基于局部关联信息的零样本语音合成方法
本发明涉及语音信号处理,尤其涉及一种基于局部关联信息的零样本语音合成方法。
背景技术:
1、零样本语音合成旨在利用少数目标说话人的语音作为参考,从文本合成具有该说话人音色的自然流畅的语音,其可以应用于有声小说、语音播报等诸多实际场景中;零样本语音合成面临合成泛化性不佳、韵律合成不够自然等诸多挑战;近年来,零样本语音合成已从传统的数学模型转向基于神经网络的深度学习方法;
2、这些方法中多采用全局的参考引入方式,即将参考谱图经过提取后转换为一维向量,使其包含目标说话人的基本音色信息,再利用该向量来帮助模型学习目标说话人的声音信息;然而,该方式在引入向量时,对于中间特征的每一时间帧,引入的向量都是一致的,这忽略了目标语句的局部内容信息;最近,在语音合成任务中,有研究者提出利用目标文本的内容信息来寻找信息关联度更高的参考声音特征;相比于全局方法,该方法能够为不同的局部引入更为丰富的有用信息,从而使语音合成的结果更加自然。
3、另一方面,零样本语音合成系统通常可以修改为说话人转换系统。说话人转换的目标是在保持语义内容不变的前提下,将源说话人的音色替换为目标说话人的音色,在数字人、虚拟换声等场景均有应用。最近,研究者提出将零样本语音合成的声学模型转换为说话人转换模型,利用零样本语音合成对目标说话人声音的适应能力,帮助完成不同说话人之间的音色转换。基于上述内容,本发明提出一种基于局部关联信息的零样本语音合成方法。
技术实现思路
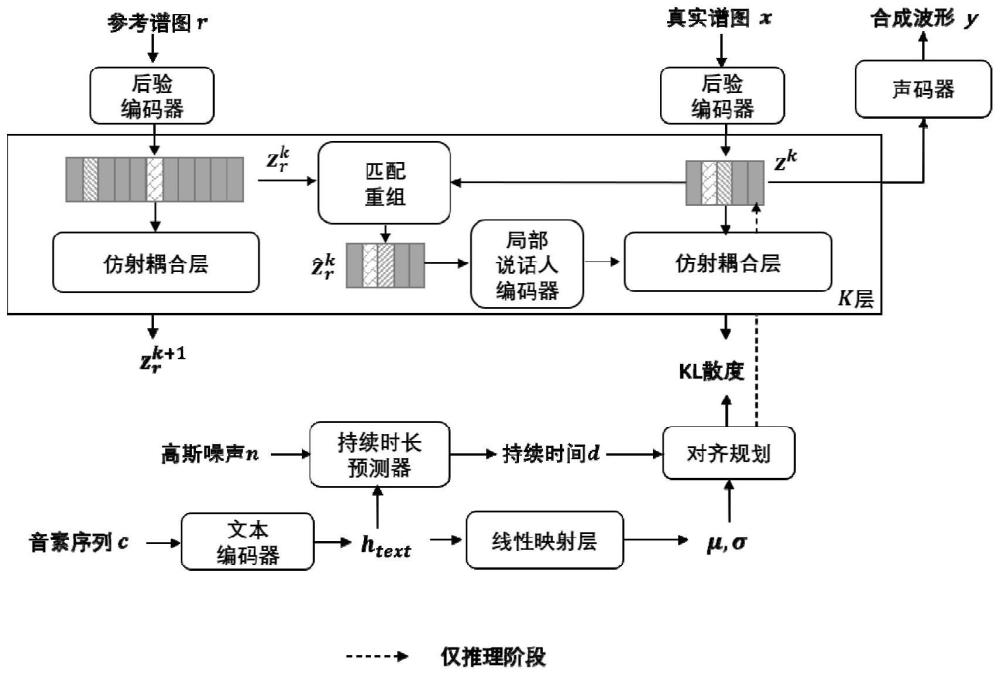
1、本发明的目的在于提出一种基于局部关联信息的零样本语音合成方法以解决背景技术中所提出的问题,以实现在少量样本的情况下,从文本生成自然高质量的语音。
2、为了实现上述目的,本发明采用了如下技术方案:
3、基于局部关联信息的零样本语音合成方法,包括以下步骤:
4、s1、预处理文本及语音数据:给定原始文本和语音数据(craw,sraw),对craw进行词到音素处理,得到音素序列c;对sraw进行短时傅里叶变换(stft)并随机选取片段,得到参考短时傅里叶变换(stft)频谱r和真实短时傅里叶变换(stft)频谱x,将数据划分为训练集、验证集、测试集,以及独立的参考语音集;
5、s2、构建基本网络框架:设计一个基于transformer的先验文本编码器,一个基于流的多层声学解码器,一个基于膨胀卷积的后验编码器以及一个基于生成对抗网络的声码器,将上述结构共同组成了一个联合对抗训练的条件变分自编码器网络框架;
6、s3、设计方案、搭建模型:基于目标语句与参考语音之间的信息关联性,结合s1~s2中所述预处理方法和基本网络框架,设计参考信息引入方案,并依据所设计的方案搭建零样本语音合成模型,所述方案具体包括如下内容:
7、①特征匹配与重组:将s1中所得的真实与参考短时傅里叶变换(stft)频谱数据对(x,r)输入后验编码器,分别得到目标隐藏特征z和参考隐藏特征zr;随后,在每一层仿射耦合层中,对z和zr实行匹配与重组方法,得到信息关联度更高的参考特征
8、②局部说话人编码器:将重组后的特征输入到基本声纹向量生成模块,得到基本声纹向量e;同时将输入到门卷积模块中进行信息过滤;最后将过滤后的特征与e输入到局部注意力模块,得到局部说话人嵌入
