一种利用耳戴式运动传感器识别语音内容的方法
本发明涉及一种语音内容识别方法,尤其涉及一种利用耳戴式运动传感器来识别语音内容的方法,用于扩展人机交互应用,属于移动计算应用。
背景技术:
1、在物联网技术迅速发展以及人机交互重要性日趋凸显的背景下,计算机面临的交互任务场景和深度与日俱增,促进了人机交互技术类型的多样化。语音内容识别由于形式自然,免于接触式操作成为了人机交互技术的重要一环。传统语音内容识别技术通过麦克风录制音频,根据其时域和频域特征匹配语音音素,最后整合成为语音内容。然而,麦克风录制的音频对于环境噪音较为敏感,导致此类方法在环境噪音较强时无法工作。因此,在复杂噪声环境下实现可靠的识别语音内容,成为国内外相关领域的研究热点。
2、为了应对复杂的环境噪声,研究人员开发了大量的噪音滤波算法。然而,滤波算法针对性强,往往只能应对单一的噪声类型。部分方法利用大规模麦克风阵列来录制含有噪声的音频,基于盲源分离技术提取噪音信号和语音信号。然而,麦克风阵列成本较高,部署复杂,依赖对环境噪音的先验知识,难以在日常生活中应用。
3、此外,部分方法用摄像头来捕捉说话口型,然后识别语音内容,但此类依赖摄像头的方法存在隐私泄露的风险,并且对测试环境要求苛刻,如人脸无遮挡、光线充足等。还有部分方法利用毫米波信号、wi-fi信号或其他射频信号捕捉说话时的唇部和喉部运动以识别语音内容,但此类方法易被身体运动导致的多径效应影响,且在测量时普遍要求用户保持静止,严重限制用户行为。另外,还有部分方法利用专用喉部骨传导麦克风录制说话时的骨传导音频以识别语音内容,然而,在喉部佩戴麦克风在日常生活中会带来诸多不便,难以大规模推广。
4、综上所述,现有的方法存在各种不足,亟需新的方法来克服其局限性。
技术实现思路
1、本发明的目的是为了克服现有在复杂环境噪音下语音内容识别方法的问题和缺陷,创造性地提出一种利用耳戴式运动传感器识别语音内容的方法,能够在复杂环境噪音下准确识别佩戴者的语音内容。
2、随着嵌入式和传感器技术的不断发展,耳戴式设备(如智能耳机、智能助听器)普遍部署了加速度计、陀螺仪等运动传感器,用于实现佩戴监测、触摸交互等功能,使耳戴设备的感知能力显著提升,为感知佩戴者语音内容提供了有力支撑。
3、本发明提出的利用耳戴式运动传感器识别语音内容的方法,其基本原理在于:语音产生过程中,一方面,声带的振动以下颌骨和肌肉组织为媒介传播到耳朵,可以被耳戴式设备的运动传感器捕捉,被称为骨传导振动(bone conduction vibrations,简称bcv)。另一方面,说话时舌头、嘴唇等器官的运动会引起耳道轮廓变形,也可以被耳戴式设备的运动传感器的捕捉,被称为耳道动态运动(ear canal dynamic motions,简称ecdm)。bcv和ecdm的特性取决于说话内容,因此,分析bcv和ecdm能够提取与说话内容有关的大量信息,最终识别佩戴者的语音内容。
4、本发明的目的是通过以下技术方案实现的。
5、一种利用耳戴式运动传感器识别语音内容的方法,包括以下步骤:
