基于神经网络的语音特征滤波方法与流程
1.本发明涉及语音滤波技术领域,具体为基于神经网络的语音特征滤波方法。
背景技术:
2.语音是人类实现信息交换的最常用和最高效的方法之一,相对于视觉信号,语音可以表达更精炼、更抽象、更复杂的信息,语音信号在环境中产生和传播时,会受到环境噪声的影响,混入大量的噪声成分,在噪声强、信噪比低的场景下,语音信号会受到严重干扰,噪声污染影响了信息传递的可靠性与清晰度,信号滤波是一种典型的语音信号处理方法,主要是根据语音和噪声信号的频域分布特点,设计特定的带通、带阻滤波器进行频率过滤,尽可能将噪声部分滤除,保留语音信息,有实验表明:人的声音能量主要集中在低频部分,而噪声能量主要集中在高频部分,采用低通滤波器和带阻滤波器对含噪语音信号进行滤波具有较好的效果。
3.然而,经典的语音滤波方法具有先天的局限性:
4.(1)需要假设语音频段和噪声频段具有明显的分界线,这是实现频率滤波的前提条件,然而在现实中这一条件通常无法满足,噪声往往具有较宽的谱段,基本覆盖了语音的全部频段,经典滤波只能实现大体上的信噪分离。
5.(2)具有确定频谱“噪声”的概念本身就是一个伪命题,例如在人通话时,旁人的声音就是一种干扰“噪声”,在这种场景下信号和噪声可能没有明确的频谱差异,人类听觉系统对该类“噪声”的时候具有良好的抑制作用,但经典滤波算法则无能为力。
6.深度学习算法是一种针对大数据进行特征分布统计的算法,通过回归训练的方法,优化深度神经网络中数百万个滤波器参数,理论上可以得到精准适合人类语音特征分布的滤波器,在此基础上实现噪声滤波,就能很好地滤除噪声,还原真实的语音。
7.使用深度卷积网络对含噪声的语音信号进行“语音-噪声”分离,语音主要来自男女日常对话和朗读声音,噪声包括自然环境中的较轻微的环境声音、家庭和城市环境下的环境声音、公共场景下的喧闹噪声以及工厂和工地场景下的机器噪声等,通过深度学习进行训练后,形成以深度卷积神经网络为骨干的语音特征滤波器,能够在各种噪声场景下还原语音信息,这些噪声包括物品、工具产生的自然噪声和餐厅、体育场中的人群喧闹声等,本课题成果可以应用于手机、会议等语音滤波和语音增强场景中,更进一步,还针对个体人的语音模式滤波进行了初步的探索,并提出两种实现个体语音模式滤波的深度学习模型。
技术实现要素:
8.本发明的目的在于提供基于神经网络的语音特征滤波方法,以解决上述背景技术中提出的问题。
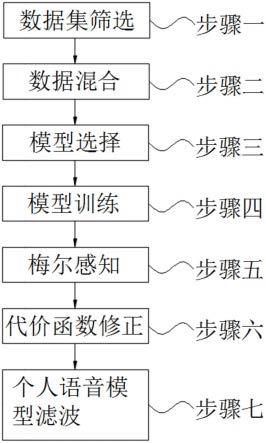
9.为实现上述目的,本发明提供如下技术方案:基于神经网络的语音特征滤波方法,包括以下步骤:步骤一,数据集筛选;步骤二,数据混合;步骤三,模型选择;步骤四,模型训练;步骤五,梅尔感知;步骤六,代价函数修正;步骤七,个人语音模型滤波;
10.其中在上述步骤一中,首先进行训练数据的准备,收集8个语音识别训练集,分别是:aidatatang_200zh、aishell-2、aishell-3、cn-celeb2、cv-corpus、magicdata、primewords_md_2018_set1、st-cmds-20170001_1-os,并且对训练集进行筛选,去除其中无效部分后形成语音原始数据集;
11.其中在上述步骤二中,当步骤一中的语音原始数据集准备完成后,随机选择一条语音和一条噪声数据,再随机从两段数据中各截取定长片片段进行混合,且噪声混合比从0.2-1.0随机,同时将语音信号转换到频域,实现“频域-频域”的拟合,拟合后的数据作为神经网络的输入(xi),以纯人声作为样本标注(yi);
12.其中在上述步骤三中,当步骤二中的数据拟合完成后,进行模型的选择,选择深度神经网络模型作为训练模型;
13.其中在上述步骤四中,当步骤三中的训练模型选择完毕后,将步骤二中拟合后的数据输入到训练模型中进行不停的迭代训练,u型网络总体上由编码分支e1-e6和解码分支d7-d1构成,编码分支将信号逐渐转换成特征,直到top层形成512维特征向量,解码分支将特征向量逐渐展开形成信号,为了解决从信号到特征信息损失的问题,需要用到损失函数,u型网络每一个隐藏层都会产生一个分支,和每一层的decode层合并,丰富输出的信号细节;
