音频处理方法、装置、电子设备及可读存储介质与流程
本申请属于人工智能,具体涉及一种音频处理方法、装置、电子设备及可读存储介质。
背景技术:
1、目前,对于语音通信、语音唤醒、语音识别、声音识别等语音通信和语音智能交互等场景得到的语音音频,电子设备通常可以通过语音增强技术从噪声背景中提取有用的语音信号,并抑制、降低噪声的干扰,从而提升所得到的语音的质量。
2、然而,传统的音频降噪算法依赖硬件设计及其配套算法,使得降噪方式单一,从而导致音频处理的效果较差。
技术实现思路
1、本申请实施例的目的是提供一种音频处理方法、装置、电子设备及可读存储介质,能够提高音频处理的效果。
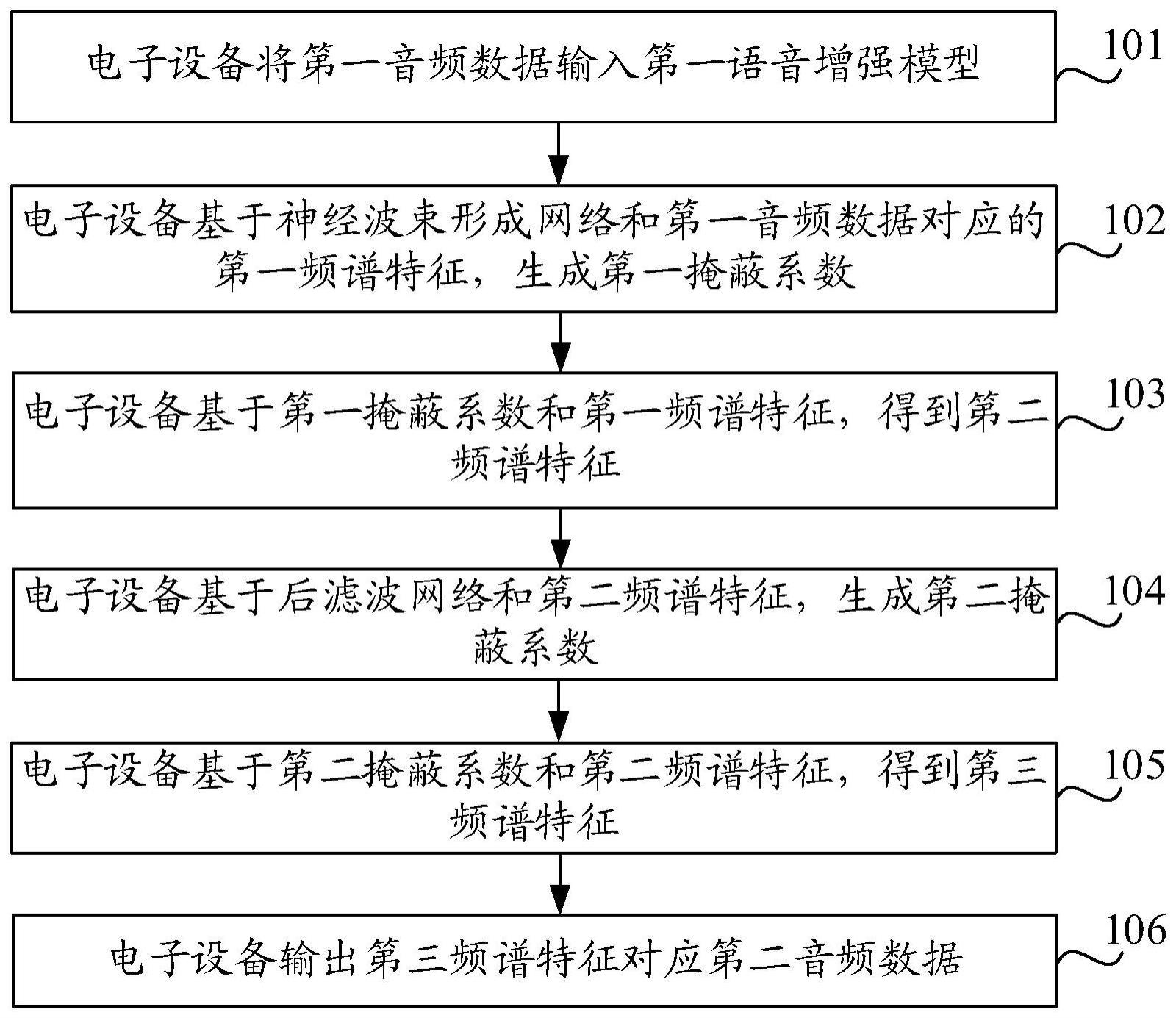
2、第一方面,本申请实施例提供了一种音频处理方法,该方法包括:将第一音频数据输入第一语音增强模型,第一语音增强模型包括神经波束形成网络和后滤波网络;基于神经波束形成网络和第一音频数据对应的第一频谱特征,生成第一掩蔽系数;基于第一掩蔽系数和第一频谱特征,得到第二频谱特征,第二频谱特征的信噪比大于第一频谱特征的信噪比;基于后滤波网络和第二频谱特征,生成第二掩蔽系数;基于第二掩蔽系数和第二频谱特征,得到第三频谱特征,第三频谱特征的信噪比大于第二频谱特征的信噪比;输出第三频谱特征对应的第二音频数据,第二音频数据的信噪比大于第一音频数据。
3、第二方面,本申请实施例提供了一种音频处理装置,该装置包括:输入模块、处理模块和输出模块;输入模块,用于将第一音频数据输入第一语音增强模型,第一语音增强模型包括神经波束形成网络和后滤波网络;处理模块,用于基于神经波束形成网络和输入模块输入的第一音频数据对应的第一频谱特征,生成第一掩蔽系数;处理模块,还用于基于第一掩蔽系数和第一频谱特征,得到第二频谱特征,第二频谱特征的信噪比大于第一频谱特征的信噪比;处理模块,还用于基于后滤波网络和第二频谱特征,生成第二掩蔽系数;处理模块,还用于基于第二掩蔽系数和第二频谱特征,得到第三频谱特征,第三频谱特征的信噪比大于第二频谱特征的信噪比;输出模块,用于输出处理模块得到的第三频谱特征对应的第二音频数据,第二音频数据的信噪比大于第一音频数据。
4、第三方面,本申请实施例提供了一种电子设备,该电子设备包括处理器和存储器,所述存储器存储可在所述处理器上运行的程序或指令,所述程序或指令被所述处理器执行时实现如第一方面所述的方法的步骤。