9、③训练与推理流程设计:所述训练流程按照s2中所述的对抗训练和变分推理来进行;所述推理流程与训练流程的不同在于,仿射耦合层采用可逆形式;
10、④损失函数模块设计:将零样本语音合成模型通过在变分推理过程中的重建损失和kl散度损失、对抗训练过程中的对抗损失和特征匹配损失、基本声纹向量生成过程中的说话人身份损失进行联合优化;
11、⑤说话人转换方法设计:基于s3所述的零样本语音合成模型做出修改,保留参考信息引入方案、后验编码器、k层仿射耦合层、声码器,以实现不同说话人之间的声音转换;
12、s4、训练模型:利用深度学习pytorch框架训练模型,遍历s1中所有预处理的文本和语音数据,初始学习率设置为2e-4,按0.999的速率指数衰减,经过500k次迭代的训练,保存在验证集上表现最好的模型;
13、s5、输出结果:将s1中预处理的测试集文本数据和参考集语音数据输入到稳定模型中,获得零样本语音合成的结果。
14、优选地,所述方案①进一步包括以下内容:
15、a1、在同一仿射耦合层内,对目标隐藏特征z和参考隐藏特征zr进行帧级别的余弦相似度计算,即对于z中的每一帧z(t),计算这一帧与zr中所有帧的相似度,选择其中余弦相似度最大的一帧作为z(t)的匹配索引,该过程的函数表示为:
16、
17、式中,<·,·>代表内积,ψ[·]代表向量的归一化;
18、a2、按照匹配得到的索引值来重组生成一个与z在时域上对齐的重组参考特征所述重组参考特征是与当前目标中间特征z局部关联性最高的参考帧级特征组合。
19、优选地,所述方案②具体包括以下内容:
20、b1、基本声纹向量生成模块首先通过三层长短时记忆网络(lstm)将重组参考特征映射为最后一层lstm的隐藏向量,然后通过线性层将该隐藏向量映射为说话人的基本声纹向量e;
21、b2、门卷积模块首先通过由卷积模块和门控激活单元组成的输入门对重组参考特征进行信息过滤,然后通过由全局基本声纹向量g控制的遗忘门,以实现对冗余信息的进一步控制;
22、b3、局部注意力模块使用b2中过滤后的特征来调制基本声纹向量e;首先沿着时间维度将过滤后的特征切分成不同的帧组,然后基于注意力机制,将不同的帧组分别与e融合,生成同时捕捉了目标说话人基本声纹信息以及对应帧组j所代表的局部关联信息的局部说话人嵌入向量ej;所述注意力机制使用e作为查询,同时将e作为键和值;所述帧组j不作为查询,只作为键和值使用;上述过程的函数表示为:
23、
24、式中,q0、k0和v0分别表示从e中获取的查询、键和值;ki,vi分别表示由帧组所得到的键和值,其中,i={1,2,3}。
25、优选地,所述方案③具体包括以下内容:
26、以最大化的对数似然的证据下界作为训练过程的目标,其函数表示为:
27、
28、式中,对数似然函数logpθ(x│z,r)代表声码器重建波形的流程;logqθ(z│x,r)-logpθ(x│z,r)代表先验分布和近似后验分布之间的kl散度,实际对应k层仿射耦合层建立文本隐藏特征与音频隐藏特征之间的可逆变换的流程;
