语音识别模型的生成方法及语音识别方法与流程
本公开涉及人工智能,尤其涉及一种语音识别模型的生成方法及语音识别方法。
背景技术:
1、asr(automatic speech recognition,自动语音识别技术)是一种将语音转换为文本的技术。具体地,asr能够“听写”出不同人所说出的连续语音,可以实现“声音”到“文字”的转换。
2、对于语音识别模型,需要基于具有文本标注的音频数据对预设识别模型进行训练,得到语音识别模型。在训练过程中,为了强化模型抗干扰能力,通常使用数据增强的方式扩展样本类型,针对语音数据进行加噪,最后喂入模型中训练。目前,行业内常用的数据增强方式固化,喂入模型的数据特征一样,导致模型泛化能力降低。而随着生活条件的发展,人们的生活环境越来越多样化,会存在多种复杂场景下语音识别需求,如多人聚会、现场演讲和视频直播等。可见,现有的加噪音频数据的质量低,通过现有的加噪音频数据训练得到的语音识别模型,对于上述各种复杂场景下的语音数据的语音识别能力较弱。
3、另外,若直接对复杂场景下的音频进行标注,需要依靠标注员对每一句话进行手动听音标注,并且需要筛选出复杂的音频数据,通过平台化的听音标注生产文音匹配样本,用以语音识别asr模型的训练。但是,复杂场景下的音频标注较困难,标注员需要逐字转写音频内容,转写难度较大,转写效率较低,且因音频场景复杂,可能会出现部分发音听不清导致转写错误,影响数据质量的问题。
技术实现思路
1、有鉴于上述存在的技术问题,本公开提出了一种语音识别模型的生成方法及语音识别方法。
2、根据本公开实施例的一方面,提供一种语音识别模型的生成方法,包括:
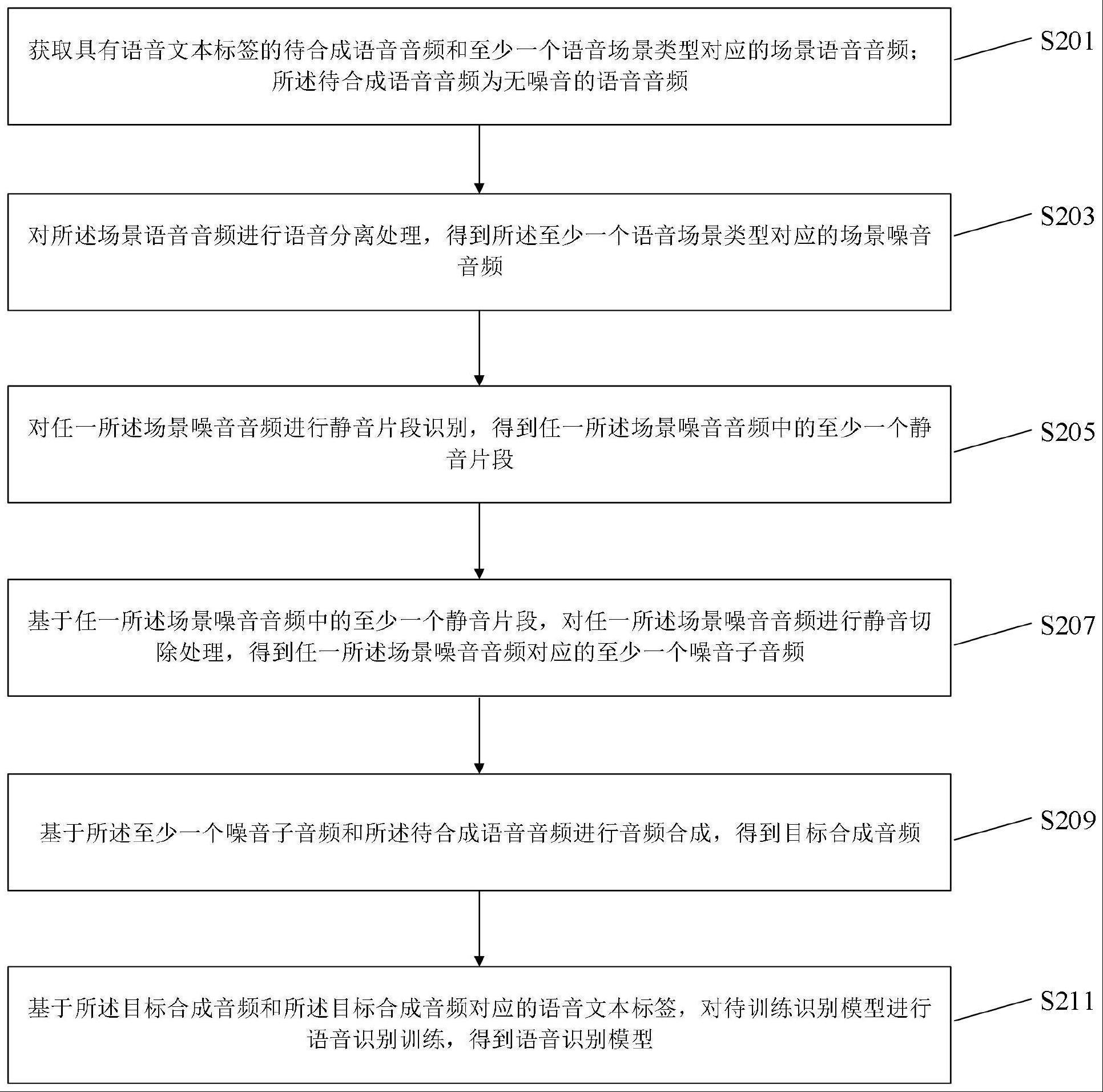
3、获取具有语音文本标签的待合成语音音频和至少一个语音场景类型对应的场景语音音频;所述待合成语音音频为无噪音的语音音频;
4、对所述场景语音音频进行语音分离处理,得到所述至少一个语音场景类型对应的场景噪音音频;
5、对任一所述场景噪音音频进行静音片段识别,得到任一所述场景噪音音频中的至少一个静音片段;
6、基于任一所述场景噪音音频中的至少一个静音片段,对任一所述场景噪音音频进行静音切除处理,得到任一所述场景噪音音频对应的至少一个噪音子音频;
7、基于所述至少一个噪音子音频和所述待合成语音音频进行音频合成,得到目标合成音频;
8、基于所述目标合成音频和所述目标合成音频对应的语音文本标签,对待训练识别模型进行语音识别训练,得到语音识别模型。
9、根据本公开实施例的另一方面,提供一种语音识别方法,包括:
10、获取待识别语音音频;
11、将所述待识别语音音频输入上述的语音识别模型的生成方法得到的语音识别模型进行语音识别处理,得到所述待识别语音音频对应的语音文本信息。
12、根据本公开实施例的另一方面,提供一种语音识别模型的生成装置,包括:
