一种基于机器学习的电子病历语音交互设备的制作方法
1.本发明涉及电子病历领域,尤其涉及一种基于机器学习的电子病历语音交互设备。
背景技术:
2.在医生与患者的问诊过程中,医生更倾向于与患者面对面进行沟通以提供更好的诊疗服务。由于电子病历发展和医院规章制度的要求,医生需要面对越来越复杂的电子病历的录入,面对电脑的时间在问诊时间中的占比逐步增加。更低侵入性、更便捷的病历录入方式亟待研发,让问诊的过程更多的回归面对面交流。
3.随着语音识别技术与机器学习技术的成熟,利用更高语音识别率的语音识别技术和更懂上下文推理的人工智能帮助医生实现与患者对话同时自动写完病历的场景已逐步成为可能。
4.现有技术专利cn107564571a中使用麦克风设备通过语音的方式让医生在结构化病历模板中进行录入,专利cn113724695a仅通过医患双方语音对话判断身份并自动生成病历,均利用语音识别技术帮助医生达成与患者对话同时自动写完病历,但是存在以下缺陷:
5.1)语音识别在此期间起的作用是辅助录入,而不是辅助问诊过程,医生只是换了一种方式逐字逐句地念自己想要录入的病历;
6.2)仅通过医生与患者双方语音对话判断身份,误判率较高,且无法准确应对就诊过程中常见的有第三人闯入打断就诊对话的情况,这是在问诊对话过程中实现语音自动录入病历的重要问题。
7.3)医生说话会有口音和不同用词、缩略语习惯,提高识别率的学习算法是基于所有医生的修正结果,对于医生每个个体而言,语音录入依然存在着较高的错误率;
8.4)虽然监督学习对于算法的进化有较高的提升,但需要额外的流程来参与提示对错,成本较高。
技术实现要素:
9.本发明要解决的技术问题是提供一种基于机器学习的电子病历语音交互设备,基于机器自动学习实现电子病历的准确高效的自动生成。
10.本发明为解决上述技术问题而采用的技术方案是提供一种基于机器学习的电子病历语音交互设备,包括语音输入装置、客户端和服务端,所述客户端部署有电子病例系统,所述服务端部署有语音分词系统、录入采样系统和机器学习系统;所述语音输入装置采集语音信息;所述语音分词系统将语音信息转换为文本信息并将文本信息处理生成电子病历后发送给电子病历系统;所述电子病例系统通过客户端展示电子病历并进行电子病历的修正;所述录入采样系统采集修正后的电子病历发送到语音分词系统处理后提供给机器学习系统进行模型训练;所述机器学习系统为语音分词系统提供声学模型、语言模型和书写模型;所述服务端中设置有诊疗语音数据库、诊疗文本数据库、字典、医学术语知识库、方言
语言库和标准病历范本库。
11.进一步地,所述语音分词系统包括语音识别模块和nlp模块;所述语音识别模块通过语音输入装置获取语音信息,所述语音信息包括问诊对话和口述病历;所述语音识别模块通过客户端连接的身份信息获取装置获取医患双方的身份信息;所述语音识别模块根据身份信息将问诊对话语音信息转换为带身份信息和时间信息的医患对话文本,所述语音识别模块将口述病历语音信息转换为带身份信息和时间信息的口述病历文本;所述nlp模块处理医患对话文本和/或口述病历文本生成电子病历后发送到电子病例系统。
12.进一步地,所述语音识别模块对语音信息进行声音向量转换后依次输入到声学模型中进行声学识别和语言模型中进行语言识别生成初步对话文本;同时所述客户端通过连接的身份信息获取装置监测是否有身份信息请求变动,所述电子病历系统监测是否有患者病历切换,结合初步对话文本判断是否有对话人物的转换,在初步对话文本中识别并剔除中途插入的与问诊不相关的对话内容,生成带身份信息和时间信息的医患对话文本。
13.进一步地,所述诊疗语音数据库储存有历史诊疗语音信息,所述声学模型由机器学习系统从诊疗语音数据库获取历史诊疗语音信息提取语音特征进行模型训练后得到;所述诊疗文本数据库储存有历史医患对话文本和口述病历文本,所述语言模型由机器学习系统从诊疗文本数据库获取历史医患对话文本和口述病历文本进行模型训练后得到;所述字典连接声学模型和语音模型,存储语音与文本的对应关系。
