的时间尺度上选择示例。
[0105]
对原始人声s
original
(n)执行如上面关于图3所描述的音高分析处理获得原始人声音高分析结果ω
f,original
(n),并且对用户人声s
original
(n)进行分析以获得用户的音高分析结果ω
f,user
(n)。
[0106]
在图3的实施例中,建议执行音高测量分析,如音高测量分析303,用于基于fft频谱估计基频ωf。或者,基频ωf可以基于快速自适应表示(far)频谱算法来估计。
[0107]
以下科学论文描述了可替代或补充图3中描述的方法的其他单声道信号音高分析和估计方法:由sondhi,m.m发表于1968年的ieee trans.audio electroacoust.au-16,262至266页的“new methods of pitch extraction(音高提取的新方法)”中描述了乘法自相关方法。由ross,m.j.、shaffer,h.l.、cohen,a.、freudberg,r.和manicy,h.j发表于1974年的ieee trans.acoust.speech signal process.assp-22,353至362页,的“average magnitude difference function pitch extractor”中描述了平均幅度差函数方法。由moorer,j.a.发表于1974年的ieee trans.acoust.speech signal process.assp-22,330至338页的“the optimum comb method of pitch period analysis of continuous digitized speech”中描述了梳状滤波方法。由moorer,j.a发表于1974年的纽约springer-verlag的“linear prediction of speech”中描述了基于线性预测分析的方法。由noll,a.m.发表于1966年的j.acoust.soc.am.41,293至309页的“cepstrum pitch determination”中描述了基于倒谱的方法。在“周期直方图”中描述了周期直方图方法以及产品光谱:由schroeder,m.r.发表于1968年的j.acoust.soc.am.43,829至834页的“new methods for fundamental frequency measurement”。
[0108]
再进一步地,由r.c.maher,j.w.beauchamp发表于1994年四月在the journal of the acoustical society of america 95(4)中的科学论文“fundamental frequency estimation of musical signals using a two-way mismatch procedure”中描述了其他更高级的音高分析和估计方法,这些方法可以代替或补充图3中描述的方法。
[0109]
为了进行稳健的音高确定,需要使用音高跟踪(避免音高加倍错误和有声/无声检测),这通常通过对音高f0候选使用动态编程来完成,如上面给出的任何方法中所述。音高跟踪方法在b.secrest和g.doddington发表于1983年的美国马萨诸塞州波士顿,icassp
′
83.ieee international conference on acoustics,speech,and signal processing的第1352至1355页,doi:10.1109/icassp.1983.1172016中的“an integrated pitch tracking algorithm for speech systems”中有所描述。
[0110]
再进一步地,如果人声和伴奏是分开的,音高分析和(音调)移调会更好。
[0111]
音高范围确定
[0112]
图4示意性地示出了描述图1的音高范围确定器15的处理的流程图。在步骤41中,音高分析结果ωf(n)作为输入接收到音高范围确定器15中。在步骤42中,测试样本数n是否为零。如果来自步骤41的查询被回答为“是”,则该处理继续到步骤43。在步骤43中,音高范围r
ω
(n)=[min_ωf(n),max_ωf(n)]的下限min_ωf(n)被初始化为min_ωf(0)=ωf(0),以及音高范围r
ω
(n)=[min-ωf(n),max_ωf(n)]的上限max_ωf(n)被初始化为max_ωf(0)=ωf(0)。在步骤43之后,该处理继续到步骤51。在步骤51中,音高范围r
ω
=[min_ωf(n),max_
ωf(n)]作为音高范围确定器15的结果输出以及存储在存储器中,例如存储内存1202。如果来自步骤41的查询被回答为“否”,则处理继续到步骤44。在步骤44中,旧的音高范围r
ω,old
=[min_ωf(n-1),max_ωf(n-1)]从存储器中加载。在步骤45中,测试音高分析结果ωf(n)是否小于旧音高范围r