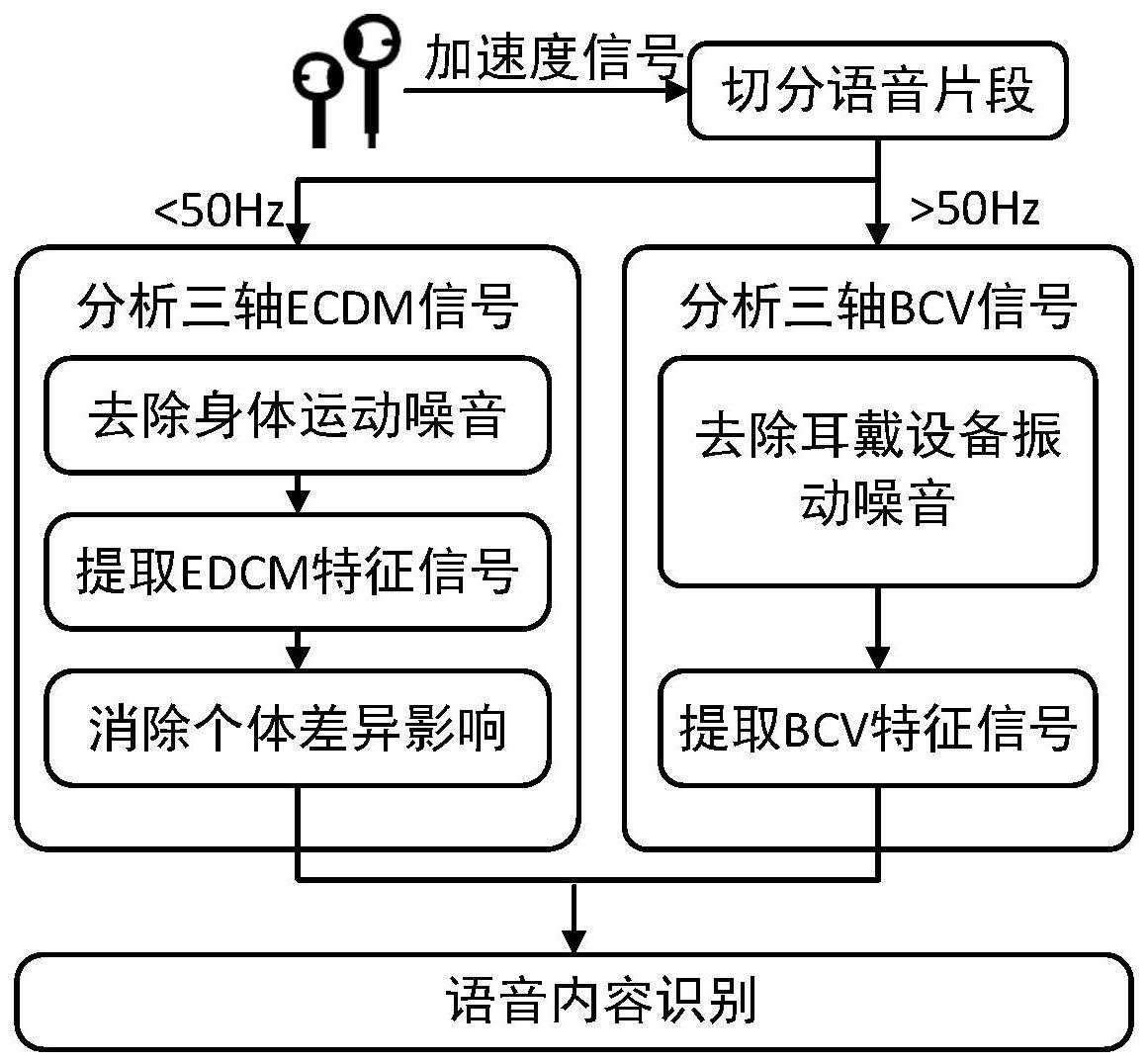
6、步骤1:使用耳戴式运动传感器采集佩戴者耳部的运动状态信号(加速度信号),并切分语音片段。
7、该步骤的目的是为了节省计算资源,根据说话时加速度信号变化剧烈的特点监测并切分含有语音的片段。
8、具体地,包括以下步骤:
9、步骤1.1:使用滤波器处理采集到的三轴加速度信号,分别提取三轴骨传导振动bcv信号和三轴耳道动态运动ecdm信号。
10、步骤1.2:分析步骤1.1获得的三轴bcv信号和三轴ecdm信号,使用基于阈值的方法检测语音片段的开始和结束时间,切分语音片段。
11、步骤2:分析三轴ecdm信号,提取与语音内容有关的特征信号,消除特征中的个体差异。
12、该步骤的目的是去除运动状态信号中的噪声,提取与语音内容有关的特征信号,并重构特征信号以消除个体差异的影响,为后续实现用户无关的语音内容识别做准备。
13、具体地,包括以下步骤:
14、步骤2.1:利用深度回归网络,处理步骤1.2获取的语音片段中的三轴ecdm信号,去除身体运动引起的噪音。
15、步骤2.2:分析步骤2.1获取的纯净三轴ecdm信号,提取与语音内容有关的ecdm信号。
16、步骤2.3:重构步骤2.2提取的ecdm信号的波形,消除个体差异的影响。
17、步骤3:分析三轴bcv信号,提取与语音内容有关的特征信号。
18、该步骤的目的是去除bcv中的噪声,提取与语音内容有关的特征信号,为后续结合数据驱动方法实现用户无关的语音内容识别做准备。
19、步骤3.1:处理步骤1.2获取的语音片段中的三轴bcv信号,消除由耳戴设备振动引起的噪音。
20、步骤3.2:分析步骤3.1获取的纯净bcv信号,提取与语音内容有关的bcv信号。
21、步骤4:利用步骤2.3和3.2获取的ecdm信号和bcv信号,基于卷积神经网络(convolutional neural network,简称cnn)和连接主义时空分类(connectionisttemporal classification,简称ctc)识别语音内容。
22、至此,从步骤1到步骤4,实现了利用耳戴运动传感器的语音内容识别方法。
23、有益效果
24、本发明方法,与现有认证技术相比,具有以下优点:
25、1.本发明仅依靠耳戴式设备上普遍嵌入的运动传感器识别语音内容,可以在复杂环境噪音下可靠运行,具有抗干扰、低成本的优势。
26、2.本发明设计了一种利用基音追踪的噪音消除方法,可以精准地从bcv信号中分离身体运动引起的噪音。
27、3.本发明设计了一种基于procrustes变换的信号重构方法,可以有效减少个体差异导致的ecdm特征信号的不稳定性,是实现用户无关的语音内容识别的基础之一。
28、4.本发明设计了一种特征信号生成算法,利用正常语音信号生成含有个体差异信息的bcv特征信号,是实现用户无关的语音内容识别的基础之一。
29、5.本发明基于cnn和ctc设计了一个深度学习模型,该模型能够独立于用户实现准确的单词级语音内容识别。