29、在推理过程中,所述k层仿射耦合层采用可逆形式,以文本先验为输入,输出声学隐藏特征z。
30、优选地,所述方案④进一步包括以下内容:
31、c1、将真实的短时傅里叶变换(stft)频谱x投影到梅尔刻度上,记为xmel;对于声码器预测的波形y,也使用相同的参数将其转换为梅尔频谱ymel;然后,使用xmel与ymel之间的l1损失作为重建损失,其函数表示如下:
32、
33、c2、利用变分推理使得声码器更好地还原x,并使得近似的后验分布qθ(z│x,r)与先验分布pθ(x│z,r)相趋近;定义kl散度为:
34、
35、z~qφ(z|x,r)=n(z;μφ(x,r),σφ(x,r))
36、式中,[μφ(x,r),σφ(x,r)]表示后验分布的统计量;
37、c3、使用最小二乘损失函数作为对抗训练损失函数以避免梯度消失现象,具体函数表示如下:
38、
39、
40、c4、声码器使用多尺度和多周期辨别器,并使用多层特征匹配损失函数以提高对抗训练的稳定性,具体函数表示如下:
41、
42、式中,t表示辨别器的层数,dl和nl分别表示第l层的特征图和该特征图中特征的数目;
43、将拉近相同说话人的声纹向量的距离,拉远不同说话人的声纹向量的距离作为说话人身份损失函数的基本思想,具体函数表示如下:
44、
45、
46、式中,i(j)表示批处理中的样本索引,m表示仿射耦合层的层索引,和e分别表示由重组的参考特征和目标特征z生成的声纹向量,ψ(·)表示向量的归一化,<·,·>表示内积;表示来自同一说话人两个样本的声纹向量之间的相似性,而s表示来自不同说话人两个样本的声纹向量之间的相似性;正实数α和β分别作为s和的乘子。
47、优选地,所述方案⑤进一步包括以下内容:
48、说话人转换的目的是保持相同语义内容的前提下,将源音色转换为目标音色,具体指:
49、d1、在源说话人参考语音s的帮助下,经过后验编码器qφ和正向仿射耦合层fdec,将源说话人语音x转换为与说话人无关的中间变量z′,其函数表示如下:
50、z~qφ(z|x,s)
51、z′=fdec(z|s)
52、d2、在目标说话人参考语音t的帮助下,经过逆向仿射耦合层和声码器v,将与说话人无关的中间变量z′转换为目标说话人的波形y,其函数表示如下:
53、
54、式中,v表示声码器;表示逆向仿射耦合层;z′表示与说话人无关的中间变量;t表示目标说话人参考语音。
55、与现有技术相比,本发明提供了基于神经网络的事件相机图像重建方法,具备以下有益效果:
56、(1)本发明提出了一种基于局部关联信息的零样本语音合成方法;不同于以往的全局目标参考信息的引入方式,本发明额外考虑了目标语句与参考语音在音素级别上的信息关联性,能够为不同的局部引入更加丰富的信息,从而使合成结果更加自然。
57、(2)本发明提出了一个帧级别的特征匹配与重组方法,能获取信息关联度更高的参考特征;本发明还提出一种局部说话人编码器,能够使参考特征更好地表达基本声纹特征和局部关联信息。
58、(3)基于本发明实施例中所进行的实验表明,所提出的方法优于目前主流的零样本语音合成方法;经过本发明的研究探索,能够启发更多利用目标语句与参考语音之间的局部关联信息的研究。
- 还没有人留言评论。精彩留言会获得点赞!