ω
(n)=[min_ωf(n-1),max_ωf(n-1)]的下限min_ωf(n-1)。如果来自步骤45的查询被回答为“是”,则该处理继续到步骤46。在步骤46中,音高范围r
ω
(n)=[min_ωf(n),max_ωf(n)]的下限min_ωf(n)设置为min_ωf(n)=ωf(n)并且该处理继续到步骤50。在步骤50中,音高范围r
ω
(n)=[min_ωf(n),max_ωf(n)]的上限min_ωf(n)设置为max_ωf(n)=max_ωf(n-1)以及该处理继续到步骤51。在步骤51中,音高范围r
ω
(n)=[min_ωf(n),max_ωf(n)]作为音高范围确定器15的结果输出以及存储在存储体中,例如存储体存储器1202。如果来自步骤45的查询被回答为“否”,则处理继续到步骤47。在步骤47中,音高范围r
ω
(n)=[min_ωf(n),max_ωf(n)]的下限max_ωf(n)被设置为min_ωf(n)=min_ωf(n-1)以及该处理继续到步骤48。在步骤48中,测试音高分析结果ωf(n)大于旧音高范围r
ω
=[min_ωf(n-1),max_ωf(n-1)]的上限max_ωf(n-1)。如果来自步骤48的查询被回答为“是”,则该处理继续到步骤49。存步骤49中,音高范围r
ω
=[min_ωf(n),max_ωf(n)]的上限max_ωf(n)设置为max-ωf(n)=ωf(n)并且该处理继续到步骤51。在步骤51中,音高范围r
ω
(n)=[min_ωf(n),max_ωf(n)]作为音高范围确定器15的结果输出以及存储在存储器中,例如存储内存1202。如果来自步骤48的查询被回答为“否”,则处理继续到步骤50。在步骤50中,音高范围r
ω
(n)=[min_ωf(n),max_ωf(n)]的上限max_ωf(n)设置为max-ωf(n)=max_ωf(n-1)并且该处理继续到步骤51。在步骤51中,音高范围r
ω
(n)=[min_ωf(n),max_ωf(n)]作为音高范围确定器15的结果输出以及存储在存储器中,例如存储内存1202。
[0113]
如上所述的音高范围确定处理可以基于原始人声s
original
(n)来执行音高分析结果ω
f,original
(n)和用户人声s
user
(n)音高分析结果ω
f,user
(n)进行。
[0114]
上面图4中描述的音高确定器的音高确定处理可以在线执行,这意味着对于来自音频输入y(n)的每个样本(或帧),例如用户的卡拉ok表演、进行音高分析处理14和音高范围确定处理15。
[0115]
在另一实施例中,如上所述音音高确定器15的音高范围确定处理可以对预先存储的音频输入x(n)执行,该音频输入例如是应该确定其音高范围的卡拉ok系统的存储歌曲。在这种情况下,音高范围r
ω
(n)=[min-ωf(n),max_ωf(n)]的上限max-ωf(n)由设置确定,其中max是最大函数,并且n是所有样本的数量,如果存储的音频输入x(n)和音高范围r
ω
(n)=[min_ωf(n),max_ωf(n)]的下限min-ωf(n)由设置决定,其中min是最小函数。
[0116]
在又一实施例中,如上所述的音高确定器15的音高范围确定处理可以对预先存储的音频输入y(n)进行,即例如用户对多首先前歌曲的存储的卡拉ok表演,可以从中编制出音高范围和歌唱努力(见下文)的概况。在这种情况下,音高范围r
ω
(n)=[min_ωf(n),max_ωf(n)]可以如前一段所述确定。
[0117]
图5示意性地示出了音高分析结果的图线。在图50的x轴上示出了音频输入
t
y(n)或
t
x(n)的多个样本n,其中样本的总数是n。在图50的y轴上,示出音高范围分析结果ωf(n)。图线53表示音高范围分析结果ωf(n)超过样本数n。在所有n样本中,音高范围r
ω
(n)=
[min-ωf(n),max-ωf(n)]的下限min-ωf(n)由图53在所有n个样本中所达到的最小值min_ωf(n)给出。音高范围r
ω
(n)=[min-ωf(n),max_ωf(n)]的上限max-ωf(n)由图53在所有n个样本中达到最大值max-ωf(n)给出。
[0118]
音高范围比较
[0119]
图6示意性地示出了描述图1的音高范围比较器16的处理的流程图。在步骤61中,原始人声s
original
(n)(也称为第一人声信号)的音高范围r
ω,original
(n)=[min-ωf(n),max-ωf(n)](也称为第一音高范围)被作为输入接收到步骤63。在步骤62中,用户人声s
user
(n)(也称为第二人声信号)的音高范围r
ω,user
(n)=[min_ωf(n),max_ωf(n)](也称为第二音高范围)被作为输入接收到步骤64。在步骤63中,原始声高平均范围avg-ω
f,original
确定为。在步骤64中,对用户人声音高平均范围avg_ω
f,user
(n)确定为avg_ω
f,uset
(n)=[max_ω
f,user
(n)-min_ω
