从韵律特征预测参数化声码器参数的制作方法
本公开涉及从韵律特征预测参数化声码器参数。
背景技术:
1、语音合成系统使用文本到语音(tts)模型从文本输入生成语音。生成/合成的语音应该准确地传达消息(可理解性),同时听起来像人类语音(自然度),具有预期韵律(prosody)(表现力)。虽然传统的级联和参数合成模型能够提供可理解的语音并且语音神经建模的最新进展显著地提高合成语音的自然度,但大多数现有的tts模型在对韵律进行建模时无效,从而导致重要应用程序使用的合成语音缺乏表现力。例如,诸如会话助理和长格式读者的应用程序希望通过输入文本输入中未传达的韵律特征(诸如语调、重音,以及节奏和风格)来产生真实的语音。例如,简单的陈述能够用许多不同的方式说出,这取决于所述陈述是否是一个问题、一个问题的答案、陈述中是否存在不确定性,或传达输入文本未指定的关于环境或上下文的任何其它意义。
2、最近,已经开发变分自编码器来预测时长、基音轮廓(pitch contour)和能量轮廓的韵律特征,以有效地建模合成语音的韵律。虽然这些预测韵律特征足以驱动对语言和韵律特征操作的基于大型神经网络的声学模型,诸如wavenet或wavernn模型,但这些预测韵律特征不足以驱动需要许多附加声码器参数的参数化声码器。
技术实现思路
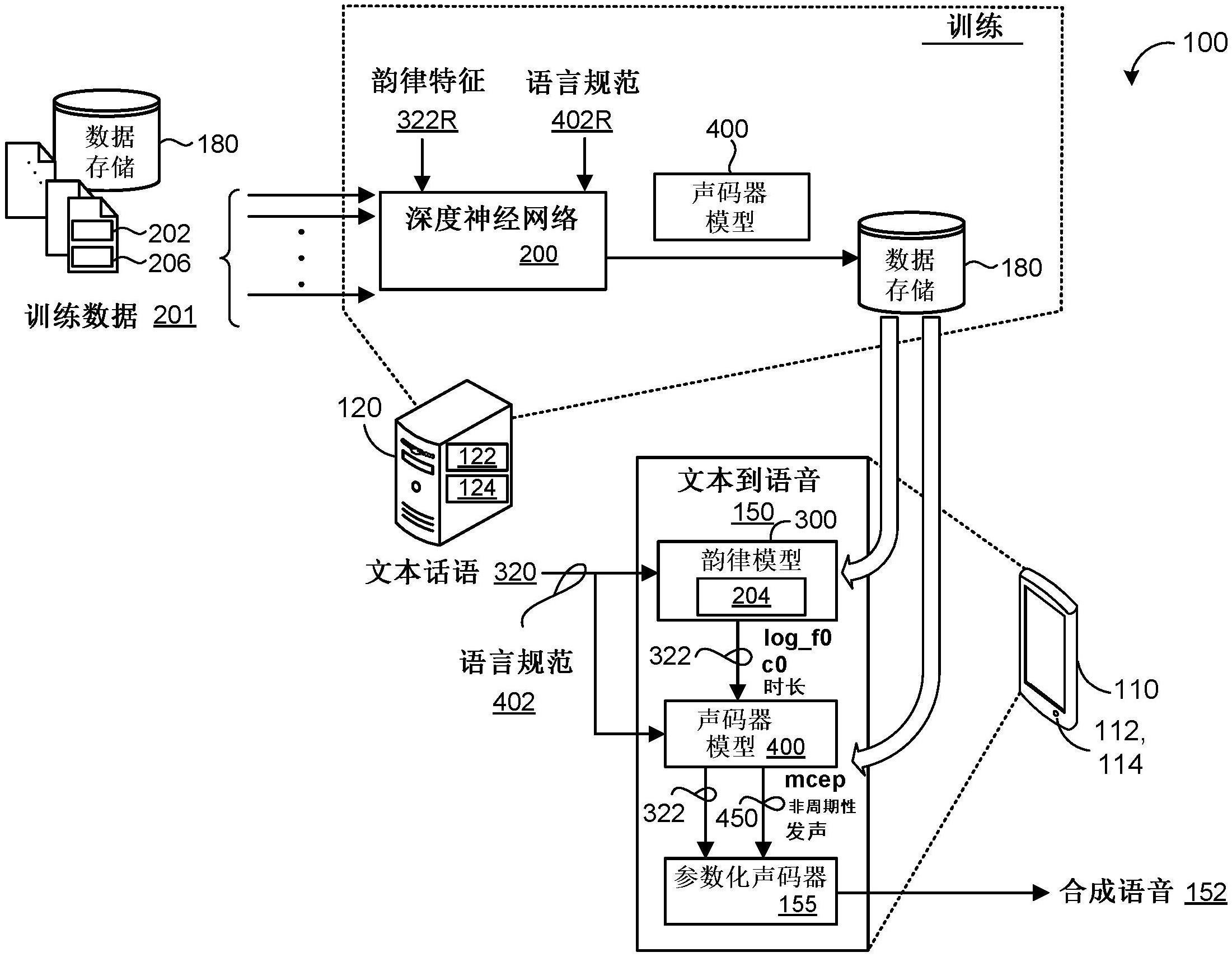
1、本公开的一个方面提供了一种用于从韵律特征预测参数化声码器参数的方法。所述方法包括在数据处理硬件处接收具有一个或多个词的文本话语,每个词具有一个或多个音节,并且每个音节具有一个或多个音素。所述方法还包括在数据处理硬件处接收从韵律模型输出的韵律特征和文本话语的语言规范作为声码器模型的输入,所述韵律特征表示文本话语的预期韵律。韵律特征包括文本话语的时长、基音轮廓和能量轮廓,而文本话语的语言规范包括文本话语的句子级语言特征、文本话语的每个词的词级语言特征和文本话语的每个音节的音节级语言特征,以及文本话语的每个音素的音素级语言特征。所述方法还包括由数据处理硬件基于从韵律模型输出的韵律特征和文本话语的语言规范来预测声码器参数作为来自声码器模型的输出。所述方法还包括由数据处理硬件将从声码器模型输出的预测声码器参数和从韵律模型输出的韵律特征提供到参数化声码器。参数化声码器被配置成生成文本话语的具有预期韵律的合成语音表示。
2、本公开的实施方式可以包括以下任选特征中的一个或多个。在一些实施方式中,所述方法进一步包括在数据处理硬件处接收文本话语的语言规范的语言特征对齐激活作为声码器模型的输入。在这些实施方式中,预测声码器参数进一步基于文本话语的语言规范的语言特征对齐激活。在一些示例中,语言特征对齐激活包括词级对齐激活和音节级对齐激活。词级对齐激活各自将每个词的激活与词的每个音节的音节级语言特征对齐,并且音节级对齐激活各自将每个音节的激活与音节的每个音素的音素级语言特征对齐。此处,每个词的激活可以基于对应词的词级语言特征和文本话语的句子级语言特征。在一些示例中,词级语言特征包括从一系列词块嵌入获得的词块嵌入,所述一系列词块嵌入由转换器的双向编码器表示(bert)模型从文本话语生成。