技术特征:
1.一种利用耳戴式运动传感器的语音内容识别方法,其特征在于,包括以下步骤:
2.如权利要求1所述的一种利用耳戴式运动传感器的语音内容识别方法,其特征在于,步骤1.1中,分别利用截止频率为50hz的高通滤波器和低通滤波器处理所采集的三轴加速度信号,其中频率高于50hz的分量即为三轴bcv信号,低于50hz的分量即为三轴ecdm信号;
3.如权利要求1所述的一种利用耳戴式运动传感器的语音内容识别方法,其特征在于,步骤1.2中,阈值t0设为线性bcv信号和线性ecdm信号的最大值的[0.1,0.5]倍。
4.如权利要求2所述的一种利用耳戴式运动传感器的语音内容识别方法,其特征在于,阈值t0设为线性bcv信号和线性ecdm信号的最大值的0.2倍。
5.如权利要求2所述的一种利用耳戴式运动传感器的语音内容识别方法,其特征在于,步骤2.1中,深度回归网络由输入层,两个全连接层和一个输出组成;输入层对输入受到噪音干扰的三轴ecdm信号进行处理,利用短时傅里叶变换分别计算其x、y、z数据的频谱密度并输入给全连接层,全连接层消除运动噪音,输出层利用逆短时傅里叶变换将消除噪音后的三轴频谱密度恢复为纯净三轴ecdm信号;
6.如权利要求1所述的一种利用耳戴式运动传感器的语音内容识别方法,其特征在于,步骤2.2中,分别提取三轴ecdm信号x、y、z轴数据的上包络ex,ey,ez作为edcm特征信号e={ex,ey,ez};
7.如权利要求1所述的一种利用耳戴式运动传感器的语音内容识别方法,其特征在于,步骤3.1中,通过基音追踪消除耳戴设备振动引起的噪音来提取纯净的bcv信号,基音追踪包括信号分解、通道聚合、基音追踪和信号合成;
8.如权利要求7所述的一种利用耳戴式运动传感器的语音内容识别方法,其特征在于,步骤3.1中,t1设定取值范围为[0.5-0.99],t2设定取值范围为[0.6,1)。
9.如权利要求8所述的一种利用耳戴式运动传感器的语音内容识别方法,其特征在于,t1设为0.985,t2设为0.985。
10.如权利要求1所述的一种利用耳戴式运动传感器的语音内容识别方法,其特征在于,步骤4中,基于cnn和ctc构建深度神经网络,包括特征信号处理器、特征融合器和语音内容识别器;
技术总结
本发明涉及一种利用耳戴式运动传感器识别语音内容的方法,属于移动计算应用技术领域。首先使用耳戴式运动传感器采集佩戴者耳部的运动状态信号并切分语音片段。分析三轴ECDM信号,提取与语音内容有关的特征信号,消除特征中的个体差异。分析三轴BCV信号,提取与语音内容有关的特征信号。最后,利用获取的ECDM特征信号和BCV特征信号,基于卷积神经网络和连接主义时空分类来识别语音内容。本发明仅依靠耳戴式设备上普遍嵌入的运动传感器识别语音内容,能够在复杂环境噪音下可靠运行,具有抗干扰、低成本等优势。
技术研发人员:李凡,曹烨彤,刘晓晨,翟圣淳
受保护的技术使用者:北京理工大学
技术研发日:
技术公布日:2024/1/13
- 还没有人留言评论。精彩留言会获得点赞!