f,user
(n)]/2+min_ω
f,user
(n)。在步骤65中,音高比p
ω
(n)确定为在步骤66中,音高比p
ω
(n)作为音高范围比较器16的音高范围比较处理的结果输出。
[0120]
针对用户人声s
user
(n)的每个样本n执行如上所述的音高范围比较器16的音高范围比较处理。这意味着,当用户可以进行卡拉ok时,音高比p
ω
(n)可以在每个样本n处进行调整。最终音高比p
ω
(n)在所有样本中n=1
…
n在完成用户的卡拉ok表演之后,可以将其存储在数据库中,例如存储体1202,并与用户联系。
[0121]
音高比p
ω
(n)是相对于原始人声音高范围平均值的值avg_ω
f,original
(n),并以1为中心,所以它可以被看作是一种“移调因子”,应该应用于原始人声的音高频率ω
f,original
(n)。
[0122]
如上所述,除了来自音高分析器14的音高分析结果ωf(n)和来自音高范围确定器15的音高范围r
ω
(n)之外,还可以针对来自音频输入y(n)的每个样本n在线确定音高比p
ω
(n),例如来自用户的现场卡拉ok表演,和来自音频输入x(n),例如从选择的歌曲到应该执行卡拉ok表演。
[0123]
如果预先知道用户的音高范围r
ω,user
(n)(即,在执行产生音频输入y(n)的歌曲的卡拉ok之前),例如来自由用户表演并存储在存储体1202中的另一首歌曲,则音高比p
ω
(n)可以基于用户的预先已知的范围r
ω,user
和用户r
ω,original
(n)的预先已知的范围来确定。
[0124]
在音乐领域和音乐移调中人们通常会说乐曲的半音值或全音值被移调了多少。因为一个八度音阶包含12个半音,并且八度音阶对应音高比p
ω
(n)=2,向上移调半音值对应于音高比p
ω
(n)=2
1/12
=1.087,向下移半音值对应于音高比p
ω
(n)=(1/2)
1/12
=0.920。这样,音高比p
ω
(n)和半音移调规范可以很容易地相互转换。因此,另一实施例音高比p
ω
(n)可以四舍五入到上限或下限(即向上或向下)到下一个半音,使得音高比p
ω
(n)总是对应于半音整数倍的移调。
[0125]
移调
[0126]
如上所述,目标是在用户对歌曲的卡拉ok表演期间,对歌曲的伴奏s
acc
(n)移调,使
得用户可以更容易地将他的声音与伴奏s
acc
(n)相匹配。对伴奏s
acc
(n)进行移调的“移调因子”如文图6中所述确定。音频输入的移调例如可以通过标准的音高尺度修改技术来完成,其中所有频率都乘以预定值,在我们的例子中乘以移调值transpose_val(n)。标准的音高尺度修改技术包括时间尺度修改的步骤以及重采样的步骤。
[0127]
图7示意性地示出了描述图1的移调器17的处理的流程图。在步骤71,接收移调值transpose_val。在该实施例中,移调值transpose_val(n)被设置为等于音高比p
ω,user
(n),即,transpose
val(n)
=p
ω,user
(n)。在步骤72中,接收伴奏s
acc
(n)作为输入。在步骤73中,伴奏s
acc
(n)的时间尺度修改以移调值transpose_val(n)作为时间因子。伴奏s
acc
(n)的时间尺度修改是用相位声码器完成的。在不改变伴奏的频率s
acc
(n)的情况下,相位声码器按照移调值transpose_val因子扩展或缩短伴奏s
acc
(n)。这就产生了时间尺度的修正伴奏s
acc,mod
(n)作为步骤73的输出并作为步骤74的输入。在步骤74中,时间标度的修正伴奏s
acc,mod
(n)用新的采样周期δt*transpose_val(n)重新采样,其中,所述δt是采样该伴奏s
acc
(n)时使用的采样周期。这意味着在新的采样周期δt*transpose_val(n)的重采样期间,时间尺度的修正伴奏s
acc,mod
(n)已被缩短或扩展到原始长度的伴奏s
acc
(n),并由此,所有频率都乘以移调值transpose_val(n)的因子,产生移调伴奏在步骤75中,移调伴奏是移调器17输出的结果。
[0128]
在该实施例中,音频输出信号是x
*
(n)等于伴奏s
acc
(n)。一般而言,如图7中所述的相同处理可应用于另一音频输出信号是x
*
(n)。例如,在另一实施例中,音频输出信号是x
*
(n)可以等于音频输入信号x(n)。在这种情况下,如图7中所述的相同移调应用于音频输出信号是x
*
(n)。在这种情况下,移调器的输出信号可以称为移调信号s
*
(n)。
[0129]
