基于韵律发音解耦的元学习多语种语音合成模型及方法
for multilingual text-to-speech,”proc.interspeech 2020,pp.2972
–
2976,2020.
10.[5]m.chen,m.chen,s.liang,j.ma,l.chen,s.wang,and j.xiao,“cross-lingual,multi-speaker text-to-speech synthesis using neural speaker embedding.”in interspeech,2019,pp.2105
–
2109.
[0011]
[6]y.cao,x.wu,s.liu,j.yu,x.li,z.wu,x.liu,and h.meng,“end-to-end code-switched tts with mix of monolingual record-ings,”in icassp 2019-2019ieee international conference on acoustics,speech and signal processing(icassp).ieee,2019,pp.6935
–
6939.
[0012]
[7]r.liu,x.wen,c.lu,and x.chen,“tone learning in low-resource bilingual tts.”in interspeech,2020,pp.2952
–
2956.
[0013]
[8]h.zhan,h.zhang,w.ou,and y.lin,“improve cross-lingual text-to-speech synthesis on monolingual corpora with pitch contour information,”proc.interspeech 2021,pp.1599
–
1603,2021.
[0014]
[9]h.tachibana,k.uenoyama,and s.aihara,“efficiently trainable text-to-speech system based on deep convolutional networks with guided attention,”in 2018ieee international conference on acoustics,speech and signal processing(icassp).ieee,2018,pp.4784
–
4788.
[0015]
[10]j.shen,r.pang,r.j.weiss,m.schuster,n.jaitly,z.yang,z.chen,y.zhang,y.wang,r.skerrv-ryan et al.,“natural tts synthesis by conditioning wavenet on mel spectrogram predictions,”in 2018ieee international conference on acoustics,speech and signal processing(icassp).ieee,2018,pp.4779
–
4783.
技术实现要素:
[0016]
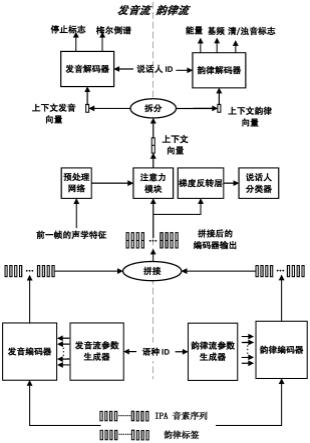
本发明的目的是提供了一种基于韵律发音解耦的元学习多语种语音合成模型及方法,能对发音和韵律分别建模,有效提高多语言语音合成的可懂度和自然度,进而解决现有技术中存在的上述技术问题。
[0017]
本发明的目的是通过以下技术方案实现的:
[0018]
发音流声学子模型、韵律流声学子模型、预处理网络、注意力模块、梯度反转层和说话人分类器;;其中,
[0019]
发音流声学子模型、韵律流声学子模型、预处理网络、注意力模块、梯度反转层和说话人分类器;;其中,
[0020]
所述发音流声学子模型包括:发音流参数生成器、发音编码器和发音解码器;
[0021]
所述发音流参数生成器设有接收语种id的语种id输入端,该发音流参数生成器的发音流参数输出端与所述发音编码器的发音流参数输入端相连;
[0022]
所述发音编码器设有接收ipa音素序列的ipa音素序列输入端和接收韵律标签的韵律标签输入端,该发音编码器的发音编码输出端连接所述注意力模块的拼接输入端;
