一种基于多并行卷积神经网络的声学特征采样方法与流程
本发明公开一种声学特征采样方法,具体为基于多并行卷积神经网络的声学特征采样方法。
背景技术:
1、互联网技术的飞速发展带动着各种技术快速进步,例如声音、文字等信息的发送、接受、传递以及处理相关技术,均或多或少的从中受益得到提高。就目前而言,音频这类更容易表达情感的信息媒体更受人们喜爱,因此,对于这类信息的处理也就变的尤为重要。语音信号在人类生活中扮演着很关键的角色,人们无时无刻不在制造或者接受声音信号,日常人与人之间的交流就是最为典型的例子。同样在这个科技飞速发展的时代,通过语音信号实现人与机器之间的信息交互也是尤为重要,例如智能家居中的智能音箱,手机中的语音助手,汽车中配备的车载语音助手等。语音是日常生活中交流的主要媒介,同时,语音是一种富含信息的信号载体,它承载了语义、说话人、情绪、语种、方言等诸多信息。语音信息抽取类似于人类语言学习的思路,采用机器学习手段,让机器通过“聆听”大量的语音数据,并从语音数据中学习蕴含其中的规律。
2、在深度学习应用到语音建模领域之前,声学模型已经有了非常成熟的模型体系,从20世纪70年代开始,隐马尔科夫模型(hmm)理论被成功应用到语音识别中。在声学模型上,fundamentals of speech recognition系统地介绍了如何训练一个大规模的连续语音识别系统,即hmm-gmm模型,随着gmm模型的自适应、降噪、特征工程等方法的相继提出,增强了系统的性能和鲁棒性。传统信号处理方法为了简化计算或获得解析解做了很多假设和简化,比如有限阶线性系统(滤波)假设、语音和噪声的复数域高斯分布假设、频带独立假设等等。
3、声学模型的发展实际就是伴随着机器学习的发展而不断尝试更好的建模方式来代替基于统计的建模方式的过程。语音信号不仅包含上下文关联信息,也包含了各种频率特征,这些特征在不同帧之间有差别,每一帧内部也有差异,传统的建模方式不能很好捕捉到局部差异,因此使用神经网络来提取局部特征。在dnn之前,hmm的观察值概率分布普遍使用gmm进行建模,而搭建dnn-hmm系统则需要训练一种深度神经网络,通过预测每个输入帧最可能的hmm状态来代替gmm的分布。并且,gmm本质上属于浅层结构,表征能力不够强,且要求特征元素之间相互独立。dnn拥有更强的表征能力,能够对复杂的语音变化情况进行建模,适合有更多维度的mfcc或者fbank特征。同时dnn还具有强大环境学习能力,可以提升对噪声和口音的鲁棒性。这个模型框架成为声学模型基础结构,并沿用至今。
