语音识别方法、电子设备和计算机可读存储介质与流程
1.本公开的实施例涉及一种语音识别方法、电子设备和计算机可读存储介质。
背景技术:
2.随着科学技术的快速发展,语音识别功能越来越多的被应用于各种场景中,例如在车载导航、智能家居、日常办公等领域都有涉及,给人们生活带来了很多便利。语音识别是以语音为研究对象,通过语音信号处理和模型识别让机器理解人类语言,并将其转换为计算机可输入的数字信号。
技术实现要素:
3.本公开至少一个实施例提供一种语音识别方法,包括:获取待识别的语音信息;针对所述待识别的语音信息,确定至少一个识别领域;从至少两个候选识别模型中,确定与所述至少一个识别领域匹配的至少一个识别模型;利用所述至少一个识别模型,对所述待识别的语音信息进行识别,以得到语音识别结果。
4.例如,在本公开一实施例提供的语音识别方法中,针对所述待识别的语音信息,确定至少一个识别领域,包括:基于所述待识别的语音信息,确定所述待识别的语音信息对应的意图信息;至少基于所述意图信息,确定所述至少一个识别领域。
5.例如,在本公开一实施例提供的语音识别方法中,基于所述待识别的语音信息,确定所述待识别的语音信息对应的意图信息,包括:对所述待识别的语音信息进行特征提取操作,得到特征数据;将所述特征数据输入声学模型,以得到所述声学模型的输出结果,其中,所述声学模型的输出结果包括与所述特征数据对应的字符;基于所述声学模型的输出结果,解码得到所述待识别的语音信息对应的k条字符序列;基于所述k条字符序列,确定所述意图信息;其中,k为正整数。
6.例如,在本公开一实施例提供的语音识别方法中,针对所述待识别的语音信息,确定至少一个识别领域,包括:获取接收所述待识别的语音信息的语音接收设备的当前状态信息和/或与所述语音接收设备相关联的关联设备的当前状态信息;基于所述语音接收设备的当前状态信息和/或所述关联设备的当前状态信息,确定当前场景信息;至少基于所述当前场景信息,确定所述至少一个识别领域。
7.例如,在本公开一实施例提供的语音识别方法中,针对所述待识别的语音信息,确定至少一个识别领域,包括:获取在接收所述待识别的语音信息之前接收的至少一条历史语音信息对应的至少一个历史识别领域;至少基于所述至少一个历史识别领域,确定所述至少一个识别领域。
8.例如,在本公开一实施例提供的语音识别方法中,针对所述待识别的语音信息,确定至少一个识别领域,包括:获取m个参考信息,并分别基于所述m个参考信息确定m个候选领域;基于所述m个候选领域,确定所述至少一个识别领域;其中,m为大于1的整数。
9.例如,在本公开一实施例提供的语音识别方法中,所述m个参考信息包括以下信息
中的至少一种:所述待识别的语音信息对应的意图信息;基于接收所述待识别的语音信息的语音接收设备的当前状态信息和/或与所述语音接收设备相关联的关联设备的当前状态信息确定的当前场景信息;在接收所述待识别的语音信息之前接收的历史语音信息对应的历史识别领域。
10.例如,在本公开一实施例提供的语音识别方法中,确定至少一个识别领域包括:确定一个识别领域;基于所述m个候选领域,确定所述至少一个识别领域,包括:若所述m个候选领域均为第一领域,则将所述第一领域作为所述识别领域;若所述m个候选领域包括各不相同的n个候选领域,则从所述n个候选领域中确定一个候选领域作为所述识别领域;其中,n为大于1且小于等于m的正整数。
11.例如,在本公开一实施例提供的语音识别方法中,从所述n个候选领域中确定一个候选领域作为所述识别领域,包括:基于所述m个候选领域,统计所述n个候选领域各自的频次;将所述n个候选领域中频次最高的候选领域作为所述识别领域。
12.例如,在本公开一实施例提供的语音识别方法中,从所述n个候选领域中确定一个候选领域作为所述识别领域,包括:基于所述m个参考信息的优先权排序,确定所述m个参考信息中优先权最高的参考信息;将所述n个候选领域中与所述优先权最高的参考信息对应的候选领域作为所述识别领域。
13.例如,在本公开一实施例提供的语音识别方法中,所述m个参考信息包括p个意图信息和q个其他信息,所述m个候选领域包括分别与所述p个意图信息对应的p个第一候选领域和分别与所述q个其他信息对应的q个其他候选领域,p为大于1且小于m的整数,q为小于m的正整数;从所述n个候选领域中确定一个候选领域作为所述识别领域,包括:若所述p个第一候选领域中的至少一个候选领域与所述q个其他候选领域中的至少一个候选领域均为第二领域,则将所述第二领域作为所述识别领域。
14.例如,在本公开一实施例提供的语音识别方法中,确定至少一个识别领域包括:确定多个识别领域;基于所述m个候选领域,确定所述至少一个识别领域。包括:若所述m个候选领域包括各不相同的n个候选领域,则将所述n个候选领域作为所述多个识别领域,其中,n为大于1且小于等于m的正整数;确定与所述至少一个识别领域匹配的至少一个识别模型,包括:确定分别与所述多个识别领域匹配的多个识别模型;利用所述至少一个识别模型,对所述待识别的语音信息进行识别,以得到语音识别结果。包括:分别利用所述多个识别模型对所述待识别的语音信息进行识别,以得到多个候选识别结果;基于所述多个候选识别结果,确定所述语音识别结果。
15.例如,在本公开一实施例提供的语音识别方法中,分别利用所述多个识别模型对所述待识别的语音信息进行识别,以得到多个候选识别结果,包括:分别利用所述多个识别模型对所述待识别的语音信息进行识别,以得到多个候选识别结果以及所述多个候选识别结果分别对应的多个得分;基于所述多个候选识别结果,确定所述语音识别结果,包括:从所述多个候选识别结果中选择得分最高的候选识别结果作为所述语音识别结果。