[0023]
所述韵律流声学子模型包括:韵律流参数生成器、韵律编码器和韵律解码器;
[0024]
所述韵律流参数生成器设有接收语种id的语种id输入端,该韵律流参数生成器的韵律流参数输出端与所述韵律编码器的韵律流参数输入端相连;
[0025]
所述韵律编码器设有接收ipa音素序列的ipa音素序列输入端和接收韵律标签的韵律标签输入端,该韵律编码器的韵律编码输出端连接所述注意力模块的拼接输入端;
[0026]
所述预处理网络的输入端,用于以自回归方式接收前一帧的梅尔倒谱、基频和能量,该预处理网络的输出端连接所述注意力模块;
[0027]
所述注意力模块,能将由所述发音编码器输入的发音编码特征和所述韵律编码器输入的韵律编码特征拼接后,从预处理网络的输出、前一帧的上下文向量和拼接后的编码器输出中预测当前帧的上下文向量,再将当前帧的上下文向量根据所述发音编码器的输出维度和所述韵律编码器的输出维度拆分为上下文发音向量和上下文韵律向量;
[0028]
所述注意力模块分别设有连接所述发音流声学子模型的发音解码器的上下文发音向量输出端和连接所述韵律流声学子模型的韵律解码器的上下文韵律向量输出端,能将拆分得出的上下文发音向量输出至所述发音解码器以及将拆分得出的上下文韵律向量输出至所述韵律解码器;
[0029]
所述梯度反转层的输入端与所述注意力模块的发音韵律编码拼接输出端相连,该梯度反转层的输出端连接所述说话人分类器,该梯度反转层能反转说话人分类器在训练时回传的梯度,通过对抗训练的方式去除所述发音编码器和所述韵律编码器输出中的残余说话人信息;
[0030]
所述说话人分类器模块用于在训练过程中,从所述发音编码器和所述韵律编码器拼接后的输出中预测说话人身份;
[0031]
所述发音解码器设有接收说话人id的说话人id输入端,能根据说话人id映射成的说话人编码和输入的上下文发音向量预测输出梅尔倒谱和停止标志;
[0032]
所述韵律解码器设有接收说话人id的说话人id输入端,能根据说话人id映射成的说话人编码和输入的上下文韵律向量预测输出能量、基频和清浊音标志。
[0033]
一种基于韵律发音解耦的元学习多语种语音合成方法,采用本发明所述的基于韵律发音解耦的元学习多语种语音合成模型,按以下方式对该基于韵律发音解耦的元学习多语种语音合成模型进行训练,包括:
[0034]
以多语种数据集作为训练样本集,按预设的训练批次联合对该基于韵律发音解耦的元学习多语种语音合成模型进行训练,最终训练损失表示为:
[0035]
loss
total
=loss
rec-λloss
spk
;
[0036]
其中,loss
rec
为重建声学特征的损失函数,其中,梅尔倒谱、能量和基频预测采用均方误差损失函数,清音浊音标志和停止标志预测采用二元交叉熵损失函数;loss
spk
为说话人分类器的损失函数;λ设置为0.05;
[0037]
训练过程的每一个训练批次中,b为批次大小,l为训练所用语种数量,b是l的整数倍,在训练批次b中,对于任意的j<l且i<b/l,则b中第j+il个样本是相同的语种;
[0038]
预设的超参数中,ipa音素嵌入的维度和韵律标签嵌入的维度分别为512和16;
[0039]
所述韵律流声学子模型设置一半的初始学习率;
[0040]
所述发音流声学子模型、注意力模块和预处理网络的初始学习率均设置为10-3
,采用adam优化器,学习速率为每15000步衰减一半;
[0041]
待所述基于韵律发音解耦的元学习多语种语音合成模型训练完成后,用训练完成后的基于韵律发音解耦的元学习多语种语音合成模型对输入的多语种文本进行对应的语
音合成,得出对应的语音音频。
[0042]
与现有技术相比,本发明所提供的基于韵律发音解耦的元学习多语种语音合成模型及方法,其有益效果包括:
[0043]
由于利用不同的声学特征来表示这两种类型的信息。通过分开设置的发音流声学子模型与韵律流声学子模型这种双流的编码器解码器组来同时分别学习语言的发音和韵律特征,解决了传统多语种语音合成模型使用梅尔频谱作为输出,梅尔频谱中混合了所有发音相关和韵律相关的信息,模型难以从中学习到不同语种之间差异化的发音和韵律表现的问题;本发明对于不同的语言能在共享语种间发音知识的情况下,能学习到每种语言独特的韵律风格,相比直接从字符序列或音素中预测梅尔谱的方法,可以提高多语种合成语音自然度和可懂度。
附图说明
[0044]
