音频生成方法、声码器、电子设备及存储介质与流程
本技术涉及音频处理,具体地涉及一种音频生成方法、声码器、电子设备及存储介质。
背景技术:
1、目前常用的声码器主要分为两大类:传统声码器和神经网络型可学习声码器。常用的传统声码器主要有griffin-lim声码器和world声码器,常用神经网络声码器主要有hifigan、melgan等gan类声码器。
2、传统声码器重建的语音信号较差,尤其针对歌声,机器感太强,听感生硬,音质较差。神经网络可学习声码器普遍都是针对普通语音的,输出的语音音质还原度比较高,但是对于训练集外的人声还原能力较差,生成的歌声电音感较强,自然度不够,人工痕迹明显,存在明显的伪声。
3、本背景技术描述的内容仅为了便于了解本领域的相关技术,不视作对现有技术的承认。
技术实现思路
1、因此,本技术实施例意图提供一种音频生成方法电子设备及存储介质,以解决音频音质较差,自然度不够的问题。
2、在第一方面,提供了一种音频生成方法,所述音频生成方法由神经网络型声码器实施,所述神经网络型声码器包括基频提取模块、波发生模块和生成器网络模块,所述音频生成方法包括:
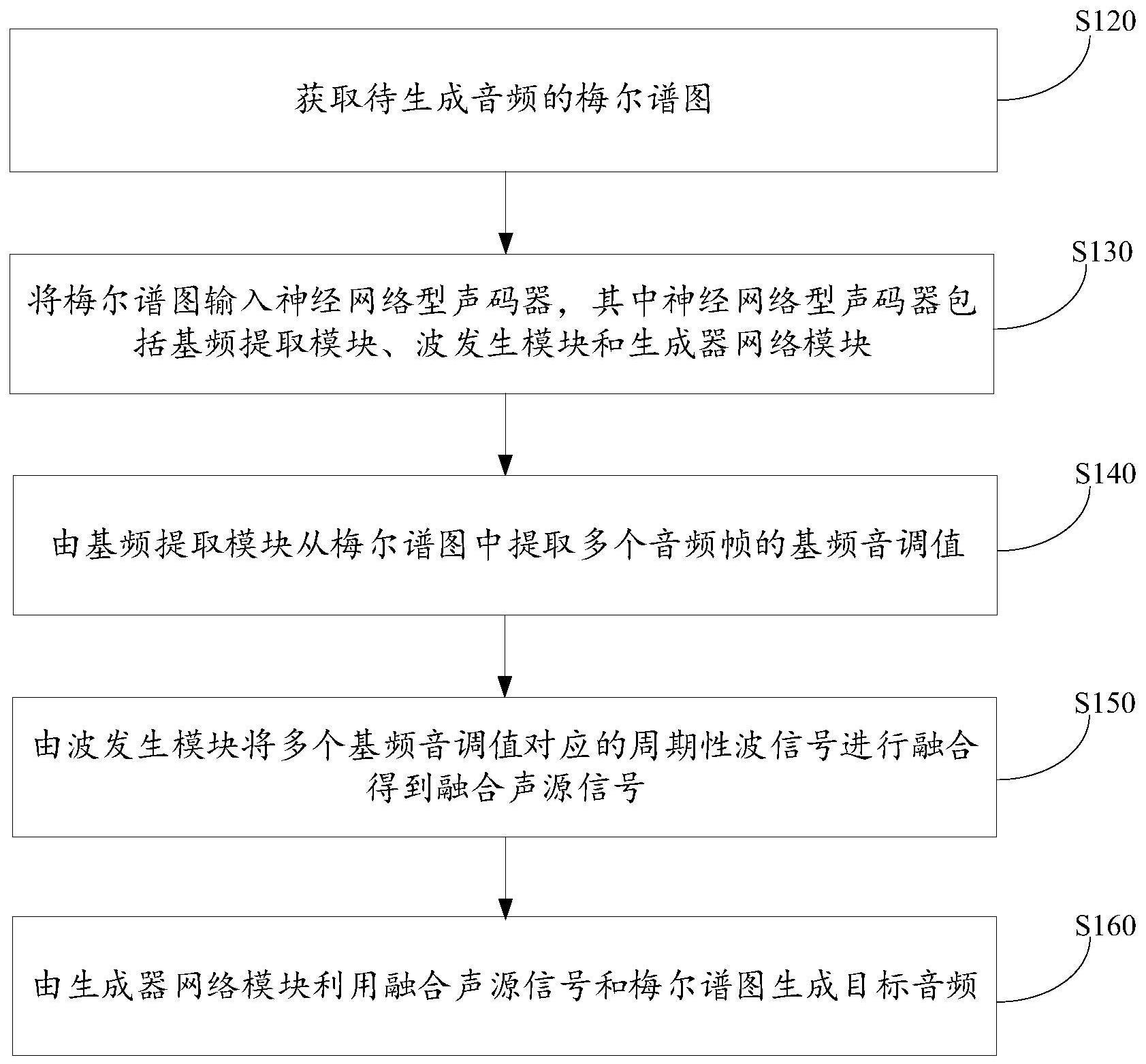
3、获取待生成音频的梅尔谱图;
4、由所述基频提取模块从所述梅尔谱图中提取多个音频帧的基频音调值;
5、由所述波发生模块将多个所述基频音调值对应的周期性波信号进行融合得到融合声源信号;
6、由所述生成器网络模块利用融合声源信号和梅尔谱图生成目标音频。
7、在一些可选的实现方式中,所述基频提取模块包括划分子模块、梅尔预测网络子模块、梅尔编码子模块和音调预测子模块;
8、所述由所述基频提取模块从所述梅尔谱图中提取多个音频帧的基频音调值,包括:
9、由所述梅尔谱划分子模块将所述梅尔谱图划分为多帧子图;
10、由所述梅尔预测网络子模块对每一帧所述子图进行卷积,生成第一中间音调值;
11、由所述梅尔编码子模块对所述第一中间音调值进行卷积和归一化处理,生成第二中间音调值;
12、由所述音调预测子模块对所述第二中间音调值进行卷积、激活和归一化处理,得到多个基频音调值。
13、在一些可选的实现方式中,所述波发生模块包括周期性波发生器子模块和源过滤子网络;
14、所述由所述波发生模块将多个所述基频音调值对应的周期性波信号进行融合得到融合声源信号,包括:
