一种语音数据的处理方法及处理装置与流程
本发明属于语音处理的,尤其涉及一种语音数据的处理方法及处理装置。
背景技术:
1、语音识别和语音处理技术正在不断进步,但仍存在一些困难。当前语音数据处理方法在高噪声环境下的准确性有限,而且对于口音、说话速度和语言表达方式的变化非常敏感。此外,在资源受限或网络不稳定的环境中,现有的语音处理方法通常面临性能退化的挑战,这限制了其广泛应用领域。
2、近年来,深度神经网络(dnn)已被应用于降噪和去混响任务中,并取得了显著的效果。基于深度学习的方法能够通过大规模数据集的训练来捕捉语音信号的显著特征,同时保留语音细节。这包括使用卷积神经网络(cnn)、循环神经网络(rnn)和变分自编码器(vae)等。这些方法在降噪和去混响任务上展现出了较好的性能,但仍然存在一些挑战,如处理长时延迟和不完美的复杂场景效果等问题。
3、但是,目前深度学习算法对于语音数据处理的处理精度偏低,这是一个亟需解决的技术问题。
技术实现思路
1、有鉴于此,本发明实施例提供了一种语音数据的处理方法、处理装置、终端设备以及计算机可读存储介质,以解决目前深度学习算法对于语音数据处理的处理精度偏低的技术问题。
2、本发明实施例的第一方面提供了一种语音数据的处理方法,所述处理方法包括:
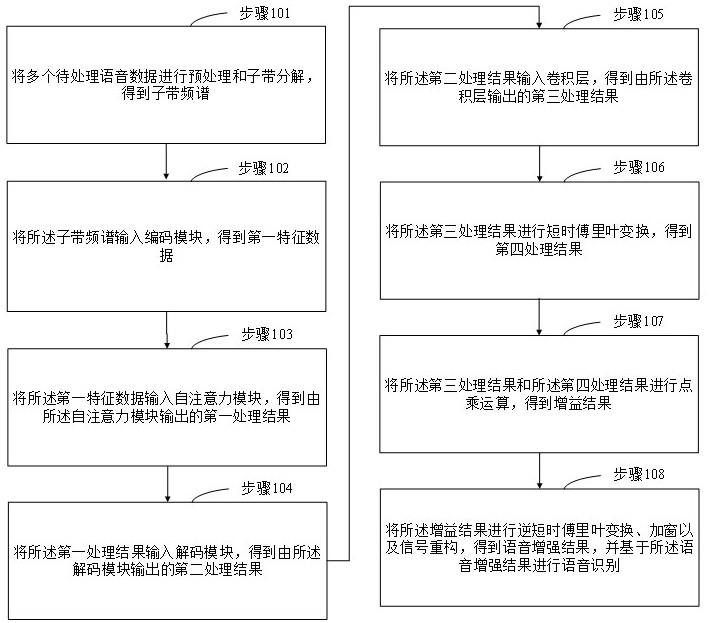
3、将多个待处理语音数据进行预处理和子带分解,得到子带频谱;
4、将所述子带频谱输入编码模块,得到第一特征数据;
5、将所述第一特征数据输入自注意力模块,得到由所述自注意力模块输出的第一处理结果;
6、将所述第一处理结果输入解码模块,得到由所述解码模块输出的第二处理结果;
7、将所述第二处理结果输入卷积层,得到由所述卷积层输出的第三处理结果;
8、将所述第三处理结果进行短时傅里叶变换,得到第四处理结果;
9、将所述第三处理结果和所述第四处理结果进行点乘运算,得到增益结果;
10、将所述增益结果进行逆短时傅里叶变换、加窗以及信号重构,得到语音增强结果,并基于所述语音增强结果进行语音识别;
11、其中,所述编码模块的输出与所述自注意力模块的输出拼接得到所述解码模块的输入,所述解码模块中第二子模块的输入由所述解码模块的第一子模块和编码模块中第二个子模块的输出拼接组成,所述解码模块中第三子模块的输入由所述解码模块的第二子模块和编码模块中第一个子模块的输出拼接组成,所述卷积层的输入为所述解码模块的输出。
12、进一步地,所述将多个待处理语音数据进行预处理和子带分解,得到子带频谱的步骤,包括:
13、将多个待处理语音数据进行滤波处理,得到多个第一语音数据;
14、将多个所述第一语音数据进行混响卷积,得到多个第二语音数据;
15、将多个所述第二语音数据进行噪声混合处理,得到多个第三语音数据;
16、将多个所述第三语音数据进行短时傅里叶变换,并进行子带分解,得到所述子带频谱。
17、进一步地,所述将多个所述第三语音数据进行短时傅里叶变换,并进行子带分解,得到子带频谱的步骤,包括:
18、对所述第三语音数据进行预加重处理,得到第四语音数据;
19、将所述第四语音数据进行分帧加窗和短时傅里叶变换,得到第五语音数据;
20、将所述第五语音数据进行子带分解,并转换为预设数据格式,得到所述子带频谱。
21、进一步地,所述编码模块包括多个第一卷积模块,所述第一卷积模块包括依次连接的卷积层、批量归一化层和激活层;多个所述第一卷积模块之间通过最大池化层连接。
22、进一步地,所述将所述第一特征数据输入自注意力模块,得到由所述自注意力模块输出的第一处理结果的步骤,包括:
23、所述自注意力模块通过三种预设的线性变换矩阵,将所述第一特征数据中每一位置上的特征向量映射至查询向量、键向量和值向量上;
24、所述自注意力模块将所述查询向量和所述键向量代入如下公式一,得到注意力得分;
25、其中, a i表示所述注意力得分,q表示所述查询向量,k表示所述键向量,为所述键向量的维度,为所述查询向量的维度,和预训练权重矩阵,tanh()表示双曲正切函数;
26、将所述值向量和所述注意力得分代入如下公式二,得到所述第一处理结果;
27、
