一种基于深度学习的复合音频实时传输方法及系统与流程
本发明涉及音频传输领域,特别是一种基于深度学习的复合音频实时传输方法及系统。
背景技术:
1、在生活中涉及很多复合音频传输情况,例如在电脑端同时播放音乐和人声,并传输至广播中供人们收听;或者耳机采集外界音频后,在耳机内部进行音频复合、降噪等处理,传输至人耳内等等。在音频复合处理和传输处理过程中会存在多种问题,例如音频噪音过大,音频传输失真等,所以需要解决音频复合处理和传输处理过程出现的问题。获取一种基于深度学习的复合音频实时传输方法,能够提高传输效率,对生活中的音频传输方面起良好效果。
技术实现思路
1、本发明克服了现有技术的不足,提供了一种基于深度学习的复合音频实时传输方法及系统。
2、为达到上述目的,本发明采用的技术方案为:
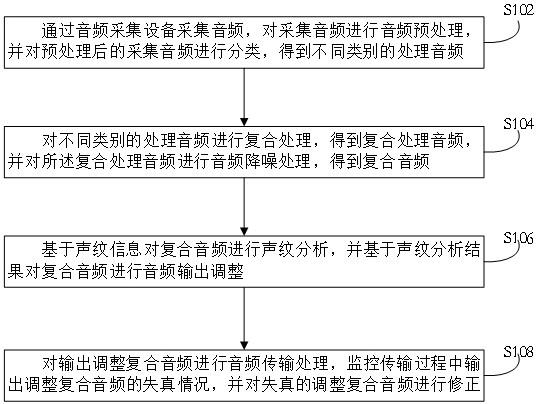
3、本发明第一方面提供了一种基于深度学习的复合音频实时传输方法,包括以下步骤:
4、通过音频采集设备采集音频,对采集音频进行音频预处理,并对预处理后的采集音频进行分类,得到不同类别的处理音频;
5、对不同类别的处理音频进行复合处理,得到复合处理音频,并对所述复合处理音频进行音频降噪处理,得到复合音频;
6、基于声纹信息对复合音频进行声纹分析,并基于声纹分析结果对复合音频进行音频输出调整;
7、对输出调整复合音频进行音频传输处理,监控传输过程中输出调整复合音频的失真情况,并对失真的调整复合音频进行修正。
8、进一步的,本发明的一个较佳实施例中,所述通过音频采集设备采集音频,对采集音频进行音频预处理,并对预处理后的采集音频进行分类,得到不同类别的处理音频,具体为:
9、确定目标音频信息,通过音频采集设备,获取包含目标音频信息的音频,并构建音频存储库,将采集获取的音频导入音频存储库中进行存储;
10、在所述音频存储库中,对采集音频进行音频预处理,所述音频预处理包括将采集的音频进行回声消除处理、音频增强处理和静音剪裁处理,得到处理音频;
11、将所述处理音频转化为处理音频样本,并通过傅里叶变换对所述处理音频样本进行特征提取,得到处理音频样本特征数据;
12、构建音频中心,并对所述音频中心进行初始化处理,一个音频中心代表一个类别的处理音频,引入模糊聚类法对处理音频样本特征数据进行迭代计算,得到迭代计算结果,所述迭代计算为反复计算处理音频样本特征数据与音频中心的欧氏距离;
13、基于所述迭代计算结果,计算每个音频处理样本与音频中心的隶属度,并根据每个音频处理样本与音频中心的隶属度,对音频处理样本进行划分,得到不同类别的处理音频。
14、进一步的,本发明的一个较佳实施例中,所述对不同类别的处理音频进行复合处理,得到复合处理音频,并对所述复合处理音频进行音频降噪处理,得到复合音频,具体为:
15、计算目标音频信息与不同类别处理音频之间的欧氏距离,并预设欧氏距离区间;
16、基于所述欧氏距离区间,若存在目标音频信息与任意处理音频之间的欧氏距离在同一欧氏距离区间中,则将对应类别的处理音频定义为目标处理音频;
17、对所述目标处理音频进行数字编码,并结合混音算法,对数字编码后的目标处理音频进行音频复合处理,得到复合处理音频;
18、获取复合处理音频的时域特征和能量分布特征,并引入自适应滤波器,所述自适应滤波器基于所述复合处理音频的时域特征和能量分布特征,生成权重系数,并基于所述权重系数,对自适应滤波器进行自适应训练,得到训练后的自适应滤波器;
19、将所述复合处理音频导入至训练后的自适应滤波器中进行噪声相位和噪声反相位获取,将复合处理音频的噪声相位和噪声反相位结合,得到初步复合音频;
20、对所述初步复合音频进行音频幅度自适应调整,得到复合音频。
21、进一步的,本发明的一个较佳实施例中,所述基于声纹信息对复合音频进行声纹分析,并基于声纹分析结果对复合音频进行音频输出调整,具体为:
22、将大数据网络与所述音频存储库连接,使所述音频存储库在大数据网络中下载人声音频声纹信息储存;
23、预设一帧音频的时间,基于所述一帧音频的时间,将所述复合音频进行分帧处理,得到复合音频帧;
24、对所有的复合音频帧进行线性编码处理,得到复合音频帧线性编码结果,并将所有复合音频帧线性编码结果合成,生成一类复合音频声纹信息;