时间尺度修改相位声码器和重采样在z发表于1999年十月的proc.1999ieee workshop on applications of signal processing to audio and acoustics,new paltz,newyork,17至20页,或在其中提到的论文中“new phase-vocoder techniques for pitch-shifting,harmonizing and other exotic effects中有更详细的描述。再进一步地,改进的相位编码器在由jean laroche和mark dolson发表在1999年5月的ieee transactions on speech and audio processing,vol.7,no.3中的论文“improved phase vocoder time-scale modification of audio”中有更详细的解释。
[0130]
如果移调值transpose_val(n)小于1,则步骤73和步骤74可以互换。
[0131]
如上所述,同样可以在线确定每个样本n的音高比p
ω
(n),可以根据当前的移调值transpose_val(n)(也可以将其视为移调音调)为每一首n在线确定移调伴奏以及然后实时应用于整首歌曲。
[0132]
如果预先知道所选择的卡拉ok歌曲和特定用户的音高比p
ω
(n)(以及因此的移调值transpose_val(n)),如上所述,也可以预先确定移调的伴奏
[0133]
如上所述,伴奏s
acc
(n)如mss 12所输出的(见图2),例如可以包括所有的乐器(轨道),如鼓,钢琴,弦乐等。在这种情况下,移调器的移调处理如图7所示,直接应用于“完整的”伴奏s
acc
(n)(也称为复音音高移调)。复音音高移调可能导致比单音轨音高移调更低的质量(见图11),因为它可能很难处理对于具有多种乐器的轨道的非常不同的起音/释放、旋
律/泛音、多音符开关。因此,可能会出现打击乐部分的预回声、旋律部分的梳状/法兰效果等伪像。
[0134]
如上所述,音高比p
ω
(n)也可以用半音或全音来表达,并且对于移调值transpose_val(n)是真的完全一样。
[0135]
再进一步地,在另一实施例中,音频输入信号x(n)可以作为midi(乐器数字接口)提供,以及因此伴奏s
acc
(n),或者伴奏的单声道也可以作为midi文件提供。在这种情况下,midi文件伴奏的移调s
acc
(n)可以通过标准的midi命令来实现,如移调滤波器。这意味着在这种情况下,通过在乐器合成之前将midi音轨的音调简单地按照所需的移调值transpose_val(n)移调来执行移调。
[0136]
因此,上述移调器能够处理任何类型的记录(合成的midi、第三方翻唱或商业发行的记录),其中,可以通过高分离质量和音高分析以及移调值确定来提高移调质量。
[0137]
歌唱努力确定
[0138]
图8示意性地示出了基于首频源分离和首高范围估计对首频信号进行移调的卡拉ok系统的处理的第二实施例。从单声道或立体声音频输入13接收的音频输入信号x(n),包含多个源(参见图2中的1、2、
…
、k),并且输入到音乐源分离12的处理,并分解成分离信号(见图2中的分离源2和残余信号3),此处分为分离源2,即原始人声s
original
(n),以及残余信号3,即伴奏s
acc
(n)。在下面的图2中描述了音乐源分离2的处理的示例性实施例。音频输出信号为x
*
(n)等于伴奏s
acc
(n),并且音频输出信号为x
*
(n)被传输到移调器17,并且原始人声s
original
(n)被传输到信号加法器18和音高分析器14,音高分析器14估计原始人声s
original
(n)的音高分析结果ω
f,original
(n)(图3中更详细)。音高分析结果ω
f,orignal
(n)被输入到音高范围估计器15,音高范围估计器15对原始人声s
original
(n)的音高范围r
ω,original
进行估计(在图4中更详细地描述)中。音高范围r
ω,oiginal
被输入到音高比较器16中。用户的麦克风11获取音频输入信号y(n),该信号被输入到音乐源分离12处理,并分解成分离信号(见图2中的分离源2和残余信号3),此处分为分离源2,即用户人声s
use
(n),以及在下文中不需要的残余信号3。用户人声s
original
(n)传送到歌唱努力确定器22、到信号加法器18以及到音高分析器14(更详细地见图3)用于估计用户人声s
original
(n)音高分析结果s
original
(n)。音高分析结果ω
f,user
(n)被输入到对用户人声s
user
(n)的音高范围r
ω,user
进行估计的音高范围估计器15(在图4中更详细地描述)中。音高范围r
ω,user
输入到音高比较器16中。音高范围估计器16(在图5中更详细地描述)接收原始人声s
original
(n)的音高范围r
ω,original
和用户人声s
user
(n)的音高范围r
ω,user
,并且输出原始人声s
original
(n)的平均音高范围r
ω,original
的音高与用户人声s
user
(n)的平均音高范围r
ω,user
的音高之间的音高比。音高比p
ω
输入到移调值确定器23中。歌唱努力确定器22接收用户人声s
original
(n)、用户人声s
original
(n)的音高分析结果ω
f,user
(n)以及用户人声s
user
