一种基于语音理解的短视频自动生成字幕的方法及系统与流程
本发明涉及自然语言处理领域,具体来说,尤其涉及一种基于语音理解的短视频自动生成字幕的方法及系统。
背景技术:
1、短视频是一种在各种新媒体平台上广泛分享和播放的内容形式,特别适合在移动设备上观看,以满足人们在短暂的休闲时间内的娱乐需求。这种类型的视频通常时长不超过五分钟,自2016年以来,通过其易于创作、强社交特性和碎片化的娱乐性质,已经在中国乃至全球范围内流行开来。短视频已经成为了网红记录和分享生活的主要手段,也为观众提供了娱乐和发现新事物的新方式。它甚至还被用作品牌推广,也为独立创作者提供了利益来源。
2、短视频的制作包括内容策划、视频拍摄和后期处理等步骤。其中,字幕生成是后期处理的重要部分,通常需要作者手动完成,这个过程可能会消耗大量的时间和精力。尽管当前市场上存在一些可以自动生成字幕的软件,但这些软件主要依赖视频中的音频信息。如果视频中没有清晰的音频信息,这些软件就无法提取出文字。在实际生活中,普通用户可能希望通过短视频记录生活,但他们可能会觉得边拍摄边解说很尴尬。如果选择在拍摄后再录制音频,又会回到初始的时间和精力消耗问题。因此,对于没有音频背景的短视频,如何自动生成字幕是一个待解决的问题。
3、文本生成技术在许多场景中都有广泛的应用,包括信息提取、问答系统、文字创作等任务。例如,问答系统使得聊天机器人的出现成为可能,文字创作使得机器人能够编写歌词和作曲。同时,跨模态的文本生成也是近年来的研究热点。跨模态技术需要结合图像、音频和语言处理技术。常见的应用包括“看图说话”以及为教学视频自动生成字幕等。
4、目前的语音识别和语义理解模型存在一些关键的问题和局限性;首先,这两个模型的训练过程是独立的,这使得语音特征无法共享,且语音与语义之间的对应关系建模较弱;同时,语音识别作为中间监督信号的潜力并没有被充分利用,导致语音编码器对语音序列的建模能力不足;此外,这两个模型的评估指标体系不同,造成优化目标不清晰;训练流程的复杂性也使得模型的部署和使用变得困难;基于rnn的解码器在建模语音和语义的长程依赖关系方面也存在问题;同时,用户交互界面简单,用户体验较差,无法实现自动学习和优化;字幕渲染和结果展示方式单一,缺乏可读性和趣味性;最后,模型的自定义选项有限,无法满足不同用户的个性化需求。
5、针对相关技术中的问题,目前尚未提出有效的解决方案。
技术实现思路
1、为了克服以上问题,本发明旨在提出一种基于语音理解的短视频自动生成字幕的方法及系统,目的在于解决目前的语音识别和语义理解模型存在一些关键的问题和局限性的问题。
2、为此,本发明采用的具体技术方案如下:
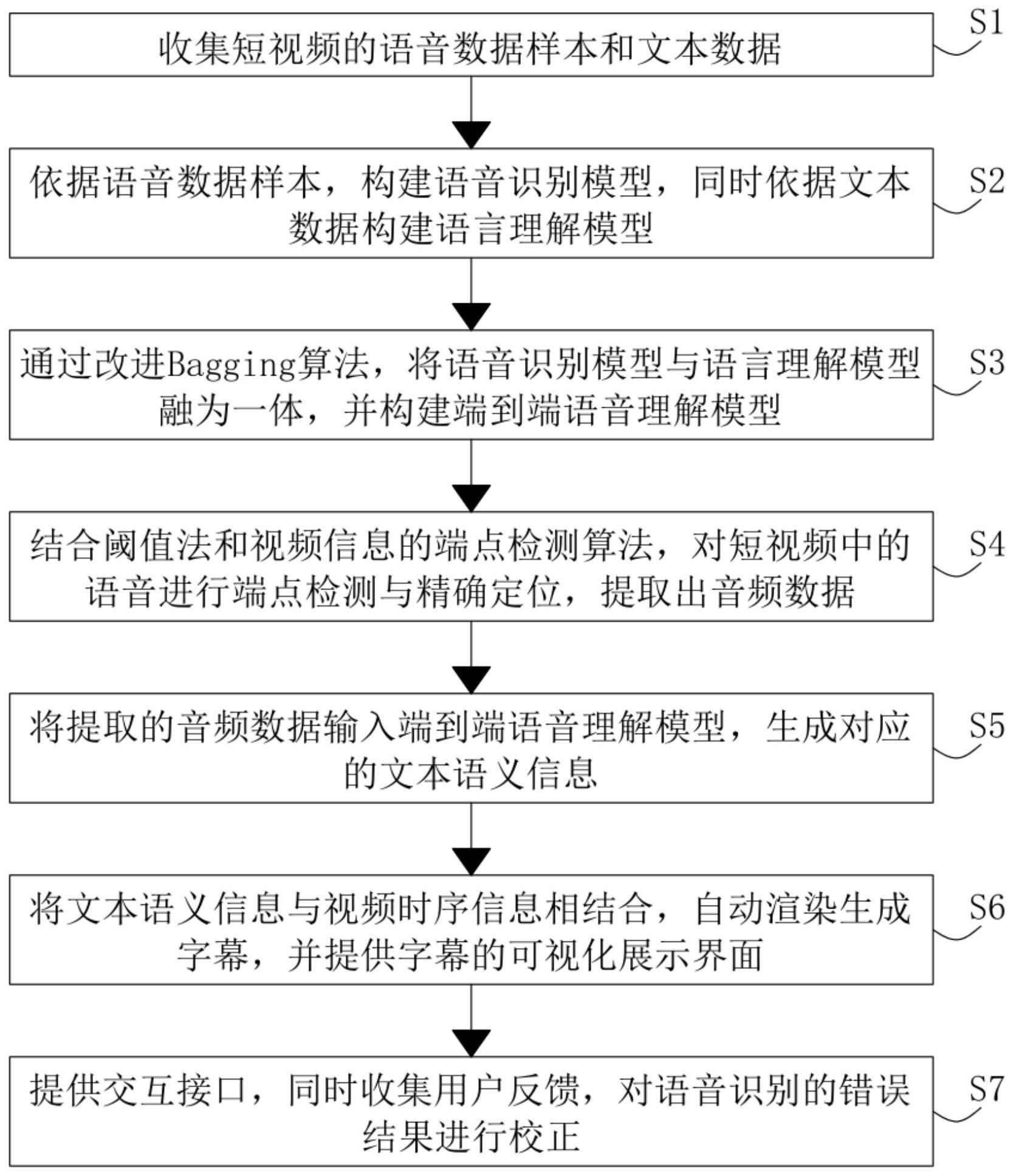
3、根据本发明的一个方面,提供了一种基于语音理解的短视频自动生成字幕的方法,该短视频自动生成字幕的方法包括以下步骤:
4、s1、收集短视频的语音数据样本和文本数据;
5、s2、依据语音数据样本,构建语音识别模型,同时依据文本数据构建语言理解模型;