为了更清楚地说明本发明实施例的技术方案,下面将对实施例描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域的普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他附图。
[0045]
图1为本发明实施例提供的基于韵律发音解耦的元学习多语种语音合成模型的构成示意图。
具体实施方式
[0046]
下面结合本发明的具体内容,对本发明实施例中的技术方案进行清楚、完整地描述;显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例,这并不构成对本发明的限制。基于本发明的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明的保护范围。
[0047]
首先对本文中可能使用的术语进行如下说明:
[0048]
术语“和/或”是表示两者任一或两者同时均可实现,例如,x和/或y表示既包括“x”或“y”的情况也包括“x和y”的三种情况。
[0049]
术语“包括”、“包含”、“含有”、“具有”或其它类似语义的描述,应被解释为非排它性的包括。例如:包括某技术特征要素(如原料、组分、成分、载体、剂型、材料、尺寸、零件、部件、机构、装置、步骤、工序、方法、反应条件、加工条件、参数、算法、信号、数据、产品或制品等),应被解释为不仅包括明确列出的某技术特征要素,还可以包括未明确列出的本领域公知的其它技术特征要素。
[0050]
术语“由
……
组成”表示排除任何未明确列出的技术特征要素。若将该术语用于权利要求中,则该术语将使权利要求成为封闭式,使其不包含除明确列出的技术特征要素以外的技术特征要素,但与其相关的常规杂质除外。如果该术语只是出现在权利要求的某子句中,那么其仅限定在该子句中明确列出的要素,其他子句中所记载的要素并不被排除在整体权利要求之外。
[0051]
除另有明确的规定或限定外,术语“安装”、“相连”、“连接”、“固定”等术语应做广义理解,例如:可以是固定连接,也可以是可拆卸连接,或一体地连接;可以是机械连接,也
可以是电连接;可以是直接相连,也可以通过中间媒介间接相连,可以是两个元件内部的连通。对于本领域的普通技术人员而言,可以根据具体情况理解上述术语在本文中的具体含义。
[0052]
术语“中心”、“纵向”、“横向”、“长度”、“宽度”、“厚度”、“上”、“下”、“前”、“后”、“左”、“右”、“竖直”、“水平”、“顶”、“底”“内”、“外”、“顺时针”、“逆时针”等指示的方位或位置关系为基于附图所示的方位或位置关系,仅是为了便于描述和简化描述,而不是明示或暗示所指的装置或元件必须具有特定的方位、以特定的方位构造和操作,因此不能理解为对本文的限制。
[0053]
下面对本发明所提供的基于韵律发音解耦的元学习多语种语音合成模型及方法进行详细描述。本发明实施例中未作详细描述的内容属于本领域专业技术人员公知的现有技术。本发明实施例中未注明具体条件者,按照本领域常规条件或制造商建议的条件进行。本发明实施例中所用试剂或仪器未注明生产厂商者,均为可以通过市售购买获得的常规产品。
[0054]
如图1所示,本发明实施例提供一种基于韵律发音解耦的元学习多语种语音合成模型,包括:
[0055]
发音流声学子模型、韵律流声学子模型、预处理网络、注意力模块、梯度反转层和说话人分类器;;其中,
[0056]
所述发音流声学子模型包括:发音流参数生成器、发音编码器和发音解码器;
[0057]
所述发音流参数生成器设有接收语种id的语种id输入端,该发音流参数生成器的发音流参数输出端与所述发音编码器的发音流参数输入端相连;
[0058]
所述发音编码器设有接收ipa音素序列的ipa音素序列输入端和接收韵律标签的韵律标签输入端,该发音编码器的发音编码输出端连接所述注意力模块的拼接输入端;
[0059]
所述韵律流声学子模型包括:韵律流参数生成器、韵律编码器和韵律解码器;
[0060]
所述韵律流参数生成器设有接收语种id的语种id输入端,该韵律流参数生成器的韵律流参数输出端与所述韵律编码器的韵律流参数输入端相连;
[0061]
所述韵律编码器设有接收ipa音素序列的ipa音素序列输入端和接收韵律标签的韵律标签输入端,该韵律编码器的韵律编码输出端连接所述注意力模块的拼接输入端;
[0062]
