端到端音频隐写方法、系统、存储介质及电子设备
本发明涉及音频处理,具体涉及一种端到端音频隐写方法、系统、存储介质及电子设备。
背景技术:
1、随着因特网的普及、信息处理技术和通信手段的飞速发展,信息隐藏和隐藏分析技术在信息安全中的作用越来越受到人们的关注。其中,音频隐写术是一种将秘密信息隐藏在普通的、非秘密的、可运行的音频文件中的技术。
2、现有的音频隐写术主要是通过音频的时域特征设计算法,使用生成载体修改向量的方式达到隐写的目的。然而,该方法容易导致网络模型退化,不利于模型稳定训练,导致隐写的稳定性差。
技术实现思路
1、(一)解决的技术问题
2、针对现有技术的不足,本发明提供了一种端到端音频隐写方法、系统、存储介质及电子设备,解决了现有的音频隐写方法稳定性差的技术问题。
3、(二)技术方案
4、为实现以上目的,本发明通过以下技术方案予以实现:
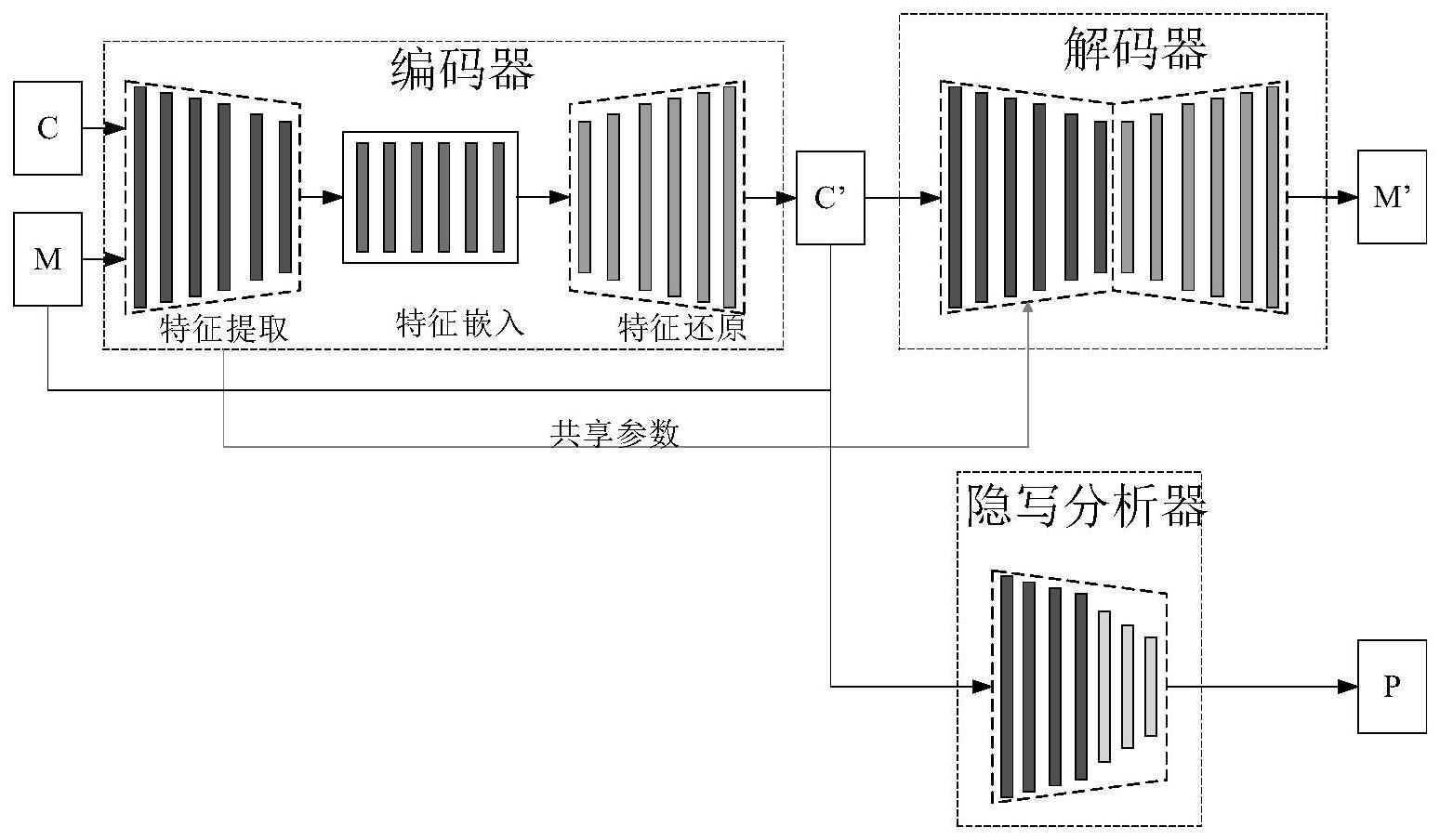
5、第一方面,本发明提供一种端到端音频隐写方法,采用生成对抗网络预先构建编码器和隐写分析器,根据编码器预先构建解码器,所述端到端音频隐写方法包括:
6、s1、获取秘密音频和载体音频,并通过预先训练的编码器对秘密音频和载体音频进行处理,输出载密音频;
7、s2、通过解码器对载密音频进行解密处理,输出秘密音频的估计音频;
8、其中,通过循环自编码器进行生成对抗网络预训练,确定编码器中特征提取模块和特征还原模块的参数。
9、优选的,所述特征提取模块用于提取并联合秘密音频时间依赖特征和载体音频时间依赖特征,得到时间依赖特征;
10、所述特征提取模块包括依次连通的6个convblock和1个拼接层,其中,第一个convblock的输入通道数1,输出通道数64和卷积核大小为3×3,第二个convblock的输入通道数64,输出通道数64和卷积核大小为1×3,第三个convblock的输入通道数64,输出通道数128和卷积核大小为1×3,第四个convblock的输入通道数128,输出通道数128和卷积核大小为1×3,第五个convblock的输入通道数128,输出通道数128和卷积核大小为1×3;第六个convblock的输入通道数256,输出通道数256和卷积核大小为1×3。
11、优选的,所述编码器还包括特征嵌入模块,所述特征嵌入模块用于高维展开时间依赖特征,并进行秘密特征的嵌入,得到嵌入秘密音频特征的载密融合特征;
12、所述特征嵌入模块包括依次连通的8个mixblock,8个mixblock的卷积核大小均为3×3,其中,第一个mixblock的输入通道数512,输出通道数576,第二个mixblock的输入通道数576,输出通道数640,第三个mixblock的输入通道数640,输出通道数768,第四个mixblock的输入通道数768,输出通道数1024,第五个mixblock的输入通道数1024,输出通道数768,第六个mixblock的输入通道数768,输出通道数576,第七个mixblock的输入通道数576,输出通道数512,第四个mixblock的输入通道数512,输出通道数256。
13、优选的,所述特征还原模块用于对载密融合特征进还原,输出载密音频;
