信号处理方法及装置、计算机可读存储介质、终端与流程
1.本技术涉及语音处理技术领域,尤其涉及一种信号处理方法及装置、计算机可读存储介质、终端。
背景技术:
2.目前,用户对于语音通信质量的要求越来越高,为此,现有的一些终端配备至少两个麦克风以提高对噪声的抑制能力。例如,在配置两个麦克风的场景下,其中一个麦克风用于采集拾取背景噪声,另一个麦克风用于拾取带噪声的语音,然后根据两个麦克风采集的信号进行降噪处理。然而现有的降噪方案鲁棒性较差,在用户手持终端通话的过程中,仍然容易出现语音质量较差的情况。
技术实现要素:
3.本技术的技术目的之一是提供一种鲁棒性更好的信号处理方法,以提高终端的语音质量。
4.为解决上述技术问题,本技术实施例提供一种信号处理方法,所述方法应用于终端,所述终端配置有主麦克风和辅麦克风,包括:获取所述主麦克风采集的第一输入信号和所述辅麦克风采集的第二输入信号;确定用户手持所述终端的姿势;根据所述姿势选择噪声估计算法,并采用选择的噪声估计算法对所述第一输入信号和/或第二输入信号进行噪声估计,得到噪声信号;根据所述噪声信号对所述第一输入信号或者所述第二输入信号进行处理,得到输出信号。
5.可选的,用户手持所述终端的姿势和所述终端与竖直方向之间的夹角相关;其中,所述夹角越大,所述主麦克风与用户的嘴部之间的距离越大。
6.可选的,所述姿势属于第一姿势,在所述第一姿势下,所述夹角大于或等于第一预设值,采用选择的噪声估计算法对所述第一输入信号和/或第二输入信号进行噪声估计,得到噪声信号包括:采用单麦噪声估计算法对所述第一输入信号或者所述第二输入信号进行噪声估计,得到所述噪声信号。
7.可选的,所述姿势属于第一姿势,在所述第一姿势下,所述夹角大于或等于第一预设值,采用选择的噪声估计算法对所述第一输入信号和/或第二输入信号进行噪声估计,得到噪声信号包括:根据所述第二输入信号,对所述第一输入信号进行滤波处理,得到所述噪声信号。
8.可选的,采用选择的噪声估计算法对所述第一输入信号和/或第二输入信号进行噪声估计,得到噪声信号包括:根据所述第一输入信号,对所述第二输入信号进行滤波处理,得到所述噪声信号;其中,所述滤波处理采用的滤波系数的更新速度与所述夹角正相关。
9.可选的,第二姿势下所述滤波系数的更新速度大于第三姿势下所述滤波系数的更新速度;其中,在所述第二姿势下,所述夹角大于第二预设值,在所述第三姿势下,所述夹角
小于或等于所述第二预设值。
10.可选的,所述姿势属于所述第二姿势,根据所述第一输入信号,对所述第二输入信号进行滤波处理之前,所述方法还包括:判断当前帧是否存在语音活动;如果当前帧存在语音活动,则根据第一步长值更新所述滤波系数,否则,根据第二步长值更新所述滤波系数,其中,所述第二步长值小于所述第一步长值。
11.可选的,所述第二步长值为0。
12.本技术实施例还提供一种信号处理装置,所述装置包括:获取模块,用于获取终端的主麦克风采集的第一输入信号和辅麦克风采集的第二输入信号;姿势确定模块,用于确定用户手持所述终端的姿势;噪声估计模块,用于根据所述姿势选择噪声估计算法,并采用选择的噪声估计算法对所述第一输入信号和/或第二输入信号进行噪声估计,得到噪声信号;处理模块,用于根据所述噪声信号对所述第一输入信号或者所述第二输入信号进行处理,得到输出信号。
13.本技术实施例还提供一种计算机可读存储介质,其上存储有计算机程序,所述计算机程序被处理器运行时,执行上述的信号处理方法的步骤。
14.本技术实施例还提供一种终端,包括存储器和处理器,所述存储器上存储有可在所述处理器上运行的计算机程序,所述处理器运行所述计算机程序时执行上述的信号处理方法的步骤。
15.与现有技术相比,本技术实施例的技术方案具有以下有益效果:
16.在本技术实施例的方案中,确定用户手持终端的姿势,并根据用户手持终端的姿势选择噪声估计算法,然后采用选择的噪声估计算法对主麦克风采集的第一输入信号和/或辅麦克风采集的第二输入信号进行噪声估计,得到噪声信号;根据噪声信号对第一输入信号或者第二输入信号进行处理,得到输出信号。本实施例的方案中,根据用户手持终端的姿势选择噪声估计算法,使得用于噪声估计的算法适应于用户手持终端的姿势,从而可以在不同姿势下均能够较好地抑制噪声,获得稳定的降噪性能,降噪的鲁棒性更好。