3、在一些实施方式中,所述方法进一步包括由数据处理硬件选择文本话语的话语嵌入,所述话语嵌入表示预期韵律。对于每个音节,使用所选的话语嵌入,所述方法包括:由数据处理硬件通过用音节的对应韵律音节嵌入对音节中的每个音素的音素级语言特征进行编码来使用韵律模型预测音节的时长;由数据处理硬件基于音节的预测时长而预测音节的基音;以及由数据处理硬件基于音节的预测时长而生成多个固定长度的预测基音帧。每个固定长度的基音帧表示音节的预测基音,其中,作为声码器模型的输入接收的韵律特征包括针对文本话语的每个音节生成的多个固定长度的预测基音帧。在一些示例中,所述方法进一步包括对于每个音节,使用所选的话语嵌入:由数据处理硬件基于音节的预测时长而预测音节中的每个音素的能量水平;以及对于音节中的每个音素,由数据处理硬件基于音节的预测时长而生成多个固定长度的预测能量帧。每个固定长度的预测能量帧表示对应音素的预测能量水平。此处,作为声码器模型的输入接收的韵律特征进一步包括针对文本话语的每个音节中的每个音素生成的多个固定长度的预测能量帧。
4、在一些实施方式中,韵律模型并入分层语言结构来表示文本话语。分层语言结构包括:第一级,所述第一级包括表示文本话语的每个词的长短期记忆(lstm)处理单元;第二级,所述第二级包括表示文本话语的每个音节的lstm处理单元;第三级,所述第三级包括表示文本话语的每个音素的lstm处理单元;第四级,所述第四级包括表示每个固定长度的预测基音帧的lstm处理单元;以及第五级,所述第五级包括表示每个固定长度的预测能量帧的lstm处理单元。第二级的lstm处理单元相对于第一级的lstm处理单元更快地计时,第三级的lstm处理单元相对于第二级的lstm处理单元更快地计时,第四级的lstm处理单元相对于第三级的lstm处理单元更快地计时,并且第五级的lstm处理单元与第四级的lstm处理单元以相同速度计时并且相对于第三级的lstm处理单元更快地计时。在一些实施方式中,分层语言结构的第一级在单个第一遍次(pass)中生成文本话语的每个词的激活,分层语言结构的第二级在第一遍次之后的单个第二遍次中生成文本话语的每个音节的激活,分层语言结构的第三级在第二遍次之后的单个第三遍次中生成文本话语的每个音素的激活,分层语言结构的第四级在第三遍次之后的单个第四遍次中生成每个固定长度的预测基音帧的激活,并且分层语言结构的第五级在第三遍次之后的单个第五遍次中生成每个固定长度的预测能量帧的激活。
5、在一些示例中,声码器模型并入分层语言结构来表示文本话语。分层语言结构包括:第一级,所述第一级包括表示文本话语的每个词的长短期记忆(lstm)处理单元;第二级,所述第二级包括表示文本话语的每个音节的lstm处理单元;第三级,所述第三级包括表示文本话语的每个音素的lstm处理单元;以及第四级,所述第四级包括表示多个固定长度的语音帧中的每一个的lstm处理单元,第四级的lstm处理单元相对于第三级的lstm处理单元更快地计时。第二级的lstm处理单元相对于第一级的lstm处理单元更快地计时,第三级的lstm处理单元相对于第二级的lstm处理单元更快地计时,并且第四级的lstm处理单元相对于第三级的lstm处理单元更快地计时。