所述预处理网络的输入端,用于以自回归方式接收前一帧的梅尔倒谱、基频和能量,该预处理网络的输出端连接所述注意力模块;在训练过程中预处理网络接收真实语音的前一帧的梅尔倒谱、基频和能量,在合成过程中使用发音解码器和韵律解码器这两个解码器输出的前一帧的梅尔倒谱、基频和能量作为预处理网络的输入;
[0063]
所述注意力模块,能将由所述发音编码器输入的发音编码特征和所述韵律编码器输入的韵律编码特征拼接后,从预处理网络的输出、前一帧的上下文向量和拼接后的编码器输出中预测当前帧的上下文向量,再将当前帧的上下文向量根据发音编码器的输出维度和韵律编码器的输出维度拆分为上下文发音向量和上下文韵律向量;其中,发音编码器的输出维度用da表示,韵律编码器的输出维度用d
p
表示;
[0064]
所述注意力模块分别设有连接所述发音流声学子模型的发音解码器的上下文发音向量输出端和连接所述韵律流声学子模型的韵律解码器的上下文韵律向量输出端,能将上下文向量拆分为上下文发音向量与上下文韵律向量后,将上下文发音向量输出至所述发
音解码器以及将上下文韵律向量输出至所述韵律解码器;
[0065]
所述梯度反转层的输入端与所述注意力模块的发音韵律编码拼接输出端相连,该梯度反转层的输出端连接所述说话人分类器,该梯度反转层能反转说话人分类器在训练时回传的梯度,通过对抗训练的方式去除所述发音编码器和所述韵律编码器输出中的残余说话人信息;
[0066]
所述说话人分类器模块用于在训练过程中,从所述发音编码器和所述韵律编码器拼接后的输出中预测说话人身份;
[0067]
所述发音解码器设有接收说话人id的说话人id输入端,能根据说话人id映射成的说话人编码和输入的上下文发音向量预测输出梅尔倒谱和停止标志;
[0068]
所述韵律解码器设有接收说话人id的说话人id输入端,能根据说话人id映射成的说话人编码和输入的上下文韵律向量预测输出能量、基频和清浊音标志。
[0069]
上述模型中,所述发音流声学子模型的发音编码器采用dc-tts编码器,包括:两个一维卷积层和十二个高速1d-conv层,该发音编码器设有256个隐藏单元;
[0070]
所述韵律流声学子模型的韵律编码器采用dc-tts编码器,包括:两个一维卷积层和十二个高速1d-conv层,该韵律编码器设有128个隐藏单元。
[0071]
上述模型中,所述发音流声学子模型的发音解码器采用基于长短期记忆网络的解码器,该发音解码器的隐藏单元大小为1024;
[0072]
所述韵律流声学子模型的韵律解码器采用基于长短期记忆网络的解码器,该韵律解码器的隐藏单元大小为256。
[0073]
上述模型中,所述发音解码器包括:
[0074]
第一查找表模块、第一长短期记忆网络、第一线性层和第一具有sigmoid激活层的线性层;其中,
[0075]
所述第一查找表模块与所述长短期记忆网络相连,能将输入的说话人id映射成说话人编码输出给所述长短期记忆网络;
[0076]
所述第一长短期记忆网络的输入连接所述注意力模块的上下文发音向量输出端,该第一长短期记忆网络能从上下文发音向量和说话人编码中预测当前帧的解码发音特征,分别输出至第一线性层和第一具有sigmoid激活层的线性层;
[0077]
所述第一线性层能对输入的当前帧的解码发音特征变换投影预测当前帧的梅尔倒谱向量;
[0078]
所述第一具有sigmoid激活层的线性层,能将输入的当前帧的解码发音特征投影到标量中,预测停止标志。
[0079]
上述模型中,所述韵律解码器包括:
[0080]
第二查找表模块、第二长短期记忆网络、两个单独的第二线性层和第二具有sigmoid激活层的线性层;其中,
[0081]
所述第二查找表模块与所述第二长短期记忆网络连接,能将输入的说话人id映射成说话人编码输出给所述第二长短期记忆网络;
[0082]
所述第二长短期记忆网络的输入连接所述注意力模块的上下文韵律向量输出端,该第二长短期记忆网络能从上下文韵律向量和说话人编码中预测当前帧的解码韵律特征,分别输出至两个单独的线性层和具有sigmoid激活层的线性层;
[0083]
两个单独的第二线性层能对输入的当前帧的解码韵律特征变换投影,分别预测当前帧的能量和基频;
[0084]
第二具有sigmoid激活层的线性层,能将输入的当前帧的解码韵律特征投影到标量中,预测当前帧的清音浊音标志。
[0085]
上述模型中,所述发音解码器对梅尔倒谱的预测采用均方误差损失函数,该发音解码器对停止标志的预测采用二元交叉熵损失函数;
