一种基于协调简单注意力机制的两阶段语音分离方法
本发明涉及智能语音处理技术,具体涉及一种基于协调简单注意力机制的两阶段语音分离方法。
背景技术:
1、随着语音识别、语音合成等领域的飞速发展,语音分离作为一项关键技术,越来越受到学术界和工业界的关注。语音分离是指从混合的语音信号中分离出不同说话者的语音信号,它在语音识别、语音翻译、语音增强、人机交互、听觉辅助、远程会议等多个场景中具有重要的应用价值。然而,由于语音信号的复杂性和多样性,实现高效、准确的语音分离仍然面临许多挑战。近年来,随着深度学习技术的发展,基于深度学习的语音分离方法取得了显著的进展,语音分离也成为视听学习中研究的热点之一。
2、我们在一个很多人说话的会议室中,也能专注于感兴趣的说话者语音,这种现象被称为“鸡尾酒会效应”。这种注意力集中的能力是我们大脑中的一个重要功能。它使我们能够专注于重要的信息,而不受其他干扰的干扰。此外,我们的大脑可以通过过滤掉不必要的信息,提高我们对重要信息的处理速度和准确性。这种能力在日常生活中尤为重要,例如在繁忙的城市环境中,人们需要集中注意力,以便处理来自不同方向的各种信息和干扰。
3、以往的工作主要有:(i)仅使用音频信息的语音分离,其效果并不是很好,主要因为音频信号重叠和相互干扰,在音频混合中,不同的声音可能会相互重叠和干扰,使得分离变得更加困难。还有音频特征的限制,音频信号具有高度复杂的时间和频率结构,需要使用高维度的特征来表示不同的声音。然而,这种高维度的特征可能会带来计算上的挑战,并且可能需要更多的训练数据来实现良好的性能。(ii)基于静态视觉信息引导的语音分离,面部身份嵌入信息可能缺乏足够的语音相关特征,例如说话人的情感、语调和语速等。因此,使用面部身份嵌入信息进行语音分离可能会导致分离结果的不准确和不完整。面部身份嵌入信息可能会受到光照、姿态和表情等因素的干扰,从而影响分离性能。另外,不同人之间的面部身份嵌入信息可能会存在重叠和相似性,从而使得分离变得更加困难。(iii)基于动态视觉信息引导的语音分离,这类方法主要依靠那些随时间变化的动态信息来进行任务处理,而这些信息通常包含在同步的视觉流中,因此这些方法多数是音频-视觉方法。
4、现有的基于动态视觉信息引导的语音分离方法虽然取得了不错的分离效果,但分离过后仍存在两个主要的问题:(i)分离后的目标语音仍存在来自其他说话者噪声,(ii)分离后的目标语音存在部分缺失。如何有效地去除分离后目标音频存在的其他说话者噪声和恢复分离后缺失的目标语音片段更加值得探索。
技术实现思路
1、发明目的:本发明的目的在于解决现有技术中存在的不足,提供一种基于协调简单注意力机制的两阶段语音分离方法。
2、技术方案:本发明的一种基于协调简单注意力机制的两阶段语音分离方法,包括以下步骤:
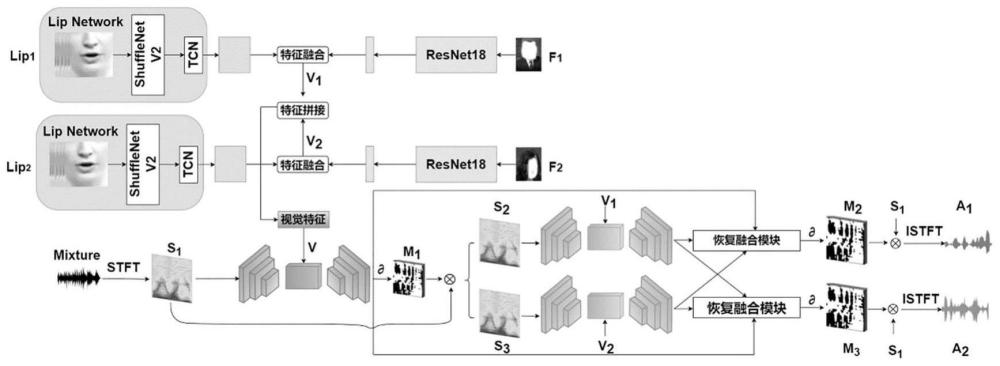
3、步骤s1、获取说话者的视频数据集以及对应音频数据集,将视频数据集及音频数据集划分为训练集、验证集和测试集;分别对训练集、验证集和测试集中部分数据进行预处理,预处理方法包括:提取每个视频数据中的嘴唇运动特征并保存为h5文件,以及随机选择两个音频数据进行混合来构造混合音频,再将混合音频通过短时傅里叶变化转换成音频频谱图s1;
4、步骤s2、构建基于协调简单注意力机制的两阶段语音分离模型,包括面部网络、嘴唇网络和语音分离编码器解码器模块;