14.进一步地,所述nlp模块对医患对话文本进行分词识别医患对话文本中的关键字,根据关键字经由书写模型转换为日常书写行文风格的文字,结合电子病历书写要求填充电子病历的客观事实描述部分并发送到电子病历系统;所述电子病历的客观事实描述部分包括主诉部分、现病史部分和既往病史部分。
15.进一步地,所述nlp模块根据诊疗文本数据库和医学术语知识库对医患对话文本进行预处理和分词并获取关键字;然后通过规则描述语言设定的规则集对关键字进行医学命名的实体识别;再根据熵扩展的术语抽取算法,判断识别出来的是单个关键字还是复合关键字;最后通过通用词库过滤,去除掉常规关键字后进行电子病历标签的提取和标签向量的构建,通过书写模型根据电子病历的标签填充电子病历的各个部分。
16.进一步地,所述机器学习系统包括声学模型学习模块、语言模型学习模块和书写模型学习模块;所述医学术语知识库、方言语言库和标准病历范本库设置在机器学习系统中;所述声学模型学习模块利用语音输入装置采集的语音信息,生成关联身份信息的个性化的声学模型;所述语言模型学习模块通过已生成的医患对话文本与修正后的电子病历的比较调整语言模型;所述书写模型学习模块,通过已生成的电子病历与修正后的电子病历的比较调整书写模型。
17.进一步地,所述声学模型学习模块获取语音信息,根据语音特征区分语音信息对应的人物,建立初步的声学模型;同时获取语音信息中人物的身份信息;然后根据语音分词系统转换的文本信息进行语义推理,将语音信息与人物的身份信息对应;结合诊疗语音数据库储存的历史诊疗语音信息进行学习,更新语音信息中人物的语音个性化特征,生成个性化的声学模型。
18.进一步地,所述语言模型学习模块根据历史诊疗语音信息和历史医患对话文本,结合医学术语知识库与方言语音库,依据语音信息对应的时间信息和身份信息建立语言模
型,通过口述病历文本与修正后的病历文本的对比,更新语言模型中的个性化特征。
19.进一步地,所述书写模型学习模块根据电子病例系统的病历、标准病历范本库和医学术语知识库来建立个性化的书写模型;根据录入采样系统记录的病历的修改记录,更新优化书写模型。
20.本发明对比现有技术有如下的有益效果:本发明提供的基于机器学习的电子病历语音交互设备,语音分词系统结合医患对话内容、医患身份信息以及医患个性化语音特征三方面数据,更准确地识别对话人的身份,便于区分第三人,剔除干扰实现语音自动录入病历;机器学习系统建立医生个性化的声学模型与语言模型,更准确地识别医生的说话内容,避免因为医生各异的口音、用词、缩略语习惯造成的录入错误;机器学习系统自动学习,无需医生额外评判结果,随着使用时间的增长,对声音识别的声学模型、对语言组织的语音模型和病历生成的书写模型都更加精准;提高医生的看诊效率,提高电子病历的准确性。
附图说明
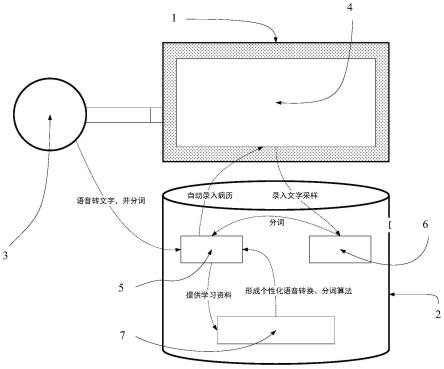
21.图1为本发明实施例的基于机器学习的电子病历语音交互设备结构示意图;
22.图2为本发明实施例的语音识别模块工作流程图;
23.图3为本发明实施例的语音识别模块原理图;
24.图4为本发明实施例的nlp模块工作流程图;
25.图5为本发明实施例的nlp模块原理图;
26.图6为本发明实施例的声学模型学习模块工作流程图;
27.图7为本发明实施例的声学模型学习模块学习过程图;
28.图8为本发明实施例的语言模型学习模块工作流程图;
29.图9为本发明实施例的语言模型学习模块学习过程图;
30.图10为本发明实施例的书写模型学习模块工作流程图。
31.图中:
32.1、客户端;2、服务端;3、语音输入装置;4、电子病历系统;5、语音分词系统;6、录入采样系统;7、机器学习系统。
