歌曲识别网络的训练方法、翻唱歌曲识别方法及相关装置与流程
本发明涉及歌曲数据处理,尤其涉及一种歌曲识别网络的训练方法、翻唱歌曲的识别方法及相关装置。
背景技术:
1、翻唱识别技术是指通过特征提取方法,从歌曲音频中提取旋律信息,根据旋律的相似性找出同歌曲的不同翻唱版本。翻唱识别技术在版权检测、歌曲分组、盗歌检测中都有着广泛的应用。
2、随着深度学习技术的发展,通过深度神经网络模型提取旋律特征的方法已经成为主流,现有的主流做法通常采用网络模型的架构,结合翻唱识别任务的特性,对网络模型的架构做一些针对性的优化,或者结合翻唱识别模型提取旋律特征的目标,融合多元损失函数。因此,现有方案已经在歌曲识别网络模型的架构和损失函数设计方面做了许多详尽的工作,如何继续优化神经网络模型成为当先需要解决的问题。
技术实现思路
1、本发明实施例提供了一种歌曲识别网络的训练方法、翻唱歌曲的识别方法及相关装置,用于识别目标歌曲翻唱版本中的离群点和野点,并基于离群点和野点,对歌曲识别网络进行训练,从而提升歌曲识别网络对翻唱歌曲识别的准确率。
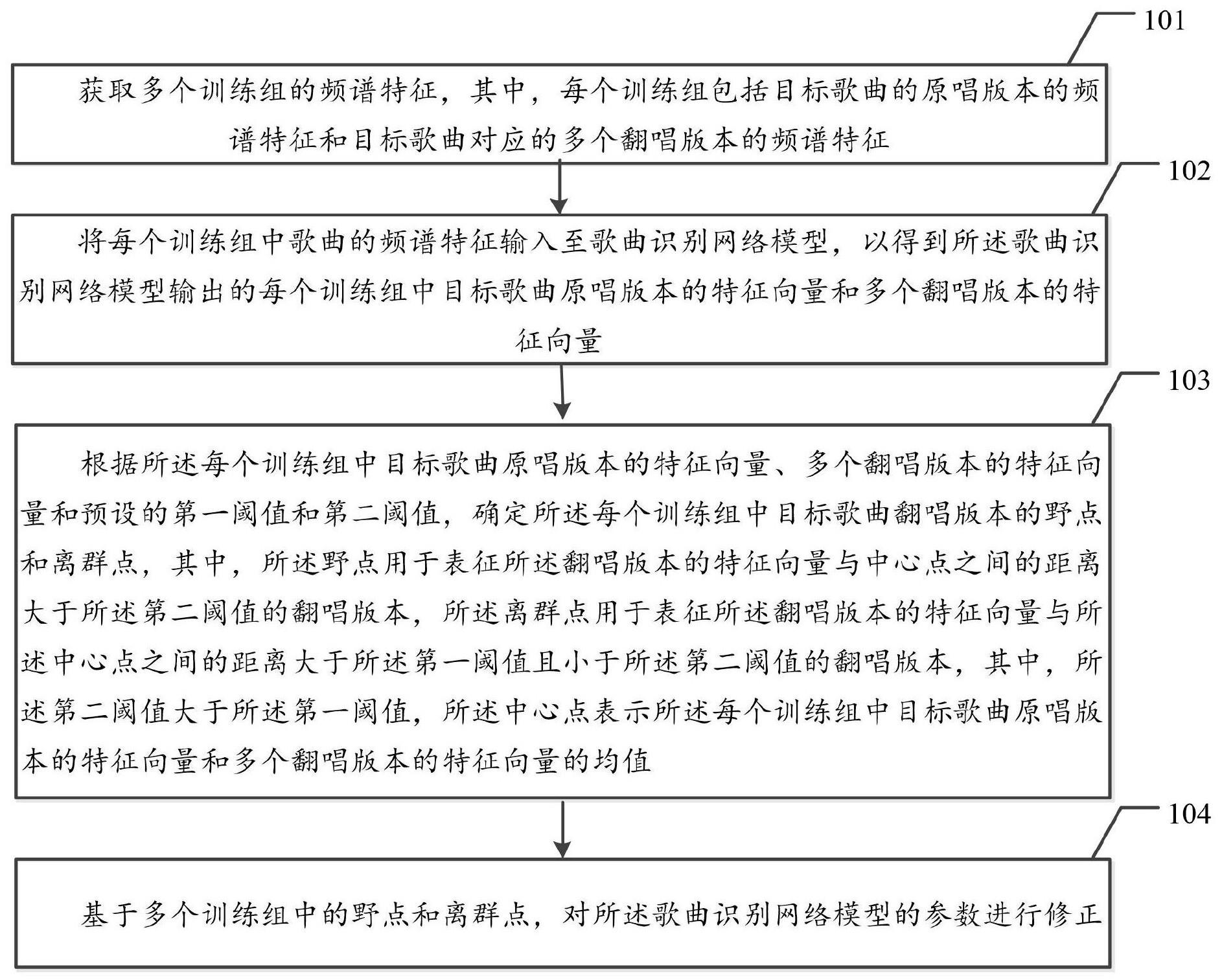
2、本技术实施例第一方面提供了一种歌曲识别网络模型的训练方法,包括:
3、获取多个训练组的频谱特征,其中,每个训练组包括目标歌曲的原唱版本的频谱特征和目标歌曲对应的多个翻唱版本的频谱特征;
4、将每个训练组中歌曲的频谱特征输入至所述歌曲识别网络模型,以得到所述歌曲识别网络模型输出的每个训练组中目标歌曲原唱版本的特征向量和多个翻唱版本的特征向量;
5、根据所述每个训练组中目标歌曲原唱版本的特征向量、多个翻唱版本的特征向量和预设的第一阈值和第二阈值,确定所述每个训练组中目标歌曲翻唱版本的野点和离群点,其中,所述野点用于表征所述翻唱版本的特征向量与中心点之间的距离大于所述第二阈值的翻唱版本,所述离群点用于表征所述翻唱版本的特征向量与所述中心点之间的距离大于所述第一阈值且小于所述第二阈值的翻唱版本,其中,所述第二阈值大于所述第一阈值,所述中心点表示所述每个训练组中目标歌曲原唱版本的特征向量和多个翻唱版本的特征向量的均值;
6、基于多个训练组中的野点和离群点,对所述歌曲识别网络模型的参数进行修正。
7、作为一种可选的实施例,所述基于多个训练组中的野点和离群点,对所述歌曲识别网络模型的参数进行修正,包括:
8、删除每个训练组中的所述野点;
9、根据多个训练组中的每个训练组的所述离群点,计算离群点损失;
10、根据所述离群点损失,采用反向传播算法,对所述歌曲识别网络模型的参数进行修正。
11、作为一种可选的实施例,所述根据多个训练组中的每个训练组的所述离群点,计算离群点损失,包括:
12、确认每个训练组中的离群点和组内点,其中,所述组内点表示所述翻唱版本的特征向量与所述中心点之间的距离小于所述第一阈值的翻唱版本;
13、计算每个训练组中所有离群点的偏差,其中,每个离群点的偏差表示每个离群点到训练组中心点的距离,与训练组内所有组内点到所述中心点距离均值的比值;
14、将多个训练组中全部离群点的偏差累加,得到所述离群点损失。
15、作为一种可选的实施例,每个训练组还包括至少一首区别于目标歌曲的其他歌曲,其中,目标歌曲和其他歌曲都自带样本标签;
16、将每个训练组中歌曲的频谱特征输入至所述歌曲识别网络模型,以得到所述歌曲识别网络模型输出的每个训练组中目标歌曲原唱版本的特征向量和多个翻唱版本的特征向量,包括:
17、将每个训练组中歌曲的频谱特征输入至所述歌曲识别网络模型,以得到所述歌曲识别网络模型输出的每个训练组中目标歌曲原唱版本的特征向量和多个翻唱版本的特征向量,以及所述其他歌曲的特征向量;
18、在根据每个训练组中目标歌曲原唱版本的特征向量、多个翻唱版本的特征向量和预设的第一阈值和第二阈值,确定每个训练组中翻唱版本的野点和离群点之后,所述方法还包括:
19、根据所述每个训练组中目标歌曲原唱版本的特征向量、多个翻唱版本的特征向量和所述其他歌曲的特征向量,确定三元损失;
20、基于每个训练组中的野点、离群点和所述三元损失,对所述歌曲识别网络模型的参数进行修正。
21、作为一种可选的实施例,根据所述每个训练组中目标歌曲原唱版本的特征向量、多首翻唱版本的特征向量和所述其他歌曲的特征向量,确定三元损失,包括:
22、计算所述每个训练组中目标歌曲原唱版本的特征向量和多首翻唱版本的特征向量之间的第一距离的平均值d1;
23、计算所述每个训练组中目标歌曲原唱版本的特征向量和其他歌曲的特征向量之间的第二距离d2;
24、根据所述第一距离的平均值d1、所述第二距离d2和第一公式,计算每个训练组的三元损失;
25、所述第一公式包括:
26、l=max(d1-d2+margin,0),margin表示可调的程度系数,l表示所述三元损失。
27、作为一种可选的实施例,所述基于每个训练组中的野点、离群点和所述三元损失,对所述歌曲识别网络模型的参数进行修正,包括:
28、删除每个训练组中的野点和离群点;
29、根据所述三元损失,采用反向传播算法,对所述歌曲识别网络模型的参数进行修正。
30、作为一种可选的实施例,所述基于每个训练组中的野点、离群点和所述三元损失,对所述歌曲识别网络模型的参数进行修正,包括:
31、删除每个训练组中的野点;
32、选取同一训练组中的两个离群点,作为所述训练组下一轮训练的目标歌曲的原唱版本和目标歌曲的翻唱版本;
33、根据多个训练组中的每个训练组的所述离群点,计算离群点损失;
34、根据所述三元损失和所述离群点损失,采用反向传播算法,对所述歌曲识别网络模型的参数进行修正。
35、作为一种可选的实施例,在根据所述每个训练组中目标歌曲的原唱版本的特征向量、多个翻唱版本的特征向量和所述其他歌曲的特征向量,确定三元损失之后,所述方法还包括:
36、获取所述歌曲识别网络模型在每个训练组中输出的目标歌曲和其他歌曲的真实样本标签,及所述真实样本标签的概率值;
37、基于第二公式计算多个训练组的分类损失;
38、所述第二公式包括:其中,yc表示真实样本标签,f(zc)表示真实样本标签的概率值,k表示样本标签的数量,c表示样本标签数量的最大值;
39、基于每个训练组中的野点、离群点、所述三元损失和所述分类损失,对所述歌曲识别网络模型的参数进行修正。
40、作为一种可选的实施例,基于每个训练组中的野点、离群点、所述三元损失和所述分类损失,对所述歌曲识别网络模型的参数进行修正,包括:
41、删除每个训练组中的所述野点;
42、根据多个训练组中的每个训练组的所述离群点,计算离群点损失;
43、根据所述离群点损失、所述三元损失和所述分类损失,采用反向传播算法,对所述歌曲识别网络模型的参数进行修正。
44、作为一种可选的实施例,基于每个训练组中的野点、离群点、所述三元损失和所述分类损失,对所述歌曲识别网络模型的参数进行修正,包括:
45、删除每个训练组中的野点和离群点;
46、根据所述三元损失和所述分类损失,采用反向传播算法,对所述歌曲识别网络模型的参数进行修正。
47、作为一种可选的实施例,基于每个训练组中的野点、离群点、所述三元损失和所述分类损失,对所述歌曲识别网络模型的参数进行修正,包括:
48、删除每个训练组中的野点;
49、选取同一训练组中的两个离群点,作为所述训练组下一轮训练的目标歌曲的原唱版本和目标歌曲的翻唱版本;
50、根据多个训练组中的每个训练组的所述离群点,计算离群点损失;
51、根据所述三元损失、所述离群点损失和所述分类损失,采用反向传播算法,对所述歌曲识别网络模型的参数进行修正。
52、作为一种可选的实施例,所述频谱特征包括常q变化特征和梅尔频率倒谱系数中的任一个。
53、作为一种可选的实施例,在将每个训练组中歌曲的频谱特征输入至歌曲识别网络模型之后,所述方法还包括:
54、利用ibn归一化层对所述歌曲识别网络模型的参数进行优化,其中,bn层用于在多个训练组的维度上对所述歌曲识别网络模型的参数进行归一化,ibn层用于在单个样本维度上对所述歌曲识别网络模型的参数进行归一化。
55、本技术实施例第二方面提供了一种翻唱歌曲识别方法,所述方法包括:
56、将待识别歌曲输入至本技术实施例第一方面提供的歌曲识别网络模型中;
57、获取所述歌曲识别网络模型输出的所述待识别歌曲的歌曲名称和所述待识别歌曲的种类,其中,所述待识别歌曲的种类包括原唱版本和翻唱版本。
58、本技术实施例第三方面提供了一种计算机装置,包括处理器,所述处理器在执行存储于存储器上的计算机程序时,用于实现本技术实施例第一方面提供的歌曲识别网络的训练方法,或本技术实施例第二方面提供的翻唱歌曲的识别方法。
59、本技术实施例第四方面提供了一种计算机可读存储介质,其上存储有计算机程序,所述计算机程序被处理器执行时,用于实现本技术实施例第一方面提供的歌曲识别网络的训练方法,或本技术实施例第二方面提供的翻唱歌曲的识别方法。
60、从以上技术方案可以看出,本发明实施例具有以下优点:
61、获取多个训练组的频谱特征,其中,每个训练组包括目标歌曲的原唱版本的频谱特征和目标歌曲对应的多个翻唱版本的频谱特征;将每个训练组中歌曲的频谱特征输入至所述歌曲识别网络模型,以得到所述歌曲识别网络模型输出的每个训练组中目标歌曲原唱版本的特征向量和多个翻唱版本的特征向量;根据所述每个训练组中目标歌曲原唱版本的特征向量、多个翻唱版本的特征向量和预设的第一阈值和第二阈值,确定所述每个训练组中目标歌曲翻唱版本的野点和离群点,其中,所述野点用于表征所述翻唱版本的特征向量与中心点之间的距离大于所述第二阈值的翻唱版本,所述离群点用于表征所述翻唱版本的特征向量与所述中心点之间的距离大于所述第一阈值且小于所述第二阈值的翻唱版本,其中,所述第二阈值大于所述第一阈值,所述中心点表示所述每个训练组中目标歌曲原唱版本的特征向量和多个翻唱版本的特征向量的均值;基于多个训练组中的野点和离群点,对所述歌曲识别网络模型的参数进行修正。
62、因为本技术实施例在采用目标歌曲的翻唱版本对歌曲识别网络进行训练时,可以识别目标歌曲翻唱版本中的离群点和野点,并基于离群点和野点,对歌曲识别网络进行训练,从而提升歌曲识别网络对翻唱歌曲识别的准确率。
- 还没有人留言评论。精彩留言会获得点赞!