17.进一步,本技术实施例的方案中,当用户手持终端的姿势对应的夹角大于或等于第一预设值时,采用单麦噪声估计算法进行噪声估计或者采用第二输入信号对第一输入信号进行滤波,得到噪声信号。采用这样的方案,可以在终端外扩的程度较大的情况下,得到更加准确的噪声信号,有利于避免降噪后出现语音失真的情况。
18.进一步,本技术实施例的方案中,根据第一输入信号,对第二输入信号进行滤波处理,得到噪声信号,其中,第二姿势下滤波系数的更新速度大于第三姿势下滤波系数的更新速度。采用这样的方案,可以在终端外扩的情况下,加快滤波系数的更新速度,消除第二输入信号中更多的语音,得到更加准确的噪声信号,有利于减少在降噪过程中的语音损失。
19.进一步,本技术实施例的方案中,在第二姿势下,根据第一输入信号,对第二输入信号进行滤波处理之前,判断当前帧是否存在语音活动;如果当前帧存在语音活动,则根据第一步长值更新滤波系数,否则,根据第二步长值更新所述滤波系数,其中,第二步长值小于第一步长值。采用这样的方案,有利于改善因加快更新滤波系数导致噪声过小的情况,使得估计的噪声信号更加准确,提高降噪的性能。
附图说明
20.图1是一种用户手持终端的姿势的示意图;
21.图2是本技术实施例中一种终端的结构示意图;
22.图3是本技术实施例中另一种终端的结构示意图;
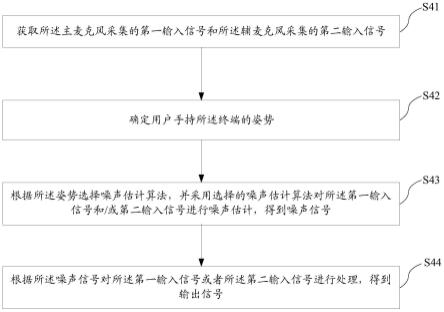
23.图4是本技术实施例中一种信号处理方法的流程示意图;
24.图5是另一种用户手持终端的姿势的示意图;
25.图6是本技术实施例中另一种信号处理方法的流程示意图;
26.图7是采用本技术实施例的方案和采用现有方案进行信号处理的一种性能对比示意图;
27.图8是采用本技术实施例的方案和采用现有方案进行信号处理的另一种性能对比示意图;
28.图9是本技术实施例中一种信号处理装置的结构示意图。
具体实施方式
29.如背景技术所述,现有的降噪方案鲁棒性较差,在用户手持终端通话的过程中,仍然容易出现语音质量较差的情况。
30.现有的降噪方案通常仅考虑正常姿势下(例如,图1示出的姿势)的场景。参照图1,图1是一种用户手持终端的姿势的示意图。
31.如图1所示,图1示出了通常情况下用户手持终端的姿势。具体而言,在图1示出的姿势下,主麦克风靠近用户的嘴部,主麦克风和用户的嘴部之间的距离明显小于辅麦克风和用户嘴部之间的距离,主麦克风采集的信号和辅麦克风采集的信号之间具有较为明显的能量差,利用两者的能量差进行噪声估计,能够较好地抑制噪声。
32.然而由于用户使用习惯等原因,在实际应用中,大概率会出现用户手持外扩的情况。在手持外扩的情况下,主麦克风与用户的嘴部之间的距离较远,主麦克风和辅麦克风拾取的信号能量接近,如果也沿用正常姿势下的噪声估计方法,会出现语音损失甚至是无声的情况。
33.为了解决上述技术问题,本技术实施例提供一种信号处理方法,在本技术实施例的方案中,确定用户手持终端的姿势,并根据用户手持终端的姿势选择噪声估计算法,然后采用选择的噪声估计算法对主麦克风采集的第一输入信号和/或辅麦克风采集的第二输入信号进行噪声估计,得到噪声信号;根据噪声信号对第一输入信号或者第二输入信号进行处理,得到输出信号。本实施例的方案中,根据用户手持终端的姿势选择噪声估计算法,使得用于噪声估计的算法适应于用户手持终端的姿势,从而可以在不同姿势下均能够较好地抑制噪声,获得较高的降噪性能,降噪的鲁棒性更好。
34.为使本技术的上述目的、特征和有益效果能够更为明显易懂,下面结合附图对本技术的具体实施例做详细的说明。
35.需要说明的是,本技术实施例中的终端可以配置有至少两个麦克风,麦克风可以是指语音采集模块,所述语音采集模块集成于终端。其中,终端可以是语音通话设备、语音录制设备等,例如,可以是手机、穿戴式设备、计算机、平板电脑等,但并不限于此。语音采集模块也可以是现有的各种具有语音采集功能的器件,本实施例对于语音采集模块的结构或
型号并不进行限制。
36.进一步地,终端配置的至少两个麦克风可以包括:主麦克风和辅麦克风。主麦克风和辅麦克风设置于终端的不同位置。在理想情况下,主麦克风拾取用户的语音,辅麦克风拾取背景噪声。
37.参照图2,图2是本技术实施例中一种终端的结构示意图。
