基于语音的情感识别方法和装置、电子设备及存储介质与流程
本技术涉及人工智能和金融科技,尤其涉及一种基于语音的情感识别方法和装置、电子设备及存储介质。
背景技术:
1、语音情感识别(speech emot ion recognit ion,ser)可以用于根据语音片段识别出情感类别,例如在金融场景下,可以根据客户的语音识别出当前客户的情感,以根据客户的情感与客户进行互动;又如在医疗场景下,可以根据患者的语音识别出当前患者的情感,以便及时了解患者的情绪,以结合患者的情绪与患者交流,从而提高患者的就诊体验。传统的语音情感识别方法主要基于深度学习,提取音频中的频谱,并根据提取到的频谱进行特征提取,以根据提取到的特征进行情感识别。实际场景中,不同说话人的音频,在音高、音色、语调、语速等多个特征上有较大差异,若训练样本在上述音高、音色、语调、语速等方面分布不均,训练得到的模型对于情感识别的效果不好,预测得到的情感类别不准确。因此,如何提高情感识别的准确率,成为了亟待解决的技术问题。
技术实现思路
1、本技术实施例的主要目的在于提出一种基于语音的情感识别方法和装置、电子设备及存储介质,旨在提高情感识别的准确率和效率。
2、为实现上述目的,本技术实施例的第一方面提出了一种基于语音的情感识别方法,所述方法包括:
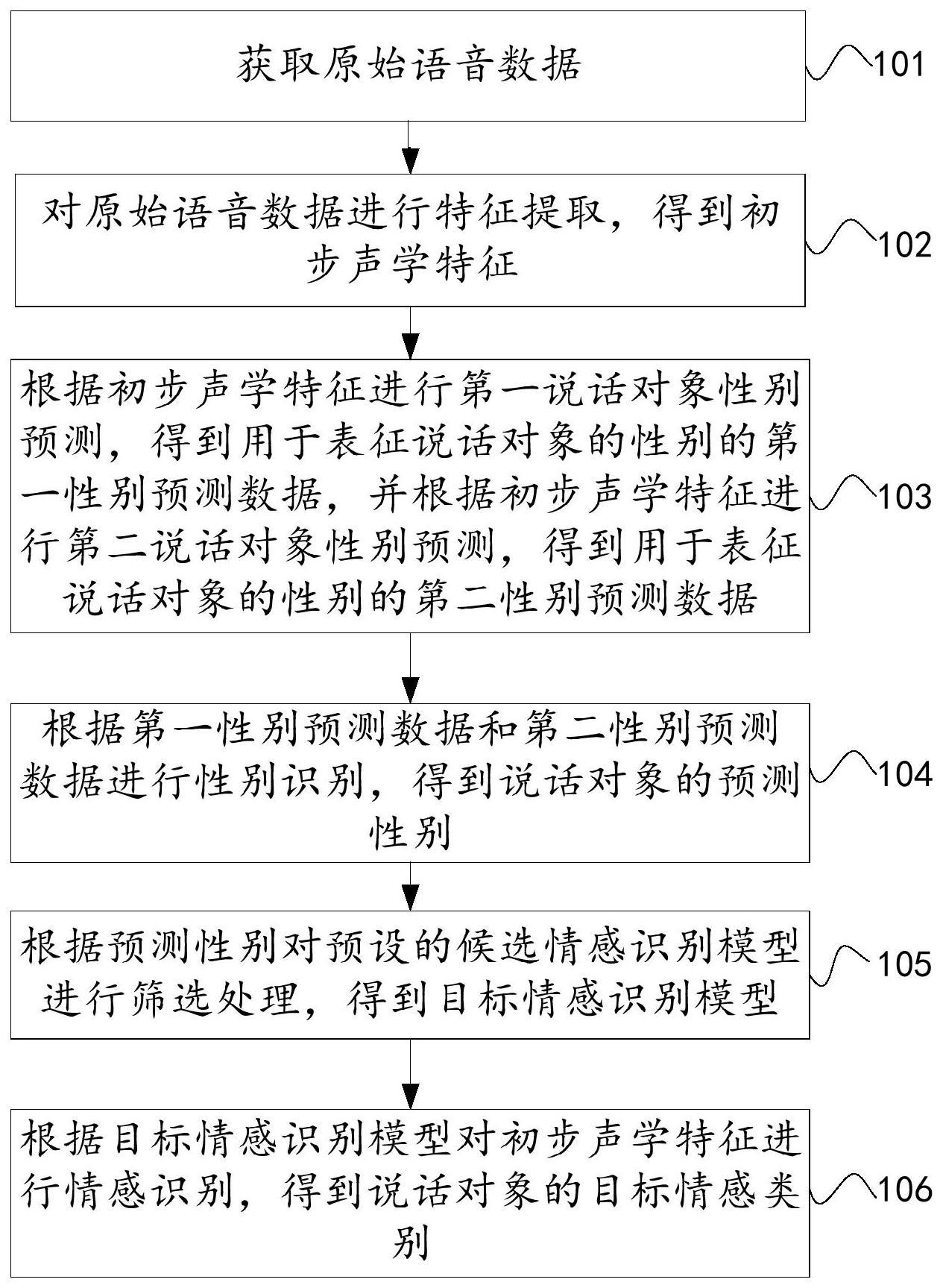
3、获取原始语音数据;
4、对所述原始语音数据进行特征提取,得到初步声学特征;
5、根据所述初步声学特征进行第一说话对象性别预测,得到用于表征所述说话对象的性别的第一性别预测数据,并根据所述初步声学特征进行第二说话对象性别预测,得到用于表征所述说话对象的性别的第二性别预测数据;
6、根据所述第一性别预测数据和所述第二性别预测数据进行性别识别,得到所述说话对象的预测性别;
7、根据所述预测性别对预设的候选情感识别模型进行筛选处理,得到目标情感识别模型;
8、根据所述目标情感识别模型对所述初步声学特征进行情感识别,得到所述说话对象的目标情感类别。
9、在一些实施例,所述根据所述第一性别预测数据和所述第二性别预测数据进行性别识别,得到所述说话对象的预测性别,包括:
10、获取所述第一性别预测数据的第一性别参数得到第一性别值,获取所述第二性别预测数据的第二性别参数得到第二性别值;
11、对所述第一性别值和所述第二性别值进行比对,得到目标性别值;其中,所述目标性别值等于所述第一性别值或者所述第二性别值;
12、根据所述目标性别值得到所述预测性别。
13、在一些实施例,所述获取所述第一性别预测数据的第一性别参数得到第一性别值,获取所述第二性别预测数据的第二性别参数得到第二性别值,包括:
14、将所述第一性别预测数据输入至预设的第一性别预测模型进行第一性别预测,得到所述第一性别参数;
15、将所述第二性别预测数据输入至预设的第二性别预测模型进行第二性别预测,得到所述第二性别参数;其中,所述第二性别预测模型与所述第一性别预测模型的模型结构相同;
16、从所述第一性别参数提取出所述第一性别值,从所述第二性别参数提取出所述第二性别值。
17、在一些实施例,所述目标情感识别模型包括特征提取网络、transformer编码器和情感分类器,所述根据所述目标情感识别模型对所述初步声学特征进行情感识别,得到所述说话对象的目标情感类别,包括:
18、基于所述特征提取网络对所述梅尔频谱特征进行特征提取,得到频谱特征序列;
19、基于所述transformer编码器对所述频谱特征序列进行情感特征识别,得到目标情感特征;
