一种基于小波包分解特征参数的语音转换方法
1.本技术涉及语音转换领域,特别是一种基于小波包分解特征参数的语音转换方法。
背景技术:
2.语音转换技术是将a话者的语音转换为具有b话者发音特征的语音,保持语音内容不变。语音转换技术广泛应用于语音信号处理领域,此技术在帮助克服语言障碍、实时翻译、汽车驾驶、游戏娱乐等领域均有不同程度的应用价值。
3.韵律传达语言、准语言和各种类型的非语言信息,例如说话者身份、情感、意图、态度和情绪。韵律受到短期和长期依赖的影响。基音频率f0是关于语音声调的一个重要韵律因素,描述了从音节到整个话语的不同时域内音高的变化,应该用分层建模来表示,例如,在多个时间尺度上。目前一些语音转换方法使用连续小波变换(cwt)对基音频率进行分解,并采用不同的时间尺度表示,被证明对语音转换有效。
4.然而由于基音频率是不连续的,连续小波变换的方法需要对基音频率进行线性差值,归一化等处理,这会导致损失精度,并且小波分解只对低频部分进行进一步分解,容易丢失高频部分的信息,从而影响基音频率的转换效果。
5.小波包理论能够为基音频率提供一种更为精细的分析方法,即小波包变换既可以对低频部分进行分解,也可以对高频部分进行分解,而且小波包分解既无冗余,也无疏漏,所以对包含大量中、高频信息的信号能够进行更准确的时频局部化分析,以二层分解为例,小波和小波包的区别如图1所示。因此小波包分解是一种更广泛应用的小波分解方法。
技术实现要素:
6.本发明针对现有技术的存在的上述不足,提供一种基于小波包分解特征参数的语音转换方法。本发明提出:在训练阶段,对训练语音样本提取基音频率f0和平均功率谱npow,再以句为单位形成长时特征参数f0
lt
和npow
lt
,对其进行小波包分解后输入高斯混合模型训练得到转换函数;在转换阶段,对需转换的源说话人语音样本提取同类型f0
lt
和npow
lt
并进行小波包分解,经过转换函数转换后,进行小波包逆变换得到转换后的目标说话人基音频率f0,最终结合其余参数生成目标说话人语音。
7.本发明采用如下技术方案,一种基于小波包分解特征参数的语音转换方法,包括训练步骤和转换步骤:
8.训练步骤:
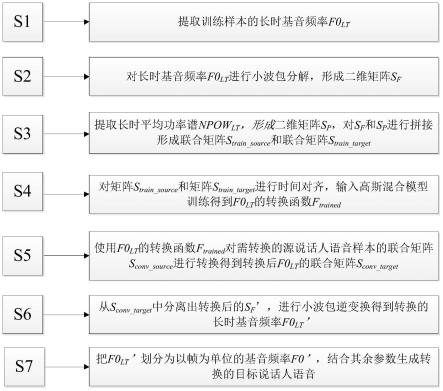
9.s1对训练语音样本提取基音频率特征f0并以句为单位形成长时基音频率f0
lt
;
10.s2对长时基音频率f0
lt
进行n层小波包分解,得到第n层各频段的分解值,将分解值组成二维矩阵sf;
11.s3提取训练样本的长时平均功率谱npow
lt
,对长时平均功率谱npow
lt
进行n层小波包分解,得到第n层上各个频段上的分解值,将分解值组成二维矩阵s
p
,把sf和s
p
拼接形成联
合矩阵s
train_source
和联合矩阵s
train_target
;
12.s4对矩阵s
train_source
和矩阵s
train_target
进行时间对齐后,输入高斯混合模型训练,得到长时基音频率f0
lt
的转换函数f
trained
;
13.语音转换步骤:
14.s5使用f0
lt
的转换函数f
trained
对需转换源说话人样本的联合矩阵s
conv_source
进行转换,得到转换后f0
lt
的联合矩阵s
conv_traget
;
15.s6从矩阵s
conv_traget
中的分离出转换后的s'f,对s'f进行小波包逆变换得到转换的长时基音频率f0'
lt
;
16.s7把f0'
lt
划分为以帧为单位的基音频率f0',最后结合其余参数生成转换后的目标说话人语音。
17.进一步的,上述的一种基于小波包分解特征参数的语音转换方法,训练步骤具体为:
18.s1-1对源说话人的训练样本与目标说话人的训练样本均进行语音句长时间范围的限制,限制语音句长时间范围在2~4秒,且每句样本中包含5~10个连续音节;
19.s1-2对被限定句长范围的源说话人的训练样本和目标说话人的训练样本分别提取基音频率f0,即先以帧为单位提取短时基音频率f0,然后把每一帧的基音频率f0按时间先后顺序组成一维向量f0
