一种语料标注方法、装置、电子设备及存储介质与流程
本技术涉及计算机,尤其涉及一种语料标注方法、装置、电子设备及存储介质。
背景技术:
1、语音识别模型为一个给予输入语音,可产生其对应辨识文字结果的模型。因此,训练语音识别模型时,需要有音档和其对应的正确标注文本,透过此类训练语料,才能让他学习到语音和文字的相互关系以达到语音识别的能力。
2、语音识别若要达到产品化的标准,其辨识准确度势必要很高,语音识别模型的效能好坏与训练语料量的多寡有直接的影响。目前普遍的研究分析都有使用的训练语料越多,语音识别模型效能越好的现象,也就是说,高准确度的语音识别模型时常建立在大量的训练语料上,在市面上可见的语音识别产品都是基于大量训练语料才能达到高准确率的效果。
3、然而,目前要搜集大量训练语料,需要消耗大量的人力来进行语者标注以及复检,模型的训练语料的获取效率非常低,无法快速取得更多训练语料来增加模型的强健性。
技术实现思路
1、为了解决上述技术问题或者至少部分地解决上述技术问题,本技术提供了一种语料标注方法、装置、电子设备及存储介质。
2、第一方面,本技术提供了一种语料标注方法,包括:
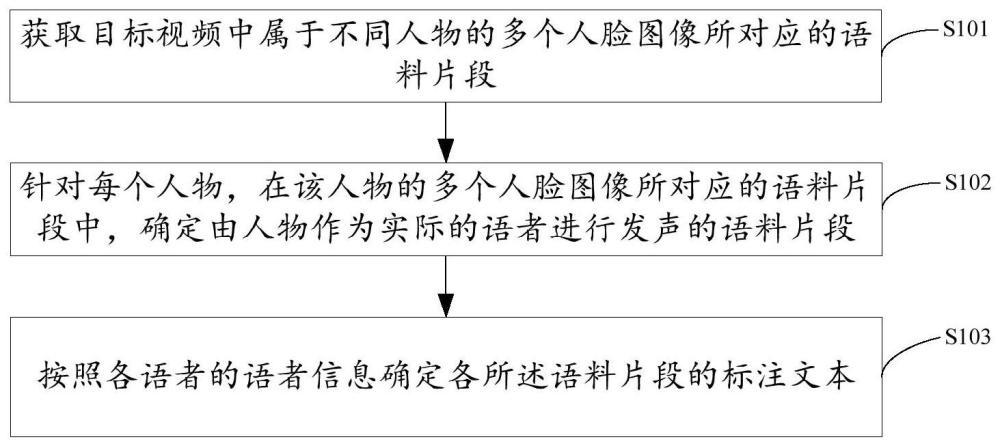
3、获取目标视频中属于不同人物的多个人脸图像所对应的语料片段;
4、针对每个人物,在该人物的多个人脸图像所对应的语料片段中,确定由所述人物作为实际的语者进行发声的语料片段;
5、按照各所述语者的语者信息确定各所述语料片段的标注文本。
6、可选地,获取目标视频中属于不同人物的多个人脸图像所对应的语料片段,包括:
7、在所述目标视频的多个视频帧中检测人脸图像;
8、在各所述人脸图像中分别确定属于不同人物的多个人脸图像;
9、根据属于不同人物的多个人脸图像获取属于不同人物的多个所述人脸图像所对应的语料片段。
10、可选地,根据属于不同人物的多个人脸图像获取属于不同人物的多个所述人脸图像所对应的语料片段,包括:
11、针对每个人脸图像,获取所述人脸图像对应的时间戳;
12、根据各所述人脸图像对应的时间戳,获取属于不同人物的多个所述人脸图像所对应的语料片段。
13、可选地,根据各所述人脸图像对应的时间戳,获取属于不同人物的多个所述人脸图像所对应的语料片段,包括:
14、基于各所述人脸图像对应的时间戳,确定属于不同人物的多个所述人脸图像所对应的时间段;
15、根据属于不同人物的多个所述人脸图像所对应的时间段,获取属于不同人物的多个所述人脸图像所对应的语料片段。
16、可选地,针对每个人物,在该人物的多个人脸图像所对应的语料片段中,确定由所述人物作为实际的语者进行发声的语料片段,包括:
17、将任意两个语料片段进行声音相似度识别,得到声音相似度;
18、将声音相似度大于第一预设阈值的两个语料片段确定为由所述人物作为实际的语者进行发声的语料片段。
19、可选地,针对每个人物,在该人物的多个人脸图像所对应的语料片段中,确定由所述人物作为实际的语者进行发声的语料片段,还包括:
20、将声音相似度小于或等于第一预设阈值的两个语料片段确定为候选语料片段;
21、针对每个候选语料片段,获取所述候选语料片段与其它语料片段之间的声音相似度;
22、若所述候选语料片段与其它语料片段之间的声音相似度中,大于第一预设阈值的声音相似度的比例超过第二预设阈值,确定所述候选语料片段为由所述人物作为实际的语者进行发声的语料片段。
23、可选地,针对每个人物,在该人物的多个人脸图像所对应的语料片段中,确定由所述人物作为实际的语者进行发声的语料片段,还包括:
24、将声音相似度小于或等于第一预设阈值的两个语料片段确定为候选语料片段;
25、针对每个候选语料片段,获取所述候选语料片段与每个语者的语料片段之间的声音相似度;