14.其中在上述步骤五中,由于人耳感知的声音频率和声音的实际频率不是线性的,人耳能轻易区分500hz和1000hz声音,但对2500hz和3000hz很难区分,从而利用经验公式将语音信号的频域变换为mel感知频域;
15.其中在上述步骤六中,利用mel感知曲线对mse代价函数进行修正,可得到更好的感知精度,即在相同的误差下,mel感知代价函数得到的语音效果要优于mse,mel感知代价函数数学表达式如下:
[0016][0017]
其中为mel曲线确定的误差函数:
[0018][0019]fmax
为该采样率下mel频率的最大值,如8000hz带宽下,f
max
=2481,a为调节系数,这里取a=1.6;
[0020]
其中在上述步骤七中,步骤六中的模型函数语音修正完成后,通过特征注入法,将预先获得的个人声纹特征向量作为通道滤波器注入u型网络中,在u型网络中间增加了一个分支,变成了三叉戟模样,因此称为trident net,随后通过迁移学习法,将训练好的通用语音滤波器使用特定的个人数据进行“精确调校”,得到个人语音模型,形成单个人模式滤波器,通过模式滤波器对含噪声音进行滤波,就能准确地还原其中的语音信息,同时能够在二人或多人的混合语音中提取特定人的语音。
[0021]
优选的,所述步骤一中,语音原始数据集共计4869个id,945686条语音数据,噪声数据选择了esc-50、tut-acoustic-scenes-2016、noisex-92等3456个不同场景下的环境声
音、人群声音和机器噪声等数据。
[0022]
优选的,所述步骤二中,利用短时傅里叶变换将语音信号转换到频域。
[0023]
优选的,所述步骤三中,深度神经网络模型为u型深度神经网络模型。
[0024]
优选的,所述步骤四中,损失函数使用均方差损失函数,其表达式为:
[0025][0026]
其中n为节点数量,为第i个节点的预测值,为第i个节点的标注值。
[0027]
优选的,所述步骤五中,经验公式为:
[0028][0029]
其中fmel是以梅尔为单位的感知频域,f是以hz为单位的实际语音频率。
[0030]
优选的,所述步骤七中,特征注入法主要训练流程如下:1)训练声纹识别网络,能够提取一段语音的声纹特征,一般使用512维特征向量表示;2)训练数据集中,除了“人声-噪声”随机混合外,还使用一定比例的“人声-人声”混合;3)将混合人声和指定id的声纹同时作为网络输入,将关键人“干净”原声作为标注,使用mse损失函数进行评价。
[0031]
与现有技术相比,本发明的有益效果是:本发明采用u型深度神经网络模型结合深度学习算法,通过回归训练的方法,优化深度神经网络中数百万个滤波器参数,有利于得到精准适合人类语音特征分布的滤波器,便于实现良好的“语音-噪声”分离,同时利用mel感知曲线对mse代价函数进行修正,实现了更好的听觉感受,使用trident-net和特征注入法实现个体语音分离,便于在二人或多人的混合语音中提取特定人的语音。
附图说明
[0032]
图1为本发明的方法流程图。
具体实施方式
[0033]
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
[0034]
请参阅图1,本发明提供的一种实施例:基于神经网络的语音特征滤波方法,包括以下步骤:步骤一,数据集筛选;步骤二,数据混合;步骤三,模型选择;步骤四,模型训练;步骤五,梅尔感知;步骤六,代价函数修正;步骤七,个人语音模型滤波;
[0035]
其中在上述步骤一中,首先进行训练数据的准备,收集8个语音识别训练集,分别是:aidatatang_200zh、aishell-2、aishell-3、cn-celeb2、cv-corpus、magicdata、primewords_md_2018_set1、st-cmds-20170001_1-os,并且对训练集进行筛选,去除其中无效部分后形成语音原始数据集,且语音原始数据集共计4869个id,945686条语音数据,噪声数据选择了esc-50、tut-acoustic-scenes-2016、noisex-92等3456个不同场景下的环境声