16.例如,本公开一实施例提供的语音识别方法还包括:针对至少两个预设识别领域,分别训练得到对应的至少两个候选识别模型;基于所述至少两个预设识别领域与所述至少两个候选识别模型的对应关系生成领域与模型对应信息;其中,确定与所述至少一个识别领域匹配的至少一个识别模型,包括:利用所述领域与模型对应信息,确定与所述至少一个
识别领域匹配的至少一个识别模型。
17.例如,在本公开一实施例提供的语音识别方法中,所述识别模型包括语言模型;利用所述至少一个识别模型,对所述待识别的语音信息进行识别,以得到语音识别结果,包括:将所述声学模型的输出结果输入所述语言模型,以得到所述语言模型的输出结果,将所述语言模型的输出结果作为所述语音识别结果。
18.例如,在本公开一实施例提供的语音识别方法中,所述识别模型包括语言模型;利用所述至少一个识别模型,对所述待识别的语音信息进行识别,以得到语音识别结果。包括:将所述k条字符序列输入所述语言模型,以得到所述语言模型的输出结果,将所述语言模型的输出结果作为所述语音识别结果。
19.例如,在本公开一实施例提供的语音识别方法中,基于所述声学模型的输出结果,解码得到所述待识别的语音信息对应的k条字符序列,包括:执行多次解码操作,直至触发结束条件,以获得最后一次解码操作解码得到的多条字符序列以及所述多条字符序列的排序,其中,所述结束条件表征当前解码的语句结束,对于首次解码操作之后的每次解码操作,均基于上一次解码操作得到的多条非完整字符序列继续向后解码;其中,在所述排序中,所述多条字符序列按照质量由高至低排列,所述k条字符序列为所述排序中的前k条字符序列。
20.本公开至少一个实施例提供一种电子设备,包括语音接收装置和语音识别装置,语音接收装置配置为接收待识别的语音信息;语音识别装置配置为执行本公开任一实施例提供的语音识别方法。
21.本公开至少一个实施例提供一种电子设备,包括处理器;存储器,存储有一个或多个计算机程序模块;其中,所述一个或多个计算机程序模块被配置为由所述处理器执行,用于实现本公开任一实施例提供的语音识别方法。
22.本公开至少一个实施例提供一种计算机可读存储介质,存储有非暂时性计算机可读指令,当所述非暂时性计算机可读指令由计算机执行时可以实现本公开任一实施例提供的语音识别方法。
附图说明
23.为了更清楚地说明本公开实施例的技术方案,下面将对实施例的附图作简单地介绍,显而易见地,下面描述中的附图仅仅涉及本公开的一些实施例,而非对本公开的限制。
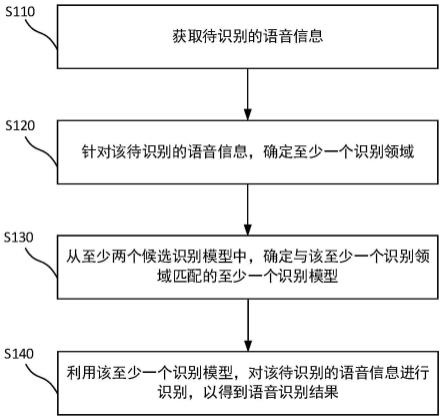
24.图1示出了本公开至少一实施例提供的一种语音识别方法的流程图;
25.图2示出了本公开至少一实施例提供的特征提取操作的流程图;
26.图3示出了本公开至少一实施例提供的一种语音识别过程的流程图;
27.图4示出了本公开至少一实施例提供的另一种语音识别过程的流程图;
28.图5示出了本公开至少一实施例提供的再一种语音识别过程的流程图;
29.图6示出了本公开至少一个实施例提供的一种语音识别装置的示意框图;
30.图7为本公开一些实施例提供的一种电子设备的示意框图;
31.图8示出了本公开至少一个实施例提供的另一种电子设备的示意框图;
32.图9示出了本公开至少一个实施例提供的再一种电子设备的示意框图;以及
33.图10示出了本公开至少一个实施例提供的一种计算机可读存储介质的示意图。
具体实施方式
34.为使本公开实施例的目的、技术方案和优点更加清楚,下面将结合本公开实施例的附图,对本公开实施例的技术方案进行清楚、完整地描述。显然,所描述的实施例是本公开的一部分实施例,而不是全部的实施例。基于所描述的本公开的实施例,本领域普通技术人员在无需创造性劳动的前提下所获得的所有其他实施例,都属于本公开保护的范围。
35.除非另外定义,本公开使用的技术术语或者科学术语应当为本公开所属领域内具有一般技能的人士所理解的通常意义。本公开中使用的“第一”、“第二”以及类似的词语并不表示任何顺序、数量或者重要性,而只是用来区分不同的组成部分。同样,“一个”、“一”或者“该”等类似词语也不表示数量限制,而是表示存在至少一个。“包括”或者“包含”等类似的词语意指出现该词前面的元件或者物件涵盖出现在该词后面列举的元件或者物件及其等同,而不排除其他元件或者物件。“连接”或者“相连”等类似的词语并非限定于物理的或者机械的连接,而是可以包括电性的连接,不管是直接的还是间接的。“上”、“下”、“左”、“右”等仅用于表示相对位置关系,当被描述对象的绝对位置改变后,则该相对位置关系也可能相应地改变。
36.发明人发现相关技术中,为了实现语音识别功能,会采用一种识别模型来进行语音识别操作,并且,针对各种场景均使用一种固定的识别模型。若采用小体量的识别模型为识别模型,则其计算速度较快,但是准确度较低。若采用大体量的识别模型,虽然其准确度高但是计算量较大,增加了延迟。因此,采用一种固定的识别模型很难满足各种场景的需求,不能兼顾计算速度和准确度。
37.本公开至少一个实施例提供一种语音识别方法、语音识别装置、电子设备和计算机可读存储介质。该语音识别方法包括:获取待识别的语音信息;针对该待识别的语音信息,确定至少一个识别领域;从至少两个候选识别模型中,确定与该至少一个识别领域匹配的至少一个识别模型;利用该至少一个识别模型,对该待识别的语音信息进行识别,以得到语音识别结果。
38.该实施例的语音识别方法预先设置适配不同领域的至少两个候选识别模型,在识别过程中,选择与当前识别领域相匹配的识别模型进行识别操作,可以适用多种场景,在不降低准确度的前提下达到减少计算量的目的。
39.图1示出了本公开至少一实施例提供的一种语音识别方法的流程图。
40.如图1所示,该方法可以包括步骤s110~s140。
41.步骤s110:获取待识别的语音信息。
