多分辨率UNet去混响网络
多分辨率unet去混响网络
技术领域
1.本发明涉及语音处理领域,尤其是一种去混响网络,通过在不同的分辨率块中将语音频谱沿时间维度进行切块,并在不同的分辨率块之间加入信息交互,实现了不同分辨率块间信息的互补,有助于语音去混响性能的提升。
背景技术:
2.在实际生活中,人们的大部分时间处于室内环境中。在相对封闭的室内环境中,当人们使用手机或电话、视频会议时,声源发出的声音不仅会通过空气直接传入麦克风中(通常被称为直达声,direct sound),同时也会通过如墙壁、天花板、地板等表面的多次反射后传入麦克风中。麦克风接收到的信号是声源发出的原始声信号与其通过表面反射造成的原始声信号的延迟、衰减的集合,这种现象被成为混响。
3.对于听力正常的人群而言,混响将会严重的影响语音质量及语音可懂度,在混响时间较长的情况下影响更加严重,而对于听力受损的人群,混响的危害更甚。不仅如此,混响的存在还会对很多实际应用产生严重的影响,如被广泛应用于智能音箱及车内语音控制的语音识别系统(automatic speech recognition,asr),有助于听力受损者的助听器(hearing aids)以及麦克风拾音的声源定位系统(sound source localization)。
4.近些年,随着深度学习技术的迅速发展,大量基于深度学习的去混响方法被提出,这些方法也使去混响的性能有了巨大的提升。2014年,han等人首先提出使用深度神经网络(deep neural network,dnn)进行语音去混响;在观察到根据混响时间(t
60
) 选择合适的帧长和帧移能够提高去混响的性能后,wu等人将t
60
纳入特征选择和dnn 训练中;williamson等人首次在有监督学习中在复数域进行去噪声和去混响,通过在实数域和虚数域估计复数理想比率掩模(complex ideal ratio mask,cirm)共同增强语音的幅度谱和相位谱;zhao等人观察到在语音去混响任务上频谱映射优于时频掩蔽的方法,而在去噪声任务上时频掩蔽的方法优于频谱映射的方法,构建了一种双阶段的算法。
5.2015年以来,unet在医学图像分割领域取得重大突破,开启深度学习时代。在 2018年,ernst等人将unet网络引入语音去混响任务中。在unet中,首先对含混响语音频谱进行步长为2的下采样直至达到瓶颈特征。随后,将瓶颈特征经过上采样恢复到原始频谱形状。同时,为了减少由于下采样造成的重要信息损失,在下采样层与之对应的上采样层之间加入了跳跃连接。
6.然而,该方法将整个语音的频谱送入unet网络,缺乏局部信息从而可能导致次优的性能。
技术实现要素:
7.为了克服现有技术的不足,本发明提供一种多分辨率unet去混响网络。本发明提出的多分辨率unet(multi-resolution unet,mr-unet)去混响网络,能够很好地去除混响所带来的不利影响。基于unet的语音去混响网络虽然通过下采样层与上采样层之间的跳跃
连接减少了由于下采样造成的信息损失,但仍缺乏局部信息而可能导致次优的性能。针对此问题,本发明提出了多分辨率unet去混响网络,通过在不同的分辨率块中将语音频谱沿时间维度进行切块,并在不同的分辨率块之间加入信息交互,实现了不同分辨率块间信息的互补,有助于语音去混响性能的提升。
8.本发明解决其技术问题所采用的技术方案是:
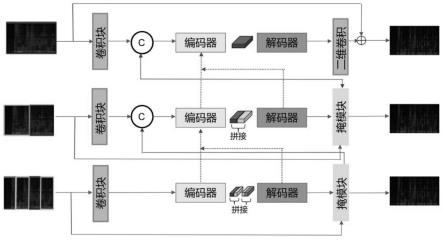
9.一种多分辨率unet去混响网络,包括三个分辨率块,每个分辨率块的输入特征为特定分辨率的时频特征,去混响网络采用编码器-解码器结构三个分辨率块分别称作 b1,b2和b3,其中每个分辨率块所输入的时频特征的分辨率均不相同,在分辨率块 b3中,输入特征沿着时间维度均匀切分为4个部分,每个部分经过卷积块(conv block, cb)以及编码器编码后沿时间维度进行两两拼接,拼接后的特征送入解码器进行解码,解码器的输出经过掩模块(mask block,mb)后得到b3的去混响结果;同理,分辨率块 b2中的输入特征被沿着时间维度切分为相同大小的2个部分,每个部分经过卷积块、编码器后沿时间维度拼接后,送入解码器进行解码,然后经过掩模块后得到b2的去混响结果;在分辨率块b1中不进行任何分割操作,直接经过编码器和解码器输出后,经二维卷积得到b1的去混响结果;通过信息的直接相加和通道拼接,将当前分辨率块输出的有用信息传递到下一分辨率块中,从而渐进式的提高mr-unet网络的去混响性能。