音、人群声音和机器噪声等数据;
[0036]
其中在上述步骤二中,当步骤一中的语音原始数据集准备完成后,随机选择一条语音和一条噪声数据,再随机从两段数据中各截取定长片片段进行混合,且噪声混合比从0.2-1.0随机,同时将语音信号转换到频域,且利用短时傅里叶变换将语音信号转换到频域,实现“频域-频域”的拟合,拟合后的数据作为神经网络的输入(xi),以纯人声作为样本标注(yi);
[0037]
其中在上述步骤三中,当步骤二中的数据拟合完成后,进行模型的选择,选择深度神经网络模型作为训练模型,且深度神经网络模型为u型深度神经网络模型;
[0038]
其中在上述步骤四中,当步骤三中的训练模型选择完毕后,将步骤二中拟合后的数据输入到训练模型中进行不停的迭代训练,u型网络总体上由编码分支e1-e6和解码分支d7-d1构成,编码分支将信号逐渐转换成特征,直到top层形成512维特征向量,解码分支将特征向量逐渐展开形成信号,为了解决从信号到特征信息损失的问题,需要用到损失函数,u型网络每一个隐藏层都会产生一个分支,和每一层的decode层合并,丰富输出的信号细节,且损失函数使用均方差损失函数,其表达式为:
[0039][0040]
其中n为节点数量,为第i个节点的预测值,为第i个节点的标注值;
[0041]
其中在上述步骤五中,由于人耳感知的声音频率和声音的实际频率不是线性的,人耳能轻易区分500hz和1000hz声音,但对2500hz和3000hz很难区分,从而利用经验公式将语音信号的频域变换为mel感知频域,且经验公式为:
[0042][0043]
其中fmel是以梅尔为单位的感知频域,f是以hz为单位的实际语音频率;
[0044]
其中在上述步骤六中,利用mel感知曲线对mse代价函数进行修正,可得到更好的感知精度,即在相同的误差下,mel感知代价函数得到的语音效果要优于mse,mel感知代价函数数学表达式如下:
[0045][0046]
其中为mel曲线确定的误差函数:
[0047][0048]fmax
为该采样率下mel频率的最大值,如8000hz带宽下,f
max
=2481,a为调节系数,这里取a=1.6;
[0049]
其中在上述步骤七中,步骤六中的模型函数语音修正完成后,通过特征注入法,将预先获得的个人声纹特征向量作为通道滤波器注入u型网络中,在u型网络中间增加了一个
分支,变成了三叉戟模样,因此称为trident net,随后通过迁移学习法,将训练好的通用语音滤波器使用特定的个人数据进行“精确调校”,得到个人语音模型,形成单个人模式滤波器,通过模式滤波器对含噪声音进行滤波,就能准确地还原其中的语音信息,同时能够在二人或多人的混合语音中提取特定人的语音,且特征注入法主要训练流程如下:1)训练声纹识别网络,能够提取一段语音的声纹特征,一般使用512维特征向量表示;2)训练数据集中,除了“人声-噪声”随机混合外,还使用一定比例的“人声-人声”混合;3)将混合人声和指定id的声纹同时作为网络输入,将关键人“干净”原声作为标注,使用mse损失函数进行评价。
[0050]
基于上述,本发明的优点在于,采用u型深度神经网络模型结合深度学习算法,通过回归训练的方法,优化深度神经网络中数百万个滤波器参数,有利于得到精准适合人类语音特征分布的滤波器,便于实现良好的“语音-噪声”分离,同时利用mel感知曲线对mse代价函数进行修正,实现了更好的听觉感受,使用trident-net和特征注入法实现个体语音分离,便于在二人或多人的混合语音中提取特定人的语音。
[0051]
对于本领域技术人员而言,显然本发明不限于上述示范性实施例的细节,而且在不背离本发明的精神或基本特征的情况下,能够以其他的具体形式实现本发明。因此,无论从哪一点来看,均应将实施例看作是示范性的,而且是非限制性的,本发明的范围由所附权利要求而不是上述说明限定,因此旨在将落在权利要求的等同要件的含义和范围内的所有变化囊括在本发明内。不应将权利要求中的任何附图标记视为限制所涉及的权利要求。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1