6、s3、通过改进bagging算法,将语音识别模型与语言理解模型融为一体,并构建端到端语音理解模型;
7、s4、结合阈值法和视频信息的端点检测算法,对短视频中的语音进行端点检测与精确定位,提取出音频数据;
8、s5、将提取的音频数据输入端到端语音理解模型,生成对应的文本语义信息;
9、s6、将文本语义信息与视频时序信息相结合,自动渲染生成字幕,并提供字幕的可视化展示界面;
10、s7、提供交互接口,同时收集用户反馈,对语音识别的错误结果进行校正。
11、可选地,收集短视频的语音数据样本和文本数据包括以下步骤:
12、s11、从视频分享网站的公开渠道收集覆盖不同场景、话题的短视频;
13、s12、对收集的短视频进行处理,提取音频轨道,获取语音数据样本;
14、s13、对语音数据样本进行分割,获取语音段,并对语音段进行标注;
15、s14、从网络资源和电子书籍收集海量不同题材、风格的文本数据;
16、s15、对文本数据进行处理,并建文本语料库;
17、s16、从文本语料库中抽取句子,标注句法结构,构建文本训练数据集。
18、可选地,依据语音数据样本,构建语音识别模型,同时依据文本数据构建语言理解模型包括以下步骤:
19、s21、基于标注的语音段,构建语音识别模型;
20、s22、通过迁移学习法优化语音识别模型的参数,提升语音识别的准确率;
21、s23、基于文本训练数据集,构建语言理解模型;
22、s24、通过迁移学习法优化语言理解模型对指定领域的适应性;
23、s25、评估语音识别模型和语言理解模型的性能,并进行迭代优化。
24、可选地,通过改进bagging算法,将语音识别模型与语言理解模型融为一体,并构建端到端语音理解模型包括以下步骤:
25、s31、对语音数据进行特征提取,获取语音特征矩阵;
26、s32、对文本数据进行词汇编码,获取文本特征矩阵;
27、s33、基于语音特征矩阵和文本特征矩阵,使用灰色关联投影法计算语音特征和文本特征之间的关联度,选择关联度最高的语音样本与文本样本对作为训练样本;
28、s34、使用botstrap算法对训练样本进行抽样,生成子集,并利用子集训练基学习器;
29、s35、在子集上训练连接了语音编码器和文本解码器的端到端语音理解模型,获得训练好的基学习器;
30、s35、对新输入的语音样本,利用训练好的基学习器进行语音理解,并通过模型融合获得最终理解结果。
31、可选地,基于语音特征矩阵和文本特征矩阵,使用灰色关联投影法计算语音特征和文本特征之间的关联度,选择关联度最高的语音样本与文本样本对作为训练样本包括以下步骤:
32、s331、计算语音特征矩阵和文本特征矩阵之间的关联度,获得关联度矩阵;
33、s332、对新输入的语音特征向量,计算语音特征向量与语音特征矩阵中各语音特征向量的关联度,获得关联度向量;
34、s333、通过关联度向量在文本特征矩阵中的投影,获得语音特征向量与各文本特征的关联度;
35、s334、选择与语音特征向量关联度最高的文本特征向量作为训练样本;
36、s335、重复步骤s331至s334的步骤,获取全部的语音与文本训练样本对;