10.所述卷积块中,cb看作是在每个分辨率块中提取特征的由多个二维卷积层组成的残差网络;混响语音的幅度谱由x表示,cb的输出用z表示,则:
11.z=x+w
cb
x
ꢀꢀꢀꢀ
(1)
12.其中w
cb
表示cb的权重矩阵,将输入特征x经过二维卷积层跟参数化修正线性单元(parametric rectified linear unit,prelu)的结果再经过二维卷积层的输出称作为 x1,x1通过全局池化层得到x2,公式为:
[0013][0014]
其中h和w表示频谱的维度,x1(i,j)表示在时频点(i,j)处的频谱值;h
gp
是全局池化函数,有助于表示整个频谱的所有信息;
[0015]
为了充分利用全局池化后的信息,利用门函数以及sigmoid函数:
[0016]
x3=f(wuδ(wdx2))
ꢀꢀꢀꢀꢀꢀꢀꢀ
(3)
[0017]
其中f(
·
)表示sigmoid激活函数,δ(
·
)表示线性修正单元(rectified linear unit, relu)激活函数,wd表示在全局池化后的第一个二维卷积层,下采样率为r,wu表示全局池化后的第二个二维卷积层,上采样率为r,最终,得到:
[0018]
z=x+x1x3ꢀꢀꢀꢀꢀꢀ
(4)
[0019]
其中z为卷积块的输出结果。
[0020]
所述掩模块中,当前分辨率块未处理幅度谱与中间产物经过1
×
1卷积后的结果相加,得到当前阶段的处理后的幅度谱,所得到的当前阶段的处理后的幅度谐将通过1
×
1 卷积以及sigmoid激活函数与中间产物经过二维卷积后的结果进行掩模处理;掩模处理后的结果在经过残差连接后将与下一分辨率块的未处理幅度谱进行通道连接,掩模块的好处在于在当前分辨率块抑制信息量较小的特征,只允许有用的特征传播到下一分辨率块。其中“当前分辨率块未处理幅度谱”和“下一分辨率块未处理幅度谱”指的是两个相邻的分辨率
块的未处理的含混响语音幅度谱。“中间产物”指的是当前分辨率块中的解码器的输出,“处理后幅度谱”指的是估计的去混响语音的幅度谱。
[0021]
在每个分辨率块,采用u-net网络,将卷积块堆叠起来形成多卷积块(multi-convblock,mcb),mcb中不含有下采样操作,从而不会损失频谱信息,每个mcb中包含8个cb以及一个二维卷积层,mcb的输入与输出通过残差连接连接起来,使用3 个mcb代替unet。
[0022]
多分辨率unet去混响网络所采用的损失函数为:
[0023][0024]
其中l
mr-unet
表示mr-unet的损失函数,r表示一个分辨率块的分辨率,表示该分辨率块所估计的去混响语音,y表示直达声语音的幅度谱,lr表示为:
[0025][0026]
其中ε设置为10-3
。
[0027]
本发明的有益效果在于由于使用了多分辨率特征,将下层分辨率块中的信息与上层分辨率块之间的信息进行交互,从而渐进式的提高了去混响的性能,解决了基线方法中采用单分辨率特征带来的性能局限问题。本发明所提出的去混响网络在实际录制的强混响环境中进行了实验验证,实验结果表明所提出的去混响网络仍然有很好的去混响性能,解决了原有方法在强混响环境中性能较差的问题。
附图说明
[0028]
图1是本发明mr-unet的结构框图。
[0029]
图2是本发明卷积块的结构框图。
[0030]
图3是本发明掩模块的结构框图。
[0031]
图4是本发明不同分辨率块之间信息融合的结构框图。
[0032]
图5是本发明多卷积块的结构框图。
[0033]
图6为样例语音使用各去混响算法后的频谱图,其中图6(a)为混响语音频谱图 (t60=756ms),图6(b)为直达声语音频谱图,图6(c)为wpe(1ch)去混响语音频谱图,图6(d)为lstm去混响语音频谱图,图6(e)为late-lstm去混响语音频谱图,图6 (f)为unet去混响语音频谱图,图6(g)为skipconvnet去混响语音频谱图,图6(h) 为mr-unet去混响语音频谱图。
