基于深度学习的语音提示作弊行为检测方法及电子设备与流程
本发明属于驾驶考试检测,具体涉及一种基于深度学习的语音提示作弊行为检测方法及电子设备。
背景技术:
1、随着驾考领域的不断发展,对于规范考试纪律越来越至关重要。在驾考考试过程中,检测安全员在车内是否存在通过语音形式提示考生的行为。若安全员存在咳嗽、敲击车体、说话的任意一种语音提示行为,则将被判定为安全员疑似作弊,并将疑似作弊数据推荐给管理人员进行复核。管理人员的复核工作只需要针对性的关注疑似作弊部分的语音片段,以及结合该语音片段对应的视频中的动作。
2、检测安全员是否在考试中存在语音提示行为是驾驶考试规范的重要一部分,它是保证驾驶考试公平公正的关键,能在一定程度上规范驾考纪律,减少作弊行为的发生。目前驾考中的语音提示作弊行为的发现主要依赖于后台管理人员的人工听和看,他们需要对所有考试的全程数据进行审核,存在耗时、效率低下等亟需改进的地方。
技术实现思路
1、为解决上述问题,本发明提供一种基于深度学习的语音提示作弊行为检测方法及电子设备,将语音识别与深度学习算法相结合得到,可适用于驾考考试中辅助判断安全员是否存在作弊行为。进一步,还可以将有疑似作弊行为的目标数据推荐给管理人员复核,最终确定是否确实存在作弊行为。
2、本发明第一方面公开一种基于深度学习的语音提示作弊行为检测方法,主要包括以下步骤:
3、步骤1:对获取的车内视频数据进行滑动切片得到若干子视频,提取切所述子视频中的音频部分,经格式转换后,输出若干具有相同时间维度和统一格式的音频数据;
4、步骤2:对所述音频数据分别进行预处理以生成对应的时域信号,再通过短时傅里叶变换将所述时域信号转换为具有振幅和频率信息的语谱图,最后使用梅尔滤波器组对各语谱图进行滤波,生成对应的梅尔频谱;
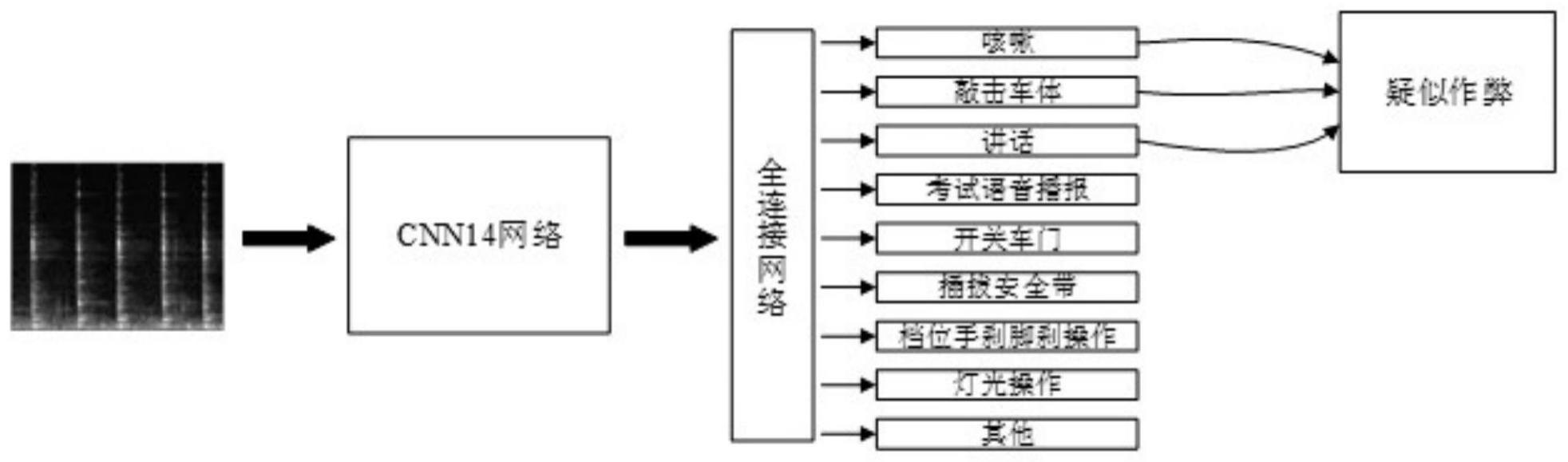
5、步骤3:将所述梅尔频谱输入至训练后的目标深度神经网络模型,所述深度神经网络模型包括特征提取网络模块和多标签分类器网络模块,所述梅尔频谱经特征提取网格模块输出音频数据的一维特征向量,并将所述一维特征向量输入到多标签分类器网络模块中,输出所述音频数据中包含的声音类别;若所述声音类别包含疑似作弊行为的语音提示类别,则初步判定为疑似作弊。
6、作为一种可选方案,所述步骤1具体包括:
7、步骤1.1:通过固定在车内的摄像机获取车内视频数据,将所述视频数据统一转换为mp4格式;
8、步骤1.2:以定长为t的时间窗口对所述视频数据进行滑动切片,获得多个等时长的子视频;
9、步骤1.3:提取所述子视频中的pcm格式音频流,获得等时长的音频数据,再将所述pcm格式音频流转换为wav格式;
10、步骤1.4:对时长不足t的音频数据进行尾部padding填充操作,以保证输出的音频数据具有相同的时间维度。
11、作为一种可选方案,所述步骤2中,预处理是指采用预加重、分帧和加窗技术对所述音频数据中的语音信号进行操作,生成对应的时域信号;所述预加重用于补偿对所述音频数据中高频部分的衰减;所述分帧用于获取语音信号的短时平稳性;所述加窗是将分帧后的语音信号与窗函数相乘,使语音信号呈现出周期函数的部分特征。
12、作为一种可选方案,所述预加重采用的是一阶高通滤波器;所述分帧采用交叠分段方法;所述窗函数选用汉明窗。
13、作为一种可选方案,所述步骤3中,特征提取网络模块采用cnn14网络架构;所述cnn14网络架构的主干网络由6个cnn block块组成,每个cnn block块内部结构为2*(conv+bn+relu)+avg pooling网络层,每个cnn block块后连接dropout层,网络末端通过结合maxpooling和avg pooling两种池化方式以及全连接层的flatten操作,输出特征融合后的一维特征向量;