15、由所述周期性波发生器子模块生成各个所述基频音调值分别对应的周期性波信号;以及由所述源过滤子网络融合所述周期性波信号,得到所述融合声源信号。
16、在一些可选的实现方式中,所述生成器网络模块包括频段切分子模块、波网子模块及频段合成子模块,
17、所述由所述生成器网络模块利用融合声源信号和梅尔谱图生成目标音频,包括:
18、由所述频段切分子模块对所述融合声源信号进行频段切分,得到至少两个第一频段信号;
19、针对各个所述第一频段信号,将所述第一频段信号和所述梅尔谱图输入双输入波网模块的所述波网子模块,得到第二频段信号;
20、将各个所述第二频段信号输入所述频段合成子模块,合成所述目标音频。
21、在一些可选的实现方式中,所述将所述第一频段信号和所述梅尔谱图输入双输入波网模块的所述波网子模块,得到第二频段信号,包括:
22、将所述第一频段信号输入双输入波网模块的空洞卷积层以得到至少两个第一子频段;
23、将所述梅尔谱图输入双输入波网模块的1x1卷积层以得到至少两个子梅尔谱图;
24、将各第一子频段与各子梅尔谱图合并输入到至少两个激活函数以得到至少两个中间音频;
25、将所述至少两个中间音频叉乘输入1x1卷积层以得到所述第二频段信号。
26、在一些可选的实现方式中,所述频段切分子模块为多相正交镜像过滤器(pqmf)分解模块;频段合成子模块为多相正交镜像过滤器(pqmf)合成模块;
27、由所述频段切分子模块对所述融合声源信号进行频段切分,得到至少两个第一频段信号,包括:利用所述多相正交镜像过滤器(pqmf)分解模块对所述融合声源信号进行频段滤波得到位于不同频段的所述第一频段信号;
28、将各个所述第二频段信号输入所述频段合成子模块,合成所述目标音频,包括:利用多相正交镜像过滤器(pqmf)合成模块对所述第二频段信号进行频段叠加以合成所述目标音频。
29、在一些可选的实现方式中,所述获取待生成音频的梅尔谱图,包括:
30、获取对应目标音频的目标乐谱信息;
31、从所述目标乐谱信息中确定目标歌词音素序列和目标乐理特征;
32、将所述目标歌词音素序列和所述目标乐理特征输入训练好的声学模型,得到所述待生成音频的梅尔谱图。
33、在一些可选的实现方式中,由生成式对抗网络进行训练得到所述声码器,其音频生成方法还包括:
34、构建生成式对抗网络,所述生成式对抗网络包括生成器和判别器;