[0086]
所述韵律解码器对能量和基频的预测采用均方误差损失函数,该韵律解码器对清音浊音标志的预测采用二元交叉熵损失函数。
[0087]
本发明实施例还提供一种基于韵律发音解耦的元学习多语种语音合成方法,采用上述的基于韵律发音解耦的元学习多语种语音合成模型,按以下方式对该基于韵律发音解耦的元学习多语种语音合成模型进行训练,包括:
[0088]
以多语种数据集作为训练样本集,按预设的训练批次联合对该基于韵律发音解耦的元学习多语种语音合成模型进行训练,最终训练损失表示为:
[0089]
loss
total
=loss
rec-λloss
spk
;
[0090]
其中,loss
rec
为重建声学特征的损失函数,其中,梅尔倒谱、能量和基频预测采用均方误差损失函数,清音浊音标志和停止标志预测采用二元交叉熵损失函数;loss
spk
为说话人分类器的损失函数;λ设置为0.05;
[0091]
训练过程的每一个训练批次中,b为批次大小,l为训练所用语种数量,b是l的整数倍,在训练批次b中,对于任意的j<l且i<b/l,则b中第j+il个样本是相同的语种;
[0092]
预设的超参数中,ipa音素嵌入的维度和韵律标签嵌入的维度分别为512和16。
[0093]
所述韵律流声学子模型设置一半的初始学习率;
[0094]
所述发音流声学子模型、注意力模块和预处理网络的初始学习率均设置为10-3
,采用adam优化器,学习速率为每15000步衰减一半;
[0095]
待所述基于韵律发音解耦的元学习多语种语音合成模型训练完成后,用训练完成后的基于韵律发音解耦的元学习多语种语音合成模型对输入的多语种文本进行对应的语音合成,得出对应的语音音频。
[0096]
上述方法中,所述多语种数据集中包括:与语种语言文本对应的ipa音素序列,ipa音素序列的每个单词边界处插入空格符作为标记,每个ipa音素分配一个描述音素的音调或重音特征的韵律标签;
[0097]
所述韵律标签是一个具有m+n维的one-hot向量,其中,m对应于声调语言的声调数,n对应于非声调语言的重音类别数。
[0098]
综上可见,本发明实施例的系统及方法,相比传统多语种语音合成模型使用梅尔频谱作为输出,梅尔频谱中混合了所有发音相关和韵律相关的信息,模型难以从中学习到不同语种之间差异化的发音和韵律表现。在本发明中,利用不同的声学特征来表示这两种类型的信息。通过双流的编码器解码器组来同时分别学习语言的发音和韵律特征。本发明对于不同的语言能在共享语种间发音知识的情况下,学习到每种语言独特的韵律风格。相比直接从字符序列或音素中预测梅尔谱的方法,本发明可以提高多语种合成语音自然度和可懂度。
[0099]
为了更加清晰地展现出本发明所提供的技术方案及所产生的技术效果,下面以具
体实施例对本发明实施例所提供的基于韵律发音解耦的元学习多语种语音合成模型及方法,进行详细描述。
[0100]
实施例1
[0101]
如图1所示,本发明实施例提供一种基于韵律发音解耦的元学习多语种语音合成模型,通过构建的一个双流的声学模型来解耦语言的韵律和发音,发音流声学子模型和韵律流声学子模型各自包含一组编码器-解码器来分别用于发音建模和韵律建模,为了在语种间知识共享的同时保留语种独特的发音和韵律特点,编码器包含一个基于元学习的参数生成器,发音流和韵律流的输入为国际音标(international phonetic alphabet,ipa)序列;发音流和韵律流的预测目标分别是谱特征(梅尔倒谱)和激励特征(能量、基频和浊音/清音标志);利用共享的注意力模块,保证两个流在合成过程中的同步输出,这样能提高多语种语音合成的可懂度和自然度。
[0102]
如图1,本发明的基于韵律发音解耦的元学习多语种语音合成模型的架构遵循基于注意力的序列到序列(seq2seq)框架进行声学建模,并采用tacotron2作为基础。它包含一个发音流和一个韵律流,这两个流分别包含单独的编码器,以语种为条件的参数生成器,以及用于预测不同声学特征的解码器,通过共享一个注意力模块来保持两个流之间的同步。每个编码器参考dctts[参见参考文献9]包括两个一维卷积(1d-conv)层和十二个高速1d-conv层。并且每个编码器都依赖于以语种id作为输入的参数生成器来获得其网络的权重和偏差。发音编码器和韵律编码器的输出可以表示为和其中da和d
p