42.步骤s120:针对该待识别的语音信息,确定至少一个识别领域。
43.步骤s130:从至少两个候选识别模型中,确定与该至少一个识别领域匹配的至少一个识别模型。
44.步骤s140:利用该至少一个识别模型,对该待识别的语音信息进行识别,以得到语音识别结果。
45.例如,在步骤s110中,待识别的语音信息为音频数据,可以通过麦克风等语音接收器件来获取音频数据,或接收其它器件发送的音频数据。音频数据可以包括任意文件格式和编码的音频,例如为pcm(pulse code modulation,脉冲编码调制)音频数据或者wav数据(wave audio files,波形音频文件格式)。音频采样率例如为16000hz,位宽为16bit,单声
道。
46.例如,在步骤s120中,针对当前接收的待识别的语音信息,确定一个或多个与之相关的识别领域。例如,在语音交互模式下,识别领域可以包括交互的主题类型,可以用于指示当前交互的是哪种类型的话题,主题类型例如包括天气、音乐、导航等类型。
47.例如,在执行步骤s110之前,可以预先获取多个候选识别模型,以供语音识别过程中使用。例如,针对至少两个预设识别领域,分别训练得到对应的至少两个候选识别模型;基于该至少两个预设识别领域与该至少两个候选识别模型的对应关系生成领域与模型对应信息。
48.例如,如表1所示,可以预先设置r个识别领域(r为大于1的整数),作为上述的预设识别领域,r个预设识别领域例如可以包括导航领域、天气查询领域、音乐领域、火车票领域、车控领域等。例如,可以针对其中的每个预设识别领域,训练得到一个对应的识别模型,作为上述的候选识别模型。候选识别模型例如可以是神经网络模型,例如可以是卷积神经网络(cnn)、循环神经网络(rnn)、编码器-译码器等。针对每个预设识别领域,可以采用该领域相关的样本数据以及样本数据对应的标签数据训练得到对应的候选识别模型。例如,针对导航领域,利用导航领域的样本及标签训练得到识别模型d1;针对天气查询领域,利用天气查询领域的样本及标签训练得到识别模型d2,等等。然后,可以根据该r个预设识别领域与对应的r个候选识别模型生成表1,该表1可以作为上述的领域与模型对应信息,存储该表1以及r个候选识别模型的模型代码。
49.表1
50.预设识别领域候选识别模型导航识别模型d1天气查询识别模型d2音乐识别模型d3火车票识别模型d4
……
车控识别模型dr
51.例如,步骤s120得到的至少一个识别领域例如均为表1所包含的领域,这样,在步骤s130中,可以利用该领域与模型对应信息,确定与该至少一个识别领域匹配的至少一个识别模型,例如,针对每个识别领域,可以从表1中查找与该识别领域相对应的候选识别模型,作为与该识别领域相匹配的识别模型。
52.例如,在步骤s140中,可以调用该至少一个识别模型的模型代码,以执行识别操作,得到语音识别结果。
53.根据本公开至少一实施例的语音识别方法,预先设置适配不同领域的至少两个候选识别模型,在识别过程中,选择与当前识别领域相匹配的识别模型进行识别操作,可以适用多种场景,在不降低准确度的前提下达到减少计算量的目的。
54.例如,在一些示例中,步骤s120可以包括:基于该待识别的语音信息,确定该待识别的语音信息对应的意图信息;至少基于该意图信息,确定该至少一个识别领域。
55.例如,意图信息可以是待识别的语音信息中所提到的信息,用于表征用户进行本次语音交互的目的。例如,待识别的语音信息为“帮我查一下明天去x市的火车票”,则该条
语音信息对应的意图为查询火车票,根据该意图,可以确定对应的识别领域为火车票领域。
56.例如,可以通过以下步骤来确定意图信息:对该待识别的语音信息进行特征提取操作,得到特征数据;将该特征数据输入声学模型,以得到该声学模型的输出结果,其中,该声学模型的输出结果包括与该特征数据对应的字符;基于该声学模型的输出结果,解码得到该待识别的语音信息对应的k条字符序列;基于该k条字符序列,确定该意图信息;其中,k为正整数。
57.例如,对于特征提取操作,输入数据为音频数据(即待识别的语音信息),输出结果为特征数据,例如为fbank(filter-bank)特征数据,fbank是梅尔滤波器的功率谱的幅度平方求和后再取对数得到。该特征提取操作的功能是从音频数据中计算出特征数据,作为后续声学模型的输入。
58.上述以fbank作为示例,其它类型的特征数据,例如mfcc、pncc等,也可以适用。
59.图2示出了本公开至少一实施例提供的特征提取操作的流程图。
60.如图2所示,先对音频文件进行预加重,也就是对高频信号增强,再对预加重处理后的数据进行分帧和加窗,在分帧时,可以把音频信号按照例如10ms(毫秒)一帧分开。例如,若待识别的语音信息为“帮我查一下明天去x市的火车票”,其中,每个发音的时间可能是几百ms,在分帧时,每个音可能被分为十几帧或几十帧。为了防止2帧之间丢失信息,每次可以使用25ms的信号计算特征,也就是每次移动10ms,实际计算特征时使用的是25ms的信号。然后,再经过傅里叶变换从时域信号得到频域信号,也就是频谱。在经过取功率谱和幅度平方,累加某一时间的频域得到语谱,然后经过梅尔滤波器组把频率映射到梅尔频率标度,最后取对数得到fbank特征。梅尔滤波器组可以取80个,也就是每帧音频对应80个输出。
61.例如,在识别中可以使用多帧一起作为一次识别输入,例如使用67帧作为一次识别输入。