具体实施方式
[0034]
下面结合附图和实施例对本发明进一步说明。
[0035]
图1展示了本发明所提的mr-unet去混响网络的结构框图。本发明所提出的 mr-unet分为三个分辨率块,每个分辨率块的输入特征是特定分辨率的时频特征,去混响网络使用编码器-解码器结构的神经网络,即unet网络。输出是当前分辨率块下的去混响输出结果。具体来讲,由上至下将三个分辨率块分别称作b1,b2和b3,其中每个分辨率块所输入的时频特征的分辨率均不相同。在b3中,输入特征沿着时间维度均匀切分为4个部分,每个部分经过卷积块(conv block,cb)以及编码器编码后沿时间维度进行两两拼接,拼接后的特
(multi-conv block,mcb),mcb中不含有下采样操作,从而不会损失频谱信息。mcb 的结构框图如图5所示,每个mcb中包含8个cb以及一个二维卷积层,mcb的输入与输出通过残差连接连接起来。使用3个mcb去代替unet;
[0048]
所提出的mr-unet的损失函数为:
[0049][0050]
其中l
mr-unet
表示mr-unet的损失函数,r表示一个分辨率块的分辨率,表示该分辨率块所估计的去混响语音,y表示直达声语音的幅度谱,lr表示为:
[0051][0052]
其中ε在所有实验中被设置为10-3
。
[0053]
本发明在仿真混响数据集以及实录混响数据集下评估mr-unet方法的去混响结果。
[0054]
在仿真的混响数据集下,设计了一系列的实验以评估所提出的mr-unet网络,其评分结果如表1所示,黑体数字表示性能最好,所有的指标都是得分越高,所对应的语音质量越好。明显看出mr-unet在所有指标上都比所比的所有基线系统的得分更高,性能更好。
[0055]
表1仿真混响的数据集下stoi、pesq、fwsegsnr的平均得分
[0056][0057]
在图6中,从仿真数据集中随机选择一个样本来直观表明本发明提出的mr-unet 算法去混响的有效性。图6(a)是混响语音的幅度谱,图6(b)是所对应的干净语音的幅度谱。图6(c),(d),(e),(f),(g)和(h)分别展示了用wpe(1ch),lstm,late-lstm, unet,skipconvnet和mr-unet去混响得到的处理后语音的幅度谱。显然,mr-unet 在抑制由混响造成的拖尾效应上表现的最好。
[0058]
图6仿真混响数据集中样品的频谱图,其中(a)混响语音频谱图(t
60
=756ms),(b) 直达声语音频谱图,(c)wpe(1ch)去混响语音频谱图,(d)lstm去混响语音频谱图, (e)late-lstm去混响语音频谱图,(f)unet去混响语音频谱图,(g)skipconvnet去混响语音频谱图,(h)mr-unet去混响语音频谱图
[0059]
为了验证本发明所提出的mr-unet在实际环境中的去混响效果,记录了在实录混响数据集下,各去混响算法的stoi,pesq及fwsegsnr得分。
[0060]
下面结合附图和实施实例,对本发明作进一步详细的描述。但是所描述的具体实施实例仅仅用以解释本发明,并不用于限制本发明的范围。此外,在以下说明中,省略了对
公知结构和技术的描述,以避免不必要地混淆本发明的概念。
[0061]
在使用仿真方法产生的房间冲激响应以及实际房间中录制的情景下,分别评估了本发明所提出的mr-unet网络的去混响性能。在仿真环境下,使用librispeech数据集进行仿真。该数据集是包含大约1000小时的英语语音的大型语料库。该语料库的训练部分分为了100小时,360小时和500小时三个子集。其中,录音质量更高,口音更接近美国口音的将被选入前两个子集。通过在wall street journal(wsj)的si-84模型上训练的声学模型识别数据集中的音频,用二元语言模型估计相应书的文本。根据自动翻译的文本和参考文本计算词错误率(word error rate,wer)。