5、第四方面,本申请实施例提供了一种可读存储介质,所述可读存储介质上存储程序或指令,所述程序或指令被处理器执行时实现如第一方面所述的方法的步骤。
6、第五方面,本申请实施例提供了一种芯片,所述芯片包括处理器和通信接口,所述通信接口和所述处理器耦合,所述处理器用于运行程序或指令,实现如第一方面所述的方法。
7、第六方面,本申请实施例提供一种计算机程序产品,该程序产品被存储在存储介质中,该程序产品被至少一个处理器执行以实现如第一方面所述的方法。
8、在本申请实施例中,将第一音频数据输入第一语音增强模型,第一语音增强模型包括神经波束形成网络和后滤波网络;基于神经波束形成网络和第一音频数据对应的第一频谱特征,生成第一掩蔽系数;基于第一掩蔽系数和第一频谱特征,得到第二频谱特征,第二频谱特征的信噪比大于第一频谱特征的信噪比;基于后滤波网络和第二频谱特征,生成第二掩蔽系数;基于第二掩蔽系数和第二频谱特征,得到第三频谱特征,第三频谱特征的信噪比大于第二频谱特征的信噪比;输出第三频谱特征对应的第二音频数据,第二音频数据的信噪比大于第一音频数据。在该方案中,通过在语音增强模型中增加神经波束形成网络和后滤波网络,从而可以通过神经波束形成网络,获取第一音频数据对应的第一频谱特征中噪声的掩蔽系数,以对第一频谱特征进行一次降噪,得到第二频谱特征。并且还可以通过后滤波网络,获取第二频谱特征中噪声的掩蔽系数,以对第二频谱特征再次进行降噪,如此,通过两次降噪可以大幅度地降低语音增强模型输出的音频数据中噪声的干扰,从而可以提高对音频数据的质量与降噪的效果,进而可以提高音频处理的效果。
技术特征:
1.一种音频处理方法,其特征在于,所述方法包括:
2.根据权利要求1所述的方法,其特征在于,所述第一音频数据包括n个子音频数据,每个子音频数据对应一个音频通道,n为大于1的正整数;
3.根据权利要求1所述的方法,其特征在于,所述基于所述神经波束形成网络和所述第一音频数据对应的第一频谱特征,生成第一掩蔽系数之前,所述方法还包括:
4.根据权利要求3所述的方法,其特征在于,所述第一音频数据包括n个子音频数据,n为大于1的正整数;
5.根据权利要求1所述的方法,其特征在于,所述后滤波网络包括第一网络层和第二网络层;