38.如图2所示,主麦克风101设置于终端10的底部,辅麦克风102设置于终端10的顶部。
39.参照图3,图3是本技术实施例中另一种终端的结构示意图。
40.如图3所示,主麦克风201设置于终端20的底部,辅麦克风202设置于终端20的背部。更具体地,辅麦克风202设置于终端20的背部的上方区域。在一个具体的例子中,辅麦克风202可以设置于终端20的后置摄像头的附近。
41.需要说明的是,图2和图3仅示例性地示出主麦克风和辅麦克风在终端上的布局,在实际应用中,主麦克风和辅麦克风也可以设置于终端的其他位置,本实施例对此并不限制。
42.参照图4,图4是本技术实施例中一种信号处理方法的流程示意图。所述方法可以由终端执行,终端配置有主麦克风和辅麦克风,换言之,终端为双通道的设备。关于终端的具体描述可以参照上文的相关描述,在此不再赘述。
43.图4示出的信号处理方法可以包括以下步骤:
44.步骤s41:获取所述主麦克风采集的第一输入信号和所述辅麦克风采集的第二输入信号;
45.步骤s42:确定用户手持所述终端的姿势;
46.步骤s43:根据所述姿势选择噪声估计算法,并采用选择的噪声估计算法对所述第一输入信号和/或第二输入信号进行噪声估计,得到噪声信号;
47.步骤s44:根据所述噪声信号对所述第一输入信号或者所述第二输入信号进行处理,得到输出信号。
48.可以理解的是,在具体实施中,上述方法可以采用软件程序的方式实现,该软件程序运行于芯片或芯片模组内部集成的处理器中;或者,该方法可以采用硬件或者软硬结合的方式来实现,例如用专用的芯片或芯片模组来实现,或者,用专用的芯片或芯片模组结合软件程序来实现。
49.在步骤s41的具体实施中,获取第一输入信号和第二输入信号,其中,第一输入信号由终端的主麦克风采集得到,第二输入信号由终端的辅麦克风采集得到。为便于描述,下文中主麦克风也可以被称为“主麦”,辅麦克风也可以被称为“辅麦”,第一输入信号可以表示为s1(n),第二输入信号可以表示为s2(n)。其中,第一输入信号s1(n)和第二输入信号s2(n)均为时域信号。
50.在步骤s42的具体实施中,可以确定用户手持终端的姿势。本实施例的方案中,用户手持终端的姿势与终端和竖直方向之间的夹角相关。其中,竖直方向可以是指垂直于水平面的方向。
51.具体而言,用户手持终端的姿势不同,终端和竖直方向的夹角也不同。夹角的大小可以用于表征终端外扩的程度。
52.参照图5,图5是本技术实施例中另一种用户手持终端的姿势的示意图。图5示出了终端外扩的场景,在图5示出的姿势下,主麦远离用户的嘴部,主麦与用户的嘴部之间的距离、辅麦与用户嘴部之间的距离的差异较小。在一些情况下,辅麦与用户嘴部之间的距离可能大于主麦与用户的嘴部之间的距离。
53.如图5所示,终端和竖直方向之间的夹角为θ,夹角θ的大小和终端外扩的程度正相关,θ越大,主麦和用户的嘴部之间的距离越大,第一输入信号中的语音信号越少,噪声信号越多。另外,相较于图1示出的正常姿势的场景,在终端外扩的场景下,第二输入信号中语音信号的占比也会增大。更具体地,θ越大,第二输入信号中的语音信号越多。
54.在具体实施中,可以预先设置有多个姿势,预先设置的每个姿势可以具有对应的夹角范围,预先设置的各个姿势对应的夹角范围互不相同或者互不重叠。更具体地,可以采用以下任意一种方式从预先设置的多个姿势中确定用户手持终端的姿势,但并不限于此:
55.方式一:可以根据第一输入信号和第二输入信号的相位差进行波达方向(direction of arrival,简称doa)估计,以确定声源方向,最终确定用户手持终端的姿势。
56.方式二:可以根据第一输入信号和第二输入信号的能量差确定用户手持终端的姿势。具体而言,在不同姿势下,第一输入信号和第二输入信号的能量差是不同的,用户外扩的程度越大,第一输入信号和第二输入信号的能量差越小,因此可以根据第一输入信号和第二输入信号的能量差确定用户手持终端的姿势。
57.方式三:可以采用基于传感器的方法确定用户手持终端的姿势。例如,终端可以设置有接近光传感器,采用接近光传感器检测用户手持终端的姿势。
58.需要说明的是,上述仅示例性地给出确定用户手持终端的姿势的实施方式,在实际应用中,还可以采用其他适当的方式来确定用户手持终端的姿势,姿势不同,终端外扩的程度也不同。