lt
,作为长时基音频率;
20.s2-1将长时基音频率f0
lt
序列进行n层小波包分解,得到第n层上所有2n个频段分量的一维向量s1,s2,...,sz(z的取值为2n),标号的顺序为所分频段由低频到高频排列,其中,si视为n层小波包分解树中的叶子节点,句长时间范围2~4秒对应小波包分解的层数n取值为3;
21.s2-2长时基音频率f0
lt
的小波包分解形成矩阵sf,sf=[s
1 s
2 ... sz]
t
;
[0022]
s3-1从被限定句长的源说话人训练样本和目标说话人训练样本中分别提取平均功率谱npow,以句为单位形成平均功率谱npow
lt
;
[0023]
s3-2对长时平均功率谱npow
lt
进行n层小波包分解,得到小波包分解后的二维矩阵s
p
;
[0024]
s3-3把矩阵sf和矩阵s
p
拼接形成联合矩阵s,s=[s
f s
p
];
[0025]
s3-4将从源说话人训练样本形成的联合矩阵标记为s
train_source
,将从目标说话人训练样本形成的联合矩阵标记为s
train_target
。
[0026]
s4-1使用动态时间规整方法对矩阵s
train_source
和矩阵s
train_target
进行时间对齐;
[0027]
s4-2对齐后分别输入高斯混合模型中进行训练,得到长时基音频率f0
lt
的转换函数f
trained
;
[0028]
进一步地,在训练步骤完成后,将得到的转换函数f
trained
运用到转换步骤,上述的一种基于小波包分解特征参数的语音转换方法,转换步骤具体为:
[0029]
s5-1对需转换的源说话人样本提取长时基音频率f0
lt
和长时平均功率谱npow
lt
;
[0030]
s5-2对基音频率f0
lt
进行n层小波包分解得到sf,对长时频谱包络npow
lt
进行n层小波包分解得到s
p
,对sf和s
p
进行拼接形成联合矩阵s
conv_source
;
[0031]
s5-3将联合矩阵s
conv_source
输入f0
lt
的转换函数f
trained
,输出转换后的联合矩阵s
conv_traget
;
[0032]
s6从转换后的联合矩阵s
conv_traget
=[sf' s
p
']中分离出sf'=[s1' s2' ... sz']
t
,将sf'中的各元素与n层小波包分解树的叶子节点相对应,进行小波包逆变换后得到转换的长时基音频率f0'
lt
;
[0033]
s7对转换后的长时f0'
lt
参数,按先后顺序每帧对应向量中一个元素,得到每一帧转换后的基音频率f0';最终结合频谱包络参数sp'和激励参数ap生成转换后的目标说话人语音;
[0034]
本发明的优点和积极效果:
[0035]
(1)本发明基于小波包分解特征参数的语音转换方法以句为单位对长时基音频率和平均功率谱进行小波包分解后转换,在转换中考虑了基音频率随时间变化因素,以及频谱参数对于韵律参数的影响,可进一步提高生成语音与目标说话人语音的韵律(如声调)相似度。
[0036]
(2)本发明基于小波包分解特征参数的语音转换方法采用小波包变换对长时特征进行分解后转换,对高频部分进行进一步分解,提取所有频段的信息,不丢失频率信息,在对基音频率进行小波包分解中避免小波分解必须先要对基音频率进行归一化,线性差值等操作,减少这些因素带来的误差,使得转换的效果大大提升。
附图说明
[0037]
图1是小波与小波包二层分解示意图,a)小波分解图,b)小波包分解图;
[0038]
图2为本发明基于小波包分解的语音转换方法的流程框图;
[0039]
图3为本发明基于小波包分解的语音转换方法的训练过程流程图;
[0040]
图4为本发明基于小波包分解的语音转换方法的转换过程流程图。
具体实施方式
[0041]