是发音编码器的输出维度与韵律编码器的输出维度,l是音素序列长度。然后将xa和x
p
按维度拼接起来得到用于注意力模块对齐。
[0103]
前一帧的梅尔倒谱、基频和能量会以自回归的方式被传递到预处理网络,然后利用一个长短期记忆(lstm)层从预处理网络的输出和前一帧的上下文向量中获取帧级上下文向量,之后将上下文向量根据da和d
p
维度进一步拆分为两部分,分别送入两个流的解码器。
[0104]
每个解码器都包含一个查找表用以将说话人id映射成话者编码。在韵律解码器中,说话人编码与上下文向量连接作为基于lstm的解码器的输入。lstm输出通过两个单独的线性变换投影,分别预测能量和基频。同时,输出也通过具有sigmoid激活层的线性层投影到标量中,以预测清音/浊音标志。在发音解码器中也使用相同的结构来分别预测梅尔倒谱向量和停止标志。
[0105]
本发明还将具有梯度反转层的对抗性说话人分类器应用于编码器输出。它遵循域对抗训练的原理来去除编码器输出中的残余说话人信息。
[0106]
为了验证本发明的系统及方法的有效性,设计了如下实验。
[0107]
(1)实验设置
[0108]
本发明的实验使用了多语言单说话人数据集css10的子集,并从多语言多说话人数据集common voice中选择清晰的说话人来增强css10。原始css10数据集中有10种语言,在本实施例的实验中使用了其中的5种语言,包括:普通话(zh)、德语(de)、法语(fr)、荷兰语(nl)和俄语(ru)。通过将最大和最小句子持续时间设置为10秒和1秒来删除数据集中过长和过短的句子。表1显示了用于实验的数据量。每种语言的数据以8:1:1的比例分成训练
集、开发集和测试集。音频均以22.05khz采样。将韵律发音解耦的声学模型与下面列出的三个模型进行了比较。
[0109]
(1)tacotron2:该模型遵循原始的tacotron2架构,参见参考文献[10]。为了与多语言语音合成兼容,它有一个完全共享的编码器,其中字符和语种id作为输入。添加了一个对抗性说话人分类器以去除编码器输出中包含的说话人信息,并将说话人嵌入连接到解码器层的长短时记忆网络输入。为了公平比较它的超参数与本发明的模型中的一致。
[0110]
(2)meta-char:该模型是按照基于基线元学习的多语言tts方法构建的,参见参考文献[4]。为了公平比较,输出声学特征与本发明的模型中的相同。
[0111]
(3)meta-ipa:这个模型和meta-char结构相同,唯一的区别是将数据集的文本转录为音素(ipa)序列和韵律标签被用作模型输入。meta-ipa与本发明的模型之间的区别在于本发明的模型中采用了韵律发音解耦的双流建模方法。
[0112]
使用客观指标和主观测听来评价本发明。对于客观实验,比较了合成的音频特征与真实特征的相似性。关于效果的客观指标包括:基频的相关性系数(记为f0-corr)、基频的均方根误差(记为f0-rmse)、能量的均方根误差(记为en-rmse)、清浊判决(记为清音/浊音-err)以及梅尔倒谱距离(记为mcd)。此外,通过将合成话语发送到谷歌云平台的语音识别引擎来评估合成话语的可理解性。以语音识别的字符错误率(cer)作为一种评价指标。
[0113]
对于主观评测,进行了语言自然度的平均意见分(mos)测听实验。评分范围从1(完全不自然)到5(完全自然)。其中对于普通话、俄语和荷兰语,线下分别招募了11、7和8名母语评分者。对于德语和法语,测试是通过众包的形式在公共众包平台amazon mechanical turk上进行的,分别有14和10名母语评分者。他们被要求对不同模型的合成语音进行打分其中每种语言各有20句。
[0114]
表1:实验中使用的训练数据
[0115][0116][0117]
(2)实验结果
[0118]
从表2中,可以看到两个基于元学习的基线比tacotron2表现更好,并且meta-ipa优于meta-char。本发明的合成模型在所有语言的所有相似性指标上都取得了最佳性能,除了在俄语的mcd指标和荷兰语的en-rmse指标meta-ipa略微优于本发明的合成模型。这些结果证明了本发明基于元学习的声学模型的有效性,组合ipa音素和韵律标签作为模型输入策略的可行,以及本发明的双流模型结构在提高声学特征预测准确性方面的作用。
[0119]