13、语音音频获取模块,用于获取具有语音文本标签的待合成语音音频和至少一个语音场景类型对应的场景语音音频;所述待合成语音音频为无噪音的语音音频;
14、语音分离处理模块,用于对所述场景语音音频进行语音分离处理,得到所述至少一个语音场景类型对应的场景噪音音频;
15、静音片段识别模块,用于对任一所述场景噪音音频进行静音片段识别,得到任一所述场景噪音音频中的至少一个静音片段;
16、静音切除处理模块,用于基于任一所述场景噪音音频中的至少一个静音片段,对任一所述场景噪音音频进行静音切除处理,得到任一所述场景噪音音频对应的至少一个噪音子音频;
17、音频合成模块,用于基于所述至少一个噪音子音频和所述待合成语音音频进行音频合成,得到目标合成音频;
18、语音识别训练模块,用于基于所述目标合成音频和所述目标合成音频对应的语音文本标签,对待训练识别模型进行语音识别训练,得到语音识别模型。
19、根据本公开实施例的另一方面,提供一种语音识别装置,包括:
20、待识别语音音频获取模块,用于获取待识别语音音频;
21、语音识别处理模块,用于将所述待识别语音音频输入上述的语音识别模型的生成方法得到的语音识别模型进行语音识别处理,得到所述待识别语音音频对应的语音文本信息。
22、根据本公开实施例的另一方面,提供一种电子设备,包括:处理器;用于存储所述处理器可执行指令的存储器;其中,所述处理器被配置为执行所述指令,以实现上述语音识别模型的生成方法或上述语音识别方法。
23、根据本公开实施例的另一方面,提供一种计算机可读存储介质,当所述存储介质中的指令由电子设备的处理器执行时,使得所述电子设备能够执行上述语音识别模型的生成方法或上述语音识别方法。
24、根据本公开实施例的另一方面,提供一种包含指令的计算机程序产品,当其在计算机上运行时,使得计算机执行上述语音识别模型的生成方法或上述语音识别方法。
25、本公开的实施例提供的技术方案至少带来以下有益效果:
26、通过获取具有语音文本标签的、无噪音的待合成语音音频和至少一个语音场景类型对应的场景语音音频,从场景语音音频中通过语音分离处理分离出至少一个语音场景类型对应的场景噪音音频,可以保证场景噪音音频极为贴近真实复杂场景,再对每个场景噪音音频进行静音片段识别,得到每个场景噪音音频中的至少一个静音片段,基于每个场景噪音音频中的至少一个静音片段,对每个场景噪音音频进行静音切除处理,得到每个场景噪音音频对应的至少一个噪音子音频,可以提高噪音子音频的质量,避免无声噪音片段导致语音识别训练的有效性降低,接着,基于至少一个噪音子音频和已完成标注的待合成语音音频进行音频合成,得到目标合成音频,可以提高目标合成音频的生成的便利性和目标合成音频的质量,然后,结合目标合成音频和目标合成音频对应的语音文本标签,对待训练识别模型进行语音识别训练,可以提高语音识别模型的抗干扰能力,并提高语音识别模型对于各种复杂场景的语音识别能力。