62.例如,声学模型的操作用于实现特征数据到字符的映射,该步骤的输入数据是上述的特征提取操作得到的特征数据(例如fbank特征数据),输出结果为每帧对应的字符以及字符的概率,形成时序标签矩阵。例如上述的特征提取操作得到了160帧fbank特征数据,可以将该特征数据输入声学模型,声学模型针对每帧均输出例如5000个字符(包括空白,即无字符)以及每个字符的概率,形成时序标签矩阵为[160,5000]。例如,沿用上述示例,待识别的语音信息为“帮我查一下明天去x市的火车票”,其中,“帮”例如被划分至了第1帧至第20帧,针对每帧可以得到5000条结果,针对其中的某一帧,得到的5000条结果例如为:“帮”的概率为0.8;“把”的概率为0.5;“班”的概率为0.3;
……
;空白的概率为0.001。
[0063]
例如,声学模型可以是神经网络模型,例如可以是基于transformer(一种注意力神经网络)的网络。可以预先利用样本数据和对应的标签数据对声学模型进行训练,在本公开实施例中,声学模型可以基于fbank特征数据进行建模,即样本数据可以是fbank特征数据。在另一些实施例中,声学模型还可以基于其他数据进行建模,例如基于音素建模的声学模型(例如kaldi模型)。
[0064]
例如,解码操作用于根据上述得到的时序标签矩阵找出k条最佳解码路径(即概率最高的k条解码路径)。该操作的输入是时序标签矩阵,例如若有160帧fbank特征数据,声学模型针对每帧输出5000个字符,则解码操作的输入矩阵为[160,5000],该解码操作的输出为k个最佳解码路径(top k解码路径)。
[0065]
例如,基于该声学模型的输出结果,解码得到该待识别的语音信息对应的k条字符序列,包括:执行多次解码操作,直至触发结束条件,以获得最后一次解码操作解码得到的多条字符序列以及该多条字符序列的排序,其中,该结束条件表征当前解码的语句结束,对于首次解码操作之后的每次解码操作,均基于上一次解码操作得到的多条非完整字符序列继续向后解码;其中,在该排序中,该多条字符序列按照质量由高至低排列,该k条字符序列为该排序中的前k条字符序列。
[0066]
例如,可以采用ctc(connectionist temporal classification)解码,ctc解码属于流式解码,针对部分音频帧推理、解码,并实时反馈解码结果给用户,因此,随着音频的持续输入,需要进行连续多次ctc解码。例如用户说“帮我查一下明天去x市的火车票”,流式识别的过程可能如下:
[0067]
第1次ctc解码:帮我;
[0068]
第2次ctc解码:帮我查一下;
[0069]
第3次ctc解码:帮我查一下明天;
[0070]
第4次ctc解码:帮我查一下明天去;
[0071]
第5次ctc解码:帮我查一下明天去x市;
[0072]
第6次ctc解码:帮我查一下明天去x市的;
[0073]
第7次ctc解码:帮我查一下明天去x市的火车票。
[0074]
例如,每次解码可以得到多条解码路径,上述7次ctc解码仅示出了其中一条解码路径。例如,在第1次ctc解码中,根据前若干帧,得到概率较高的字符为“帮”、“把”、“班”等,根据接下来的若干帧,得到概率较高的字符为“我”、“五”、“握”等,可以计算“我”、“五”、“握”等字符分别出现在“帮”、“把”、“班”等字符后边的概率,得到概率较高的若干条路径,例如得到概率最高的10条路径:“帮我”、“把我”、“把握”、
…
、“班五”,因此,该第1次ctc解码可以得到10条解码路径。在第2次ctc解码中,随着用户语音的持续输入,可以在上述10条解码路径的基础上进一步向后解码,例如同样得到10条最佳解码路径,其中一条解码路径例如为“帮我查一下”。以此类推,直至当前语句结束,得到最后一次ctc解码的多条解码路径(例如top10解码路径),即识别得到多个可能的句子,其中一条解码路径例如为上述的“帮我查一下明天去x市的火车票”。可以将最后一次ctc解码得到的k条最佳解码路径可以作为上述k条字符序列。
[0075]
例如,ctc解码过程可以使用贪心算法(greedy search)、束搜索算法(beam search)或者前缀束搜索算法(prefix beam search)。
[0076]
例如,对于贪心算法(greedy search),每一步保留最大概率的字符,算法简单,但是准确度降低。例如下表2是3个时刻也就是3个帧t1、t2、t3的概率,标签例如为3个:blank空白标签、a标签和b标签。如表2所示,t1帧是空白的概率为0.5,是a标签的概率为0.2,是b标签的概率为0.3;t2帧是空白的概率为0.4,是a标签的概率为0.3,是b标签的概率为0.3;t3帧是空白的概率为0.6,是a标签的概率为0.3,是b标签的概率为0.1。
[0077]
表2
[0078] t1t2t3blank0.50.40.6a0.20.30.3
b0.30.30.1
[0079]
例如,根据表2,计算每个标签的概率。对于blank空白标签,需要计算3个帧都是blank的概率,整个路径的概率(所有标签概率的乘积)为0.5*0.4*0.6=0.12。对于a标签,可以有“a
‑‑”
、
“‑‑
a”、
“‑a‑”
三种组合路径,
“‑”
代表blank空白标签,a标签的概率为这3种路径概率的和。“a
‑‑”
的概率为0.2*0.4*0.6=0.048,
“‑‑
a”的概率为0.5*0.4*0.3=0.06,
“‑a‑”
的概率为0.5*0.3*0.6=0.09,则这3种路径概率的和为0.09+0.048+0.06=0.198,作为a标签的概率。同理计算出标签为b的概率,然后比较blank空白标签、a标签和b标签的概率大小,例如标签为a的概率最大,则greedy search的解码结果为a。
[0080]
例如,greedy search选择的是每个时刻的最大概率的路径,但ctc解码的目的是选择整个过程概率最大的路线,二者有时并不是一致的。束搜索算法(beam search)可以应对这种不一致,每次保持k个最优的路线,而不仅仅是使用当前时刻概率最大字符,这里k是一个超参。beam search解码计算量更大,但是结果更准确。