14、所述多标签分类器网络模块包含一层神经元结构的全连接网络层和n个二元子分类器,所述全连接网络层的输入端与特征提取网络模块的输出特征进行连接,输出端与二元子分类器连接,将所述音频数据的一维特征向量转换为n个输出分支;每个输出分支对应一种声音类别;
15、所述二元子分类器将输出分支中的神经元输出值分别输入到sigmoid函数中,得到每个声音类别的概率值,所述概率值范围为(0,1],通过所述概率值来表示每个输出类别的置信度,若所述置信度大于预设阈值则输出对应的声音类别,否则不输出。
16、作为一种可选方案,所述深度神经网络模型的训练过程包括:
17、将训练数据及其对应的训练标签输入至初始构建的深度神经网络模型,通过反向传播的方式对深度神经网络模型进行迭代更新,在总损失值趋于收敛时,训练结束;
18、所述深度神经网络模型的总损失函数由n个二元子分类器损失组成,每个二元子分类器的损失值losscls表示为:
19、
20、总损失值loss为所有子分类器的损失值losscls的平均值,表示为:
21、
22、式中,p为每个二元子分类器的输出概率值,取值范围为(0,1);y为每个分支的数值化标签值,y=0 or 1;α为正负样本平衡因子;γ为困难样本权重调节因子;n为输出分支的类别数量;
23、所述训练数据为获取的车内视频数据经步骤1和步骤2处理后得到的若干梅尔频谱;
24、所述训练标签为人工标注的各视频数据对应的数值化声音类别标签。
25、作为一种可选方案,对于正负样本平衡因子α,基于训练数据集的整体分布,遵循长尾分布的解决方案给各类别赋予不同的权重系数,其中,样本数量较少的类别的权重大于样本较多的类别的权重;对于困难样本权重调节因子γ,通过训练过程的不同迭代周期来确定,训练前期、中期、后期分别给予不同大小的数值,随着训练迭代次数的增加,困难样本权重调节因子不断增大。
26、作为一种可选方案,所述声音类别包括:咳嗽、敲击车体、讲话、考试语音播报、开关车门、插拔安全带、档位手刹脚刹操作、灯光操作,其中包含疑似作弊行为的语音提示类别有:咳嗽、敲击、说话。
27、作为一种可选方案,该检测方法还包括:
28、步骤4:判断所述声音类别包含疑似作弊行为的语音提示类别后,将对应的音频数据推荐给管理人员进行复核,以确定是否确实存在作弊行为。
29、本发明的第二方面公开一种电子设备,其包括处理器和存储器,所述处理器用于调用存储器中存储的计算机程序,执行第一方面及其任意一可选方案所述的基于深度学习的语音提示作弊行为检测方法。
30、本发明具有以下有益效果:
31、(1)本发明将语音识别与深度学习算法相结合,能实现自动识别疑似作弊行为,这样可以在大量的视频数据中挑出初步判定为疑似作弊行为的目标数据推荐给管理人员复核,由此可大大降低管理人员的工作量,提高工作效率,并起到规范驾考纪律,提升安全员监管能力水平的作用。
32、(2)本发明能针对多标签语音分类的问题场景,同时结合自身数据分布的整体情况考虑,对focalloss损失函数进行有效的改进优化,进一步提升了模型的整体分类性能。
33、(3)本发明基于智能音视频技术,可以适用于任何复杂场景,并且涉及的硬件设备仅包括摄像头、麦克风和计算机、平板电脑等电子设备,无需改造车体,大大降低了硬件成本和运行功耗,且对不同驾乘人员和车型的鲁棒性较高,具有较高的实用价值和广阔应用前景。
- 还没有人留言评论。精彩留言会获得点赞!