为了能够更清楚地理解本发明的上述目的、特征和优点,下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述。需要说明的是,在不冲突的情况下,本技术的实施例及实施例中的特征可以相互组合。显然,所描述的实施例仅是本发明一部分实施例,而不是全部的实施例,因此,本发明的保护范围并不受下面公开的具体实施例的限制。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
[0042]
名称说明:
[0043]
(1)高斯混合模型(gaussian mixture model,gmm):指用高斯概率密度函数(正态分布曲线)精确地量化事物,它是一个将事物分解为若干的基于高斯概率密度函数(正态分布曲线)形成的模型。gmm模型的训练就是给定一组训练数据,依据某种准则确定模型的参数。
[0044]
(2)动态时间归整(dynamic time warping,dtw):动态时间归整是基于动态规划(dynamic programming)的思想,解决了发音长短不一的模板匹配问题,在此专利中主要用于对发音长短不同的源说话人特征与目标说话人特征进行时间对齐。
[0045]
(3)world声码器:world声码器是一个纯信号处理的声码器。包括提取对应的声学特征以及将声学特征转换成波形的过程。world声码器提取的声学特征包括:每一帧的基频
(f0)、频谱包络(spectral envelope)和非周期比值(aperiodicity)。
[0046]
下面结合图2-图4和实施例对本发明的技术方案做进一步的说明。
[0047]
实施例1
[0048]
如图2,本发明实施例是一种基于小波包分解特征参数的语音转换方法,包括训练步骤和转换步骤,具体过程如下:
[0049]
图3为本发明涉及的方法的训练过程框图,包括以下具体步骤:
[0050]
s1对训练语音样本提取基音频率特征f0并以句为单位形成长时基音频率f0
lt
;
[0051]
s2对长时基音频率f0
lt
进行n层小波包分解,得到第n层各频段的分解值,将分解值组成二维矩阵sf;
[0052]
s3提取训练样本的长时平均功率谱npow
lt
,对长时平均功率谱npow
lt
进行n层小波包分解,得到第n层上各个频段上的分解值,将分解值组成二维矩阵s
p
,把sf和s
p
拼接形成联合矩阵s
train_source
和联合矩阵s
train_target
;
[0053]
s4对矩阵s
train_source
和矩阵s
train_target
进行时间对齐后,输入高斯混合模型训练,得到长时基音频率f0
lt
的转换函数f
trained
;
[0054]
图4为本发明涉及的方法的转换过程框图,包括以下具体步骤:
[0055]
s5使用f0
lt
的转换函数f
trained
对需转换源说话人样本的联合矩阵s
conv_source
进行转换,得到转换后f0
lt
的联合矩阵s
conv_traget
;
[0056]
s6从矩阵s
conv_traget
中的分离出转换后的s'f,对s'f进行小波包逆变换得到转换的长时基音频率f0'
lt
;
[0057]
s7把f0'
lt
划分为以帧为单位的基音频率f0',最后结合其余参数生成转换后的目标说话人语音。
[0058]
实施例2
[0059]
结合图3和图4,本实施例提供的一种基于小波包分解特征参数的语音转换方法是在实施例1的基础上提供从步骤s1到步骤s7的如下详细步骤:
[0060]
s1-1准备源说话人的训练样本和转换样本,准备目标说话人的训练样本和转换样本,对上述所有样本均进行语音句长时间范围的限制并形成以句为单位的样本数据,每句样本限制语音句长时间范围在2~4秒内,且每句样本中包含5~10个连续音节;
[0061]
s1-2利用world声码器分别对被限定句长范围的源说话人训练集样本和目标说话人训练样本进行预处理(分帧和加窗)后,先以帧为单位提取源说话人训练样本和目标说话人训练样本的基音频率f0和频谱包络sp。把每一帧的基音频率f0以句为单位按时间先后顺序组成一维向量f0