27、应当理解的是,以上的一般描述和后文的细节描述仅是示例性和解释性的,并不能限制本公开。
技术特征:
1.一种语音识别模型的生成方法,其特征在于,所述方法包括:
2.根据权利要求1所述的方法,其特征在于,所述基于所述至少一个噪音子音频和所述待合成语音音频进行音频合成,得到目标合成音频,包括:
3.根据权利要求2所述的方法,其特征在于,所述从所述至少一个噪音子音频中获取第一噪音子音频,包括:
4.根据权利要求3所述的方法,其特征在于,所述方法还包括:
5.根据权利要求1所述的方法,其特征在于,所述方法还包括:
6.根据权利要求1-5任一所述的方法,其特征在于,所述对任一所述场景噪音音频进行静音片段识别,得到任一所述场景噪音音频中的至少一个静音片段,包括:
7.根据权利要求1所述的方法,其特征在于,所述目标合成音频包括多个语音场景类型对应的多个合成音频,所述基于所述目标合成音频和所述目标合成音频对应的语音文本标签,对待训练识别模型进行语音识别训练,得到语音识别模型,包括:
8.根据权利要求1-7任一所述的方法,其特征在于,所述对所述场景语音音频进行语音分离处理,得到所述至少一个语音场景类型对应的场景噪音音频,包括:
9.一种语音识别方法,其特征在于,所述方法包括:
10.一种语音识别模型的生成装置,其特征在于,所述装置包括:
11.一种语音识别装置,其特征在于,所述装置包括:
12.一种电子设备,其特征在于,包括:
13.一种非易失性计算机可读存储介质,其上存储有计算机程序指令,其特征在于,所述计算机程序指令被处理器执行时实现权利要求1至8中任意一项所述的语音识别模型的生成方法或实现权利要求9所述的语音识别方法。
14.一种计算机程序产品,包括计算机指令,其特征在于,所述计算机指令被处理器执行时实现权利要求1至8中任意一项所述的语音识别模型的生成方法或实现权利要求9所述的语音识别方法。
技术总结
本公开关于一种语音识别模型的生成方法及语音识别方法,包括:获取具有语音文本标签的待合成语音音频和至少一个语音场景类型对应的场景语音音频;对场景语音音频进行语音分离处理,得到至少一个语音场景类型的场景噪音音频;对任一场景噪音音频进行静音片段识别,得到至少一个静音片段;基于至少一个静音片段,对任一场景噪音音频进行静音切除处理,得到至少一个噪音子音频;基于至少一个噪音子音频和待合成语音音频进行音频合成,得到目标合成音频;基于目标合成音频和目标合成音频对应的语音文本标签,对待训练识别模型进行语音识别训练,得到语音识别模型。利用本公开实施例可以提高语音识别模型的抗干扰能力和语音识别能力。
技术研发人员:马应龙,刘攀
受保护的技术使用者:腾讯科技(深圳)有限公司
技术研发日:
技术公布日:2024/1/16
- 还没有人留言评论。精彩留言会获得点赞!