根据wsj模型的翻译结果对数据集中的说话人进行排名,词错误率较低的说话人被分为“clean”,词错误率较高的被分为“other”。从“clean”部分的说话人中随机挑选20名男性和20名女性组成开发集。组成测试集的方式与组成开发集的方式相同。对于测试集或者开发集中的说话人,每个人大约使用8分钟的音频。总共大约是5小时20分钟。“clean”部分中的其余音谱被随机分为两个训练集,分别大约是100小时和360小时,为了避免每个说话人说话时被随机分为两个训练集,分别大约是100小时和360小时,为了避免每个说话人说话时长的不平衡,每个说话人的音频被限制在25分钟左右。“other”部分也同样被划分为测试集和开发集以及大约500小时的训练集。在“other”部分中,测试集和开发集并不是被随机挑选的,而是选择了挑战性更大的数据。对wsj模型计算的wer 进行排名,测试和开发集中的说话人是从排名的后四分之一中随机选择。表2提供了数据集中所有子集的简要描述。
[0062]
表2 librispeech子集简述
[0063][0064]
基于librispeech数据集,通过镜像声源法仿真了房间冲激响应rir,生成了小规模的含混响的librispeech数据集。从librispeech中随机选择了7000句干净语音作为训练集,4000句话作为测试集,7000句话作为验证集。每句干净语音所对应的房间冲激响应的房间设置和麦克风-声源的位置都是随机的。其中,房间长度在3米到10米,宽度在3米到8米,高度在2.5到6米的范围内随机挑选。房间内麦克风和声源在距离墙壁大于0.3米的范围内随机选择,声源和麦克风之间的距离在0.5米到10米的范围内,混响时间在0.4秒到1.2秒的范围内。数据集中每句话的采样频率为16000hz,每句话长度被裁剪为4秒的长度。仿真数据集的实验设置如表3所示。
[0065]
另外,将本发明所提出的mr-unet在libri-adhoc40上进行了训练和验证。 libri-adhoc40在实际会议室场景下使用扬声器播放librispeech语料,通过40个麦克风采集重放语音所产生的数据集。其中会议室可以大体看作一个长方体,房间高度9.8 米,宽度10.3
米,高度4.2米。房间中混响十分严重,混响时间t
60
大约0.9秒,几乎没有加性噪声。麦克风及声源距离相距0.8米至7.4米。房间中麦克风位置固定,扬声器在9个位置分别放置。
[0066]
表3仿真数据集的实验设置
[0067][0068]
值得注意的是,每个位置的扬声器朝向不同,在其中一个位置扬声器在两个相反朝向分别播放。所播放的音频来源librispeech的“train-clean-100”,总共包含251个说话人。每个位置大约播放20至40个说话人的音频。在验证集和测试集中扬声器有3 个位置与训练集中扬声器的位置及朝向均相同,另外在验证集和测试集中使用了新的 5个位置以防止训练集和测试集以及验证集有重复。所播放的音频来源librispeech中的“dev-clean”和“test-clean”,验证集和测试集均包含40个说话人的音频。libri-adhoc40 的无混响语音在长11.8米,宽4.2米,高3.8米的消声室内录制,麦克风和声源距离 0.4米,音量设置与会议室相同。由于本发明的实验主要聚焦在单通道去混响的问题上,因此每句话从40个麦克风中随机挑选一个麦克风所录制的含混响语音构成实验所用数据集。最终本发明的实验中所用到的实录数据集训练集包含28540句话,测试集包含2621句话,验证集包含2704句话。所有句子的采样率均为16000hz。
[0069]
实验设置:
[0070]
对于实验中所采用的16k采样率的语音信号,使用帧长16毫秒,帧移8毫秒的汉宁窗进行加窗处理,随后对每一帧使用256点的快速傅里叶变换(fast fouriertransform,fft)使其每帧含有129个频率点。使用最大-最小化归-化压缩其动态范围至0~1。所提出的mr-unet以4的批大小训练了100轮次。实验中所用的优化器为 adam优化器,参数β1设置为0.9,参数β2设置为0.999。网络初始学习率为2
×
10-4
,通过余弦退火策略逐步衰减到最低学习率1