25、计算所述人声音频声纹信息和一类复合音频声纹信息之间的马氏距离,并构建人声音频声纹马氏距离区间,对马氏距离在人声音频声纹马氏距离区间内的一类复合音频声纹信息进行特征提取,定义为一类人声音频声纹信息;
26、将剩余的复合音频声纹信息定义为二类复合音频声纹信息,对二类复合音频声纹信息进行声纹图构建,得到二类复合音频声纹图,所述二类复合音频声纹图中包含二类复合音频声纹信息的光滑度参数、激活度参数和谐波参数;
27、引用支持向量机,将二类复合音频声纹信息的光滑度参数、激活度参数和谐波参数导入所述支持向量机中,得到二类人声音频声纹信息和其他音频声纹信息,所述支持向量机用于二类复合音频声纹信息的特征分类处理;
28、基于各类音频声纹信息将复合音频分为人声降噪音频和环境降噪音频,获取复合音频的传输性质,基于所述复合音频的传输性质,对复合音频中的人声降噪音频和环境降噪音频进行音频输出调整,得到输出调整复合音频。
29、进一步的,本发明的一个较佳实施例中,所述对输出调整复合音频进行音频传输处理,监控传输过程中输出调整复合音频的失真情况,并对失真的调整复合音频进行修正,具体为:
30、获取音频传输设备,所述输出调整复合音频通过音频传输设备,向目标设备实时传输输出调整复合音频,在输出调整复合音频传输过程中,获取输出调整后复合音频频率图;
31、获取输出调整前复合音频频率图,输出调整前后复合音频频率图中均含有音频频率值,将输出调整前后的复合音频频率图进行频率图重合分析,得到频率图重合率,若频率图重合率在预设范围内,则判断频率图中是否存在输出调整前后复合音频频率值的差值大于预设值的情况;
32、若是,则将输出调整前后复合音频频率值的差值大于预设值的对应音频进行标记,并通过大数据网络检索获取音频频率修正方法输出;
33、若不是,则不需要对音频传输后的调整复合音频进行修正;
34、若频率图重合率不在预设范围内,则获取输出调整前后复合音频频率值的差值大于预设值的输出调整后复合音频帧,定义为异常复合音频帧;
35、获取异常复合音频帧的失真原因,并进行相应修正处理,得到修正复合音频。
36、进一步的,本发明的一个较佳实施例中,所述获取异常复合音频帧的失真原因,并进行相应修正处理,得到修正复合音频,具体为:
37、对所述异常复合音频帧进行失真分析,获取异常复合音频帧的失真类型和失真程度;
38、构建复合音频模型,并将异常复合音频帧的类型和失真程度导入所述复合音频模型中进行模型更新处理,得到异常复合音频模型;
39、基于所述异常复合音频模型,获取异常复合音频帧的时域特征和频域特征,基于所述异常复合音频帧的时域特征和频域特征,对异常复合音频帧进行重采样处理和插值处理,并在重采样处理和插值处理过程中通过迭代算法计算异常复合音频帧的信噪比及频率值;
40、当异常复合音频帧的信噪比及频率值均在标准范围内,停止迭代计算,生成修正复合音频帧,并对所有的修正复合音频帧进行音频帧合成处理,输出修正复合音频。
41、本发明第二方面还提供了一种基于深度学习的复合音频实时传输系统,所述复合音频实时传输系统包括存储器与处理器,所述存储器中储存有复合音频实时传输方法,所述复合音频实时传输方法被所述处理器执行时,实现如下步骤:
42、通过音频采集设备采集音频,对采集音频进行音频预处理,并对预处理后的采集音频进行分类,得到不同类别的处理音频;
43、对不同类别的处理音频进行复合处理,得到复合处理音频,并对所述复合处理音频进行音频降噪处理,得到复合音频;
44、基于声纹信息对复合音频进行声纹分析,并基于声纹分析结果对复合音频进行音频输出调整;
45、对输出调整复合音频进行音频传输处理,监控传输过程中输出调整复合音频的失真情况,并对失真的调整复合音频进行修正。
46、本发明解决的背景技术中存在的技术缺陷,本发明具备以下有益效果:对采集音频进行音频预处理和音频分类处理,得到不同类别的处理音频,并对不同类别的处理音频进行复合与降噪处理,得到复合音频;通过对复合音频进行声纹分析,调整复合音频的音频输出效果,最后对复合音频在音频传输过程中出现的失真情况进行分析及修正。本发明能够在复合音频传输前进行音频预处理,并在传输过程中改善传输情况,提高传输效率,对生活中的音频传输方面起良好效果。
- 还没有人留言评论。精彩留言会获得点赞!