一种基于语音文本跨模态融合的情感识别方法及系统
本发明属于人工智能和情感交互,尤其是涉及一种基于语音文本跨模态融合的情感识别方法及系统。
背景技术:
1、在抑郁症等神经疾病日益严重的背景下,具有情感识别、互动和共情功能的情感交互系统在智能诊断和治疗方面都具有广泛的应用价值。
2、对于情感交互系统来说,识别并分析用户情感是重要的一环。情感通常以多种形式出现在对话中,如语音和文本,然而,现有的情绪识别系统多数仅使用单一模态的特征进行情绪识别,单模态识别系统面临情感解释不全面、分类不准确等局限。对多模态信息交互的忽略,导致现有情感识别能力尚且非常有限。其较低的情感识别准确率也无法在后续的情感交互过程中,给用户带来良好的服务体验。例如:cn202211554888.4公开了一种基于改进注意力机制的语音情感识别方法及装置,其包括对采集的音频信号样本进行数据预处理;对采集的音频信号样本提取声学特征,得到频谱特征图;构建卷积神经网络结合双向门控循环单元网络的cnn-bgru深度学习网络;构建msk改进注意力机制模块,将通过cnn-bgru深度学习网络得到的特征信息进行进一步处理;进而输出语音情感识别结果。但是单模态包含的情感信息有限从而限制了情感识别准确率。
3、虽然也有一些文献提出了融合视觉和听觉的多模态情感识别方法,但受简单拼接等融合方法的限制,导致现有情感识别方法在准确率和鲁棒性等方面无法满足动态场景下人机交互、临床诊疗的使用要求,依然限制了情感交互系统的应用与制备。为解决上述问题,需要一种基于语音文本跨模态融合的实时情感识别方法,用于识别对话中蕴含的情感。
4、此外,情感交互系统是通过赋予计算机人类的情感,使之具有识别、理解、表达情感的能力,情感表达能力也将直接影响用户的情感交互体验。如何表达丰富的情感状态并根据用户反馈进行自适应调整,是目前情感表达的难点。现有技术中情感交互系统在与用户进行交谈时,一般是从离线或在线语料数据库或聊天数据库中搜索出与用户问题相关的合理回答,图1为现有技术中语音交互系统与用户进行交谈的示意图。诸如图1的现有的大部分情感对话生成交互只考虑利用情感标签等情感表面信息来提高生成响应的质量,却忽略了情感背后更深层次的情感意图等细粒度特征,导致对话模型生成的回复共情性不足,无法满足用户的共情需求。
技术实现思路
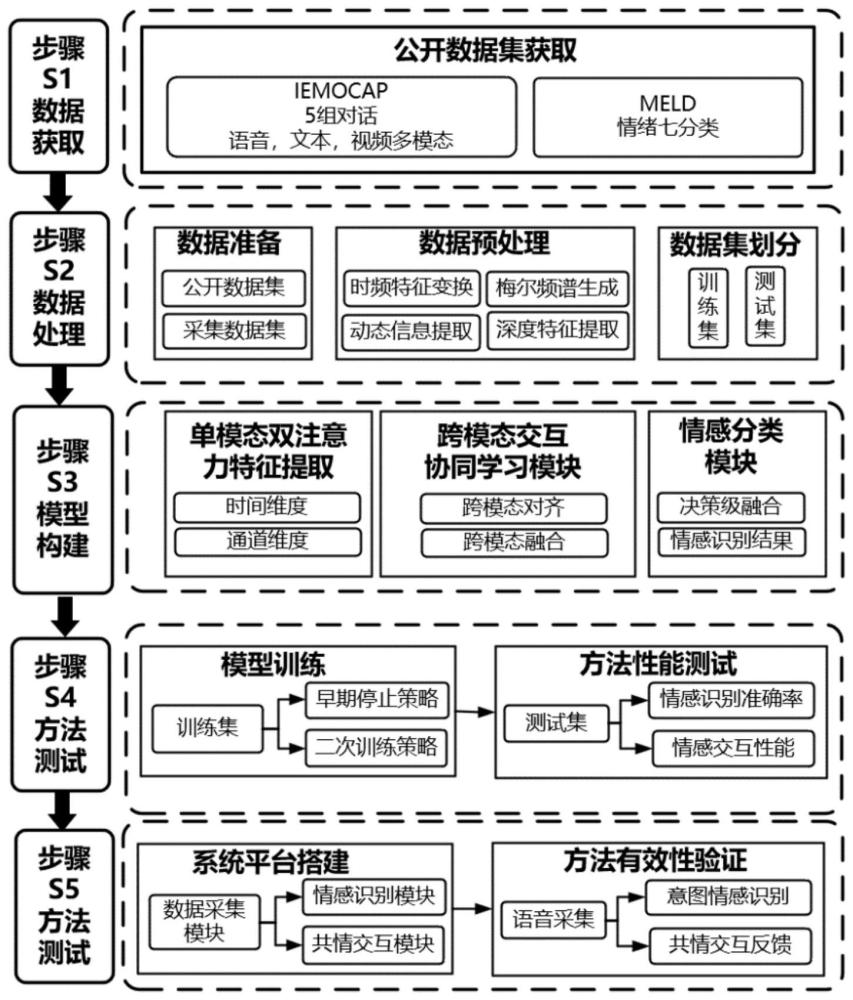
1、为解决现有基于深度学习的情感识别方法的识别准确率不高,缺乏多模态交互融合的问题,本发明提出了一种基于跨模态注意力融合的多模态情感识别方法。经过数据获取、数据处理、模型构建、方法测试和方法验证五个步骤,实现实时对话情感高准确率识别。在公开多模态对话数据集iemocap和meld数据集上对本方法进行了性能测试,加权准确率分布达到了76.0%和64.5%,均优于其他现有最优方法。此外,为解决现有情感识别系统表达僵硬,缺乏深度情感交流的问题,本发明研发了一个基于语音文本跨模态融合情感识别方法的智能情感交互系统,集成了数据采集模块、情感识别模块和交互模块,通过与5名志愿者进行情感交互对本方法进行了在线有效性验证,具备了向临床推广应用的条件。
2、本发明提供了一种基于跨模态交互多模态情感识别方法及系统。本发明人采用多模态公开数据集和采集数据,对方法进行了性能测试和有效性验证:先对获取的两个公开数据集iemocap和meld进行预处理,建立各自对应的训练集和测试集;其次构建多模态情感识别模型;然后将预处理好的训练集分别输入情感识别模型中进行模型训练,并将预处理好的测试集分别输入训练好的模型中进行方法的性能测试;最后搭建情感识别系统,进行方法的有效性验证。
3、根据本发明的一个实施例的一种基于跨模态融合的情感识别方法包括以下步骤:
4、步骤1:获取公开的情感对话数据集iemocap和meld;
5、步骤2:对获取的公开数据集进行预处理操作,并建立两个公开数据集各自对应的训练集和测试集;
6、步骤3:构建跨模态融合的情感识别神经网络;
7、步骤4:将步骤2中预处理后的两个训练集分别输入情感识别模型中,进行模型训练;
8、步骤5:再将步骤2中预处理的两个测试集输入训练好的识别模型中,进行方法的性能测试,并与现有最先进方法进行性能比对;
9、步骤6:搭建情感识别系统,利用所述系统与5名志愿者进行对话交流,通过记录人机交互过程中的识别准确率和对话流畅度,进行方法的有效性验证。
10、其中:
11、在步骤2中,数据预处理包括对音频信号进行预加重、分帧和加窗处理;对每一帧加窗后的特征通过快速傅里叶变换得到频谱,进而转化为梅尔频谱;
12、在步骤3中,所构建的跨模态融合多模态情感识别神经网络包括:单模态双注意力特征提取模块、跨模态注意力交互融合模块、决策层融合及情感分类模块依次串行连接,其中,单模态双注意力特征提取模块用于初步提取语音文本中的时域和通道维度的情感特征;跨模态注意力交互融合模块包含多模态特征对齐和多模态特征交互,用于提取深度情感语义特征;决策层融合分类模块用于输出情感识别结果,并为生成相应的情感共情交互回复奠定基础;
13、在步骤4中,进行模型训练时,先采用早期停止策略进行模型一次训练,保存好模型训练参数后,再进行模型二次训练,采用交叉熵函数计算梯度提升决策融合分类模块的输出与标签的误差,通过误差反向传播与随机梯度下降迭代更新模型参数;进行方法的性能测试时,语音信号采样频率为220hz,将划分后的数据输入训练好的情感识别模型中,并采用情感识别准确率、f1值来评价方法的识别性能;
14、在步骤5中,方法的有效性验证流程为:搭建情感识别系统,利用所述系统先进行5名所述志愿者语音数据的采集,其次按照步骤s2的方法进行数据预处理,并建立采集数据的训练集和测试集,再将预处理后的训练集输入步骤s3构建的情感识别模型中,按照步骤s4所述方法进行情感识别模型训练;然后利用所述系统再次进行5名志愿者语音数据的采集,通过记录人机情感交互过程,进行方法的有效性验证;
15、所述的情感交互系统可完成语音采集、语音预处理、模型构建、模型训练、情感识别和共情交互反馈,其中,交互反馈是基于所述的情感识别的分类结果及其与对应关系,并生成相应的共情回复。
16、本发明提出的一种基于跨模态融合的多模态情感识别方法及系统的主要优点包括:
17、1.本发明设计的单模态双注意力特征提取模块,基于双注意力机制的语音情感识别方法在传统时域注意力机制的基础上引入通道维度的注意力,可以大幅度减少多余的注意力得分计算来降低模型耗时,有效提高了语音情感识别的检测准确率,解决了当前用于语音情感识别的神经网络中对不同帧和不同通道关注度相同无法高效捕捉情感信息的问题。
18、2.本发明设计的跨模态注意力交互融合模块,通过充分利用语音和文本模态之间的互补性,计算加权特征融合中的语音权重和文本语义权重,提取高阶情感特征,最后将加权后的语音高阶情感特征和加权后的文本高阶情感特征输入到多层感知机mlp中进行加权特征融合并完成情感分类,有效地提高了多模态情感识别的准确率。在公开数据集iemocap和meld数据集上对本方法进行了有效性验证,加权准确率达到了76.0%和64.5%,均优于其他现有最优方法;
19、3.本发明设计的决策层融合分类模块,通过模态间的交互实现语音文本多模态对齐和融合,解决了单一模态情感信息提取不足的问题。
20、4.本发明搭建的情感识别系统,通过将数据采集模块、情感识别模块和交互模块集成,增强了人机情感交互性和丰富度,5名志愿者对本方法和本系统进行了在线有效性验证,满足人机交互系统实用性的要求。
- 还没有人留言评论。精彩留言会获得点赞!