×
10-6
。其中共计预热5250步。最终选择使用 pesq、stoi以及fwsegsnr指标评估去混响的效果。
[0071]
实验结果:
[0072]
(1)仿真的混响数据集下的结果
[0073]
在仿真混响数据集以及实录混响数据集下评估本发明所提出的mr-unet方法的去混响结果。
[0074]
在仿真的混响数据集下,设计了一系列的实验以评估所提出的mr-unet方法,计算出了提出的mr-nuet的去混响算法在每个句子上的stoi、pesq、fwsegsnr的得分,所有的指标都是得分越高,所对应的语音质量越好。表1列出了在仿真的混响数据集上所有语句的stoi、pesq、fwsegsnr的平均得分。相比于混响语音,除了lstm 去混响算法只在pesq上有所提升,其他所有的去混响算法在stoi、pesq和 fwsegsnr上均有提升。所提出的mr-unet在三个去混响指标的得分上超过了所有的基线系统。平均来说,对比于未处理的含混响语音,mr-unet在stoi上提高了0.184, pesq上提高了0.61,fwsegsnr上提高了4.65分贝。相比于基线系统中效果最好的 u-net去混响算法而言,所提的算法在stoi上相对提升4.2%,pesq上相对提升11.2%, fwsegsnr上相对提升22%。另外,观察到u-net网络及其变种总体来讲去混响效果要优于lstm网络及其变种。单通道的wpe算法在去混响上效果并不明显。
[0075]
在图6中,从仿真数据集中随机选择一个样本来直观表明我们提出的mr-unet 算法去混响的有效性。图6(a)是混响语音的幅度谱,图6(b)是所对应的干净语音的幅度谱。图6(c),(d),(e),(f),(g)和(h)分别展示了用wpe(1ch),lstm,late-lstm,unet,skipconvnet和mr-unet去混响得到的处理后语音的幅度谱。显然,mr-unet 在抑制由混响造成的拖尾效应上表现的最好。对于其他的去混响算法而言,大多数算法都能够很好的去除混响。具体来讲,unet算法达到了次优的性能,然而同时也导致了轻微的频谱泄漏。相比于mr-unet算法而言,skipconvnet算法并没有非常清晰的恢复其频谱结构。lstm算法虽然相对清晰的恢复出了频谱结构,然而却同时引入了不容忽视的人工伪影。late-lstm算法表现的并不好,其原因可以在于所选取的样本不是非常合适。wpe算法在单通道上去混响效果不佳。总的来说,我们所提的 mr-unet算法虽然在低频部分仍不能令人满意,但仍在混响相对较大的混响条件下消除了大部分的混响效应,有着不错的去混响效果。
[0076]
(2)仿真混响数据集下的消融实验
[0077]
为了分析本发明所提出的mr-unet各部分的作用,就不同分辨率块的数目,不同分辨率块之间是否使用了信息融合以及掩模块,unet子网络以及怎样组合多卷积块子网络性能更好进行了消融实验。表4为仿真混响的数据集不同分辨率块数目下stoi、 pesq、fwsegsnr的平均得分。黑体数字表示性能最好。
[0078]
表4仿真混响的数据集不同分辨率块数目下stoi、pesq、fwsegsnr的平均得分
[0079][0080]
在表4中比较了在mr-unet中不同数目的分辨率块的去混响性能。实验结果表明,随着分辨率块数目的增多,stoi、pesq以及fwsegsnr的得分也会越来越高,然而同时网络的
参数量,即系统的复杂度也在提升。在mr-unet中使用4个分辨率块的结果相比于使用3个分辨率块的结果仅在stoi和pesq的得分上有略微的提升,在 fwsegsnr得分上甚至会略差一些,而网络的参数量却增加了23%。最终,我们均衡考虑了去混响的性能以及系统的复杂度,选择在mr-unet中使用三个分辨率块。
[0081]
表5仿真混响的数据集不同网络组合下的stoi、pesq、fwsegsnr的平均得分。
[0082][0083]
