语音激活检测方法、装置、存储介质及电子设备与流程
本公开涉及语音检测技术,具体地,涉及一种语音激活检测方法、装置、存储介质及电子设备。
背景技术:
1、随着智能化、数字化的发展,现在越来越多的产品都会接入语音交互系统,以“语音”作为交互媒介,从而提升交互便捷性。作为语音交互系统载体的硬件设备,其上运行软件的一个重要指标即为功耗,其中减少语音识别、声纹识别、关键词识别等模块对信号的无效响应是降低功耗的重要手段。因此能够检测语音是否存在的技术就成为关键。相关即使中,存在vad(voice activity detector,语音激活检测技术)技术,可以减少大多数云端语音应用的无效处理,可以大大降低网络流量的浪费,并节省成本。
2、目前,不管传统的基于声学人工特征的方法,还是最新的基于大数据训练的模型,判断一小段信号是否存在语音已经很准确,但这些方法往往忽略了语音的语义完整性。通常情况下,由于说话习惯或者话语者思考等因素,一小段表意明确的语音信号,或多或少都会存在停顿或者间隙,而对于较长的语音间隙,vad往往会将其判断为语音结尾,从而导致一句完整语义的语音信号被截断。特别对于语音识别这类输出语义结果的应用而言,被前后截断的语音信号会被翻译错误,可能导致无意义的结果,甚至传递不同或者相反的意图。
技术实现思路
1、本公开的目的是提供一种语音激活检测方法、装置、存储介质及电子设备,以解决相关技术中语音识别过程中语音结尾判定不准确的技术问题。
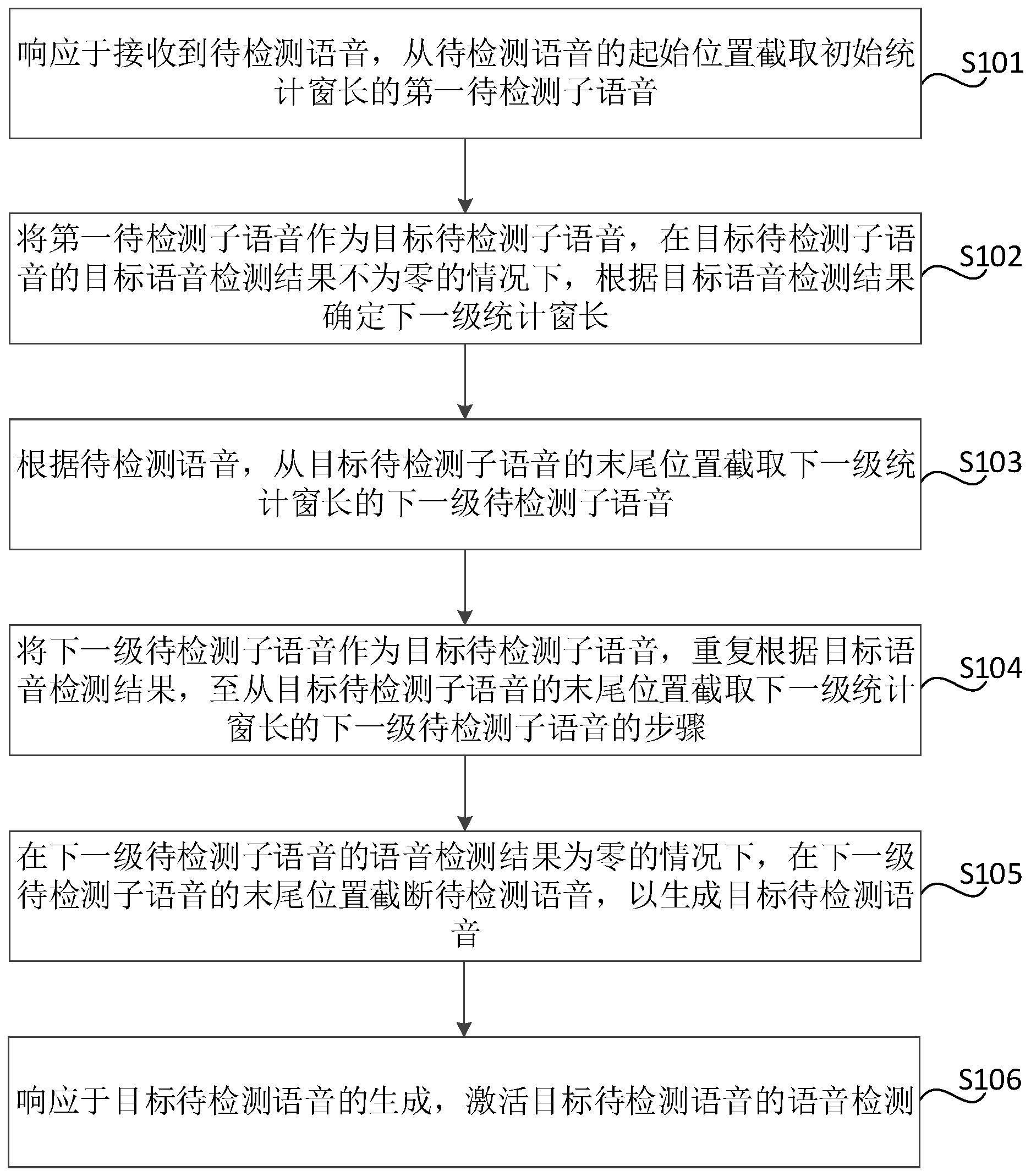
2、为了实现上述目的,本公开的第一方面提供一种语音激活检测方法,包括:
3、响应于接收到待检测语音,从所述待检测语音的起始位置截取初始统计窗长的第一待检测子语音;
4、将所述第一待检测子语音作为目标待检测子语音,在所述目标待检测子语音的目标语音检测结果不为零的情况下,根据所述目标语音检测结果,确定下一级统计窗长;
5、根据所述待检测语音,从所述目标待检测子语音的末尾位置截取所述下一级统计窗长的下一级待检测子语音;
6、在所述下一级待检测子语音的语音检测结果不为零的情况下,将所述下一级待检测子语音作为所述目标待检测子语音,重复所述根据所述目标语音检测结果,至从所述目标待检测子语音的末尾位置截取所述下一级统计窗长的下一级待检测子语音的步骤;
7、在所述下一级待检测子语音的语音检测结果为零的情况下,在所述下一级待检测子语音的末尾位置截断所述待检测语音,以生成目标待检测语音;
8、响应于所述目标待检测语音的生成,激活所述目标待检测语音的语音检测。
9、可选地,所述根据所述目标语音检测结果,确定下一级统计窗长,包括:
10、根据所述待检测语音,对环境中的噪声进行检测,以生成所述环境对应的信噪比;
11、根据所述信噪比,确定所述目标待检测子语音的语音检测阈值;
12、在所述目标语音检测结果大于所述语音检测阈值的情况下,将预设单位调整窗长叠加在所述初始统计窗长上,以生成所述下一级统计窗长;
13、在所述目标语音检测结果小于或等于所述语音检测阈值的情况下,将所述初始统计窗长减所述预设单位调整窗长,以生成所述下一级统计窗长。
14、可选地,所述根据所述信噪比,确定所述目标待检测子语音的语音检测阈值,包括:
15、根据所述信噪比,确定所述待检测语音中每一帧语音对应的语音检测子阈值;
16、根据所述每一帧语音的时长和所述初始统计窗长,确定所述待检测语音中的语音帧数;
17、根据所述语音帧数和所述语音检测子阈值,确定所述语音检测阈值。
18、可选地,所述方法还包括:
19、通过流式推理模型对所述目标检测子语音进行检测,生成所述目标检测子语音的所述目标语音检测结果,其中,所述流式推理模型包括深度神经网络模型、循环神经网络模型、长短期记忆模型或注意力模型。
20、可选地,所述在所述下一级待检测子语音的语音检测结果为零的情况下,在所述下一级待检测子语音的末尾位置截断所述待检测语音,以生成目标待检测语音,包括:
21、在所述下一级待检测子语音的语音检测结果为零的情况下,确定所述下一级待检测子语音的末尾位置为语音结尾;
22、根据所述语音结尾和所述待检测语音,生成所述目标待检测语音。
23、可选地,所述响应于所述目标待检测语音的生成,激活所述目标待检测语音的语音检测,包括:
24、响应于所述目标待检测语音的生成,确定所述目标待检测语音为完整语音;
25、对所述完整语音进行语义检测,以生成所述完整语音对应的语义信息。
26、可选地,所述初始统计窗长对应的时长为500ms。
27、根据本公开的第二方面提供一种语音激活检测装置,所述装置包括:
28、第一截取模块,用于响应于接收到待检测语音,从所述待检测语音的起始位置截取初始统计窗长的第一待检测子语音;
29、确定模块,用于将所述第一待检测子语音作为目标待检测子语音,在所述目标待检测子语音的目标语音检测结果不为零的情况下,根据所述目标语音检测结果,确定下一级统计窗长;
30、第二截取模块,用于根据所述待检测语音,从所述目标待检测子语音的末尾位置截取所述下一级统计窗长的下一级待检测子语音;
31、第三截取模块,用于在所述下一级待检测子语音的语音检测结果不为零的情况下,将所述下一级待检测子语音作为所述目标待检测子语音,重复所述根据所述目标语音检测结果,至从所述目标待检测子语音的末尾位置截取所述下一级统计窗长的下一级待检测子语音的步骤;
32、生成模块,用于在所述下一级待检测子语音的所述下一级语音检测结果为零的情况下,在所述下一级待检测子语音的末尾位置截断所述待检测语音,以生成目标待检测语音;
33、执行模块,用于响应于所述目标待检测语音的生成,激活所述目标待检测语音的语音检测。
34、根据本公开的第三方面提供一种计算机可读存储介质,其上存储有计算机程序,所述程序被处理器执行时实现权利要求1-7中任一项所述方法的步骤。
35、根据本公开的第四方面提供一种电子设备,包括:
36、存储器,其上存储有计算机程序;
37、处理器,用于执行所述存储器中的所述计算机程序,以实现权利要求1-7中任一项所述方法的步骤。
38、通过上述技术方案,响应于接收到待检测语音,从待检测语音的起始位置截取初始统计窗长的第一待检测子语音,将第一待检测子语音作为目标待检测子语音,在目标待检测子语音的目标语音检测结果不为零的情况下,根据目标语音检测结果,确定下一级统计窗长,根据待检测语音,从目标待检测子语音的末尾位置截取下一级统计窗长的下一级待检测子语音,在下一级待检测子语音的语音检测结果不为零的情况下,将下一级待检测子语音作为目标待检测子语音,重复根据目标语音检测结果,至从目标待检测子语音的末尾位置截取下一级统计窗长的下一级待检测子语音的步骤,在下一级待检测子语音的语音检测结果为零的情况下,在下一级待检测子语音的末尾位置截断待检测语音,以生成目标待检测语音,响应于目标待检测语音的生成,激活目标待检测语音的语音检测。从而通过动态变化的统计窗长,准确确定出语音中的语音结尾,在语音结尾的位置截断语音,并激活对该截断后语音的语音检测,使语音检测更准确,提高用户的产品体验。
39、本公开的其他特征和优点将在随后的具体实施方式部分予以详细说明。
- 还没有人留言评论。精彩留言会获得点赞!