lt
作为长时基音频率;以帧为单位提取梅尔倒谱参数mcep;
[0062]
s2-1将长时基音频率f0
lt
序列进行n层小波包分解,得到第n层上所有2n个频段分量的一维向量s1,s2,...,sz(z=2n),标号的顺序为所分频段由低频到高频排列,其中,si视为n层小波包分解树中叶子节点,句长时间范围2~4秒对应小波包分解的层数n取值为3;在小波包分解中小波母函数的不同,小波变换的结果也不尽相同,在本次实例中选取的小波母函数为coiflet系列小波,第l层、第k点的小波包分解系数分别为:式中g0(h-2k)和g1(h-2k)是一对共轭正交滤波器,h为滤波器系数序号,r为小波包子空间序
号;
[0063]
s2-2长时基音频率f0
lt
的小波包分解形成矩阵sf,sf=[s
1 s
2 ... sz]
t
;
[0064]
s3-1使用s1-2中提取的频谱包络sp参数计算各帧的平均功率谱npow,以句为单位形成平均功率谱npow
lt
;
[0065]
s3-2对长时平均功率谱npow
lt
进行n层小波包分解,得到小波包分解后的二维矩阵s
p
;
[0066]
s3-3由f0
lt
与npow
lt
的小波包分解矩阵sf和s
p
拼接形成联合矩阵s,s=[s
f s
p
];
[0067]
s3-4将从源说话人训练样本形成的联合矩阵标记为s
train_source
,将从目标说话人训练样本形成的联合矩阵标记为s
train_target
。
[0068]
s4-1使用动态时间规整方法对矩阵s
train_source
和矩阵s
train_target
进行时间对齐,同时也对源说话人和目标说话人的梅尔倒谱参数mcep进行时间对齐;
[0069]
s4-2将对齐后的两种参数集分别送入高斯混合模型中训练,得到长时基音频率f0
lt
的转换函数f
trained
和梅尔倒谱参数mcep的转换函数m
trained
;
[0070]
s4-2-1源说话人特征向量:x
t
=[x
t
(1),x
t
(2),...,x
t
(dx)]
t
,目标说话人特征向量:y
t
=[y
t
(1),y
t
(2),...,y
t
(dy)]
t
,联合概率密度特征向量:z
t
=[x
tt
,y
tt
]
t
,其中,t:帧数;dx,dy分别表示x,y的纬度;
[0071]
s4-2-2计算特征概率:其中,m:混合分量个数;ωm:第m个混合分量的权重;服从高斯分布;
[0072]
s4-2-3第m个分量的均值和方差表示为:
[0073]
s4-2-4基于高斯混合模型的语音转换函数f
trained
和m
trained
为:
[0074]
s5-1-1利用world声码器对需转换的源说话人样本提取基音频率f0,平均功率谱npow,频谱包络sp和非周期序列ap;
[0075]
s5-1-2以句为单位形成需转换的源说话人样本的长时基音频率f0
lt
,频谱包络npow
lt
,梅尔倒谱参数mcep;
[0076]
s5-2对基音频率f0
lt
进行n层小波包分解得到sf,对长时频谱包络npow
lt
进行n层小波包分解得到s
p
,对sf和s
p
进行拼接形成联合矩阵s
conv_source
;
[0077]
s5-3将联合矩阵s
conv_source
输入f0
lt
的转换函数f
trained
,输出转换后的联合矩阵s
conv_traget
;将梅尔倒谱参数mcep输入mcep的转换函数m
trained
,输出转换后的梅尔倒谱参数mcep',并转换为sp';
[0078]
s6从转换后的联合矩阵s
conv_traget
=[sf' s
p
']中分离出sf'=[s1' s2' ... sz']
t
,将sf'中的各元素与n层小波包分解树的叶子节点相对应,通过小波包逆变换:依据第l层、第k点小波包系数的重构公式重构信号的表达式为:
[0079][0080]
