一种基于声音识别的多模式语音交互方法及系统与流程
本发明涉及语音交互,尤其涉及一种基于声音识别的多模式语音交互方法及系统。
背景技术:
1、随着车联网和人工智能技术的兴起,越来越多的功能被搭载在车机上,当前汽车座舱智能化发展趋势下,语音交互功能已成为智能座舱内最具代表性的智能化功能,语音交互也已成为车内最为重要的交互方式,语音交互是车内最直接、最人性化、最安全的交互方式,同时随着ai和硬件性能的增强,智能语音交互会逐渐由单模交互方式向与其他交互方式相结合的多模交互方式发展。
2、现有技术中,汽车座舱内人机交互时语音i p形象的展示方式大多为通过节日来提供不同的语音形象、或者用户自己手动去切换语音i p皮肤包,这些都是基于固定的统计结果或者用户自发行为,只能迎合用户主动交互的一些喜好,语音端没有主动去识别用户需求,无法满足用户个性化与场景化的需求。
技术实现思路
1、为此,本发明提供一种基于声音识别的多模式语音交互方法及系统,用以克服现有技术中由于人机交互时无法根据用户声音特征变换语音模式导致的人机交互效率低、用户体验度低的问题。
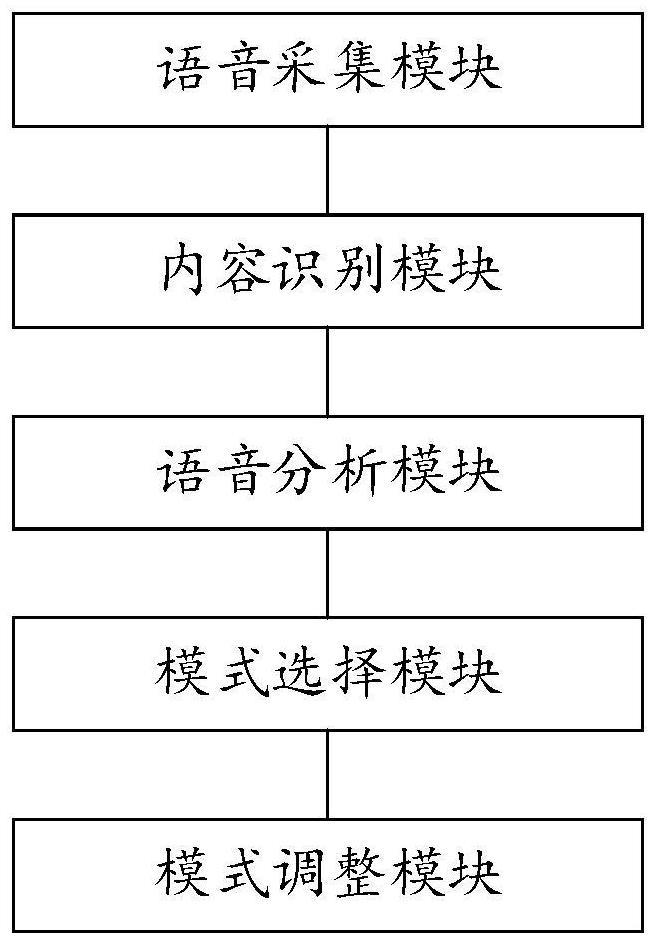
2、为实现上述目的,一方面,本发明提供一种基于声音识别的多模式语音交互系统,包括:
3、语音采集模块,用以实时采集车内用户的语音信息;
4、内容识别模块,用以识别实时采集的语音信息中的文字内容;
5、语音分析模块,用以对实时采集的语音信息进行声音特征分析,识别确认该语音信息是否为驾驶员发出,并对驾驶员的语音信息的文字内容、语速和语调进行分析,并根据分析结果判断驾驶员的驾驶状态;
6、模式选择模块,用以根据驾驶员的驾驶状态选取对应的交互模式进行语音交互;
7、模式调整模块,用以根据驾驶员的交互反馈信息对交互模式进行实时调整。
8、进一步地,所述语音分析模块包括:
9、声纹分析单元,用以对实时采集的语音信息中的声纹进行分析,以判断该语音信息是否为驾驶员的语音信息;
10、文字分析单元,用以对驾驶员的语音信息进行文字提取,以获取语音信息中的状态关键字;
11、语速分析单元,用以根据驾驶员的语音信息中的文字数量和语音时长对驾驶员进行语速分析;
12、语调分析单元,用以根据驾驶员的语音信息中的声波频率对驾驶员进行语调分析;
13、状态判断单元,用以根据获取的状态关键字数量、驾驶员的语速和驾驶员的语调对驾驶员的驾驶状态进行判断和校正。
14、进一步地,所述声纹分析单元在对实时采集的语音信息进行声纹分析时,将实时采集的语音信息的声纹与已存储的若干驾驶员的声纹信息进行匹配,并根据匹配结果进行声纹分析,其中,
15、当实时采集的语音信息的声纹与已存储的若干驾驶员的声纹信息匹配到相同声纹时,判断该语音信息为驾驶员发出的语音信息;
16、当实时采集的语音信息的声纹与已存储的若干驾驶员的声纹信息未匹配到相同声纹时,判断该语音信息非驾驶员发出的语音信息。
17、进一步地,所述文字分析单元设有若干预设状态关键字,所述文字分析单元获取驾驶员语音信息的文字内容,并将若干预设状态关键字分别与驾驶员语音信息的文字内容进行匹配,所述状态判断单元根据匹配结果对驾驶员的驾驶状态进行判断,其中,
18、当匹配到相同状态关键字时,所述状态判断单元根据该状态关键字的状态类别对驾驶员的驾驶状态进行判断;
19、当未匹配到相同状态关键字时,所述状态判断单元判定驾驶员的驾驶状态为正常状态。
20、进一步地,状态关键字的状态类别包括愤怒、悲哀和恐惧,当匹配到单一相同状态关键字时,所述状态判断单元将该状态关键字的状态类别作为驾驶员的驾驶状态;
21、当匹配到若干相同状态关键字时,若各状态关键字的状态类别相同,所述状态判断单元将该状态类别作为驾驶员的驾驶状态;若各状态关键字的状态类别不同,所述状态判断单元将包含状态关键字最多的状态类别作为驾驶员的驾驶状态。