59.在一个非限制性的例子中,可以确定上述的夹角θ,并将夹角作为用户手持终端的姿势。也即,可以通过夹角θ来表示用户手持终端的姿势。
60.在具体实施中,可以按照预设的时间间隔周期性地执行步骤s42。具体地,在主麦克风采集第一输入信号和辅麦克风采集第二输入信号的过程中,可以周期性地确定用户手持终端的姿势。采用这样的方案,可以识别到用户通话过程中姿势的变化,由此可以动态地切换噪声估计算法,有利于在通话过程中始终保持较好的通话质量。
61.继续参照图4,在步骤s43的具体实施中,可以根据步骤s42中确定的用户手持终端的姿势选择噪声估计算法,并采用选择的噪声估计算法进行噪声估计。
62.在本技术的一实施例中,如果用户手持终端的姿势属于第一姿势,则可以采用方法一或者方法二进行噪声估计,但并不限于此,其中,在第一姿势下,上述的夹角θ大于或等于第一预设值,本实施例中的第一姿势可以理解为外扩程度较大的姿势,在第一姿势下,主麦采集的第一输入信号中语音信号的占比较小,噪声信号的占比较大。
63.方法一:采用单麦噪声估计算法对第一输入信号或者第二输入信号进行噪声估计,得到噪声信号。
64.在具体实施中,可以采用单麦噪声估计算法对当前帧的第一输入信号进行噪声估计,得到当前帧的噪声信号。或者,采用单麦噪声估计算法对当前帧的第二输入信号进行噪声估计,得到当前帧的噪声信号。
65.其中,单麦噪声估计算法可以是现有的各种适当算法,例如,可以是最小值跟踪法、递归平均法等,本实施例对此并不进行限制。
66.方法二:根据第二输入信号对第一输入信号进行滤波处理,得到噪声信号。
67.具体而言,可以对第二输入信号进行延迟处理,得到延迟信号;进一步地,根据延迟信号和滤波系数确定估计的语音信号,也即,根据辅麦采集的信号估计语音信号;然后可以根据估计的语音信号对第一输入信号进行滤波,由此得到噪声信号。
68.更具体地,如果用户手持终端的姿势属于第一姿势,则可以根据下式确定噪声信号:
[0069][0070]
其中,s4(n)表示噪声信号,s3(n)表示延迟信号,h(n)表示时域滤波系数。
[0071]
需要说明的是,n表示每帧语音帧内采样点索引,时域滤波系数可以逐帧地更新。也即,时域滤波系数可以是一帧一帧地更新。
[0072]
进一步地,如果用户手持终端的姿势不属于第一姿势,则可以根据第一输入信号对第二输入信号进行滤波处理,得到噪声信号。如果用户手持终端的姿势不属于第一姿势,则说明外扩程度较小,相应的,主麦采集的第一输入信号中语音信号的占比较大。
[0073]
具体而言,可以对第一输入信号进行延迟处理,得到延迟信号;进一步地,根据延迟信号和滤波系数确定估计的语音信号,也即,根据主麦采集的信号估计语音信号;然后可以根据估计的语音信号对第二输入信号进行滤波,由此得到噪声信号。
[0074]
更具体地,如果用户手持终端的姿势不属于第一姿势,可以根据下式确定噪声信号:
[0075][0076]
在本技术的另一实施例中,可以根据第一输入信号对第二输入信号进行滤波处理,得到噪声信号,其中,滤波处理采用的滤波系数h(n)在时域上可以是不断更新的,滤波系数的更新速度与夹角正相关。也即,夹角越大,滤波处理采用的滤波系数的更新速度越快。换言之,本实施例的方案中,通过滤波系数的更新速度来适应不同的姿势,也即,通过调整滤波系数的更新速度来适应不同程度的外扩。
[0077]
在一个具体的例子中,第二姿势下滤波系数的更新速度大于第三姿势下滤波系数的更新速度。其中,在第二姿势下,上述的夹角θ大于第二预设值,在第三姿势下,上述的夹角θ小于或等于第二预设值,也即,第二姿势下的外扩程度大于第三姿势下的外扩程度。
[0078]
在具体实施中,当前帧的滤波系数可以是根据步长值对上一帧的滤波系数更新得到的。由此,可以通过调整用于更新滤波系数的步长值来调整滤波系数的更新速度。
[0079]
具体地,如果当前帧对应的姿势为第二姿势,则可以采用第一步长值更新上一帧的滤波系数,如果当前帧对应的姿势为第三姿势,则可以采用第二步长值更新上一帧的滤波系数,其中,第二步长值小于第二步长值。
[0080]