28、其中, c i表示所述第一处理结果, a i表示所述注意力得分, v j表示第j个所述值向量,j表示所述值向量的数量。
29、进一步地,在所述将多个待处理语音数据进行滤波处理,得到多个第一语音数据的步骤之前,还包括:
30、样本语音数据经过编码模块、自注意力模块和解码模块处理,得到样本处理结果;
31、根据所述样本处理结果和标准处理结果计算对数均方误差和多分辨率短时傅里叶变换误差;
32、根据所述对数均方误差和所述多分辨率短时傅里叶变换误差,调整所述编码模块、所述自注意力模块和所述解码模块的参数,得到训练后的编码模块、自注意力模块和解码模块。
33、进一步地,所述根据所述样本处理结果和标准处理结果计算对数均方误差和多分辨率短时傅里叶变换误差的步骤,包括:
34、基于样本处理结果和标准处理结果各自对应的频谱图的实部和虚部计算所述对数均方误差;
35、通过如下公式三计算频谱收敛性损失和对数stft幅度损失;
36、
37、其中,表示所述频谱收敛性损失,表示所述对数stft幅度损失,和分别表示frobenius范数和l1范数,表示stft幅度,n表示幅度中的元素数量。
38、本发明实施例的第二方面提供了一种语音数据的处理装置,包括:
39、分解单元,用于将多个待处理语音数据进行预处理和子带分解,得到子带频谱;
40、第一处理单元,用于将所述子带频谱输入编码模块,得到第一特征数据;
41、第二处理单元,用于将所述第一特征数据输入自注意力模块,得到由所述自注意力模块输出的第一处理结果;
42、第三处理单元,用于将所述第一处理结果输入解码模块,得到由所述解码模块输出的第二处理结果;
43、第四处理单元,用于将所述第二处理结果输入卷积层,得到由所述卷积层输出的第三处理结果;
44、变换单元,用于将所述第三处理结果进行短时傅里叶变换,得到第四处理结果;
45、运算单元,用于将所述第三处理结果和所述第四处理结果进行点乘运算,得到增益结果;
46、第五处理单元,用于将所述增益结果进行逆短时傅里叶变换、加窗以及信号重构,得到语音增强结果,并基于所述语音增强结果进行语音识别;
47、其中,所述编码模块的输出与所述自注意力模块的输出拼接得到所述解码模块的输入,所述解码模块中第二子模块的输入由所述解码模块的第一子模块和编码模块中第二个子模块的输出拼接组成,所述解码模块中第三子模块的输入由所述解码模块的第二子模块和编码模块中第一个子模块的输出拼接组成,所述卷积层的输入为所述解码模块的输出。
48、本发明实施例的第三方面提供了一种终端设备,包括存储器、处理器以及存储在所述存储器中并可在所述处理器上运行的计算机程序,所述处理器执行所述计算机程序时实现上述第一方面所述方法的步骤。
49、本发明实施例的第四方面提供了一种计算机可读存储介质,所述计算机可读存储介质存储有计算机程序,所述计算机程序被处理器执行时实现上述第一方面所述方法的步骤。
50、本发明实施例与现有技术相比存在的有益效果是:本发明通过对待处理的多个语音数据进行预处理和子带分解,可以将语音信号分解为不同频率范围的子带频谱。将子带频谱输入编码模块,通过编码生成第一特征数据。这里使用了自注意力模块,它有助于模型学习到不同子带频谱之间的关联和权重信息。将第一特征数据输入解码模块,通过解码过程得到第二处理结果。解码模块由多个子模块组成,其中第一个子模块与编码模块的第二个子模块的输出拼接,而第二子模块与编码模块的第一个子模块的输出拼接,这种连接方式可能有助于引入更丰富的上下文关系。第二处理结果经过卷积层,得到第三处理结果。卷积层可以进一步提取特征,帮助模型捕捉语音信号中的局部信息。第三处理结果进行短时傅里叶变换,得到第四处理结果。这个过程可能用于将信号从时间域转换到频域,进一步分析语音信号的频谱特性。通过点乘运算将第三处理结果和第四处理结果进行计算,得到增益结果,以调整频谱的增强或衰减以改善语音质量。将增益结果进行逆短时傅里叶变换,并通过加窗和信号重构来还原语音增强结果。将增益应用于频率域的信号,以恢复增强后的语音信号。基于语音增强结果进行语音识别。增强后的语音信号可能更清晰、可辨认度更高,提高了语音识别的准确性和性能。
- 还没有人留言评论。精彩留言会获得点赞!