6.根据权利要求1所述的方法,其特征在于,所述将第一音频数据输入第一语音增强模型之前,所述方法还包括:
7.一种音频处理装置,其特征在于,所述装置包括:输入模块、处理模块和输出模块;
8.根据权利要求7所述的装置,其特征在于,所述第一音频数据包括n个子音频数据,每个子音频数据对应一个音频通道,n为大于1的正整数;
9.根据权利要求7所述的装置,其特征在于,所述处理模块,还用于在基于所述神经波束形成网络和所述第一音频数据对应的第一频谱特征,生成第一掩蔽系数之前,对所述第一音频数据进行短时傅里叶变换,得到所述第一音频数据对应的第一频谱特征;
10.根据权利要求9所述的装置,其特征在于,所述处理模块,具体用于分别对每个所述子音频数据进行短时傅里叶变换,得到每个所述子音频数据对应的子频谱特征,并拼接所述每个所述子音频数据对应的子频谱特征,得到所述第一频谱特征。
11.根据权利要求7所述的装置,其特征在于,所述后滤波网络包括第一网络层和第二网络层;
12.根据权利要求7所述的装置,其特征在于,所述装置还包括:获取模块;
13.一种电子设备,其特征在于,包括处理器和存储器,所述存储器存储可在所述处理器上运行的程序或指令,所述程序或指令被所述处理器执行时实现如权利要求1至6任一项所述的音频处理方法的步骤。
14.一种可读存储介质,其特征在于,所述可读存储介质上存储程序或指令,所述程序或指令被处理器执行时实现如权利要求1至6任一项所述的音频处理方法的步骤。
技术总结
本申请公开了一种音频处理方法、装置、电子设备及可读存储介质,属于人工智能技术领域,该方法包括:将第一音频数据输入第一语音增强模型,第一语音增强模型包括神经波束形成网络和后滤波网络;基于神经波束形成网络和第一音频数据对应的第一频谱特征,生成第一掩蔽系数;基于第一掩蔽系数和第一频谱特征,得到第二频谱特征,第二频谱特征的信噪比大于第一频谱特征的信噪比;基于后滤波网络和第二频谱特征,生成第二掩蔽系数;基于第二掩蔽系数和第二频谱特征,得到第三频谱特征,第三频谱特征的信噪比大于第二频谱特征的信噪比;输出第三频谱特征对应的第二音频数据,第二音频数据的信噪比大于第一音频数据。
技术研发人员:李星
受保护的技术使用者:维沃移动通信有限公司
技术研发日:
技术公布日:2024/1/15
- 还没有人留言评论。精彩留言会获得点赞!