5、步骤s2.1、构建嘴唇网络以获取嘴唇运动特征,所述嘴唇网络包括3d卷积层、shufflenet v2网络和时间卷积网络tcn;
6、嘴唇网络提取步骤s1中原始音频对应时间段的连续帧的嘴唇运动区域,并将嘴唇运动区域输入到3d卷积层中进行处理;接使用shufflenet v2网络来提取嘴唇运动特征;最后,通过时间卷积网络tcn对嘴唇运动特征进行处理,得到第i个说话者的嘴唇运动特征lipi;lipi维度大小为512×64;
7、步骤s2.2、构建面部网络以获取面部属性特征,所述面部网络基于resnet-18网络;
8、通过面部网络学习面部属性和音频属性之间的关系(面部属性包括人脸轮廓结构,音频属性包括指音色和音调),从与步骤s2.1原始音频对应的原始视频中随机采样一帧说话者人脸图像作为面部网络输入,并输出第i个说话者对应的人脸特征fi;接着将第i个说话者的嘴唇运动特征lipi和人脸特征fi进行特征拼接融合以得到对应的视觉信息特征vi,i∈{1,2};例如视觉信息特征v1由说话者1的嘴唇运动特征lip1和说话者1的面部属性特征f1经过特征融合得出;视觉信息特征v2由说话者2的嘴唇运动特征lip2和说话者2的面部属性特征f2经过特征融合得出;
9、步骤s2.3、构建语音分离编码器解码器模块,语音分离编码器解码器采用u-net体系结构,包括对称的编码器和解码器;编码器将输入的音频频谱图转换为高层次特征表示的音频特征,解码器加入有协调简单注意力机制csam,解码器通过所得高层次特征表示来预测第i个说话者的音频频谱图的掩码mi;所述视听特征融合模块将音频特征和视觉信息特征按时间维度进行特征融合,所述跳跃连接将编码器和解码器的特征图连接在一起;
10、语音分离的推理过程中,先将预测的掩模与输入的频谱图相乘来预测语音频谱图,然后使用逆短时傅里叶反变换istft将其转换为最终分离的语音信号;
11、步骤s3、使用步骤s2训练集和验证集在基于协调简单注意力机制的两阶段语音分离模型上进行训练和验证,进行多次训练和验证并保存的在验证集上最好的模型,再将训练所得最好的基于协调简单注意力机制的两阶段语音分离模型在测试集上进行测试。
12、进一步地,所述步骤s2.1嘴唇网络中3d卷积由kernel_size为(5,7,7)、stride为(1,2,2)且padding为(2,3,3)的3d卷积、一个batchnorm3d层、一个relu层以及一个maxpool3d层组成;所述shufflenet v2网络主要用于图像分类和目标检测;所述时间卷积网络tcn处理时间序列数据,包括堆叠的一维卷积层、残差连接层和批标准化层,通过时间卷积网络tcn捕捉处理视频序列中的长期依赖关系,增加感受野,并增加网络的深度,并加速训练和改善模型稳定性。
13、进一步地,所述步骤s2.2面部网络包括输入层、卷积层、残差块、全局平均池化层、全连接层和输出层,所述输入层接收大小为224x224的rgb图像;
14、所述卷积层共4个卷积层,每个卷积层使用3x3的卷积核和relu激活函数,提取图像的局部特征;所述残差块共8个残差块,每个残差块由两个卷积层和一条跳跃连接构成,用于解决深度卷积神经网络中梯度消失和梯度爆炸问题;所述全局平均池化层对特征图进行全局平均池化,将特征图转化为一维向量;所述全连接层用于分类输出;所述输出层使用softmax激活函数。