4、利用语音来与这些电子设备进行交互是一种十分便捷的交互方式,目前使用的语音模型一般都为深度学习模型,需要数据集的支持,但是不同数据集中说话人的方式不同,音色不同,同样的说话人在不同的语境下的表示也不同,典型表现就是每个音素的快慢表达以及持续时间长短都代表了不同的语义信息,而这些特征在语谱图中表现为占据不同大小的面积,即音素持续时间越长,在语谱图中占据的面积越大。所以探索一种能实现标准化声学特征采样是一种恰当可行的方法。
技术实现思路
1、针对现有技术中尚无标准化声学特征采样等不足,本发明要解决的技术问题是提供一种基于多并行卷积神经网络的声学特征采样方法,解决了因数据集中说话人的方式不同,音色不同等问题所导致语音特征难以提取问题,增强了语音的表示,实现标准化声学特征采样。
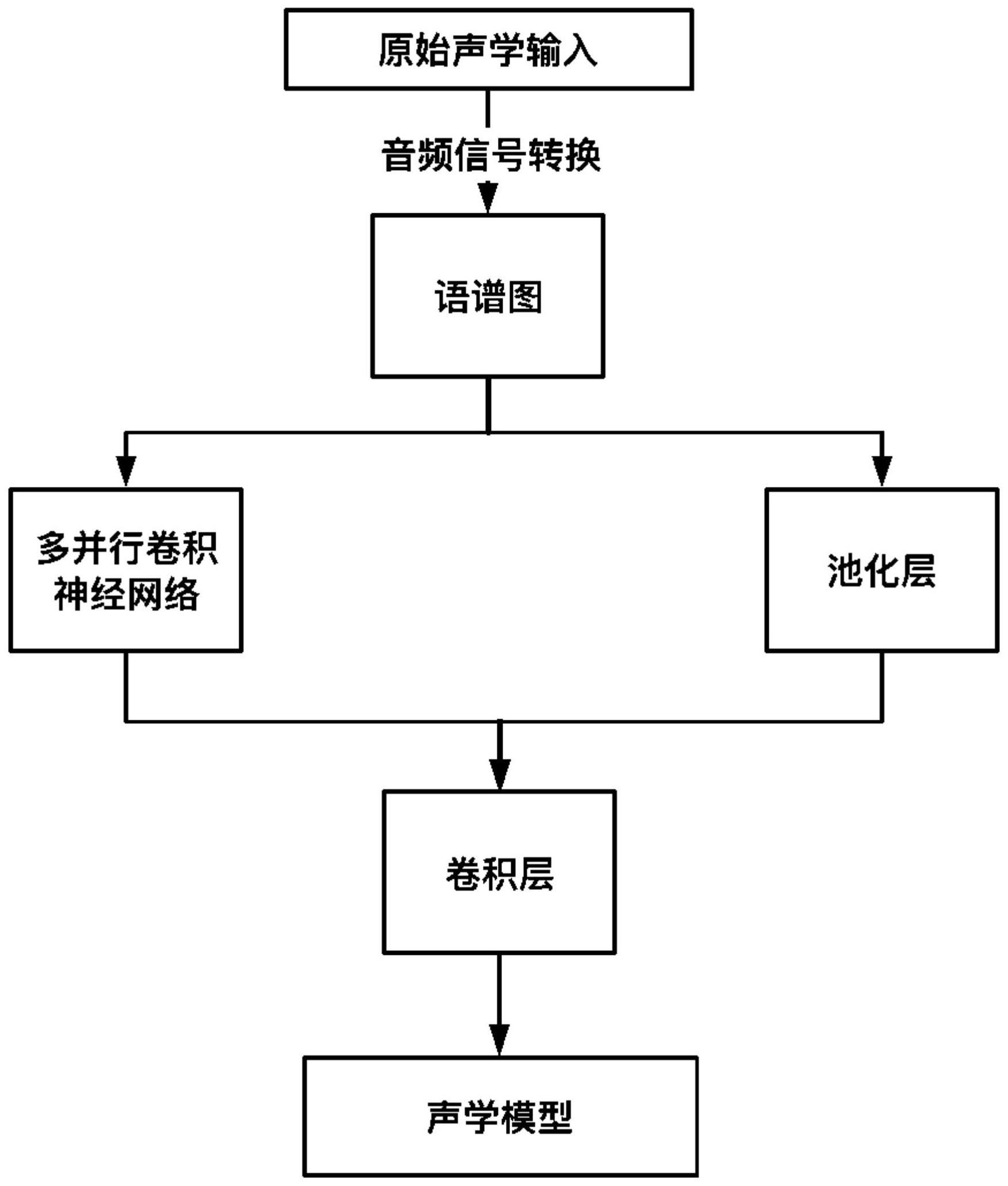
2、本发明提供一种基于多并行卷积神经网络的声学特征采样方法,包括以下步骤:
3、1)对语音数据集中原始音频信号进行转化,将原始的不定长时序信号转换为语谱图;
4、2)将语谱图作为多并行卷积神经网络的输入数据进行计算,得到不同的特征图谱,将不同的特征图谱加权叠加,得到输出a;
5、3)将语谱图经过池化层,得到输出b,合并输出a和输出b,将合并的结果输入至特征提取卷积层来提取更高维度的特征;
6、4)将得到的特征进行编码,传递给语音识别模块或语音翻译模块,构建完整的语音识别模型或语音翻译模型。
7、在步骤1)中,对语音数据集中原始音频信号进行转化,将原始的不定长时序信号转换为语谱图,具体为:
8、101)对原始信号预加重;
9、102)对预加重后的信号进行分帧加窗,进行短时傅立叶变换,得到每帧信号的频谱图;
10、103)对频谱图进行旋转,加映射;
11、104)将映射后的多帧频谱进行拼接,形成语谱图。
12、步骤2)具体为:
13、201)结合1×1、3×3和5×5卷积核来构建多并行卷积神经网络;
14、202)利用多并行卷积神经网络提取语谱图中不同持续时间的语音特征,将语音特征转化为统一的标准化特征表示,对不同长度的特征图谱进行加权求和,得到输出a。
15、步骤3)具体为:
16、301)使用3×3的池化层,对语谱图进行特征选择和信息过滤,得到输出b;
17、302)按对应深度将输出a和输出b连接起来,将连接后的结果输入至特征提取卷积层来提取更高维度的特征。