26、若所述候选语料片段与每个语者的语料片段之间的声音相似度大于第一预设阈值,确定所述候选语料片段为由所述人物作为实际的语者进行发声的语料片段。
27、第二方面,本技术提供了一种语料标注装置,包括:
28、第一获取模块,用于获取目标视频中属于不同人物的多个人脸图像所对应的语料片段;
29、第一确定模块,用于针对每个人物,在该人物的多个人脸图像所对应的语料片段中,确定由所述人物作为实际的语者进行发声的语料片段;
30、第二确定模块,用于按照各所述语者的语者信息确定各所述语料片段的标注文本。
31、可选地,所述第一获取模块包括:
32、第一检测单元,用于在所述目标视频的多个视频帧中检测人脸图像;
33、第一确定单元,用于在各所述人脸图像中分别确定属于不同人物的多个人脸图像;
34、第一获取单元,用于根据属于不同人物的多个人脸图像获取属于不同人物的多个所述人脸图像所对应的语料片段。
35、可选地,所述第一获取单元包括:
36、第一获取子单元,用于针对每个人脸图像,获取所述人脸图像对应的时间戳;
37、第二获取子单元,用于根据各所述人脸图像对应的时间戳,获取属于不同人物的多个所述人脸图像所对应的语料片段。
38、可选地,所述第二获取子单元还用于:
39、基于各所述人脸图像对应的时间戳,确定属于不同人物的多个所述人脸图像所对应的时间段;
40、根据属于不同人物的多个所述人脸图像所对应的时间段,获取属于不同人物的多个所述人脸图像所对应的语料片段。
41、可选地,所述第一确定模块包括:
42、相似度识别单元,用于将任意两个语料片段进行声音相似度识别,得到声音相似度;
43、第二确定单元,用于将声音相似度大于第一预设阈值的两个语料片段确定为由所述人物作为实际的语者进行发声的语料片段。
44、可选地,所述第一确定模块还包括:
45、第三确定单元,用于将声音相似度小于或等于第一预设阈值的两个语料片段确定为候选语料片段;
46、第二获取单元,用于针对每个候选语料片段,获取所述候选语料片段与其它语料片段之间的声音相似度;
47、第四确定单元,用于若所述候选语料片段与其它语料片段之间的声音相似度中,大于第一预设阈值的声音相似度的比例超过第二预设阈值,确定所述候选语料片段为由所述人物作为实际的语者进行发声的语料片段。
48、可选地,所述第一确定模块还包括:
49、第五确定单元,用于将声音相似度小于或等于第一预设阈值的两个语料片段确定为候选语料片段;
50、第三获取单元,用于针对每个候选语料片段,获取所述候选语料片段与每个语者的语料片段之间的声音相似度;
51、第六确定单元,用于若所述候选语料片段与每个语者的语料片段之间的声音相似度大于第一预设阈值,确定所述候选语料片段为由所述人物作为实际的语者进行发声的语料片段。
52、第三方面,本技术提供了一种电子设备,包括处理器、通信接口、存储器和通信总线,其中,处理器,通信接口,存储器通过通信总线完成相互间的通信;
53、存储器,用于存放计算机程序;
54、处理器,用于执行存储器上所存放的程序时,实现第一方面任一所述的语料标注方法。
55、第四方面,本技术提供了一种计算机可读存储介质,所述计算机可读存储介质上存储有语料标注方法的程序,所述语料标注方法的程序被处理器执行时实现第一方面任一所述的语料标注方法的步骤。
56、本技术实施例提供的上述技术方案与现有技术相比具有如下优点:
57、本技术实施例通过自动将目标视频中提取属于不同人物的多个人脸图像所对应的语料片段,再为了提高准确性,在每个人物的多个人脸图像所对应的语料片段中,确定由所述人物作为实际的语者进行发声的语料片段,最后可以按照各所述语者的语者信息确定各所述语料片段的标注文本,实现自动对目标视频中的语料片段进行标注,进而可以便于得到大量的训练语料,以用于模型的训练,在保证训练语料获取的准确性的同时,提高训练语料的获取效率。
- 还没有人留言评论。精彩留言会获得点赞!