在一个非限制性的例子中,如果用户手持终端的姿势属于第二姿势,则在根据当前帧的第一输入信号对当前帧的第二输入信号进行滤波处理之前,可以判断当前帧是否存在语音活动,如果是,则可以根据第一步长值更新上一帧的滤波系数,否则,根据第二步长值更新上一帧的滤波系数,其中,第二步长值小于第一步长值。
[0081]
具体地,可以通过语音活动检测(voice active detection,简称vad)方法判断当前帧是否存在语音活动。更具体地,可以采用单麦vad方法。本实施例对于单麦vad方法并不进行限制,例如可以是基于基音检测的vad方法、基于深度学习的vad方法等。
[0082]
在一个具体的例子中,可以对当前帧的第一输入信号进行单麦降噪处理,如果单麦降噪处理前后的输入输出信号的能量差异大于预设阈值,则可以确定当前帧不存在语音活动,反之可以确定当前帧存在语音活动。
[0083]
进一步地,在当前帧存在语音活动的情况下,采用第一步长值更新滤波系数,以加快滤波系数的更新速度;在当前帧不存在语音活动的情况下,可以不更新滤波系数,也即,可以将上一帧的滤波系数作为当前帧的滤波系数。换言之,第二步长值为0。
[0084]
在具体实施中,考虑到语音活动检测可能存在错误的情况,不更新滤波系数可能无法准确地估计噪声,为此,本实施例的方案中,第二步长值可以大于0且小于第一步长值。例如,第二步长值可以为第一步长值的1/2。
[0085]
由上,通过执行步骤s42和步骤s43,可以得到噪声信号。由于噪声信号是通过适应于用户手持终端的姿势的噪声估计算法确定的,因此得到的噪声信号更加准确。
[0086]
需要说明的是,本实施例的方案中,可以采用自适应滤波器进行滤波处理。具体而言,自适应滤波器的输入信号为延迟的第一输入信号,参考信号为第二输入信号,或者自适应滤波器的输入信号为延迟的第二输入信号,参考信号为第一输入信号,自适应滤波器的输出信号为噪声信号。本实施例对于自适应滤波器采用的更新算法并不进行限制,例如,可以是以下任意一种,但并不限于此:最小均方算法(least mean square,简称lms)、归一化最小均方算法(normalized least mean square algorithm,简称nlms)、最小二乘算法(recursive least square,简称rls)、频域最小均方算法、加窗频域最小均方算法等。
[0087]
还需要说明的是,本实施例的方案中,可以根据主麦克风和辅麦克风之间的距离进行延迟处理。更具体地,延迟程度delay=d/c,其中,d可以表示主麦克风和辅麦克风之间的距离,c可以表示声速。
[0088]
在步骤s44的具体实施中,可以根据噪声信号进行后处理,得到输出信号,输出信号可以是指降噪后得到的信号。
[0089]
具体而言,如果噪声信号是对第二输入信号进行滤波处理得到或者噪声信号是采用单麦噪声估计算法得到,则在步骤s44中,可以根据噪声信号对第一输入信号进行后处理,得到输出信号。如果噪声信号是对第一输入信号进行滤波得到,则在步骤s44中,可以根据噪声信号对第二输入信号进行后处理,得到输出信号。
[0090]
在一个非限制性的例子中,当姿势属于第一姿势,根据第二输入信号对第一输入信号进行滤波处理,得到噪声信号;然后对第二输入信号进行后处理,得到输出信号。当姿势不属于第一姿势(例如,第二姿势或第三姿势),根据第一输入信号对第二输入信号进行滤波处理,得到噪声信号;然后对第一输入信号进行后处理,得到输出信号。
[0091]
在实际应用中,用户通话过程中终端外扩的程度可能是逐渐增大的,当检测到姿势从不属于第一姿势的其他姿势(例如,第二姿势)切换至第一姿势时,如果采用上述的方案,可能会出现音量突变的情况,也即,输入信号发生突变。为了改善这一问题,本技术实施例进一步提出:在采用方法二进行噪声估计的情况下,在根据噪声信号对第二输入信号进行处理之前,可以先进行自适应增益调整,然后根据噪声信号对自适应增益调整后的第二
输入信号进行处理,得到输出信号。
[0092]
具体而言,可以采用下式计算自适应增益:
[0093][0094]