经过小波包逆变换后得到转换后的长时基音频率f0'
lt
;
[0081]
s7对转换后的长时f0'
lt
参数,按先后顺序每帧对应向量中一个元素,得到每一帧转换后的基音频率f0';最终结合频谱包络参数sp'和激励参数ap生成转换后的目标说话人语音。
[0082]
实施例3
[0083]
在本实施例中,以两男和两女的4位说话人语音转换实现作为实例,对所提供方法的实施过程作进一步说明,并把方法与其余两种非小波包转换的特征参数转换方法进行效果对比。
[0084]
本实施例一种基于小波包分解特征参数的语音转换方法,主要包括以下步骤:
[0085]
s1-1准备源说话人的训练样本和转换样本,准备目标说话人的训练样本和转换样本;对上述所有样本均进行语音句长时间范围的限制并形成以句为单位的样本数据。采用casia(institute of automation,chinese academy of sciences)汉语情感语料库数据库中2位男士与2位女士的共4人各50句中文语音样本作为本实施例的训练样本和转换样本,语音时长在2~4秒,且每句样本中包含5~10个连续音节。其中,对每个人的50句样本,取前45句作为训练样本,取后5句作为转换样本;所有样本采样率为16000hz,基音频率范围为:60-290(男生),90-500(女生);
[0086]
s1-2利用world声码器分别对被限定句长范围的源说话人训练集样本和目标说话人训练样本进行预处理(分帧和加窗)后,先以帧为单位提取源说话人训练样本和目标说话人训练样本的基音频率f0和频谱包络sp(频谱包络的维数为512)。把每一帧的基音频率f0以句为单位按时间先后顺序组成一维向量f0
lt
作为长时基音频率;以帧为单位提取梅尔倒谱参数mcep(梅尔倒谱参数的维数为24);
[0087]
s2-1将长时基音频率f0
lt
序列进行n层小波包分解,得到第n层上所有2n个频率分量的一维向量s1,s2,...,sz(z的值为2n),标号的顺序为所分频段由低频到高频排列,其中,si视为n层小波包分解树中叶子节点。句长时间范围2~4秒对应小波包分解的层数n取值为3,即n=3,z=8,只取第三层的叶子节点;si的长度为在小波包分解中小波母函数的不同,小波变换的结果也不尽相同,在本次实例中选取的小波母函数为coiflet系列小波;第l层、第k点的小波包分解系数分别为:式中g0(h-2k)和g1(h-2k)是一对共轭正交滤波器,h为滤波器系数序号,r为小波包子空间序号;
[0088]
s2-2长时基音频率f0
lt
的小波包分解形成矩阵sf,sf=[s
1 s
2 ... sz]
t
;
[0089]
s3-1使用s1-2中从被限定句长的源说话人训练样本和目标说话人训练样本中提取的频谱包络sp参数计算各帧的平均功率谱npow,以句为单位形成平均功率谱npow
lt
;
[0090]
s3-2对长时平均功率谱npow
lt
进行n层小波包分解,得到小波包分解后的二维矩阵s
p
;其中sf和s
p
为c
×
8的矩阵;
[0091]
s3-3由f0
lt
与npow
lt
的小波包分解矩阵sf和s
p
拼接形成联合矩阵s,s=[s
f s
p
],其中s为c
×
16的矩阵;
[0092]
s3-4将从源说话人训练样本形成的联合矩阵标记为s
train_source
,将从目标说话人
训练样本形成的联合矩阵标记为s
train_target
。
[0093]
s4-1使用动态时间规整方法对矩阵s
train_source
和矩阵s
train_target
进行时间对齐,同时也对源说话人和目标说话人的梅尔倒谱参数mcep进行时间对齐;
[0094]
s4-2将对齐后的两种参数集分别送入高斯混合模型中训练,得到长时基音频率f0
lt
的转换函数f
trained
和梅尔倒谱参数mcep的转换函数m
trained
;
[0095]
s4-2-1源说话人特征向量:x
t
=[x
t
(1),x
t
(2),...,x