18、在步骤4)中,将得到的特征进行编码,传递给语音识别模块,构建完整的语音识别模型,具体为:
19、将声学模型作为语音识别模型的编码器,通过解码器,得到语音识别模型。
20、在步骤4)中,对于语音翻译模块,构建完整的语音翻译模型,具体为:
21、将声学模型得到的表示传递给文本编码器,然后再通过解码器,得到语音翻译模型。
22、本发明具有以下优点:
23、1.本发明提出来一种基于多并行卷积神经网络的声学特征采样方法,解决了因数据集中说话人的方式不同,音色不同等问题所导致语音特征难以提取问题,增强了语音的表示,实现标准化声学特征采样。
24、2.本发明在提升模型性能的同时,提高了模型的鲁棒性,使得模型在不同语种以及不同数据集下都能有出色的表现。
技术特征:
1.一种基于多并行卷积神经网络的声学特征采样方法,其特征在于包括以下步骤:
2.按权利要求1所述的基于多并行卷积神经网络的声学特征采样方法,其特征在于:在步骤1)中,对语音数据集中原始音频信号进行转化,将原始的不定长时序信号转换为语谱图,具体为:
3.按权利要求1所述的基于多并行卷积神经网络的声学特征采样方法,其特征在于:步骤2)具体为:
4.按权利要求1所述的基于多并行卷积神经网络的声学特征采样方法,其特征在于:步骤3)具体为:
5.按权利要求1所述的基于多并行卷积神经网络的声学特征采样方法,其特征在于:在步骤4)中,将得到的特征进行编码,传递给语音识别模块,构建完整的语音识别模型,具体为:
6.按权利要求1所述的基于多并行卷积神经网络的声学特征采样方法,其特征在于在步骤4)中,对于语音翻译模块,构建完整的语音翻译模型,具体为:
技术总结
本发明公开一种基于多并行卷积神经网络的声学特征采样方法,步骤为:对语音数据集中原始音频信号进行转化,将原始的不定长时序信号转换为语谱图;将语谱图作为多并行卷积神经网络的输入数据进行计算,得到不同的特征图谱,将不同的特征图谱加权叠加,得到输出a;将语谱图经过池化层,得到输出b,合并输出a和输出b,将合并结果输入至特征提取卷积层来提取更高维度的特征;将得到的特征进行编码,传递给语音识别模块或语音翻译模块,构建完整的语音识别模型或语音翻译模型。本发明方法解决了因数据集中说话人的方式不同、音色不同等问题所导致语音特征难以提取问题,增强了语音的表示,实现标准化声学特征采样,提升了模型的鲁棒性。
技术研发人员:田丰宁,吕星宇
受保护的技术使用者:沈阳雅译网络技术有限公司
技术研发日:
技术公布日:2024/1/14
- 还没有人留言评论。精彩留言会获得点赞!