同时,在识别错误率的对比中,可以看到tacotron2的cer最高。meta-ipa比meta-char表现更好,本发明的合成模型在所有五种语言中实现了最低的cer。这表明,除了元学习和使用ipa之外,所提出的解耦发音和韵律建模方法也有利于合成语音的准确发音。
[0120]
在表3中,可以看到主观评价结果与客观评价结果是一致的。tacotron2模型的自然度得分最低,而meta-ipa的表现优于meta-char。本发明的合成模型在所有五种语言的四种模型中实现了最高的自然度。根据置信区间,除了本发明和meta-ipa之间在荷兰语的表现之外,本发明和基线模型之间的mos差异都是显着的。这证实了本发明的方法在提高多语
言语音合成的自然度方面的有效性。
[0121]
为了进一步对比多语种联合训练(记为多语建模)相比单语种分别训练的优势,在汉语、德语和法语上以双流模型结构为基础训练了单语种的模型(记为单语建模)。表4中可以看到,多语种混合训练比起单语种训练,在语音的可懂度和自然度上都有提升,尤其是当语种数据量不足时,多语种联合训练对改善低资源语言效果显着。
[0122]
表2:客观实验结果
[0123]
[0124][0125]
表3:不同模型在五个目标语种上的自然度mos,置信区间为95%,其中gt为真实语音(表中的新方法指本发明合成模型的合成方法)
[0126]
[0127][0128]
表3:单语建模和多语种建模结果对比
[0129][0130]
实施例2
[0131]
本发明实施例提供一种基于韵律发音解耦的元学习多语种语音合成模型,包括:
[0132]
(1)该模型输入与输出表征提取为:
[0133]
首先将所有语音的文本转录使用开源工具phonemizer转换为ipa音素序列。为了引入韵律描述,在音素序列的每个单词边界处插入一个特定的标记。此外,为每个音素分配一个韵律标签来描述音素的音调或重音特征。韵律标签是一个具有m+n维的one-hot向量,其中m对应于声调语言的声调数,n对应于非声调语言的重音类别数。本发明的实验在五种语言上进行,最终得到音素集合大小为173。对于韵律标签,根据普通话的五个声调,有m=5,根据非声调语言的重音类别,有n=3。在这里,重音类别包括主要重读元音、次要重读元音和非重读音素。
[0134]
本发明使用straight声码器从音频中提取实验所需的声学特征,其中包括40维梅尔倒谱、能量、基频和每帧的清音/浊音标志。声学特征的帧长为25ms,帧移位为10ms。这些总共43维的特征被用作模型的训练目标。
[0135]
(2)该合成模型按以下方式训练:
[0136]
所有模型参数都在多语种联合训练的情况下同时优化。训练损失由两部分组成。一部分是重建声学特征的损失(loss
rec
)。其中梅尔倒谱、能量和基频预测采用均方误差(mse)损失函数,清音/浊音标志和停止标志预测采用二元交叉熵(bce)损失函数。另一部分是说话人分类器损失(loss
spk
)。最终训练损失可以表示为:
[0137]
loss
total
=loss
rec-λloss
spk
(其中λ在实验中设置为0.05)
[0138]
为了保持每个训练批次的语言平衡,对于每一个训练批次b,当语种数量为l时对于每个l《l和i《b/l都有批次内第(l+il)个样本是相同的语种。ipa音素嵌入和韵律标签嵌入的维度分别为512和16。编码器的部分参考dctts的全一维卷积网络,参见参考文献[9],其中发音编码器模型有256个隐藏单元,而韵律编码器模型只有128个隐藏单元。发音解码器和韵律解码器的隐藏大小分别为1024和256。在韵律流中,我们使用一半的初始学习率来减少过拟合。剩余模型参数的学习率初始化为10-3
,采用adam优化器,学习速率每15000步衰减一半。此外,由于输出特征的深度足够低,我们没有使用tacotron2模型的postnet模块。
[0139]
以上所述,仅为本发明较佳的具体实施方式,但本发明的保护范围并不局限于此,
任何熟悉本技术领域的技术人员在本发明披露的技术范围内,可轻易想到的变化或替换,都应涵盖在本发明的保护范围之内。因此,本发明的保护范围应该以权利要求书的保护范围为准。本文
背景技术:
部分公开的信息仅仅旨在加深对本发明的总体背景技术的理解,而不应当被视为承认或以任何形式暗示该信息构成已为本领域技术人员所公知的现有技术。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1