具体实施方式
33.下面结合附图和实施例对本发明作进一步的描述。
34.图1为本发明实施例的基于机器学习的电子病历语音交互设备结构示意图。
35.请参见图1,本发明实施例的基于机器学习的电子病历语音交互设备,包括语音输入装置3、客户端1和服务端2,客户端1部署有电子病例系统4,服务端2部署有语音分词系统5、录入采样系统6和机器学习系统7;语音输入装置3采集语音信息;语音分词系统5将语音信息转换为文本信息并将文本信息处理生成电子病历后发送给电子病历系统4;电子病例系统4通过客户端1展示电子病历并进行电子病历的修正;录入采样系统6采集修正后的电子病历发送到语音分词系统5处理后提供给机器学习系统7进行模型训练;机器学习系统7为语音分词系统5提供声学模型、语言模型和书写模型。
36.服务端2中设置有诊疗语音数据库、诊疗文本数据库、字典、医学术语知识库、方言语言库和标准病历范本库。
37.各个部分的功能以及工作过程如下:
38.一、语音输入装置
39.语音输入装置3通过连接线与客户端1设备和/或服务端2设备(如电脑设备、移动设备等)相链接(如usb协议),以此来与客户端1和/或服务端2承载运行的系统进行数据交换,语音输入装置3内置麦克风收集来自医生、患者双方的对话,收集的数据由语音分词系统5进行处理。
40.二、电子病历系统
41.电子病历系统4部署在客户端1上由医生通过客户端1设备使用,可查看已经为患者录入的病历,也可以查看由语音分词系统5自动生成的电子病历是否准确,电子病历系统4可同时并列展示自动生成的电子病历以及对应的医患对话文本,同时支持医生在自动生成的电子病历基础上进行修正。
42.修正后的电子病历会通过接口传输至服务端2的录入采样系统6,待语音分词系统5处理生成机器学习系统7所需的学习资料。
43.在问诊过程中,电子病历系统4实时监测有无患者病历切换或身份信息请求变动,为语音分词系统5分析有无他人闯入对话提供日志分析依据。
44.三、语音分词系统
45.语音分词系统5包括语音识别模块和nlp(natural language processing,自然语言处理)模块;
46.语音分词系统5从语音输入装置3中获取来自医生、患者双方的对话语音信息,通过语音识别模块,将语音音素通过向量转换、声学模型识别、语言模型识别后转换为医患对话文本,其中声学模型和语音模型均依据机器学习系统7针对医患双方的语音特征进行优化。医患对话文本经过nlp模块的分词处理后,通过接口获取来自医患双方的身份信息,识别对话中的关键字,并依据关键字自动填充电子病历,最终医生可以在问诊结束后,在电子病历系统4中查看已经自动录入的电子病历。
47.语音识别模块
48.语音识别模块的作用是把获取的语音信息转换为带身份信息和时间信息的医患对话文本,具体流程如图2所示:语音识别模块从语音输入装置3中获取医患双方的语音,配合客户端1接口连接的身份信息获取设备如刷卡设备等获取就诊场景中医生、患者的身份信息。将语音音素通过向量转换后,输入到经过机器学习系统7个性化调优的声学模型和语音模型中,形成初步对话文本。结合语音特征以及对话的上下文通过电子病历系统4实时监测有无患者病历切换或身份信息请求变动,分析有无对话人物的转换,例如上一个患者是否已经结束问诊,有没有突然闯入的患者或医务人员等,在文本中剔除途中插入的与问诊不相关的对话内容。最终生成带时间信息与身份信息的医患对话文本。
49.语言识别模块的具体工作原理如图3所示:诊疗语音数据库储存有历史诊疗语音信息,声学模型由机器学习系统7从诊疗语音数据库获取历史诊疗语音信息,提取语音特征进行模型训练后得到;诊疗文本数据库储存有历史医患对话文本和口述病历文本,语言模型由机器学习系统7从诊疗文本数据库获取历史医患对话文本和口述病历文本进行模型训练后得到;字典连接声学模型和语音模型,存储语音与文本的对应关系。
