语音识别方法、装置、设备、存储介质及程序产品与流程
本申请实施例涉及机器学习领域,特别涉及一种语音识别方法、装置、设备、存储介质及程序产品。
背景技术:
1、语音识别技术是指对用户口述的语音转换为对应的文本内容,其中,文本内容与语音内容对应,如:用户口述的语音为“你好”,则通过语音识别技术得到文本内容“你好”。
2、相关技术中,语音识别技术通常采用自动语音识别(automatic speechrecognition,asr)将用户口述的语音转换为计算机可读的输入语言,如:按键、二进制编码或者字符序列,后续根据不同的任务需求对用户口述的语音进行相关应用,如:用户对车载终端口述语音为“请打开空调”,车载终端通过asr技术对语音进行内容分析,得到内容分析结果后,根据内容分析结果执行打开车内空调的行为。
3、然而相关技术中的方案,由于用户口述的语音会存在发音不准确等问题,导致asr技术针对语音识别得到的结果与语音本身对应的语音内容不符,降低了语音识别的内容准确度。
技术实现思路
1、本申请实施例提供了一种语音识别方法、装置、设备、存储介质及程序产品,能够提高语音识别的内容准确率。所述技术方案如下。
2、一方面,提供了一种语音识别方法,所述方法包括:
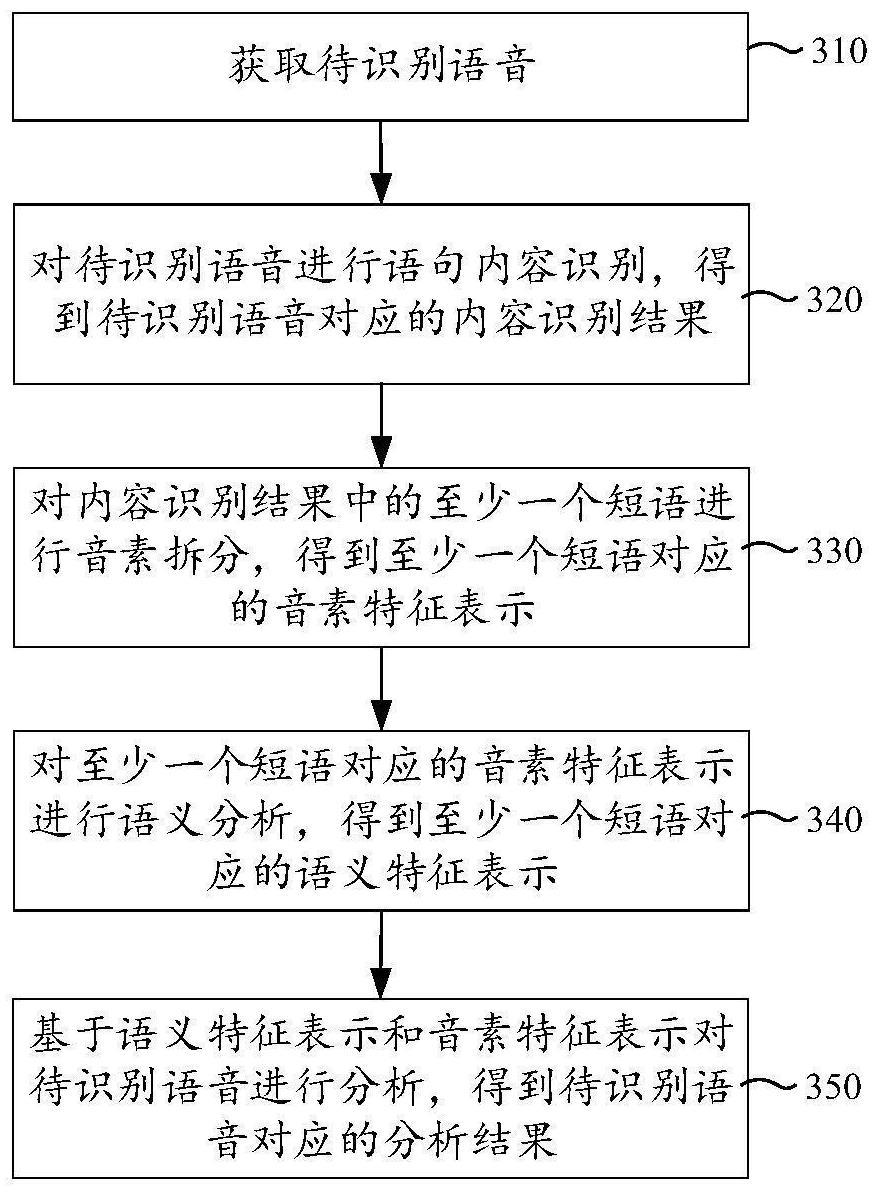
3、获取待识别语音;
4、对所述待识别语音进行语句内容识别,得到所述待识别语音对应的内容识别结果,所述内容识别结果中包括组成所述待识别语音的语音内容的至少一个短语;
5、对所述内容识别结果中的至少一个短语进行音素拆分,得到所述至少一个短语对应的音素特征表示;
6、对所述至少一个短语对应的音素特征表示进行语义分析,得到所述至少一个短语对应的语义特征表示;
7、基于所述语义特征表示和所述音素特征表示对所述待识别语音进行预测,得到所述待识别语音对应的预测结果,所述预测结果用于在校正所述内容识别结果的基础上对所述待识别语音进行应用。
8、另一方面,提供了一种语音识别方装置,所述装置包括:
9、获取模块,用于获取待识别语音;
10、识别模块,用于对所述待识别语音进行语句内容识别,得到所述待识别语音对应的内容识别结果,所述内容识别结果中包括组成所述待识别语音的语音内容的至少一个短语;
11、拆分模块,用于对所述内容识别结果中的至少一个短语进行音素拆分,得到所述至少一个短语对应的音素特征表示;
12、分析模块,用于对所述至少一个短语对应的音素特征表示进行语义分析,得到所述至少一个短语对应的语义特征表示;
13、预测模块,用于基于所述语义特征表示和所述音素特征表示对所述待识别语音进行预测,得到所述待识别语音对应的预测结果,所述预测结果用于在校正所述内容识别结果的基础上对所述待识别语音进行应用。
14、另一方面,提供了一种计算机设备,所述计算机设备包括处理器和存储器,所述存储器中存储有至少一条指令、至少一段程序、代码集或指令集,所述至少一条指令、所述至少一段程序、所述代码集或指令集由所述处理器加载并执行以实现如上述本申请实施例中任一所述语音识别方法。
15、另一方面,提供了一种计算机可读存储介质,所述存储介质中存储有至少一条指令、至少一段程序、代码集或指令集,所述至少一条指令、所述至少一段程序、所述代码集或指令集由处理器加载并执行以实现如上述本申请实施例中任一所述的语音识别方法。
16、另一方面,提供了一种计算机程序产品或计算机程序,该计算机程序产品或计算机程序包括计算机指令,该计算机指令存储在计算机可读存储介质中。计算机设备的处理器从计算机可读存储介质读取该计算机指令,处理器执行该计算机指令,使得该计算机设备执行上述实施例中任一所述的语音识别方法。
17、本申请实施例提供的技术方案带来的有益效果至少包括:
18、当对待识别语音进行语句内容识别得到内容识别结果后,对内容识别结果中的至少一个短语进行音素拆分,得到至少一个短语对应的音素特征表示,再针对音素特征表示进行语义分析,得到至少一个短语对应的语义特征表示,从而根据短语对应的语义特征表示和音素特征表示对待识别语音进行预测,最终得到预测结果。也即,通过在对待识别语音进行语句内容识别后,结合短语对应的音素特征表示得到短语对应的语义特征表示,最终基于音素特征表示和语义特征表示来对待识别语音进行预测,能够通过结合音素拆分的方式提高内容预测的准确度,进而提高语音识别的内容准确度。
技术特征:
1.一种语音识别方法,其特征在于,所述方法包括:
2.根据权利要求1所述的方法,其特征在于,所述对所述内容识别结果中的至少一个短语进行音素拆分,得到所述至少一个短语对应的音素特征表示,包括:
3.根据权利要求2所述的方法,其特征在于,所述将所述内容识别结果中的至少一个短语输入目标发音模型,输出得到所述至少一个短语对应的音素特征表示,包括:
4.根据权利要求3所述的方法,其特征在于,所述将至少一个音素元素进行音素转换,得到第i个短语对应的音素序列特征表示,包括:
5.根据权利要求1所述的方法,其特征在于,所述对所述至少一个短语对应的音素特征表示进行语义分析,得到所述至少一个短语对应的语义特征表示,包括:
6.根据权利要求5所述的方法,其特征在于,所述将所述至少一个短语对应的音素特征表示输入目标语义模型,输出得到所述至少一个短语对应的语义特征表示,包括:
7.根据权利要求2至6任一所述的方法,其特征在于,所述将所述内容识别结果中的至少一个短语输入目标发音模型,输出得到所述至少一个短语对应的音素特征表示之前,还包括:
8.根据权利要求7所述的方法,其特征在于,所述基于所述发音损失值和所述语义损失值对所述样本发音模型进行训练,得到所述目标发音模型,以及,基于所述发音损失值和所述语义损失值对所述样本语义模型进行训练,得到目标语义模型,包括:
9.根据权利要求1至6任一所述的方法,其特征在于,所述对所述至少一个短语对应的音素特征表示进行语义分析,得到所述至少一个短语对应的语义特征表示之后,还包括:
10.一种语音识别装置,其特征在于,所述装置包括:
11.一种计算机设备,其特征在于,所述计算机设备包括处理器和存储器,所述存储器中存储有至少一段程序,所述至少一段程序由所述处理器加载并执行以实现如权利要求1至9任一所述的语音识别方法。
12.一种计算机可读存储介质,其特征在于,所述存储介质中存储有至少一段程序,所述至少一段程序由处理器加载并执行以实现如权利要求1至9任一所述的语音识别方法。
13.一种计算机程序产品,其特征在于,包括计算机程序,所述计算机程序被处理器执行时实现如权利要求1至9任一所述的语音识别方法。
技术总结
本申请公开一种语音识别方法、装置、设备、存储介质及程序产品,涉及机器学习领域。该方法包括:获取待识别语音;对待识别语音进行语句内容识别,得到待识别语音对应的内容识别结果;对内容识别结果中的至少一个短语进行音素拆分,得到至少一个短语对应的音素特征表示;对至少一个短语对应的音素特征表示进行语义分析,得到至少一个短语对应的语义特征表示;基于语义特征表示和音素特征表示对待识别语音进行分析,得到待识别语音对应的分析结果。也即,能够通过结合音素拆分的方式提高内容预测的准确度,进而提高语音识别的内容准确度。本申请实施例可应用于云技术、人工智能、智慧交通、辅助驾驶等各种场景。
技术研发人员:庞雲升,王丽园,林炳怀
受保护的技术使用者:腾讯科技(深圳)有限公司
技术研发日:
技术公布日:2024/1/16
- 还没有人留言评论。精彩留言会获得点赞!