22、进一步地,所述语速分析单元获取驾驶员的语音信息中的文字数量m和语音时长h,并计算驾驶员的语速v,设定v=m/h,所述语速分析单元将计算得到的驾驶员的语速v与各预设标准语速进行比对,并根据比对结果对驾驶员的语速进行判断;
23、所述状态判断单元根据驾驶员的语速判断结果对驾驶员的驾驶状态进行校正,当判定驾驶员的语速慢时,若驾驶员为愤怒状态,则获取该状态类别的状态关键字数量pa,并将其与预设愤怒关键字数量pa0进行比对,若pa<pa0,则将驾驶员的驾驶状态校正为正常;当判定驾驶员的语速快时,若驾驶员为悲哀状态,则获取该状态类别的状态关键字数量pb,并将其与预设悲哀关键字数量pb0进行比对,若pb<pb0,则将驾驶员的驾驶状态校正为正常。
24、进一步地,所述语调分析单元获取驾驶员的语音信息中的声波频率f,并将其与各预设标准频率进行比对,并根据比对结果对驾驶员的语调进行判断;
25、所述状态判断单元根据驾驶员的语调判断结果对驾驶员的驾驶状态进行二次校正,当判定驾驶员的语调低时,若驾驶员为愤怒状态,则获取该状态类别的状态关键字数量pa,并将其与预设愤怒关键字数量pa0进行比对,若pa<pa0,则将驾驶员的驾驶状态校正为正常;当判定驾驶员的语调高时,若驾驶员为悲哀状态,则获取该状态类别的状态关键字数量pb,并将其与预设悲哀关键字数量pb0进行比对,若pb<pb0,则将驾驶员的驾驶状态校正为正常。
26、进一步地,所述模式选择模块获取二次校正后的驾驶员的驾驶状态,并根据驾驶状态设置对应的交互模式,其中,
27、当驾驶状态为正常状态时,所述模式选择模块将交互模式设置为普通交互模式,仅在唤醒状态下进行人机交互;
28、当驾驶状态为愤怒或悲哀或恐惧状态时,所述模式选择模块将交互模式设置为主动交互模式,并主动向驾驶员发起会话,且在不同状态下以不同tts发声模式进行语音交互。
29、进一步地,所述模式调整模块设有主动交互周期t,周期结束需重新设置交互模式,所述模式调整模块获取主动交互周期t内驾驶员的驾驶状态变化,并对交互模式进行调整,其中,
30、当主动交互周期t内驾驶员的驾驶状态未发生变化时,所述模式调整模块在主动交互周期结束后继续保持当前交互模式;
31、当主动交互周期t内驾驶员的驾驶状态转变为正常状态时,所述模式调整模块在主动交互周期结束后,将交互模式调整为普通交互模式;
32、当主动交互周期t内驾驶员的驾驶状态发生变化且非正常状态时,所述模式调整模块判定驾驶状态判断失误,并在驾驶状态发生变化时更换适应tts发声模式进行语音交互。
33、另一方面,本发明还提供一种基于声音识别的多模式语音交互方法,包括:
34、步骤s1:实时采集车内用户的语音信息;
35、步骤s2:识别实时采集的语音信息中的文字内容;
36、步骤s3:对实时采集的语音信息进行声音特征分析,识别确认该语音信息是否为驾驶员发出,并对驾驶员的语音信息的文字内容、语速和语调进行分析,并根据分析结果判断驾驶员的驾驶状态;
37、步骤s4:根据驾驶员的驾驶状态选取对应的交互模式进行语音交互;
38、步骤s5:根据驾驶员的交互反馈信息对交互模式进行实时调整。
39、与现有技术相比,本发明的有益效果在于,通过分析驾驶员的驾驶状态向驾驶员提供不同交互模式进行语音交互,以提高驾驶员在不同驾驶场景下的体验度,从而提高人机交互效率,在对驾驶员进行声音识别分析时,通过声纹分析确定驾驶员发出的语音信息,再针对该语音信息进行文字内容分析,通过文字内容分析进行驾驶状态初判断,再通过语速和语调分析对驾驶状态的判断进行两次校正,从而最终确定驾驶员的驾驶状态,以提高驾驶状态判断的准确度,同时,根据驾驶状态选取不同交互模式及不同tts发声模式,以针对驾驶员的不同驾驶状态提供不同模式的交互方式,从而进一步提高驾驶员在不同驾驶场景下的体验度,从而提高人机交互效率,同时,在确定交互模式后,通过根据驾驶员的交互反馈信息对交互模式进行实时调整,以使调整后的交互模式与驾驶员的驾驶状态更加契合,从而进一步提高驾驶员在不同驾驶场景下的体验度,从而提高人机交互效率。
- 还没有人留言评论。精彩留言会获得点赞!