其中,λ为语音帧的帧索引,i为频点索引,sa1(λ,i)为第一输入信号对应的第一频域信号在第i个频点的幅度谱,sa2(λ,i)为第二输入信号对应的第二频域信号在第i个频点的幅度谱;p(λ,i)为第λ帧第i个频点的语音存在概率,α为0至1之间的增益平滑系数,一般可以选取0.95~0.98,noisefloor为底噪的幅度谱,一般可以选取-80db,fs为计算幅度谱和的起始频点,fe为计算幅度谱和的终止频点,一般选取的频率为200hz~4000hz。
[0095]
其中,终端外扩程度越大,语音帧的gain(λ)的取值越接近于0,而由于噪声帧的p(λ,i)值很小,gain(λ)的取值接近1。
[0096]
进一步地,可以计算第λ帧的自适应增益和第λ帧的第二输入信号的乘积,并根据噪声信号对得到的乘积进行处理,以得到最终的输出信号。
[0097]
由上,通过根据自适应增益对第二输入信号进行处理,有利于解决输出信号音量突变的问题。
[0098]
由上,本技术实施例的方案中,根据用户手持终端的姿势选择噪声估计算法,使得用于噪声估计的算法适应于用户手持终端的姿势,从而可以在不同姿势下均能够较好地抑制噪声,获得较高的降噪性能,方案的鲁棒性更好。
[0099]
参照图6,图6是本技术实施例中另一种信号处理方法的流程示意图。下面主要就图6和图4的不同之处进行说明。
[0100]
步骤s61,获取第一输入信号和第二输入信号。
[0101]
步骤s62,确定当前帧用户手持终端的姿势。
[0102]
在具体实施中,预先设置有第一姿势、第二姿势和第三姿势,其中,第一姿势下,夹角大于或等于第一预设值,第二姿势下,夹角小于第一预设值且大于第二预设值,第三姿势下,夹角小于或等于第二预设值,其中,第一预设值大于第二预设值。第一预设值和第二预设值的具体取值可以根据实际应用需求进行设置。
[0103]
在一个具体的例子中,第二预设值为30度,第一预设值为90度。如果用户手持终端的姿势为第一姿势,则可以判定终端外扩的程度很大,第一姿势也可以被称为“大张角外扩”。如果用户手持终端的姿势为第二姿势,则可以判定终端外扩的程度较大,第二姿势也可以被称为“一般外扩”。如果用户手持终端的姿势为第三姿势,则可以判定终端外扩的程度较小,接近于图1示出的姿势,第三姿势也可以被称为“正常姿势”。
[0104]
如果确定当前帧用户手持终端的姿势属于第一姿势,则执行步骤s63;如果确定当前帧用户手持终端的姿势属于第二姿势,则执行步骤s64;如果确定当前帧用户手持终端的姿势属于第三姿势,则执行步骤s65。
[0105]
步骤s63,采用单麦噪声估计算法对第一输入信号或者第二输入信号进行噪声估计,得到当前帧的噪声信号。
[0106]
步骤s64,判断当前帧是否存在语音活动。如果判断结果为是,则执行步骤s66,否则执行步骤s65。
[0107]
步骤s65,根据第一步长值更新上一帧的滤波系数,得到当前帧的滤波系数。
[0108]
步骤s66,根据第二步长值更新上一帧的滤波系数,得到当前帧的滤波系数。
[0109]
在一个具体的例子中,自适应滤波器的更新算法采用nlms,滤波系数的更新策略如下:
[0110][0111]
其中,h为自适应滤波器的滤波系数的频域表示,h(λ)为当前帧的滤波系数的频域表示,是一个1
×
n的矢量,μ(λ)表示当前帧的步长值,δh表示更新项,λ表示帧索引,fft表示快速傅里叶变换,ifft表示快速傅里叶逆变换,m表示每帧的采样点数、n表示每帧fft的点数,x为第二输入信号的频域表示,x
*
表示对x进行共轭计算,e为误差信号的频域表示,δ表示用于防止滤波器发散的预设参数,p(λ)表示当前帧的语音存在概率矢量,也就是当前帧第1到第n个频点的语音存在概率向量,在有语音时,各个频点(即第1到n个频点)语音存在概率趋近于1,在没有语音时,各个频点的语音存在概率趋近于0,δh也趋近于0,滤波系数几乎不更新。
[0112]
如果姿势为第三姿势,或者,姿势为第二姿势且当前帧不存在语音活动,则可以根据h(λ)=h(λ-1)+μ(λ-1)
×
δh(λ)来更新当前帧的滤波系数;如果姿势为第二姿势且当前帧存在语音活动,则可以根据h(λ)=h(λ-1)+2
×
μ(λ-1)
×
δh(λ)来更新当前帧的滤波系数。
[0113]
步骤s67,根据当前帧的滤波系数和当前帧的第一输入信号,对当前帧的第二输入信号进行滤波处理,得到当前帧的噪声信号。
[0114]