[0081]
例如,对于前缀束搜索算法(prefix beam search),搜索每一步保留k个概率最大的分支,如果发现前面已经处理过的时间节点有相同的线路,则合并它们,prefix beam search解码准确度更高。
[0082]
例如,在解码得到k条字符序列之后,可以根据该k条字符序列,确定意图信息,例如可以利用其中最佳的一条字符序列(即top1解码路径)确定意图信息。将top1解码路径输入预先训练好的意图识别模型,该意图识别模型可以输出意图信息,该意图识别模型是语音识别过程中会使用到的模型,因此不用额外增加模型。例如,若top1解码路径为“帮我查一下明天去x市的火车票”,通过意图识别模型,可以得到意图信息为“查询火车票”,该意图信息对应的识别领域为“火车票”。
[0083]
例如,在一些实施例中,步骤s120可以包括:获取接收该待识别的语音信息的语音接收设备的当前状态信息和/或与该语音接收设备相关联的关联设备的当前状态信息;基于该语音接收设备的当前状态信息和/或该关联设备的当前状态信息,确定当前场景信息;至少基于该当前场景信息,确定该至少一个识别领域。
[0084]
例如,语音接收设备包括麦克风等语音接收器件,例如可以是汽车的中控屏幕、电脑等设备。关联设备可以是由语音接收设备控制的设备,用户可以通过语音接收设备来控制其关联设备。例如,在智能家居系统中,智能音响可以控制灯、扫地机器人、电视等设备,则这些设备可以作为智能音响的关联设备。在车载系统中,用户可以通过中控屏幕控制空调、座椅等设备,则这些设备可以作为中控屏幕的关联设备。
[0085]
例如,设备的当前状态信息可以包括设备当前执行的任务、开关机状态等。在一些实施例中,可以根据语音接收设备的当前状态信息来确定当前场景信息,例如,中控屏幕上正在运行的app为导航,则当前场景信息为“导航”,对应的识别领域为导航领域。再例如,中控屏幕上正在展示的界面为买火车票的界面,则当前场景信息为查询火车票,对应的识别领域为火车票领域。再例如,智能音响当前正在播放音乐,则当前场景信息可以为“音乐”,对应的识别领域为音乐领域。在另一些实施例中,可以根据关联设备的当前状态信息来确定当前场景信息,例如,与智能音响相关联的智能家居设备(例如扫地机器人)当前处于运行状态,则当前场景信息可以包括“智能家居控制”场景,对应的识别领域为智能家居领域。
[0086]
例如,在一些实施例中,步骤s120可以包括:获取在接收该待识别的语音信息之前
接收的至少一条历史语音信息对应的至少一个历史识别领域;至少基于该至少一个历史识别领域,确定该至少一个识别领域。
[0087]
例如,可以根据上下文来确定识别领域,历史语音信息可以是当前语音信息的前一轮交互的语音信息。根据历史语音信息确定上一轮交互的领域,比如用户上一轮说的语音内容为查询火车票,则上一轮领域为“火车票”领域。由于有些场景的对话是连续性的,例如用户订火车票需要经过多轮语音交互,咨询出发地、目的地、出发时间、车次车型等,连续多条语音信息对应的可能是同一个领域,当前对话可能是上一轮对话的延续,因此可以将上一轮的识别领域也作为当前可能的识别领域。
[0088]
例如,以上介绍了三种用于确定识别领域的方式,在一些实施例中,可以根据实际情况或者选择条件,从上述三种方式中选择一种方式来确定识别领域。例如,基于待识别语音信息对应的意图信息来确定识别领域的方式准确度较高,因此,在对准确度要求较高的场景中,可以使用这种方式来确定识别领域。再例如,根据历史语音信息确定识别领域的方式适用于连续对话的场景中,因此,若当前的待识别语音信息与上一条历史语音信息间隔时间小于某一阈值时,认为当前的语音信息与上一条语音信息之间存在关联,因此,可以选择上述根据历史语音信息确定识别领域的方式。
[0089]
例如,在一些实施例中,也可以结合两种或多种方式来共同确定识别领域,在以下的一些实施例中,以结合上述三种方式为例进行说明,但是本公开不限于此,除了上述介绍的三种方式之外,实际应用中,也可以结合其他方式。
[0090]
例如,步骤s120可以包括:获取m个参考信息,并分别基于该m个参考信息确定m个候选领域;基于该m个候选领域,确定该至少一个识别领域;其中,m为大于1的整数。例如,该m个参考信息包括以下信息中的至少一种:该待识别的语音信息对应的意图信息;基于接收该待识别的语音信息的语音接收设备的当前状态信息和/或与该语音接收设备相关联的关联设备的当前状态信息确定的当前场景信息;在接收该待识别的语音信息之前接收的历史语音信息对应的历史识别领域。
[0091]
图3示出了本公开至少一实施例提供的一种语音识别过程的流程图。
[0092]
如图3所示,例如,m个参考信息例如包括意图信息、当前场景信息和历史识别领域这三种参考信息。意图信息例如通过将音频进行特征提取操作、声学模型识别操作和ctc解码操作得到。根据每种参考信息可以得到至少一个候选领域,例如,根据意图信息得到第一候选领域,根据当前场景信息得到第二候选领域,以及根据历史识别领域得到第三候选领域。根据这三种参考信息确定候选领域的过程可以参见上述相关描述,在此不再赘述。每种参考信息的数量可以是一个或多个,针对每个参考信息可以确定一个对应的候选领域。例如,对于意图信息,可以选择top3解码路径,针对该三条路径分别确定三个意图信息,针对该三个意图信息分别确定三个第一候选领域。
[0093]
例如,步骤s120中的确定至少一个识别领域包括:确定一个识别领域。也就是说,在步骤s120中仅确定一个识别领域,在步骤s130中根据该一个识别领域确定一个对应的识别模型,在步骤s140中利用该一个识别模型进行识别操作以得到语音识别结果。
[0094]