(n)的音高范围r
ω,user
,并确定歌唱努力(参见图9)。歌唱努力确定器22输出歌唱努力标志e,歌唱努力标志被输入到移调值确定器23中。移调值确定器23确定移调值transpose_val,基于音高比p
ω
以及歌唱努力标志e。移调值确定器23输出移调值transpose_val进入移调器17。移调器接收移调值transpose_val,音频输出信号为x
*
(n)(=伴奏s
acc
(n))以及按照移调值transpose_val对音频输出信号x
*
(n)(=伴奏s
acc
(n))移调。移调器17输出移调的伴奏并将其输入信号加法器18。信号加法器18接收移调伴
奏和原始人声s
original
(n)并将它们相加,以及将相加的信号输出到扬声器系统19。移调值transpose_val被进一步输出到显示单元20,在显示单元中该值被呈现给用户。显示单元20进一步接收用户人声s
user
(n)的歌词并将它们呈现给用户。
[0139]
歌唱努力和声带病理学
[0140]
卡拉ok系统可以进一步估计卡拉ok用户的歌唱努力。歌唱努力指示卡拉ok用户是否尽很大的努力来达到原始歌曲的音高范围,即,卡拉ok用户是否必须付出很大的努力来演唱与原始歌曲一样高或一样低的歌曲。如果业余卡拉ok用户长时间超出其自然能力唱歌,则用户将无法忍受长时间的唱歌,并可能损坏声带,从而导致表演质量变差。
[0141]
可以从用户人声s
user
(n)的分析中推导出不同的特征参数和或者用户的音高分析结果ω
f,user
(n)这表明了很高的歌唱努力。这些不同的特征参数是示例:
[0142]-抖动值(以百分比/%/表示),它是对分析的语音样本中用户音高分析结果ω
f,user
(n)的周期间(非常短期)可变性的相对评估,其中,语音中断区域被排除。
[0143]-rap值(以百分比/%/为单位),它是对具有三个周期的平滑因子的所分析的语音样本内的音高的周期到周期可变性的相对评估,其中,语音中断区域被排除。
[0144]-闪烁值(以百分比/%/为单位),它是对所分析的语音样本中峰值到峰值幅度的周期到周期(非常短期)可变性的相对评估,其中,语音中断区域被排除。
[0145]
apq值(以百分比/%/为单位),它是在平滑11个周期时分析的语音样本中峰值到峰值幅度的周期到周期变化的相对评估,其中,语音中断区域被排除。
[0146]-噪声谐波比(nhr)值,它是1500hz至4500hz频率范围内的非谐波频谱能量与70hz至4500hz频率范围内的谐波频谱能量的平均比率。这是对分析信号中存在的噪声的一般评估。
[0147]-软发声指数(spi)值,它是70hz至1600hz范围内的低频谐波能量与1600hz至4500hz范围内的高频谐波能量的平均比率。这个参数反映了声带的近似值。高spi值被认为与声带内收不完全相关,并且是比egg更好的呼吸指标。nhr和spi都是使用音高同步频域方法计算的。
[0148]
更深入地分析上述参数以及基于用户人声s
user
(n)和或者用户音高分析结果ω
f,user
(n)测量和检测它们的方法,在j.wang和c.jo发表于2007年的29th annual international conference of the ieee engineering in medicine and biology society,lyon,2007,第3253至3256页,doi:10.1109/iembs.2007.4353023的科学论文“vocal folds disorder detection using pattern recognition methods”中进行了描述。
[0149]
以上参数大多与声带有关。其中一些也与唱歌时的表现力有关,如抖动(颤音),但在卡拉ok唱歌过程中表现出进行性混乱的声带行为可能是发展短期声带问题(如肿胀)的指标。nhr值也可以用于检测失音。卡拉ok系统可以监控上述这些及其在用户卡拉ok会话期间的变化,并确定歌唱力度和可能的声带损伤(例如通过歌唱质量逐渐退化)。
[0150]
图9示意性地描述了图8歌唱努力确定器22。在步骤91中,将用户人声s
user
(n)作为输入接收到歌唱努力确定器22中。在步骤92,用户的音高分析结果ω
f,user
(n)作为输入接收到歌唱努力确定器22中。在步骤93中,用户人声s
user
(n)的音高范围r
ω,user
(n)=[min-ω
f,user
(n),max_ω
f,use
r(n)]作为输入接收到歌唱努力确定器22中。在步骤94中,抖动值
jitter_val基于用户的音高分析结果ω
f,user
(n)和用户人声s
user