37、s336、使用语音与文本训练样本对训练端到端语音理解模型。
38、可选地,使用botstrap算法对训练样本进行抽样,生成子集,并利用子集训练基学习器包括以下步骤:
39、s341、获取语音与文本训练样本,并设置基学习器数量;
40、s342、使用botstrap算法从训练样本中进行有放回随机采样,获得大小与原训练样本相等的子集;
41、s343、重复执行s341至s342的步骤,并获得多个大小相等的子集;
42、s344、利用子集分别训练语音编码器模型和文本解码器模型,并连接为基学习器;
43、s345、利用基学习器对语音样本进行编码、解码和融合,输出文本。
44、可选地,结合阈值法和视频信息的端点检测算法,对短视频中的语音进行端点检测与精确定位,提取出音频数据包括以下步骤:
45、s41、提取音频数据的短时帧特征,计算音频能量和过零率作为音频端点置信度;
46、s42、通过视频人脸识别和口型识别算法计算视频端点置信度;
47、s43、将音频端点置信度和视频端点置信度输入端点检测模型;
48、s44、端点检测模型融合音视频信息,输出端点概率;
49、s45、根据端点概率,确定端点初步位置;
50、s46、在端点附近进行阈值调整,精确定位终点,并提取音频数据。
51、可选地,将提取的音频数据输入端到端语音理解模型,生成对应的文本语义信息包括以下步骤:
52、s51、获取音频数据,并对音频数据进行帧块化,提取音频特征;
53、s52、将音频特征输入到端到端语音理解模型的语音编码器中;
54、s53、语音编码器使用卷积神经网络进行语音序列建模,输出语音的高级特征表示;
55、s54、将语音高级特征表示输入到集成注意力机制的解码器模块;
56、s55、解码器模块使用trans former网络对语音特征进行语义解码,并通过注意力机制捕捉语音特征和输出语义之间的相关性,输出文本描述结果;
57、s56、对文本描述结果进行格式化处理,获得文本语义信息,并将文本语义信息与原音频序列对齐,得到语音对应的语义文本。
58、可选地,解码器模块使用trans former网络对语音特征进行语义解码,并通过注意力机制捕捉语音特征和输出语义之间的相关性,输出文本描述结果包括以下步骤:
59、s551、初始化trans former网络的解码器模型;
60、s552、将语音编码器输出的语音高级特征表示序列作为解码器模型的输入;
61、s553、在解码器模型的多头自注意力模块中,计算输入语音特征的多头自注意力,学习语音特征的内部关联;
62、s554、在解码器模型的多头交叉注意力模块中,计算语音特征与输出语义的多头交叉注意力,学习两者之间的相关性;
63、s555、通过前馈全连接层生成输出语义的高级语义特征表示;
64、s556、对高级语义特征表示进行softmax分类,预测输出语义标签;
65、s557、重复执行s553-s556的步骤,直到输出完全的语义标签;
66、s558、对语义标签的输出结果进行处理,生成格式化的文本描述。
