一种语音识别训练过程中数据增广方法与流程
本发明属于人工智能中的语音识别领域,尤其涉及一种语音识别训练过程中数据增广方法。
背景技术:
1、目前在无噪声背景的音频数据中,语音识别算法已经达到了很高的准确率,其中百度、搜狗、科大讯飞等语音识别准确率已经达到97%。但真实场景的数据分布往往与开源数据集存在较大差距,为此目前提出了很多种数据增强方法,分别从音频、fbank特征、mfcc特征等多个方面进行数据增强。
2、当前从音频方面进行数据增强的主要手段有:1)获取不同场景的噪声,和无噪音频生成新的带噪声的训练音频;从fbank特征、mfcc特征等方面进行数据增强主要手段有:1)specaugment方法,分别从fbank特征时间轴和频率轴生成掩码,使用有掩码的特征训练asr模型。这些方法均在原始的音频上或者对应的mfcc特征上进行操作,对训练音频的依赖性较大。
技术实现思路
1、本发明所要解决的技术问题是针对背景技术的不足提供本发明提出一种语音识别训练过程中数据增广方法,其在训练数据有限、场景不够复杂的情况下,通过不同的数据增广的方法,获得更加多样性的训练数据,以此来提高asr模型的鲁棒性和准确性。
2、本发明为解决上述技术问题采用以下技术方案:
3、一种语音识别训练过程中数据增广方法,在训练数据有限的情况下,通过不同的数据增广的方法,获得更加多样性的训练数据,具体包含背景数据获取阶段、数据增广阶段、asr模型训练阶段三个阶段;
4、其中,背景数据获取阶段,用于获取噪声音频获取和训练音频;
5、数据增广阶段,用于通过4种增广方式分别从音频维度和mfcc等特征维度进行了数据增广;
6、asr模型训练阶段,用于通过mfcc音频特征训练asr模型。
7、作为本发明一种语音识别训练过程中数据增广方法的进一步优选方案,所述背景数据获取阶段包含噪声音频获取和训练音频获取。
8、作为本发明一种语音识别训练过程中数据增广方法的进一步优选方案,所述噪声音频获取包括但不限于使用爬虫、背景声音提取、开源噪声数据集多种方式获得噪声音频。
9、作为本发明一种语音识别训练过程中数据增广方法的进一步优选方案,所述训练音频获取包括但不限于开源数据集、自己制作、购买多种方式获得无噪训练音频。
10、作为本发明一种语音识别训练过程中数据增广方法的进一步优选方案,所述数据增广阶段具体包含四种增广方式:
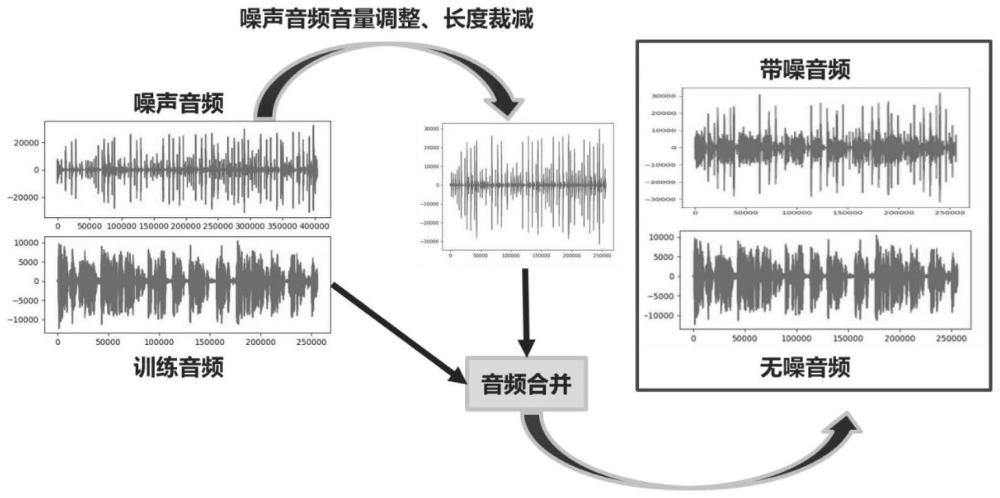
11、增广方式一:在线添加背景噪声;
12、增广方式二:音频随机速度变化;
13、增广方式三:mfcc等特征上随机速度变化;
14、增广方式四:mfcc等特征数值随机扰动。
15、作为本发明一种语音识别训练过程中数据增广方法的进一步优选方案,在线添加背景噪声,具体如下:
16、对每一条训练音频,随机从噪声库中选择一条噪声音频,使用一定的概率,并采用随机添加位置、随机噪声音量等合并噪声音频与训练音频,同时得到带噪声的训练音频,以及不带噪的训练音频,标签不变。
17、作为本发明一种语音识别训练过程中数据增广方法的进一步优选方案,所述音频随机速度变化,具体如下:
18、在增广方式一的基础上,以一定的概率,对方式一得到的音频速度使用0.9到1.15的速度进行速度变化,得到速度变化后的训练音频,标签不变。
19、作为本发明一种语音识别训练过程中数据增广方法的进一步优选方案,所述mfcc等特征上随机速度变化,具体如下
20、在增广方式二的基础上,以每一个特征维度所占的字数作为基准,以一定的概率,使用插值方式对音频的mfcc特征进行插值,达到速度随机变化的目的,同时返回速度扰动前的mfcc特征和速度扰动后的mfcc特征。
21、作为本发明一种语音识别训练过程中数据增广方法的进一步优选方案,所述mfcc特征数值随机扰动,具体如下
