一种基于深度学习的音频降噪方法及系统与流程
本发明涉及音频降噪领域,特别是一种基于深度学习的音频降噪方法及系统。
背景技术:
1、在生活中,有多个地方需要用到音频降噪,例如降噪耳机、降噪麦克风、降噪音响等。对输入音频进行降噪目的是使目标音频能更清晰的输出,同时降低噪音有利于音频处理设备使用者的身体健康,保护音频处理设备使用者不被噪声音频影响。深度学习模型能够对采集的音频进行深度学习,获取需要降噪的音频部分,并对对应的音频进行处理,最大程度的输出目标音频及降低噪声音频。所以提出一种基于深度学习的音频降噪方法及系统,用于对音频进行降噪。
技术实现思路
1、本发明克服了现有技术的不足,提供了一种基于深度学习的音频降噪方法及系统。
2、为达到上述目的,本发明采用的技术方案为:
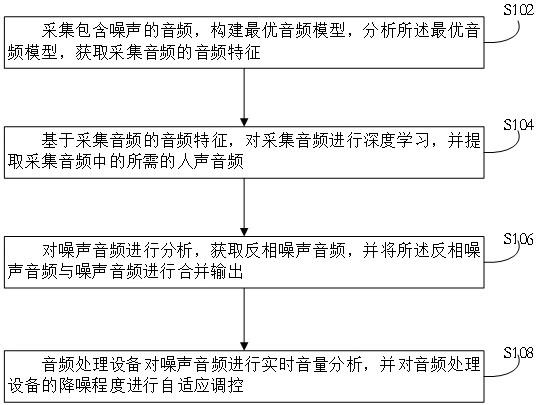
3、本发明第一方面提供了一种基于深度学习的音频降噪方法,包括以下步骤:
4、采集包含噪声的音频,构建最优音频模型,分析所述最优音频模型,获取采集音频的音频特征;
5、基于采集音频的音频特征,对采集音频进行深度学习,并提取采集音频中的所需的人声音频;
6、对噪声音频进行分析,获取反相噪声音频,并将所述反相噪声音频与噪声音频进行合并输出;
7、音频处理设备对噪声音频进行实时音量分析,并对音频处理设备的降噪程度进行自适应调控。
8、进一步的,本发明的一个较佳实施例中,所述采集包含噪声的音频,构建最优音频模型,分析所述最优音频模型,获取采集音频的音频特征,具体为:
9、通过音频处理设备,实时采集包含噪声的音频,定义为采集音频,在所述音频处理设备中构建音频存储库,将采集音频存储至所述音频存储库中;
10、将采集音频进行切分和标记,并进行音频数据预处理,所述音频数据预处理包括对采集音频进行采样率调整和归一化处理;
11、将进行音频数据预处理后的采集音频导入至信号处理工具中进行傅里叶变换,转化为采集音频频域,对所述采集音频频域进行分析,获取采集音频频域的时域特性和能量分布特性;
12、获取采集音频所处环境的环境参数,基于大数据网络检索,获取所有的音频模型样本,将所有的音频模型样本与采集音频所处环境的环境参数进行对照分析,得到对照分析重合度最高的音频模型样本,定义为最优音频模型;
13、将所述采集音频频域的时域特性和能量分布特性导入最优音频模型中进行模型训练,得到训练后的最优音频模型;
14、基于最大似然法,获取训练后的最优音频模型的模型参数,所述模型参数为采集音频的音频特征。
15、进一步的,本发明的一个较佳实施例中,所述基于采集音频的音频特征,对采集音频进行深度学习,并提取采集音频中的所需的人声音频,具体为:
16、将所述采集音频的音频特征导入深度神经网络模型中,对深度神经网络模型的权重及偏置参数进行初始化处理,并选择交叉熵函数作为深度神经网络模型的损失函数;
17、基于随机梯度下降法,对深度神经网络模型的网络参数进行更新,基于更新后的网络参数,最小化交叉熵函数;
18、基于最小化后的交叉熵函数,对深度神经网络模型进行反向训练,得到训练结果,在反向训练过程中,获取训练过程中的超参数,基于训练结果,并对超参数进行调整,得到训练好的深度学习模型;
19、将所述采集音频导入训练好的深度学习模型中进行音频初步分离,得到初步人声音频和初步噪声音频;
20、获取初步人声音频和初步噪声音频的信噪比,并预设标准信噪比,若初步人声音频和初步噪声音频的信噪比小于标准信噪比,则基于小波分解法,使用小波基函数将所述初步人声音频和初步噪声音频进行多次分解,得到多组近似函数和细节函数,在每次分解后保留细节函数,并通过逆小波变换将细节函数重新合并,得到人声音频和噪声音频;
21、若初步人声音频和初步噪声音频的信噪比在标准信噪比阈值内,则将初步人声音频和初步噪声音频直接输出,得到人声音频和噪声音频。
22、进一步的,本发明的一个较佳实施例中,所述对噪声音频进行分析,获取反相噪声音频,并将所述反相噪声音频与噪声音频进行合并输出,具体为:
23、对采集音频频域的时域特性和能量分布特性进行分析及特征提取,获取噪声音频的时域特性和能量分布特性;
24、基于所述噪声音频的时域特性和能量分布特性,在自适应滤波器中,获取自适应滤波器的权重系数;
25、基于最小化均方误差法,对自适应滤波器的权重系数进行调整训练,并将所述噪声音频分成多个噪声音频样本;