例如,在仅确定一个识别领域的情况下,步骤s120可以包括:若该m个候选领域均为第一领域,则将该第一领域作为该识别领域;若该m个候选领域包括各不相同的n个候选领域,则从该n个候选领域中确定一个候选领域作为该一个识别领域;其中,n为大于1且小
于等于m的正整数。
[0095]
例如,若第一候选领域、第二候选领域和第三候选领域均为同一种领域,例如均为导航领域,则可以将该领域确定为最终的识别领域。若第一候选领域、第二候选领域和第三候选领域中存在多种不同的领域,则可以从该多种不同的领域中确定一种作为最终的识别领域。
[0096]
例如,从该n个不同的候选领域中确定一个候选领域作为该识别领域,可以包括:基于该m个候选领域,统计该n个候选领域各自的频次;将该n个候选领域中频次最高的候选领域作为该识别领域。
[0097]
例如,第一候选领域、第二候选领域和第三候选领域的数量均为一,若第一候选领域为导航领域,第二候选领域为导航领域,第三候选领域为天气查询领域,则导航领域的频次为2,天气查询领域的频次为1,导航领域的频次最高,因此可以将导航领域作为最终的识别领域。再例如,第二候选领域和第三候选领域的数量均为一,第一候选领域的数量为三,若三个第一候选领域均为导航领域,第二候选领域为导航领域,第三候选领域为天气查询领域,则导航领域的频次为4,天气查询领域的频次为1,导航领域的频次最高,因此可以将导航领域作为最终的识别领域。
[0098]
例如,在一些实施例中,从n个不同的候选领域中确定一个候选领域作为该识别领域,可以包括:基于该m个参考信息的优先权排序,确定该m个参考信息中优先权最高的参考信息;将该n个候选领域中与该优先权最高的参考信息对应的候选领域作为该识别领域。
[0099]
例如,在第一候选领域、第二候选领域和第三候选领域均不相同的情况下,可以根据优先权来确定识别领域。可以预先确定意图信息、当前场景信息和历史识别领域的优先权排序,例如,优先权从高至低依次为:意图信息、历史识别领域、当前场景信息。
[0100]
例如,在第一候选领域、第二候选领域和第三候选领域的数量均为一的情况下,若第一候选领域为导航领域,第二候选领域为音乐领域,第三候选领域为天气查询领域,由于意图信息的优先权最高,则可以将导航领域作为最终的识别领域。
[0101]
例如,在根据多个意图信息得到了多个第一候选领域,并且意图信息的优先权最高的情况下,若该多个第一候选领域均为同一种领域,则可以将该领域作为识别领域。若该多个第一候选领域包括两种或以上不同的领域,则可以根据其他条件(例如频次)从中选择一种作为识别领域。
[0102]
例如,该m个参考信息包括p个意图信息和q个其他信息,该m个候选领域包括分别与该p个意图信息对应的p个第一候选领域和分别与该q个其他信息对应的q个其他候选领域,p为大于1且小于m的整数,q为小于m的正整数。也就是说,第一候选领域的数量为多个。在一些实施例中,从n个不同的候选领域中确定一个候选领域作为该识别领域可以包括:若该p个第一候选领域中的至少一个候选领域与该q个其他候选领域中的至少一个候选领域均为第二领域,则将该第二领域作为该识别领域。
[0103]
例如,根据top3的意图信息得到了三个第一候选领域,例如分别为导航领域、车控领域和音乐领域。根据一个当前场景信息得到了一个第二候选领域,例如为导航领域。根据一个历史识别领域得到了一个第三候选领域,例如为天气查询领域。由于其中一个第一候选领域与第二候选领域均为导航领域,则可以将导航领域作为识别领域。
[0104]
例如,以上介绍了从n个不同的候选领域中选择一个作为识别领域的三种选择方
式,第一种选择方式为根据频次选择,第二种方式为根据优先权选择,第三种方式为根据多个第一候选领域中是否存在与其他候选领域相同的领域来选择。在实际应用中,可以根据实际情况或者条件,从这三种选择方式中选择一种使用,若使用一种方式不能确定最终的识别领域,则可以结合另外两种选择方式进行选择。
[0105]
例如,对于第一候选领域、第二候选领域和第三候选领域的数量均为一的情况,针对以上三种选择方式,可以优先使用第一种选择方式,即优先选取频次最高的候选领域作为识别领域。若三种候选领域均不重叠,即频次均为1,则可以进一步使用第二种选择方式,即选取其中优先权最高的候选领域(例如第一候选领域)作为识别领域。
[0106]
例如,对于第一候选领域的数量为多个的情况,针对以上三种选择方式,可以先确定该多个第一候选领域是否均相同,若该多个第一候选领域均相同,则将多个第一候选领域合并为一个领域,然后从该合并的领域、第二候选领域和第三候选领域中选择一个领域作为识别领域,例如可以优先选取其中频次最高的领域,或者可以选取其中优先权最高的领域。若该多个第一候选领域中存在不同,可以优先使用第三种方式,即确定该多个第一候选领域中是否存在与第二候选领域或第三候选领域相同的领域,若存在相同的领域,则将该领域作为识别领域。若该多个第一候选领域中不存在与第二候选领域或第三候选领域相同的领域,则可以结合频次信息和优先权信息来选取一种领域作为识别领域。基于这一方式,可以使得识别领域的准确性更高。
[0107]
例如,如图3所示,在得到识别领域之后,可以利用识别领域来选择识别模型,然后利用识别模型进行识别操作,得到语音识别结果。
[0108]
例如,识别模型可以包括语言模型。
[0109]
例如,语言模型可以使用加权有限状态转换器wfst(weighted finite state transducer)。wfst考虑了序列之间关系,也就是序列转移权重,组成句子的汉字前后上下文是有强相关的,比如“你”“好”2个字在句子中可能出现为“你好”和“好你”,前者明显要比后者概率要大,wsft就是这种解码方法,在整句的概率加上了前后字的转移概率。