t
(dx)]
t
,目标说话人特征向量:y
t
=[y
t
(1),y
t
(2),...,y
t
(dy)]
t
,联合概率密度特征向量:z
t
=[x
tt
,y
tt
]
t
,其中,t:帧数;dx,dy分别表示x,y的纬度:
[0096]
s4-2-2计算特征概率:其中,m:混合分量个数;ωm:第m个混合分量的权重;服从高斯分布;
[0097]
s4-2-3第m个分量的均值和方差表示为:
[0098]
s4-2-4基于高斯混合模型的语音转换函数f
trained
和m
trained
为:
[0099]
s5-1-1利用world声码器对需转换的源说话人样本提取基音频率f0,平均功率谱npow,频谱包络sp和非周期序列ap;
[0100]
s5-1-2以句为单位形成需转换的源说话人样本的长时基音频率f0
lt
,频谱包络npow
lt
,梅尔倒谱参数mcep;
[0101]
s5-2对基音频率f0
lt
进行n层小波包分解得到sf,对长时频谱包络npow
lt
进行n层小波包分解得到s
p
,对sf和s
p
进行拼接形成联合矩阵s
conv_source
;
[0102]
s5-3将联合矩阵s
conv_source
输入f0
lt
的转换函数f
trained
,输出转换后的联合矩阵s
conv_traget
;将梅尔倒谱参数mcep输入mcep的转换函数m
trained
,输出转换后的梅尔倒谱参数mcep',并转换为sp';
[0103]
s6从转换后的联合矩阵s
conv_traget
=[sf' s
p
']中分离出sf'=[s1' s2' ... sz']
t
,按照频率高低与n层小波包分解树中的叶子节点标号相对应的关系,将s1',s2',...,sz'顺序放入,通过小波包逆变换:依据第l层、第k点小波包系数的重构公式重构信号的表达式为:得到转换后的长时基音频率f0'
lt
。
[0104]
s7.对转换后的长时f0'
lt
参数,按先后顺序每帧对应向量中一个元素,得到每一帧转换后的基音频率f0';最终结合频谱包络参数sp'和激励参数ap生成转换后的目标说话人语音。其中,f0'需要和f0的帧数一致。
[0105]
基于上述方法与不同的转换方法的效果对比:选用基于f0均值和方差的转换和基于连续小波分解的转换,在不同转换场景下三种方法转换效果的对比:
[0106]
1、女生转男生:女生作为源说话人,男生作为目标说话人,进行转换;
[0107]
2、男生转女生:男生作为源说话人,女生作为目标说话人,进行转换;
[0108]
3、女生转女生:女生作为源说话人,另一名女生作为目标说话人,进行转换;
[0109]
4、男生转男生:男生作为源说话人,另一名男生作为目标说话人,进行转换。
[0110]
这里引入使用均方根误差(rmse)来评估目标f0和转换后的f0之间的转换误差。均方根误差公式为是反映估计量与被估计量之间差异程度的一种度量,较低f0-rmse值表示较小的失真或转换误差。
[0111]
如表1所示,在三种f0转换的方法中,本发明的方法均优于其余两种方法,并较大程度减少了误差。
[0112]
表1不同转换方法的效果对比
[0113][0114]
本发明基于小波包分解特征参数的语音转换方法采用小波包变换对长时特征进行分解后转换,对高频部分进行进一步分解,提取所有频段的信息,不丢失频率信息,在对基音频率进行小波包分解中避免小波分解必须先要对基音频率进行归一化,线性差值等操作,减少这些因素带来的误差,使得转换的效果大大提升。
[0115]
以上所述,仅为本发明较佳的具体实施方式,但本发明的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本发明揭露的技术范围内,根据本发明的技术方案及其发明构思加以等同替换或改变,都应涵盖在本发明的保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1