(n)来确定。这在j.wang和c.jo的论文中有更详细的描述,该论文在其中引用的论文上方被引用。在步骤95中,第一歌唱努力值pitch_high(n)初始化为pitch_high(n)=0,其中,第一歌唱努力值pitch_high(n)如果设置为1,则指示卡拉ok歌手必须付出很大努力才能达到高音,否则会失败。再进一步地,在步骤95中,第二歌唱努力值pitch_low(n)初始化为pitch-low(n)=0,其中,第二歌唱努力值pitch-low(n)如果设置为1,则指示卡拉ok歌手必须尽最大努力才能达到低音高,否则会失败。在步骤96中,测试抖动值jitter-val(n)是否大于阈值5%。在另一实施例中,抖动的阈值可以有另一值。如果来自步骤96的查询被回答为“是”,则继续进行步骤97。在步骤97中,测试用户音高分析结果ω
f,user
(n)与低值音高范围r
ω,user
(n)之差的绝对值是否大于用户音高分析结果ω
f,user
(n)与高值音高范围r
ω,user
(n)之差的绝对值|ω
f,user
(n)-min_ω
f,user
(n)|>|ω
f,user
(n)-max_ω
f,user
(n)|。如果来自步骤97的查询被回答为“是”,则继续进行步骤98。在步骤98中,第一歌唱努力值pitch_high(n)设置为1,pitch_high(n)=1以及继续进行步骤100。如果来自步骤97的查询被回答为“否”,则继续进行步骤99。在步骤99中,第二歌唱努力值pitch_low(n)设置为1,pitch_low(n)=1,则继续进行步骤100。如果步骤96中的查询被回答为“否”,则继续进行步骤100。在步骤100中,歌唱努力e(n)={pitch_low(n),pitch_high(n)}由歌唱努力确定器22输出。
[0151]
在上述实施例中,歌唱努力e(n)是抖动值jitter_val(n)的“二值化”值,即,当该值高于阈值时设置标志,当它低于阈值时不设置标志。在另一实施例中,歌唱努力e(n)可以是定量值,例如与抖动值jitter_val(n)成正比的值。
[0152]
在又一实施例中,可以使用任何其他上述不同特性参数来代替抖动或附加地用于确定第一和第二歌唱努力值,如图9所述的。
[0153]
在又一实施例中,歌唱努力e(n)可以是一个定量值,例如与上述描述不同特性参数的任何线性或非线性组合成正比的值。
[0154]
在另一实施例中,卡拉ok系统可以提出停止或暂停歌唱以防止更严重的声带问题。如何识别病态语音的更多细节,也可用于检测高歌唱努力,例如作者:dibazar,alireza和narayanan,shrikanth发表于2002年11月的proceedings of the asilomar conference on signals,systems and computers中的“a system for automatic recognition of pathological speech”中有所描述。在本文中,标准mfcc和音调特征用于对几种与语音产生相关的病症进行分类。
[0155]
如果歌唱努力确定器22已经确定了歌唱努力值e和音高比p
ω
,则可以确定移调值transpose_val。
[0156]
图10示意性地示出了图8的移调值确定器23。在步骤101中,音高比p
ω
作为输入被接收到移调值确定器23中。在步骤102中,歌唱努力e={pitch_low(n),pitch_high(n)}作为输入被接收到移调值确定器23中。在步骤103中,音高比p
ω
被设置为等于移调值transpose_val(n),transpose_val(n)=p
ω
。在步骤104中,测试第一歌唱努力值pitch_high设置为1。如果步骤104中的查询被回答为“是”,则继续进行步骤105。在步骤105中,移调值transpose_val减少0.05,transpose_val(n)=transpose_val-0.05以及继续进行步骤108。如果步骤104中的查询被回答为“否”,则继续进行步骤106。在步骤106中,测试第二歌唱努力值pitch_low设置为1。如果步骤106中的查询被回答为“是”,则继续进行步骤107。
在步骤107中,移调值transpose_val(n)增加0.05,transpose_val(n)=transpose_val(n)+0.05以及继续进行步骤108。在步骤108中,移调值transpose_val由移调值确定器23输出。
[0157]
图11示意性地示出了基于音频源分离和音高范围估计对音频信号进行移调的卡拉ok系统的处理的第三实施例。图11的实施例大部分类似于图1的实施例。然而,在图11中伴奏s
acc
(n)可以被音乐源分离12分离成不同的乐器(音轨),例如第一乐器s
a1
(n)、第二个乐器s
a2
(n)以及第三乐器s
a3
(n)),例如鼓、钢琴、弦乐等。三个乐器s
a1
(n),s
a2
(n)和s
a3
(n)中的每个乐器都可以设置为输出信号x
*
(n),并由移调器17按照相同的移调值移调,如上图7中所述。移调器17为第一乐器s
a1
(n)的输入输出移调的第一乐器或者为第二乐器s
a2
(n)的输入输出移调的第二乐器并且为第三乐器s
a3
(n)输出移调的第三乐器移调的第一乐器移调的第二乐器移调的第三乐器被加法器1101和1102相加在一起,并接收完整的移调伴奏