35、从样本音频信号提取带有样本音频特征的训练用梅尔谱图;
36、将所述训练用梅尔谱图输入所述生成式对抗网络的生成器,通过所述生成器对所述样本音频特征进行处理,得到所述样本音频特征对应的处理音频信号;
37、将所述处理音频信号和所述原始音频信号发送至所述判别器,以使所述判别器分别对所述处理音频信号和所述原始音频信号进行判别,得到判别结果;
38、利用确定损失函数,根据所述判别结果迭代更新所述生成式对抗网络以对其进行训练,直至训练完成;
39、利用训练好的生成式对抗网络的生成器的训练好的参数构建所述神经网络型声码器;
40、其中,所述生成器包括待训练的基频提取网络模块、待训练的波生成网络模块和待训练的生成器网络模块。
41、在一些可选的实现方式中,所述判别器包括多个并行判别器。
42、在一些可选的实现方式中,多个并行判别器包括多尺度判别器、多周期判别器和由预设数量的空洞卷积层组成的判别器。
43、在第二方面,提供一种神经网络型声码器,包括:
44、基频提取模块,配置成从梅尔谱图中提取多个基频音调值;
45、波发生模块,配置成生成所述多个基频音调值对应的融合声源信号;以及
46、生成器网络模块,配置成由共同输入的所述融合声源信号和梅尔谱图生成目标音频。
47、第三方面,提供了一种电子设备,包括:处理器和存储有计算机程序的存储器,所述处理器被配置为在运行计算机程序时实现本公开第一方面及其任一实现方式中的音频生成方法。
48、第四方面,提供了一种存储介质,其上存储有计算机程序,其中,所述程序被处理器运行时实现本公开第一方面及其任一实现方式中的音频生成方法。
49、本技术实施例使用的音频生成方法,通过使用经改造的神经网络型声码器、尤其是经改造的生成式对抗网络的声码器,通过基频提取模块从梅尔谱图中提取多个基频音调值;由所述波发生模块将多个所述基频音调值对应的周期性波信号进行融合得到融合声源信号;由所述生成器网络模块利用融合声源信号和梅尔谱图生成目标音频。相比于当前的神经网络可学习声码器,本技术实施例的音频生成方法使用声源信号和梅尔谱图共同生成目标信号,能够丰富谐波细节,尤其使得高频谐波更丰富,且音色还原度更高,声音更明亮,进而能够提高音频音质和自然度。
50、本技术实施例的其他可选特征和技术效果一部分在下文描述,一部分可通过阅读本文而明白。
- 还没有人留言评论。精彩留言会获得点赞!