26、训练后的自适应滤波器逐个对噪声音频样本进行分析和取反处理,生成反相噪声音频样本,将多个反相噪声音频样本结合,生成反相噪声音频;
27、将所述反相噪声音频与噪声音频相结合,输出初步处理后的噪声音频,定义为初步处理音频,对所述初步处理音频的音频幅度进行调整,得到处理音频;
28、将所述处理音频与人声音频结合,生成输出音频,所述输出音频通过音频处理设备输出;
29、对输出音频的人声部分进行智能优化处理,使输出音频更生动清晰,得到处理后的输出音频。
30、进一步的,本发明的一个较佳实施例中,所述对输出音频的人声部分进行智能优化处理,使输出音频更生动清晰,得到人声智能优化后的输出音频,具体为:
31、所述音频处理设备获取处理后的输出音频的人声部分的音纹信息,定义为输入音纹信息,将输入音纹信息导入音频处理设备的音纹存储库中,并计算输入音纹信息与音纹存储库中音纹信息的欧氏距离;
32、若音纹存储库中不存在与输入音纹信息的欧氏距离在预设阈值内的音纹信息,则通过增加输出音频振幅,对输出音频进行声音增强,并对输出音频的音调进行校正,及维持输出音频的频谱平衡,最后基于语音处理工具对输出音频进行智能音纹修正,得到人声智能优化后的输出音频;
33、若音纹存储库中存在与输入音纹信息的欧氏距离在预设阈值内的音纹信息,则将对应的音纹信息导出并合并至输出音频中,对输出音频进行人声智能优化,得到人声智能优化后的输出音频。
34、进一步的,本发明的一个较佳实施例中,所述音频处理设备对噪声音频进行实时音量分析,并对音频处理设备的降噪程度进行自适应调控,具体为:
35、音频处理设备实时获取噪声音频的分贝值,并将噪声音频的实时分贝值导入大数据网络中进行大数据检索,获取不同噪声音频的实时分贝值对人体的影响程度;
36、基于所述不同噪声音频的实时分贝值对人体的影响程度,预设第一分贝阈值、第二分贝阈值和第三分贝阈值;
37、当噪声音频的实时分贝值小于第一分贝阈值,则音频处理设备对采集音频中的人声音频进行实时分贝值分析,音频处理设备基于人生音频的实时分贝值分析结果进行人声音频分贝值智能调控;
38、当噪声音频的实时分贝值大于第一分贝阈值且小于第二分贝阈值,则获取噪声音频的实时分贝值,并基于噪声音频获取反相噪声音频,根据噪声音频的实时分贝值,对反相噪声音频的频率进行智能调控,维持反相噪声音频的频率绝对值与噪声音频的频率绝对值动态重合;
39、当噪声音频的实时分贝值大于第二分贝阈值且小于第三分贝阈值,则基于大数据检索,获取人体能承受的最大反相噪声音频频率,定义为最大反相噪声音频频率,所述音频处理设备输出满足最大反相噪声音频频率的反相噪声音频;
40、当噪声音频的实时分贝值大于第三分贝阈值,则音频处理设备输出满足最大反相噪声音频频率的反相噪声音频,并通过音频处理设备向使用者发出警告信号,提醒使用者远离所在地,当音频处理设备检测到噪声音频的实时分贝值大于第二分贝阈值且小于第三分贝阈值,则停止发出警告信号,并维持输出满足最大反相噪声音频频率的反相噪声音频。
41、本发明第二方面还提供了一种基于深度学习的音频降噪系统,所述音频降噪系统包括存储器与处理器,所述存储器中储存有一种基于深度学习的音频降噪方法,所述一种基于深度学习的音频降噪方法被所述处理器执行时,实现如下步骤:
42、采集包含噪声的音频,构建最优音频模型,分析所述最优音频模型,获取采集音频的音频特征;
43、基于采集音频的音频特征,对采集音频进行深度学习,并提取采集音频中的所需的人声音频;
44、对噪声音频进行分析,获取反相噪声音频,并将所述反相噪声音频与噪声音频进行合并输出;
45、音频处理设备对噪声音频进行实时音量分析,并对音频处理设备的降噪程度进行自适应调控。
46、本发明解决的背景技术中存在的技术缺陷,本发明具备以下有益效果:采集包含噪声的音频,构建最优音频模型并获取采集音频的音频特征,对所述采集音频的音频特征进行深度学习,提取人声音频和噪声音频,根据所述噪声音频,获取反相噪声音频并进行合并输出。音频处理设备对噪声音频进行实时音量分析,并对音频处理设备的降噪程度进行自适应调控。本发明能够通过音频处理设备对降噪音频的深度学习,来进行音频的实时降噪,保护音频处理设备用户的身体健康,并使降噪效果更完美。
- 还没有人留言评论。精彩留言会获得点赞!