22、在增广方式三的基础上,以一定的概率,对音频的mfcc等特征乘以一个0.9-1.1的变换参数,达到对mfcc等特征某些特征值进行一个随机扰动的效果。
23、作为本发明一种语音识别训练过程中数据增广方法的进一步优选方案,所述asr模型训练阶段,具体如下:对输入为batch_size大小的音频,经过数据增广阶段的数据增广之后能够得到batch_size*4数量的mfcc音频特征,进而使用mfcc音频特征训练asr模型。
24、本发明采用以上技术方案与现有技术相比,具有以下技术效果:
25、本发明在基于原有的数据集的基础上,通过4种增广方式分别从音频维度和mfcc等特征维度进行了数据增广,在原有数据集的限制下使得数据具有多样性,能够很好的模拟真实的场景,并且由于噪声音频和训练数据是在训练过程中动态合并,使得每一个epoch训练的时候数据都不一样,且无需提前保存带噪音频,减少了本地内存的占用,同时输入一个音频能够得到数据增广后的4个音频,达到了数据扩充的效果;通过实验证明,一种语音识别训练过程中数据增广方法能够提升语音识别模型的鲁棒性和准确率。
技术特征:
1.一种语音识别训练过程中数据增广方法,其特征在于:在训练数据有限的情况下,通过不同的数据增广的方法,获得更加多样性的训练数据,具体包含背景数据获取阶段、数据增广阶段、asr模型训练阶段三个阶段;
2.根据权利要求1所述的一种语音识别训练过程中数据增广方法,其特征在于:所述背景数据获取阶段包含噪声音频获取和训练音频获取。
3.根据权利要求1所述的一种语音识别训练过程中数据增广方法,其特征在于:所述噪声音频获取包括但不限于使用爬虫、背景声音提取、开源噪声数据集多种方式获得噪声音频。
4.根据权利要求1所述的一种语音识别训练过程中数据增广方法,其特征在于:所述训练音频获取包括但不限于开源数据集、自己制作、购买多种方式获得无噪训练音频。
5.根据权利要求1所述的一种语音识别训练过程中数据增广方法,其特征在于:所述数据增广阶段具体包含四种增广方式:
6.根据权利要求5所述的一种语音识别训练过程中数据增广方法,其特征在于:在线添加背景噪声,具体如下:
7.根据权利要求5所述的一种语音识别训练过程中数据增广方法,其特征在于:所述音频随机速度变化,具体如下:
8.根据权利要求5所述的一种语音识别训练过程中数据增广方法,其特征在于:所述mfcc等特征上随机速度变化,具体如下
9.根据权利要求5所述的一种语音识别训练过程中数据增广方法,其特征在于:所述mfcc特征数值随机扰动,具体如下
10.根据权利要求5所述的一种语音识别训练过程中数据增广方法,其特征在于:所述asr模型训练阶段,具体如下:对输入为batch_size大小的音频,经过数据增广阶段的数据增广之后能够得到batch_size*4数量的mfcc音频特征,进而使用mfcc音频特征训练asr模型。
技术总结
本发明公开了一种语音识别训练过程中数据增广方法,属于人工智能中的语音识别领域,在基于原有的数据集的基础上,通过4种方法分别从音频维度和MFCC等特征维度进行了数据增广,在原有数据集的限制下使得数据具有多样性,能够很好的模拟真实的场景,并且由于噪声音频和训练数据是在训练过程中动态合并,使得每一个epoch训练的时候数据都不一样,且无需提前保存带噪音频,减少了本地内存的占用;同时输入一个音频能够得到数据增广后的4个音频,达到了数据扩充的效果;在训练数据有限的情况下,通过不同的数据增广的方法,获得更加多样性的训练数据,以此来提高ASR模型的鲁棒性和准确性。
技术研发人员:凌承昆
受保护的技术使用者:天翼云科技有限公司
技术研发日:
技术公布日:2024/4/17
- 还没有人留言评论。精彩留言会获得点赞!