67、根据本发明的另一个方面,还提供了一种基于语音理解的短视频自动生成字幕的系统,该系统包括:数据采集模块、模型构建模块、模型融合模块、语音分割模块、语音理解模块、字幕渲染模块及交互反馈模块;
68、数据采集模块,用于收集短视频的语音数据样本和文本数据;
69、模型构建模块,用于依据语音数据样本,构建语音识别模型,同时依据文本数据构建语言理解模型;
70、模型融合模块,用于通过改进bagging算法,将语音识别模型与语言理解模型融为一体,并构建端到端语音理解模型;
71、语音分割模块,用于结合阈值法和视频信息的端点检测算法,对短视频中的语音进行端点检测与精确定位,提取出音频数据;
72、语音理解模块,用于将提取的音频数据输入端到端语音理解模型,生成对应的文本语义信息;
73、字幕渲染模块,用于将文本语义信息与视频时序信息相结合,自动渲染生成字幕,并提供字幕的可视化展示界面;
74、交互反馈模块,用于提供交互接口,同时收集用户反馈,对语音识别的错误结果进行校正。
75、相较于现有技术,本技术具有以下有益效果:
76、1、本发明共享语义表示,两任务互促进,语音编码器提取的语义特征可同时服务于语音识别和语言理解任务,两任务在统一模型中进行联合优化,相互促进;引入语音识别作为中间监督信号,帮助语音序列建模,语音识别作为辅助任务,其训练可以指导语音编码器学习对语音序列的建模,从而增强语音理解模型的语音分析能力;加强语音与语义的对应关系建模,加入语音和语义一致性的监督,可以直接优化语音理解的效果。
77、2、本发明采用动态权重调整,平衡不同任务,根据各任务指标动态调整权重,使其协同训练,防止过度偏向任一任务;提供端到端的语音理解框架,无需独立训练语音识别和语言理解模型,直接端到端训练,简化流程;统一的评估指标体系,可以关注语音识别准确率、语义理解效果等指标,全面评估系统效果。
78、3、本发明利用了trans former的并行计算结构,计算效率高,其多头注意力机制可以高效模拟语音和语义之间的相关性,多头注意力机制可以同时学习语音的不同语义解释,增强模型的语义建模能力,编码器与解码器结构可以充分利用语音特征,进行顺序语义解码,适合语音理解任务,相比rnn等循环结构,trans former对长距离依赖建模更强,可以捕捉语音和语义之间的长程关联,基于大量语音语义标注数据进行预训练,使得模型更好地适配语音理解任务,可以进行多任务学习,同时完成语音识别和语言理解,相互促进,注意力机制可以关注语音关键词与语义关键词之间的相关性,实现精确语音理解,模型参数可以进行微调,快速适配不同领域的语音理解应用。
79、4、本发明提高了结果的可读性和可理解性,如生成简洁的字幕、增加情感标注等,这提升了用户的使用体验,拓展了系统的应用范围,如支持多语言翻译,这使产品适用群体更广,提高了交互效率,如支持语音反馈、提供候选结果等,这减轻了用户工作量,增强了系统的智能性,如分析用户修改模式进行模型优化,这实现了自动学习和优化,让交互过程更友好,如文字标注、流程引导等,这提升了用户体验,提供了自定义选项,如调整字幕格式、交互方式等,这满足了不同用户的个性化需求。
- 还没有人留言评论。精彩留言会获得点赞!