[0110]
例如,在一些实施例中,在利用识别模型进行识别操作时,可以将上述声学模型的输出结果输入该语言模型,以得到该语言模型的输出结果,将该语言模型的输出结果作为该语音识别结果。例如,根据声学模型得到了每帧的字符及其概率,形成了时序标签矩阵,可以将该时序标签矩阵输入语言模型中,语言模型可以解码得到概率较高的多个句子,可以将其中概率最高的一个句子(即top1)作为语音识别结果。
[0111]
例如,在一些实施例中,在利用识别模型进行识别操作时,可以将上述解码操作获得的k条字符序列输入该语言模型,以得到该语言模型的输出结果,将该语言模型的输出结果作为该语音识别结果。例如,根据ctc解码操作得到了10条最佳解码路径,可以将该10条最佳解码路径输入语言模型,利用语言模型为该10条最佳解码路径进行重打分,可以将语言模型判定为分数最高的解码路径作为语音识别结果。
[0112]
例如,步骤s120中的确定至少一个识别领域包括:确定多个识别领域。也就是说,在步骤s120中确定多个识别领域。在这种情况下,若该m个候选领域包括各不相同的n个候选领域,则可以将该n个候选领域作为该多个识别领域。在步骤s130中,可以确定分别与该多个识别领域匹配的多个识别模型。在步骤s140中,分别利用该多个识别模型对该待识别的语音信息进行识别,以得到多个候选识别结果;基于该多个候选识别结果,确定该语音识
别结果。
[0113]
图4示出了本公开至少一实施例提供的另一种语音识别过程的流程图。
[0114]
如图4所示,根据意图信息、当前场景信息和历史识别领域分别得到第一识别领域、第二识别领域和第三识别领域。在该第一识别领域、第二识别领域和第三识别领域的数量均为一并且这三个识别领域均不同的情况下,可以根据第一识别领域、第二识别领域和第三识别领域分别匹配到第一识别模型、第二识别模型和第三识别模型。分别利用第一识别模型、第二识别模型和第三识别模型进行识别操作,以分别得到第一候选识别结果、第二候选识别结果和第三候选识别结果。最后,从该第一候选识别结果、第二候选识别结果和第三候选识别结果中确定一种结果作为最终的语音识别结果。
[0115]
例如,每种识别领域的数量可以为一个或多个,例如,第一识别领域的数量可以为三个,若该三个第一识别领域均不同,则可以针对三个第一识别领域得到对应的三种识别模型。若该三个第一识别领域中有两个识别领域相同并且该两个识别领域与另外一个识别领域不同,即该三个第一识别领域中存在两种不同的识别领域,则可以针对该两种不同的识别领域确定两种识别模型。
[0116]
图5示出了本公开至少一实施例提供的再一种语音识别过程的流程图。
[0117]
如图5所示,与图4不同的是,若第一识别领域和第二识别领域相同,则可以根据第一识别领域和第二识别领域确定一个识别模型。
[0118]
例如,针对每个识别模型,在利用识别模型得到候选识别结果的同时,还可以输出每个候选识别结果对应的得分,可以根据多个候选识别结果的得分,从中选择得分最高的候选识别结果作为该语音识别结果。基于这一方式,可以使得语音识别结果更为准确,且识别操作的时间更短。
[0119]
根据本公开实施例的语音识别方法,把一个固定的识别模型替换为多个可选的识别模型,根据当前场景、意图信息和用户交互上下文等条件选择一个或几个对应的识别模型进行识别操作,可以在不降低识别准确度的前提下,减少计算量。
[0120]
根据本公开实施例的语音识别方法,提供了可以用于确定识别领域的多种参考条件以及提供了从多个候选领域中选取识别领域的多种选择方式,可以根据实际情况灵活使用,满足多种场景需求。
[0121]
根据本公开实施例的语音识别方法,可以根据多种识别领域选择多种识别模型,并从多种识别模型得到的结果中确定分数最高的结果作为最终的语音识别结果,可以使得语音识别结果更为准确。
[0122]
图6示出了本公开至少一个实施例提供的一种语音识别装置200的示意框图。
[0123]
如图6所示,该语音识别装置200包括语音获取模块210、领域确定模块220、模型确定模块230和模型识别模块240。
[0124]
语音获取模块210配置为获取待识别的语音信息。语音获取模块210例如可以执行图1描述的步骤s110。
[0125]
领域确定模块220配置为针对所述待识别的语音信息,确定至少一个识别领域。领域确定模块220例如可以执行图1描述的步骤s120。
[0126]
模型确定模块230配置为从至少两个候选识别模型中,确定与所述至少一个识别领域匹配的至少一个识别模型。模型确定模块230例如可以执行图1描述的步骤s130。
[0127]
模型识别模块240配置为利用所述至少一个识别模型,对所述待识别的语音信息进行识别,以得到语音识别结果。模型识别模块240例如可以执行图1描述的步骤s140。
[0128]
例如,语音获取模块210、领域确定模块220、模型确定模块230和模型识别模块240可以为硬件、软件、固件以及它们的任意可行的组合。例如,语音获取模块210、领域确定模块220、模型确定模块230和模型识别模块240可以为专用或通用的电路、芯片或装置等,也可以为处理器和存储器的结合。关于上述各个单元的具体实现形式,本公开的实施例对此不作限制。
[0129]
需要说明的是,本公开的实施例中,语音识别装置200的各个单元与前述的语音识别方法的各个步骤对应,关于语音识别装置200的具体功能可以参考关于语音识别方法的相关描述,此处不再赘述。图6所示的语音识别装置200的组件和结构只是示例性的,而非限制性的,根据需要,该语音识别装置200还可以包括其他组件和结构。
[0130]
图7为本公开一些实施例提供的一种电子设备的示意框图。如图7所示,该电子设备300包括语音接收装置310和语音识别装置320。语音接收装置310配置为接收待识别的语音信息。语音识别装置320配置为执行上述任一实施例的语音识别方法。