表5为仿真混响的数据集不同网络组合下的stoi、pesq、fwsegsnr的平均得分,展示了不同网络组合情况下的去混响性能,黑体数字表示性能最好。为了方便起见,将不同分辨率块间的信息融合写作“if"(informnation fusion),掩模块写作“mb”(mask block),多卷积块写作“mcb”(multi convolutional blocks)。“mr-unet-if-mb”表示不同分辨率块之间没有使用信息融合以及没有使用掩模块,“mr-unet-if”表示不同分辨率块之间没有使用信息融合,“mr-unet-mb”表示没有使用掩模块,“mr-unet”既使用了不同分辨率块之间的信息融合也使用了掩模块,“mr-unet+mcb”表示将u-net替换为mcb。从实验结果来看,不同网络组合之间的去混响效果差异并不是很大。具体来讲,不同分辨率块之间的信息融合以及掩模块带来的不同分辨率块之间的信息交互都对去混响性能有有限的作用。使用u-net作为每一个子阶段的去混响网络在fwsegsnr上的结果比于使用mcb作为每-一个子阶段的去混响网络的得分略高,而在stoi和pesq的得分上略低。总的来讲,不同分辨率块间的信息交互对最终的去混响性能有益,而mcb可以作为unet网络的另一种可代替性选择。
[0084]
(3)实录混响数据集下的结果
[0085]
为了验证本发明所提出的mr-unet在实际环境中的去混响效果,使用了实录混响数据集libri-adhoc40进行实验。表6列出了实录混响数据集下各去混响算法的stoi, pesq及fwsegsnr得分。从表中可以观察到所提出的mr-unet在stoi上比次优的基线系统40通道的wpe相对提升6.5%,在fwsegsnr上比次优的基线系统 skipcon-vnet相对提升15.7%,在pesq上与最好性能的skipconvnet几乎持平。这充分的证明了即使在混响十分严重的实际情况下,我们所提的去混响算法仍然能够实现很好的去混响水平。就去混响基线系统而言,基于u-net网络及其变种的去混响性能在各个指标上的性能仍然要优于基于lstm网络及其变种的性能,这与我们在仿真混响数据集下得到的结论相同。单通道的wpe算法的去混响性能不佳,但是如果使用了多通道的wpe后去混响效果有明显提升。
[0086]
表6实录混响的数据集下stoi、pesq、fwsegsnr的平均得分。
[0087][0088]
还测试了在实录混响数据集下的语音识别性能。所使用的语音识别系统的声学模型为使用librispeech数据集中960小时的带标注语音训练的conformer。语言模型为使用960小时librispeech中带标注语音的文本加上800m单词的纯文本语料训练的 transformer。解码算法为ctc-attention联合解码算法。这里所用的语音识别模型采用词错误率(worderrorrate,wer)作为评价指标:给定测试集s,语音识别模型在s,上的词错误率定义为其识别结果与其对应的真实标签序列y之间的平均编辑距离:
[0089][0090]
其中,表示测试集中的语句数量,|y|表示序列y的长度,ed(p,q)表示p和q 之间的编辑距离,即将p变为q所需的最小插入量、替换量和删除量。wer越低表示性能越好。
[0091]
表7列出了本发明所提出的mr-unet以及各去混响基线系统使用.上述语音识别系统所得到的wer结果。从表6中可以看出在仅使用单通道数据的情况下本发明所提的mr-unet达到了最低的wer。相比于性能最好的单通道去混响基线系统skipconvnet而言wer绝对提升6.46%。虽然mr-unet的wer比wpe(40ch)算法的wer高了2.43%,但是wpe(40ch)用到了40通道的信息,通道间的空间信息可能有助于语音识别系统wer的降低,这从侧面反映了mr-unet在单通道语音去混响上的有效性。
[0092]
表7实录混响的数据集下不同语音去混响算法的wer
[0093][0094]
本发明的上述具体实施方式仅仅用于示例性说明或解释本发明的原理,而不构成对本发明的限制,其他的任何未背离本发明的精神实质与原理下所作的改变、修饰、替代、组合、简化,均应为等效的置换方式,都包含在本发明的保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1