[0158]
在又一实施例中,伴奏s
acc
(n)可以分成旋律/和声轨道和打击乐轨道,并且可以应用与上述相同的单轨道(单一乐器)移调。如果伴奏s
acc
(n)被分离成一个以上的轨道(乐器)时,移调器17的移调过程分别应用于每个分离的音轨,然后将单独移调的音轨汇总到立体声录音中,以接收完整的移调伴奏
[0159]
图12示意性地示出了基于音频源分离和音高范围估计对音频信号进行移调的卡拉ok系统的处理的第四实施例。图12的实施例大部分类似于图1的实施例。然而,在图12中,音频输出信号x
*
(n)按照移调值transpose_val(n)移调为等于音频输入信号x(n),这意味着原始人声s
original
(n)(以及伴奏s
acc
(n))也按照值transpose_val(n)移调,如上所述。移调器的输出,即移调信号s
*
(n)输入加法器18并如图1所述进行。
[0160]
图13示意性地示出了基于音频源分离和音高范围估计对音频信号进行移调的卡拉ok系统的处理的第四实施例。图13的实施例大部分类似于图1的实施例。然而,在图13中,按照移调值transpose_val(n)移调的音频输出信号x
*
(n)由原始人声s
original
(n)和伴奏s
acc
(n)混合而成。例如,输出信号x
*
(n)由原始人声s
original
(n)组成,它乘以增益g(这意味着它们被放大或阻尼)加上伴奏s
acc
(n)。移调器的输出,即移调信号s
*
(n)被输入加法器18并如图1所述进行。
[0161]
图14示意性地描述了可实现音高范围确定的处理的电子设备的实施例以及如上所述的移调。电子设备1200包括作为处理器的cpu 1201。电子设备1200进一步包括麦克风阵列1210、扬声器阵列1211以及卷积神经网络单元1220,其连接到处理器1201。处理器1201可以例如实现音高分析器、音高范围确定器、音高比较器、歌唱努力确定器、移调确定器或移调器,其更详细地实现关于图1、图2、图3、图4、图5、图6、图7、图8、图9和图10中所描述的处理。cnn 1220可以例如是硬件中的人工神经网络,例如gpu上的神经网络或专门用于实现人工神经网络的任何其他硬件。cnn 1220可以例如实施源分离104。扬声器阵列1211,例如关于图1、图8描述的扬声器系统111,由分布在预限定空间上的一个或多个扬声器组成,并被配置为呈现任何种类的音频,例如3d音频。电子设备1200进一步包括连接到处理器1201的用户接口1212。该用户接口1212充当人机接口和启用管理员之间的对话以及电子系统。
例如,管理员可以使用该用户接口1212对系统进行配置。电子设备1200进一步包括以太网接口1221、蓝牙接口1204,以及wlan接口1205。这些单元1204、1205用作i/o接口为与外部设备的数据通信。例如,附加扬声器、麦克风,以及具有以太网、wlan或蓝牙连接的摄像机可以经由这些接口1221、1204耦合到处理器1201和1205。电子设备1200进一步包括数据存储体1202以及数据存储器1203(此处是ram)。数据存储器1203被布置成临时存储或高速缓存数据或计算机指令为处理器1201的处理。数据存储体1202被布置为长期存储体,例如,用于记录从麦克风阵列1210获得的传感器数据以及提供给cnn 1220或从cnn 1220检索。数据存储体1202还可以存储表示音频消息的音频数据,公共公告系统可以将音频消息传输给在预限定空间中移动的人。
[0162]
需要说明的是,以上描述仅为示例配置。可选配置可以用附加的或其他传感器、存储体设备、接口等来实现。
[0163]
***
[0164]
应当认识到,实施例描述了具有方法步骤的示例性排序的方法。然而,给出了方法步骤的具体顺序为仅用于说明目的以及不应被解释为具有约束力。
[0165]
还应当注意,图1的电子设备仅被划分为单元为说明目的以及本公开不限于特定单元中的任何特定功能分工。例如,至少部分电路可以由分别编程的处理器、现场可编程门阵列(fpga)、专用电路等来实现。
[0166]
在本说明书中描述的和在所附权利要求中要求的所有单元和实体,如果没有另作说明,可以实现为集成电路逻辑,例如在芯片上,并且如果没有另作说明,可以通过软件实现由这些单元和实体提供的功能。
[0167]
就上述公开的实施方式而言,至少部分地使用软件控制的数据处理装置来实现,应当理解,提供这种软件控制的计算机程序以及通过以下方式的传输、存储或其他介质提供这样的计算机程序是被设想为本公开的方面的。
[0168]
注意,本技术也可以如下所述配置。
[0169]
(1)一种电子设备,包括电路,被配置成通过音频源分离将第一音频输入信号(x(n))分离成第一人声信号(s
original
(n))和伴奏(s
acc
(n);s
a1
(n),s
a2
(n),s
a3
(n)),并且按照基于音高比(p
ω
(n))的移调值(transpose_val(n))对音频输出信号(x
*
(n))移调,其中,该音高比(p
ω
(n))基于对第一人声信号(s