20、基于所述情感分类器对所述目标情感特征进行情感特征分类,得到所述目标情感类别。
21、在一些实施例,所述特征提取网络包括网络分割层和特征向量转换层,所述基于所述特征提取网络对所述梅尔频谱特征进行特征提取,得到频谱特征序列,包括:
22、基于所述网络分割层对所述梅尔频谱特征进行特征分割,得到频谱特征片段;
23、基于所述特征向量转换层对所述特征片段进行向量化处理,得到所述频谱特征序列。
24、在一些实施例,所述对所述原始语音数据进行特征提取,得到初步声学特征,包括:
25、对所述原始语音数据进行短时傅里叶变换频谱计算,得到初步频谱数据;
26、对所述初步频谱数据进行梅尔频谱计算,得到所述初步声学特征。
27、在一些实施例,所述根据所述目标情感识别模型对所述初步声学特征进行情感识别,得到所述说话对象的目标情感类别之前,所述方法还包括:训练所述候选情感识别模型,具体包括:
28、获取带标注的第一训练数据和带标注的第二训练数据;其中,所述第一训练数据标注有第一性别标签和第一情感标签,所述第二训练数据标注有第二性别标签和第二情感标签,所述第一性别标签不同于所述第二性别标签;
29、根据所述第一训练数据对第一预设子模型进行训练,得到第一情感识别子模型;
30、根据所述第二训练数据对第二预设子模型进行训练,得到第二情感识别子模型;
31、根据所述第一情感识别子模型和所述第二情感识别子模型,得到所述候选情感识别模型。
32、为实现上述目的,本技术实施例的第二方面提出了一种基于语音的情感识别装置,所述装置包括:
33、语音数据获取模块,用于获取原始语音数据;
34、语音特征提取模块,用于对所述原始语音数据进行特征提取,得到初步声学特征;
35、对象性别预测模块,用于根据所述初步声学特征进行第一说话对象性别预测,得到用于表征所述说话对象的性别的第一性别预测数据,并根据所述初步声学特征进行第二说话对象性别预测,得到用于表征所述说话对象的性别的第二性别预测数据;
36、对象性别识别模块,用于根据所述第一性别预测数据和所述第二性别预测数据进行性别识别,得到所述说话对象的预测性别;
37、模型筛选模块,用于根据所述预测性别对预设的候选情感识别模型进行筛选处理,得到目标情感识别模型;
38、情感识别模块,用于根据所述目标情感识别模型对所述初步声学特征进行情感识别,得到所述说话对象的目标情感类别。
39、为实现上述目的,本技术实施例的第三方面提出了一种电子设备,所述电子设备包括存储器和处理器,所述存储器存储有计算机程序,所述处理器执行所述计算机程序时实现上述第一方面所述的方法。
40、为实现上述目的,本技术实施例的第四方面提出了一种存储介质,所述存储介质为计算机可读存储介质,所述存储介质存储有计算机程序,所述计算机程序被处理器执行时实现上述第一方面所述的方法。
41、本技术提出的基于语音的情感识别方法和装置、电子设备及存储介质,其通过获取原始语音数据,并对所述原始语音数据进行特征提取得到初步声学特征,再根据所述初步声学特征进行第一说话对象性别预测得到用于表征所述说话对象的性别的第一性别预测数据,并根据所述初步声学特征进行第二说话对象性别预测得到用于表征所述说话对象的性别的第二性别预测数据,从而根据所述第一性别预测数据和所述第二性别预测数据进行性别识别,得到所述说话对象的预测性别,再根据所述预测性别对预设的候选情感识别模型进行筛选处理得到目标情感识别模型,从而根据所述目标情感识别模型对所述初步声学特征进行情感识别,得到所述说话对象的目标情感类别,从而可以提高情感识别的准确率和效率。
- 还没有人留言评论。精彩留言会获得点赞!