在这些示例中,多个固定长度的语音帧中的每一个可以表示从声码器模型输出的预测声码器参数的相应部分。另外,在这些示例中,分层语言结构的第一级可以在单个第一遍次中生成文本话语的每个词的激活,分层语言结构的第二级可以在第一遍次之后的单个第二遍次中生成文本话语的每个音节的激活,分层语言结构的第三级可以在第二遍次之后的单个第三遍次中生成文本话语的每个音素的激活,并且分层语言结构的第四级可以在第三遍次之后的单个第四遍次中生成多个固定长度的语音帧中的每个固定长度的语音帧的激活。
6、所述方法可以进一步包括在数据处理硬件处接收训练数据,所述训练数据包括多个参考音频信号和对应转录。每个参考音频信号包括语音的口头话语并且具有对应韵律,而每个转录包括对应参考音频信号的文本表示。对于每个参考音频信号和对应转录对,所述方法可以包括:由数据处理硬件获得对应转录的参考语言规范和表示对应参考音频信号的对应韵律的参考韵律特征;以及由数据处理硬件使用深度神经网络来训练声码器模型,以根据参考语言规范和参考韵律特征生成一系列固定长度的预测语音帧,所述一系列固定长度的预测语音帧提供梅尔倒谱系数、非周期性分量和发音分量。在一些示例中,对于每个参考音频信号,训练声码器模型进一步包括:从对应参考音频信号对一系列固定长度的参考语音帧进行采样,所述一系列固定长度的参考语音帧提供参考音频信号的参考梅尔倒谱系数、参考非周期性分量和参考发音分量;在由声码器模型生成的一系列固定长度的预测语音帧与从对应参考音频信号采样的一系列固定长度的参考语音帧之间生成梯度/损失;以及通过声码器模型反向传播梯度/损失。
7、在一些实施方式中,所述方法进一步包括由数据处理硬件将从声码器模型输出的预测声码器参数拆分成梅尔倒谱系数、非周期性分量和发声分量。在这些实施方式中,所述方法还包括由数据处理硬件单独地去规范化梅尔倒谱系数、非周期性分量和发声分量。在这些实施方式中,所述方法还包括由数据处理硬件将从韵律模型输出的韵律特征、去规范化梅尔倒谱系数、去规范化非周期性分量和去规范化发音分量级联成声码器向量。在这些实施方式中,将从声码器模型输出的预测声码器参数和从韵律模型输出的韵律特征提供到参数化声码器包括将声码器向量提供到参数化声码器,作为用于生成文本话语的合成语音表示的输入。
8、本公开的另一方面提供了一种用于从韵律特征预测参数化声码器参数的系统。所述系统包括数据处理硬件和与数据处理硬件通信的存储器硬件。存储器硬件存储指令,当所述指令在数据处理硬件上执行时使数据处理硬件执行操作。所述操作包括接收具有一个或多个词的文本话语,每个词具有一个或多个音节,并且每个音节具有一个或多个音素。所述操作还包括接收从韵律模型输出的韵律特征和文本话语的语言规范作为声码器模型的输入,所述韵律特征表示文本话语的预期韵律。韵律特征包括文本话语的时长、基音轮廓和能量轮廓,而文本话语的语言规范包括文本话语的句子级语言特征、文本话语的每个词的词级语言特征、文本话语的每个音节的音节级语言特征,以及文本话语的每个音素的音素级语言特征。所述操作还包括基于从韵律模型输出的韵律特征和文本话语的语言规范来预测声码器参数作为来自声码器模型的输出。所述操作还包括将从声码器模型输出的预测声码器参数和从韵律模型输出的韵律特征提供到参数化声码器。参数化声码器被配置成生成文本话语的具有预期韵律的合成语音表示。