14、所述特征还原模块包括依次连通的6个transblock,其中,前五个transblock的卷积核为1×3,第六个transblock的卷积核为3×3,第一个transblock的输入通道数256,输出通道数256,第二个transblock的输入通道数256,输出通道数128,第三个transblock的输入通道数128,输出通道数128,第四个transblock的输入通道数128,输出通道数64,第五个transblock的输入通道数64,输出通道数64,第六个transblock的输入通道数64,输出通道数1。
15、优选的,所述隐写分析器包括依次连通的4个convblock、3个linearblock和一层softmax层。
16、优选的,所述解码器中包括第二特征提取模块和第二特征还原模块,所述第二特征提取模块通过共享编码器中特征提取模块的网络参数,第二特征提取模块的结构、参数和编码器中特征提取模块中的结构、参数保持一致。
17、优选的,所述编码器、隐写分析器和解码器训练过程中的损失函数包括:
18、ls=xlog(s(c))+(1-x)log(1-s(c′))
19、ld=distortion(m,m′)
20、le=λ1(distortion(c,c′))+λ2ls+λ3ld
21、
22、其中,le表示编码器的损失;ld表示解码器的损失;ls表示隐写分析器的损失;λ1、λ2、λ3分别表示编码器、隐写分析器、解码器的损失所占的权重系数;s(c)表示被隐写分析器s识别为载体音频的概率,s(c′)表示被识别为载密音频的概率;x表示隐写分析器的标签,将编码器产生的载密音频标签为1,将原始的载体音频标签为0;y={y1,y2,…,yi,…,yn}表示时域载体音频,y′={y1′,y2′,…yi′…,yn′}表示时域载密音频。
23、第二方面,本发明提供一种端到端音频隐写系统,采用生成对抗网络预先构建编码器和隐写分析器,根据编码器预先构建解码器,该端到端音频隐写系统包括:
24、加密模块,用于获取秘密音频和载体音频,并通过预先训练的编码器对秘密音频和载体音频进行处理,输出载密音频;
25、解码模块,用于通过解码器对载密音频进行解密处理,输出秘密音频的估计音频;
26、其中,通过循环自编码器进行生成对抗网络预训练,确定编码器中特征提取模块和特征还原模块的参数。
27、第三方面,本发明提供一种计算机可读存储介质,其存储用于端到端音频隐写的计算机程序,其中,所述计算机程序使得计算机执行如上述所述的端到端音频隐写方法。
28、第四方面,本发明提供一种电子设备,包括:
29、一个或多个处理器,存储器,以及一个或多个程序,其中所述一个或多个程序被存储在所述存储器中,并且被配置成由所述一个或多个处理器执行,所述程序包括用于执行如上述所述的端到端音频隐写方法。
30、(三)有益效果
31、本发明提供了一种端到端音频隐写方法、系统、存储介质及电子设备。与现有技术相比,具备以下有益效果:
32、本发明采用生成对抗网络预先构建编码器和隐写分析器,根据编码器预先构建解码器,该方法包括:获取秘密音频和载体音频,并通过预先训练的编码器对秘密音频和载体音频进行处理,输出载密音频;通过解码器对载密音频进行解密处理,输出秘密音频的估计音频;其中,通过循环自编码器进行生成对抗网络预训练,确定编码器中特征提取模块和特征还原模块的参数。本发明通过循环自编码器进行生成对抗网络预训练,确定编码器中特征提取模块和特征还原模块的参数,且基于生成对抗网络框架设计了端到端的隐写算法,不仅避免了因为stft不匹配导致的秘密信息提取失败问题,同时取消了载体音频的修改向量,使编码器直接生成载密音频,从而达到降低模型的训练难度并提高模型性能的目的,有效解决了现有的音频隐写方法稳定性差的技术问题。
- 还没有人留言评论。精彩留言会获得点赞!