15、本发明的语音分离编码器解码器模块采用u-net结构,具有对称的编码器和解码器,所述步骤s2.3中编码器由多个卷积层和池化层交替组成;卷积层对步骤s1混合音频转换所得音频频谱图进行特征提取和降维操作,提取出音频的局部特征信息;池化层将特征图的尺寸降低,减少参数数量,抑制过拟合,同时保留较重要的特征信息;在每个卷积层中,还使用批归一化和激活函数,如leakyrelu函数,来进一步提高模型的性能;解码器采用反卷积层和跳跃连接,用于将特征图重新映射回原始语音信号,得到预测音频频谱图掩码;每个反卷积层中均添加有批归一化和激活函数,以进一步提高模型的性能;跳跃连接将编码器中相应层的特征图与解码器中相应层的特征图连接起来,这样做可以有效地缓解解码器中的音频信息丢失问题,从而提高语音分离的性能。
16、进一步地,所述通过协调简单注意力机制csam将位置信息嵌入解码器的通道注意,分解通道注意为两个一维特征编码,两个一维特征编码分别沿着两个空间方向聚集特征,进而得到两个新特征图,将这两个新特征图单独编码成一对方向感知和位置敏感的注意力图;然后,在原始特征特征图基础上学习一个三维权重,将注意力图与该三维权重相乘(以增加感兴趣对象的表示)。此处,通过协调简单注意力机制能够捕获沿一个空间方向的远程依赖关系,同时保留沿另一个空间方向的精确位置信息。
17、进一步地,所述步骤s3使用训练好的基于协调简单注意力机制的两阶段语音分离模型进行语音分离,包括两个阶段;
18、第一阶段,同时使用面部轨迹的视觉信息来引导混合语音进行分离,视觉信息包括面部属性信息和嘴唇运动信息;具体方法为:
19、使用嘴唇网络对原始音频特征提取得到得到第i个说话者的嘴唇运动特征lipi,同时使用面部网络提取第i个说话者的人脸特征fi,将说话者i的嘴唇运动特征lipi和人脸特征fi经过特征融合得到视觉信息特征vi,i∈{1,2},再将视觉信息特征v1和v2经过特征拼接得到视觉信息特征v;将混合音频mixture经过短时傅里叶变换stft得到音频频谱图s1,音频频谱图s1输入编码器得到音频特征,再将音频特征和视觉信息特征v经过融合后输入解码器中计算出第一阶段预测出的掩码m1,将音频频谱图s1与掩码m1相乘得到初步分离音频频谱图s2和s3;
20、第二阶段,精细分离和恢复融合模块,精细分离具体方法为:
21、将音频频谱图s2和s3输入语音分离编码器解码器,仅使用与音频频谱图s2和s3相关的视觉信息特征来引导语音再次进行分离,通过解码器输出预测的频谱图掩码m2和m3;音频频谱图s1与掩码m2相乘再经过逆短时傅里叶变换istft得到最后分离出的音频a1,音频频谱图s1与掩码m3相乘再经过逆短时傅里叶变换istft得到最后分离出的音频a2;
22、恢复融合的具体方法为:
23、恢复第一阶段分离语音缺失的部分,最终预测的说话者i的目标语音特征fif为第一阶段预测的其他说话者j的目标语音特征fj1与第二阶段预测的其他说话者j的目标语音特征fj2的差值再加上第二阶段预测的目标说话者i的目标语音特征fi2,再经过tanh函数得到最终说话者i的目标语音频掩码mif:
24、
25、有益效果:本发明利用视觉信息来引导混合语音进行分离,针对分离后的音频存在其他音频噪声问题,本发明进行两阶段分离,在第一阶段先进行粗分离,在第二阶段进行精细分离来去除第一阶段分离后音频存在其他音频噪声问题;针对分离后的音频存在部分音频片段缺失问题,本发明在第二阶段使用恢复融合模块来恢复缺失的音频片段;最后,本发明提出协调简单注意力机制(csam)可以使音频和对应视觉信息更好地相关关联,以实现更精确的分离结果。
- 还没有人留言评论。精彩留言会获得点赞!