9、本公开的实施方式可以包括以下任选特征中的一个或多个。在一些实施方式中,所述操作进一步包括接收文本话语的语言规范的语言特征对齐激活作为声码器模型的输入。在这些实施方式中,预测声码器参数进一步基于文本话语的语言规范的语言特征对齐激活。在一些示例中,语言特征对齐激活包括词级对齐激活和音节级对齐激活。词级对齐激活各自将每个词的激活与词的每个音节的音节级语言特征对齐,并且音节级对齐激活各自将每个音节的激活与音节的每个音素的音素级语言特征对齐。此处,每个词的激活可以基于对应词的词级语言特征和文本话语的句子级语言特征。在一些示例中,词级语言特征包括从一系列词块嵌入获得的词块嵌入,所述一系列词块嵌入由转换器的双向编码器表示(bert)模型从文本话语生成。
10、在一些实施方式中,所述操作进一步包括选择文本话语的话语嵌入,所述话语嵌入表示预期韵律。在这些实施方式中,对于每个音节,使用所选的话语嵌入,所述操作还包括:通过用音节的对应韵律音节嵌入对音节中的每个音素的音素级语言特征进行编码来使用韵律模型预测音节的时长;基于音节的预测时长而预测音节的基音;以及基于音节的预测时长而生成多个固定长度的预测基音帧。每个固定长度的基音帧表示音节的预测基音,其中,作为声码器模型的输入接收的韵律特征包括针对文本话语的每个音节生成的多个固定长度的预测基音帧。
11、在一些示例中,所述操作进一步包括对于每个音节,使用所选的话语嵌入:基于音节的预测时长而预测音节中的每个音素的能量水平;以及对于音节中的每个音素,基于音节的预测时长而生成多个固定长度的预测能量帧。每个固定长度的预测能量帧表示对应音素的预测能量水平。作为声码器模型的输入接收的韵律特征进一步包括针对文本话语的每个音节中的每个音素生成的多个固定长度的预测能量帧。
12、在一些实施方式中,韵律模型并入分层语言结构来表示文本话语。分层语言结构包括:第一级,所述第一级包括表示文本话语的每个词的短期记忆(lstm)处理单元;第二级,所述第二级包括表示文本话语的每个音节的lstm处理单元;第三级,所述第三级包括表示文本话语的每个音素的lstm处理单元;第四级,所述第四级包括表示每个固定长度的预测基音帧的lstm处理单元;以及第五级,所述第五级包括表示每个固定长度的预测能量帧的lstm处理单元。第二级的lstm处理单元相对于第一级的lstm处理单元更快地计时,第三级的lstm处理单元相对于第二级的lstm处理单元更快地计时,第四级的lstm处理单元相对于第三级的lstm处理单元更快地计时,并且第五级的lstm处理单元与第四级的lstm处理单元以相同速度计时并且相对于第三级的lstm处理单元更快地计时。在一些实施方式中,分层语言结构的第一级在单个第一遍次中生成文本话语的每个词的激活,分层语言结构的第二级在第一遍次之后的单个第二遍次中生成文本话语的每个音节的激活,分层语言结构的第三级在第二遍次之后的单个第三遍次中生成文本话语的每个音素的激活,分层语言结构的第四级在第三遍次之后的单个第四遍次中生成每个固定长度的预测基音帧的激活,并且分层语言结构的第五级在第三遍次之后的单个第五遍次中生成每个固定长度的预测能量帧的激活。