[0131]
该电子设备300例如可以是计算机、平板电脑、手机、电视等设备,语音接收装置310例如为麦克风等能够接收音频数据的装置。语音接收装置310可以将接收的音频数据传输至语音识别装置320,语音识别装置320例如可以是cpu等处理器,能够在接收音频数据之后执行上述任一实施例的语音识别方法。
[0132]
本公开的至少一个实施例还提供了一种电子设备,该电子设备包括处理器和存储器,存储器存储有一个或多个计算机程序模块。一个或多个计算机程序模块被配置为由处理器执行,用于实现上述的语音识别方法。
[0133]
图8为本公开一些实施例提供的另一种电子设备的示意框图。如图8所示,该电子设备400包括处理器410和存储器420。存储器420存储有非暂时性计算机可读指令(例如一个或多个计算机程序模块)。处理器410用于运行非暂时性计算机可读指令,非暂时性计算机可读指令被处理器410运行时执行上文所述的语音识别方法中的一个或多个步骤。存储器420和处理器410可以通过总线系统和/或其它形式的连接机构(未示出)互连。
[0134]
例如,处理器410可以是中央处理单元(cpu)、图形处理单元(gpu)或者具有数据处理能力和/或程序执行能力的其它形式的处理单元。例如,中央处理单元(cpu)可以为x86或arm架构等。处理器410可以为通用处理器或专用处理器,可以控制电子设备400中的其它组件以执行期望的功能。
[0135]
例如,存储器420可以包括一个或多个计算机程序产品的任意组合,计算机程序产品可以包括各种形式的计算机可读存储介质,例如易失性存储器和/或非易失性存储器。易失性存储器例如可以包括随机存取存储器(ram)和/或高速缓冲存储器(cache)等。非易失性存储器例如可以包括只读存储器(rom)、硬盘、可擦除可编程只读存储器(eprom)、便携式紧致盘只读存储器(cd-rom)、usb存储器、闪存等。在计算机可读存储介质上可以存储一个或多个计算机程序模块,处理器410可以运行一个或多个计算机程序模块,以实现电子设备400的各种功能。在计算机可读存储介质中还可以存储各种应用程序和各种数据以及应用程序使用和/或产生的各种数据等。
[0136]
需要说明的是,本公开的实施例中,电子设备400的具体功能和技术效果可以参考
上文中关于语音识别方法的描述,此处不再赘述。
[0137]
图9为本公开一些实施例提供的再一种电子设备的示意框图。该电子设备500例如适于用来实施本公开实施例提供的语音识别方法。电子设备500可以是终端设备等。需要注意的是,图9示出的电子设备500仅仅是一个示例,其不会对本公开实施例的功能和使用范围带来任何限制。
[0138]
如图9所示,电子设备500可以包括处理装置(例如中央处理器、图形处理器等)510,其可以根据存储在只读存储器(rom)520中的程序或者从存储装置580加载到随机访问存储器(ram)530中的程序而执行各种适当的动作和处理。在ram 530中,还存储有电子设备500操作所需的各种程序和数据。处理装置510、rom 520以及ram530通过总线540彼此相连。输入/输出(i/o)接口550也连接至总线540。
[0139]
通常,以下装置可以连接至i/o接口550:包括例如触摸屏、触摸板、键盘、鼠标、摄像头、麦克风、加速度计、陀螺仪等的输入装置560;包括例如液晶显示器(lcd)、扬声器、振动器等的输出装置570;包括例如磁带、硬盘等的存储装置580;以及通信装置590。通信装置590可以允许电子设备500与其他电子设备进行无线或有线通信以交换数据。虽然图9示出了具有各种装置的电子设备500,但应理解的是,并不要求实施或具备所有示出的装置,电子设备500可以替代地实施或具备更多或更少的装置。
[0140]
例如,根据本公开的实施例,上述语音识别方法可以被实现为计算机软件程序。例如,本公开的实施例包括一种计算机程序产品,其包括承载在非暂态计算机可读介质上的计算机程序,该计算机程序包括用于执行上述语音识别方法的程序代码。在这样的实施例中,该计算机程序可以通过通信装置590从网络上被下载和安装,或者从存储装置580安装,或者从rom 520安装。在该计算机程序被处理装置510执行时,可以实现本公开实施例提供的语音识别方法中限定的功能。
[0141]
本公开的至少一个实施例还提供了一种计算机可读存储介质,该计算机可读存储介质存储有非暂时性计算机可读指令,当非暂时性计算机可读指令由计算机执行时可以实现上述的语音识别方法。
[0142]
图10为本公开一些实施例提供的一种存储介质的示意图。如图10所示,存储介质600存储有非暂时性计算机可读指令610。例如,当非暂时性计算机可读指令610由计算机执行时执行根据上文所述的语音识别方法中的一个或多个步骤。
[0143]
例如,该存储介质600可以应用于上述电子设备400中。例如,存储介质600可以为图8所示的电子设备400中的存储器420。例如,关于存储介质600的相关说明可以参考图8所示的电子设备400中的存储器420的相应描述,此处不再赘述。
[0144]
有以下几点需要说明:
[0145]
(1)本公开实施例附图只涉及到本公开实施例涉及到的结构,其他结构可参考通常设计。
[0146]
(2)在不冲突的情况下,本公开的实施例及实施例中的特征可以相互组合以得到新的实施例。
[0147]
以上所述,仅为本公开的具体实施方式,但本公开的保护范围并不局限于此,本公开的保护范围应以所述权利要求的保护范围为准。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1