original
(n))的第一音高范围(r
ω,original
(n))与第二人声信号(s
user
(n))的第二音高范围的(r
ω,user
(n))的比较。
[0170]
(2)根据(1)所述的电子设备,其中,所述电路进一步被配置成基于所述第一人声信号(s
original
(n))的第一音高分析结果(ω
f,original
(n))来确定所述第一人声信号(s
original
(n))的所述第一音高范围(r
ω,original
(n)),并且基于所述第二人声信号(s
user
(n))的第二音高分析结果(ω
f,user
(n))来确定所述第二人声信号(s
user
(n))的第二音高范围(r
ω,user
(n))。
[0171]
(3)根据(1)或(2)所述的电子设备,其中,所述电路被进一步配置成基于所述第一人声信号(s
original
(n))来确定所述第一音高分析结果(ω
f,original
(n)),并且基于所述第二人声信号(s
user
(n))确定第二音高分析结果(ω
f,user
(n))。
[0172]
(4)根据(1)至(3)中任一项所述的电子设备,其中,所述伴奏(s
acc
(n);s
a1
(n),s
a2
(n),s
a3
(n))包括除了第一人声信号(s
original
(n))之外的所述音频输入信号(x(n))的所有部分。
[0173]
(5)根据(1)至(4)中任一项所述的电子设备,其中,所述音频输出信号(x
*
(n))是伴奏(s
acc
(n))。
[0174]
(6)根据(1)至(5)中任一项所述的电子设备,其中,所述音频输出信号(x
*
(n))是音频输入信号(x(n))。
[0175]
(7)根据(1)至(6)中任一项所述的电子设备,其中,所述音频输出信号(x
*
(n))是伴奏(s
acc
(n))和所述第一人声信号(s
original
(n))的混合。
[0176]
(8)根据(1)至(8)中任一项所述的电子设备,其中,所述电路进一步被配置成将所述伴奏(s
a1
(n),s
a2
(n),s
a3
(n))分离成多个乐器(s
a1
(n);s
a2
(n);s
a3
(n))。
[0177]
(9)根据(1)至(8)中任一项所述的电子设备,其中,所述电路进一步被配置成通过音频源分离来分离第二音频输入信号(y(n))。
[0178]
(10)根据(9)所述的电子设备,其中,所述第二音频输入信号(y(n))被分离成第二人声信号(s
user
(n))和剩余信号。
[0179]
(11)根据(1)至(10)中任一项所述的电子设备,其中,所述电路被进一步配置成基于所述第二人声信号(s
user
(n))来确定歌唱努力(e(n)),其中,所述移调值(transpose_val(n))基于所述歌唱的努力(e(n))和所述音高比(p
ω
(n))。
[0180]
(12)根据(11)所述的电子设备,其中,所述歌唱努力(e(n))基于所述第二人声信号(s
user
(n))的所述第二音高分析结果(ω
f,user
(n))以及所述第二人声信号(s
user
(n))的所述第二音高范围(r
ω,user
(n))。
[0181]
(13)根据(11)或(12)所述的电子设备,其中,所述电路被进一步配置成基于抖动值(jitter_val(n))和/或rap值和/或闪烁值和/或apq值和/或噪声谐波比和/或软发声指数来确定所述歌唱努力(e(n))。
[0182]
(14)根据(1)至(13)中任一项所述的电子设备,其中,所述电路被配置成基于音高比(p
ω
(n))对所述音频输出信号(x
*
(n))移调,使得移调值(transpose_val(n))对应于半音值的整数倍。
[0183]
(15)根据(1)至(14)中任一项所述的电子设备,其中,所述电路包括配置成捕获所述第二人声信号的麦克风(s
user
(n))。
[0184]
(16)根据(1)至(15)中任一项所述的电子设备,其中,所述电路被配置成从真实录音中捕获所述第一音频输入信号(x(n))。
[0185]
(17)一种方法,所述方法包括:
[0186]
通过音频源分离将第一音频输入信号(x(n))分离成第一人声信号(s
original
(n))和伴奏(s
acc
(n);s
a1
(n),s
a2
(n),s
a3
(n)),以及
[0187]
按照基于音高比(p
ω
(n))的移调值(transpose_val(n))对音频输出信号(x
*
(n))移调,其中,所述音高比(p
ω
(n))基于对所述第一人声信号(s
original
(n))的第一音高范围(r
ω,original
(n))与所述第二人声信号(s
user
(n))的第二音高范围(r
ωz,user
(n))的比较。
[0188]
(18)一种计算机程序,包括指令,所述指令当在处理器上执行时使所述处理器执行(17)的方法。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1