13、在一些示例中,声码器模型并入分层语言结构来表示文本话语。分层语言结构包括:第一级,所述第一级包括表示文本话语的每个词的长短期记忆(lstm)处理单元;第二级,所述第二级包括表示文本话语的每个音节的lstm处理单元;第三级,所述第三级包括表示文本话语的每个音素的lstm处理单元;以及第四级,所述第四级包括表示多个固定长度的语音帧中的每一个的lstm处理单元,第四级的lstm处理单元相对于第三级的lstm处理单元更快地计时。第二级的lstm处理单元相对于第一级的lstm处理单元更快地计时,第三级的lstm处理单元相对于第二级的lstm处理单元更快地计时,并且第四级的lstm处理单元相对于第三级的lstm处理单元更快地计时。在这些示例中,多个固定长度的语音帧中的每一个可以表示从声码器模型输出的预测声码器参数的相应部分。另外,在这些示例中,分层语言结构的第一级可以在单个第一遍次中生成文本话语的每个词的激活,分层语言结构的第二级可以在第一遍次之后的单个第二遍次中生成文本话语的每个音节的激活,分层语言结构的第三级可以在第二遍次之后的单个第三遍次中生成文本话语的每个音素的激活,并且分层语言结构的第四级可以在第三遍次之后的单个第四遍次中生成多个固定长度的语音帧中的每个固定长度的语音帧的激活。
14、所述操作可以进一步包括:接收训练数据,所述训练数据包括多个参考音频信号和对应转录。每个参考音频信号包括语音的口头话语并且具有对应韵律,而每个转录包括对应参考音频信号的文本表示。对于每个参考音频信号和对应转录对,所述操作还可以包括:获得对应转录的参考语言规范和表示对应参考音频信号的对应韵律的参考韵律特征;以及使用深度神经网络训练声码器模型,以根据参考语言规范和参考韵律特征生成一系列固定长度的预测语音帧,所述一系列固定长度的预测语音帧提供梅尔倒谱系数、非周期性分量和发音分量。在一些示例中,训练声码器模型进一步包括:从对应参考音频信号对一系列固定长度的参考语音帧进行采样,所述一系列固定长度的参考语音帧提供参考音频信号的参考梅尔倒谱系数、参考非周期性分量和参考发音分量;在由声码器模型生成的一系列固定长度的预测语音帧与从对应参考音频信号采样的一系列固定长度的参考语音帧之间生成梯度/损失;以及通过声码器模型反向传播梯度/损失。
15、在一些实施方式中,所述操作进一步包括将从声码器模型输出的预测声码器参数拆分成梅尔倒谱系数、非周期性分量和发声分量。在这些实施方式中,所述操作还包括单独地去规范化梅尔倒谱系数、非周期性分量和发声分量。在这些实施方式中,所述操作还包括将从韵律模型输出的韵律特征、去规范化梅尔倒谱系数、去规范化非周期性分量和去规范化发音分量级联成声码器向量。在这些实施方式中,将从声码器模型输出的预测声码器参数和从韵律模型输出的韵律特征提供到参数化声码器包括将声码器向量提供到参数化声码器,作为用于生成文本话语的合成语音表示的输入。
- 还没有人留言评论。精彩留言会获得点赞!