步骤s68,根据当前帧的噪声信号对当前帧的第一输入信号进行处理,得到当前帧的输出信号。
[0115]
关于图6的更多内容可以参照图4中的相关描述,在此不再赘述。
[0116]
参照图7和图8,图7是采用本技术实施例的方案和采用现有方案进行信号处理的一种性能对比示意图,图8是采用本技术实施例的方案和采用现有方案进行信号处理的另一种性能对比示意图。
[0117]
更具体地,图7和图8示出了采用图6示出的方案和采用其他现有方案降噪的性能对比,其中,图7是在上述的第一姿势下的性能对比,图8是在上述的第二姿势下的性能对比。
[0118]
如图7所示,在第一姿势下,采用其他现有方案会出现无声现象,采用本实施例提供的方案能够改善大张角外扩下的无声问题,具体可以参见图7中框72标示出的部分。
[0119]
如图8所示,在第二姿势下,采用其他现有方案会出现语音失真的情况,尤其是高频段的语音失真严重,采用本实施例提供的方案能够明显改善一般外扩下的语音失真问题,具体可以参见图8中框81和框82标示出的部分。
[0120]
参照图9,图9是本技术实施例中的一种信号处理装置的结构示意图,图9示出的装置可以包括:
[0121]
获取模块91,用于获取终端的主麦克风采集的第一输入信号和辅麦克风采集的第
二输入信号;
[0122]
姿势确定模块92,用于确定用户手持所述终端的姿势;
[0123]
噪声估计模块93,用于根据所述姿势选择噪声估计算法,并采用选择的噪声估计算法对所述第一输入信号和/或第二输入信号进行噪声估计,得到噪声信号;
[0124]
处理模块94,用于根据所述噪声信号对所述第一输入信号或者所述第二输入信号进行处理,得到输出信号。
[0125]
在具体实施中,图9示出的信号处理装置可以对应于终端中具有信号处理功能的芯片;或者对应于具有信号处理功能的芯片模组,或者对应于终端。
[0126]
关于本技术实施例中的信号处理装置的工作原理、工作方法和有益效果等更多内容,可以参照上文关于信号处理方法的相关描述,在此不再赘述。
[0127]
本技术实施例还提供一种计算机可读存储介质,其上存储有计算机程序,所述计算机程序被处理器运行时,执行上述的信号处理方法的步骤。所述存储介质可以包括rom、ram、磁盘或光盘等。所述存储介质还可以包括非挥发性存储器(non-volatile)或者非瞬态(non-transitory)存储器等。
[0128]
本技术实施例还提供一种终端,包括存储器和处理器,所述存储器上存储有可在所述处理器上运行的计算机程序,所述处理器运行所述计算机程序时执行上述的信号处理方法的步骤。所述终端包括但不限于手机、计算机、平板电脑等终端设备。
[0129]
应理解,本技术实施例中,所述处理器可以为中央处理单元(central processing unit,简称cpu),该处理器还可以是其他通用处理器、数字信号处理器(digital signal processor,简称dsp)、专用集成电路(application specific integrated circuit,简称asic)、现成可编程门阵列(field programmable gate array,简称fpga)或者其他可编程逻辑器件、分立门或者晶体管逻辑器件、分立硬件组件等。通用处理器可以是微处理器或者该处理器也可以是任何常规的处理器等。
[0130]
还应理解,本技术实施例中的存储器可以是易失性存储器或非易失性存储器,或可包括易失性和非易失性存储器两者。其中,非易失性存储器可以是只读存储器(read-only memory,简称rom)、可编程只读存储器(programmable rom,简称prom)、可擦除可编程只读存储器(erasable prom,简称eprom)、电可擦除可编程只读存储器(electrically eprom,简称eeprom)或闪存。易失性存储器可以是随机存取存储器(random access memory,简称ram),其用作外部高速缓存。通过示例性但不是限制性说明,许多形式的随机存取存储器(random access memory,简称ram)可用,例如静态随机存取存储器(static ram,简称sram)、动态随机存取存储器(dram)、同步动态随机存取存储器(synchronous dram,简称sdram)、双倍数据速率同步动态随机存取存储器(double data rate sdram,简称ddr sdram)、增强型同步动态随机存取存储器(enhanced sdram,简称esdram)、同步连接动态随机存取存储器(synchlink dram,简称sldram)和直接内存总线随机存取存储器(direct rambus ram,简称dr ram)