50.nlp模块
51.nlp模块的作用是把语音识别模块输出的对话文本进行处理,并自动填充到电子病历中,具体流程如图4所示:nlp模块获取语音识别模块输出的医患对话文本,然后结合机器学习系统7中的医疗术语词库对医患对话文本进行分词,并识别关键字,获取原始关键对话素材,根据机器学习系统7个性化调优的书写模型转换为医生日常书写的行文风格的文字,同时将部分关键字依据电子病历书写要求转换为字典中的标准词条。生成的文字和字典自动填充到电子病历的各个字段中,包括主诉、现病史、既往史等不需要医生进行判断得出结论的客观事实描述部分的病历。最终在医生在问诊结束后通过查看电子病历系统4时确认自动填充的电子病历并进行修正调整。
52.此外,录入采样系统6将修正后电子病历的提供给机器学习系统7作为学习素材,也需要经过nlp模块分词后提供。
53.nlp模块的具体工作原理如图5所示:首先通过诊疗文本数据库和医疗术语词库,对医患对话文本进行预处理和分词;然后通过规则描述语言设定的规则集对数据进行医学命名的实体识别;再根据熵扩展的术语抽取算法,判断识别出来的是单个关键字还是复合关键字;最后通过通用词库过滤,去除掉常规的关键词,再进行标签提取。
54.标签提取过程,首先同样通过医疗术语词库,结合实体识别中获取的关键字,进行标签的提取和标签向量的构建,并进行量化操作,然后在标签与描述之间、标签与标签之间进行相关性的计算,构建病人病例。最终通过书写模型,对电子病历进行自动填充。
55.四、录入采样系统
56.录入采样系统6对医生录入的内容进行采样,包括医生已经录入的患者病历内容和自动生成后医生修正的内容(包含在电子病历系统4中对照原文时复制黏贴的文本),并增加相应的创建时间、修改时间,作为机器学习系统7把文字和语音进行关联分析学习的重要标记。采样后的文本,需经过语音分词系统5的nlp模块分词后,提供给机器学习系统7。
57.五、机器学习系统
58.机器学习系统7为语音分词系统5的工作提供针对医生、已就诊患者的个性化模型,模型的训练均基于语音信息、声音转换后的医患对话文本以及电子病历中录入的电子病历数据。个性化模型包括声学模型、语言模型和书写模型。所有的模型均采用静默自动化学习的原则,确保学习时人工介入的成本最小化。机器学习系统7包括声学模型学习模块、语言模型学习模块和书写模型学习模块。
59.声学模型学习模块
60.声学模型学习模块利用语音输入装置3采集的语音信息,生成了针对医生、已就诊患者的个性化声学模型,在语音识别模块进行声学识别时提供个性化声学模型,其工作流程如图6所示:声学模型学习模块获取语音输入装置3采集的医患双方的语音信息,首先区分语音信息中有哪些不同的人,建立初步的声学模型。同时获取就诊场景中的人物信息,例如依据当前就诊场景中的坐诊医生登录的账号获取相应医生的身份信息,依据刷卡设备上的患者就诊卡刷卡记录以及电子病历切换记录等行为获取相应患者的身份信息。而后由语音识别模块输出的医患对话文本进行语义推理,自动判断人物的具体身份,并同时建立语音历史记录。然后结合历史就诊产生的历史诊疗语音信息进行学习,新增或者更新说话人语音的个性化特征,生成个性化声学模型。采用自动化学习的原则,随着采集到的特定人物的语音数据量的增长,对于特定人物的声学模型也会越来越精准。
61.声学模型学习模块的具体学习过程如图7所示:首先对语音信息进行特征提取,并保存;然后使用mfcc(mel-scale frequency cepstral coefficients,梅尔倒谱系数,简称mfcc)提取语音特征参数;之后对mfcc方式提取的语音特征进行单因素和多因素训练;接着采用viterbi(维特比算法)强制对齐后进行深度神经网络训练;最后将处理完成的特征进行训练得到基于dnn神经网络的声学模型。