[0131]
上述实施例,可以全部或部分地通过软件、硬件、固件或其他任意组合来实现。当使用软件实现时,上述实施例可以全部或部分地以计算机程序产品的形式实现。所述计算机程序产品包括一个或多个计算机指令或计算机程序。在计算机上加载或执行所述计算机指令或计算机程序时,全部或部分地产生按照本技术实施例所述的流程或功能。所述计算
机可以为通用计算机、专用计算机、计算机网络、或者其他可编程装置。所述计算机程序可以存储在计算机可读存储介质中,或者从一个计算机可读存储介质向另一个计算机可读存储介质传输,例如,所述计算机程序可以从一个网站站点、计算机、服务器或数据中心通过有线或无线方式向另一个网站站点、计算机、服务器或数据中心进行传输。
[0132]
在本技术所提供的几个实施例中,应该理解到,所揭露的方法、装置和系统,可以通过其它的方式实现。例如,以上所描述的装置实施例仅仅是示意性的;例如,所述单元的划分,仅仅为一种逻辑功能划分,实际实现时可以有另外的划分方式;例如多个单元或组件可以结合或者可以集成到另一个系统,或一些特征可以忽略,或不执行。所述作为分离部件说明的单元可以是或者也可以不是物理上分开的,作为单元显示的部件可以是或者也可以不是物理单元,即可以位于一个地方,或者也可以分布到多个网络单元上。可以根据实际的需要选择其中的部分或者全部单元来实现本实施例方案的目的。
[0133]
另外,在本技术各个实施例中的各功能单元可以集成在一个处理单元中,也可以是各个单元单独物理包括,也可以两个或两个以上单元集成在一个单元中。上述集成的单元既可以采用硬件的形式实现,也可以采用硬件加软件功能单元的形式实现。例如,对于应用于或集成于芯片的各个装置、产品,其包含的各个模块/单元可以都采用电路等硬件的方式实现,或者,至少部分模块/单元可以采用软件程序的方式实现,该软件程序运行于芯片内部集成的处理器,剩余的(如果有)部分模块/单元可以采用电路等硬件方式实现;对于应用于或集成于芯片模组的各个装置、产品,其包含的各个模块/单元可以都采用电路等硬件的方式实现,不同的模块/单元可以位于芯片模组的同一组件(例如芯片、电路模块等)或者不同组件中,或者,至少部分模块/单元可以采用软件程序的方式实现,该软件程序运行于芯片模组内部集成的处理器,剩余的(如果有)部分模块/单元可以采用电路等硬件方式实现;对于应用于或集成于终端的各个装置、产品,其包含的各个模块/单元可以都采用电路等硬件的方式实现,不同的模块/单元可以位于终端内同一组件(例如,芯片、电路模块等)或者不同组件中,或者,至少部分模块/单元可以采用软件程序的方式实现,该软件程序运行于终端内部集成的处理器,剩余的(如果有)部分模块/单元可以采用电路等硬件方式实现。
[0134]
应理解,本文中术语“和/或”,仅仅是一种描述关联对象的关联关系,表示可以存在三种关系,例如,a和/或b,可以表示:单独存在a,同时存在a和b,单独存在b这三种情况。另外,本文中字符“/”,表示前后关联对象是一种“或”的关系。
[0135]
本技术实施例中出现的“多个”是指两个或两个以上。本技术实施例中出现的第一、第二等描述,仅作示意与区分描述对象之用,没有次序之分,也不表示本技术实施例中对设备个数的特别限定,不能构成对本技术实施例的任何限制。虽然本技术披露如上,但本技术并非限定于此。任何本领域技术人员,在不脱离本技术的精神和范围内,均可作各种更动与修改,因此本技术的保护范围应当以权利要求所限定的范围为准。
[0136]
虽然本技术披露如上,但本技术并非限定于此。任何本领域技术人员,在不脱离本技术的精神和范围内,均可作各种更动与修改,因此本技术的保护范围应当以权利要求所限定的范围为准。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1