62.语言模型学习模块
63.语言模型学习模块利用已生成的医患对话文本与医生对自动生成的电子病历的修改操作、查看原文比对以及复制黏贴的操作产生的最后结果相比较,进而自动化调整语言模型。其工作流程如图8所示:语言模型学习模块先使用已生成的历史医患对话文本和历史诊疗语音信息,结合机器学习系统7中内置的医学术语知识库与方言语音库,依据时间线、身份信息区分语音中不同人物的语音,建立初步语言模型,而后利用已生成的医患对话文本与医生对自动生成的电子病历的修改操作、查看原文比对以及复制黏贴的操作产生的最后结果相比较,更新语言模型中的个性化特征。采用自动化监督学习,随着医生对病历的修正以及比对原文行为的增加,语言模型会越来越精确。语言模型学习模块的具体学习过程如图9所示。
64.书写模型学习模块
65.书写模型学习模块,利用医生对自动生成的电子病历的修改记录进行自动监督学习,自动调整书写模型。其工作流程如图10所示:书写模型学习模块先使用医生撰写的电子病历、机器学习系统7中的标准病历范本库和医学术语知识库来建立针对医生的个性化初步书写模型。利用录入采样系统6捕获的该医生对自动生成的电子病历的修改记录,更新个性化书写模块。采用自动化监督学习,随着医生对病历的修正行为的增加,书写模型会越来越精确。
66.本发明实施例的基于机器学习的电子病历语音交互设备,在实际使用时,医师在问诊前,插入语音输入装置3,并登录电子病历系统4中的账号开始看病,语音输入装置3开始收集语音信息,患者就诊时,通过刷卡设备确认患者身份信息,语音分词系统5对医患双方的语音信息进行分析,转换为医患对话文本,并依据医生的个性化书写风格生成符合要求的电子病历,在问诊结束后,由医生对电子病历进行修正。再此过程中,录入采样系统6对医生录入的内容和修改记录等进行记录采样,提供给机器学习系统7对语音识别、病历生成的相关模型进行进一步自动调优。
67.实施过程中,可进行一段时间的调优期,仅插入语音输入装置3捕获医患双方的语音信息,依然由医生手动在电子病历系统4上撰写病历,其录入的结果由录入采样系统6采样,由机器学习系统7预先自动训练相关的模型。学习十余例病例后,即可开放自动生成电子病历功能。
68.优选地,还可以增加身份认证系统,外置的语音输入硬件设备上除了语音输入外,还可增加按键交互模块、摄像头模块等。
69.医师的身份认证无需再使用电子病历的身份认证界面登录,可使用语音声纹认证登录,同时也为所有就诊的患者建立声音识别库,结合摄像头关注室内人员的进出情况进一步降低因问诊时意外闯入其他人导致的问诊对话识别错误的情况,并能大幅提升问诊记录准确性。
70.医师可采用按键交互模块或者自然语言指令(例如,等我看下你之前的化验报告)的方式命令电子病历系统4快速打开复诊患者的某一类或某一份病历,由此提升使用体验。
71.综上所述,本发明实施例的基于机器学习的电子病历语音交互设备,语音分词系统5结合医患对话内容、医患身份信息以及医患个性化语音特征三方面数据,更准确地识别对话人的身份,便于区分第三人,剔除干扰实现语音自动录入病历;机器学习系统7建立医生个性化的声学模型与语言模型,更准确地识别医生的说话内容,避免因为医生各异的口音、用词、缩略语习惯造成的录入错误;机器学习系统7自动学习,无需医生额外评判结果,随着使用时间的增长,对声音识别的声学模型、对语言组织的语音模型和病历生成的书写模型都更加精准;提高医生的看诊效率,提高电子病历的准确性。
72.虽然本发明已以较佳实施例揭示如上,然其并非用以限定本发明,任何本领域技术人员,在不脱离本发明的精神和范围内,当可作些许的修改和完善,因此本发明的保护范围当以权利要求书所界定的为准。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1