多采样率的音频数据生成方法、生成器及存储介质与流程
本发明涉及语音合成领域,特别涉及一种多采样率的音频数据生成方法、生成器及存储介质。
背景技术:
1、现如今,人工智能飞速发展,人工智能发展历程中语音合成技术是一项不可忽视的技术。语音合成技术是一种将文本转换为人类语音的技术,它赋予人工智能说话的能力。语音合成技术通常包含两个阶段:声学模型和声码器;声学模型,将文本信息转换为代表发音信息的显示或隐式编码;声码器,则将语音编码转换为语音,而这一过程需要对发音细节进行重建,因此,声码器是语音合成音质和耗时的决定部分。
2、声码器通常由生成器模型和判别器模型组成,声码器的生成器,不但需要负责将频谱从频域转换到时域,而且要进行上采样。但在不同使用场景或不同的计算设备上,对语音合成的音质和耗时都有不同的要求。比如,嵌入式设备因为计算能力有限,为了减少耗时常采用较低采样率的语音合成;但在计算能力充足的云平台,为了追求更好的音质效果,通常会采用较高采样率的语音合成。
3、现有技术中针对每种采样率都会训练一种生成器模型,在不同场景需求下的语音合成需要使用不同采样率的模型,每个模型都需要重新训练,重新训练模型浪费时间和资源且过于繁琐,同时训练出的模型只能生成一种固定采样率的音频。
技术实现思路
1、本发明实施方式的目的在于提供一种多采样率的音频数据生成方法、生成器及存储介质,通过本申请方法能够选择性输出多种采样率的音频数据,适用于不同的使用场景,提高了不同场景下的音频数据生成效率。
2、为解决上述技术问题,本发明的实施方式提供了一种多采样率的音频数据生成方法,包括:
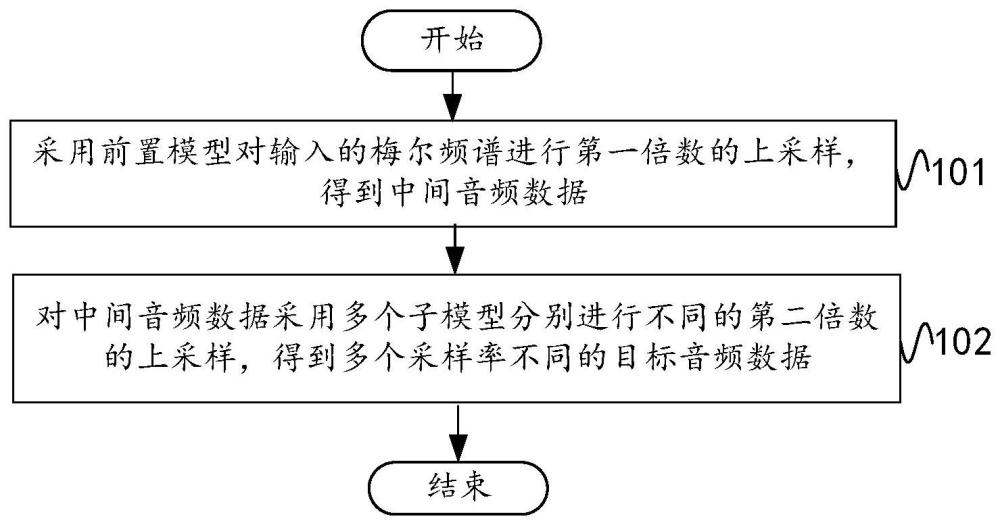
3、采用前置模型对输入的梅尔频谱进行第一倍数的上采样,得到中间音频数据;
4、对所述中间音频数据采用多个子模型分别进行不同的第二倍数的上采样,得到多个采样率不同的目标音频数据。
5、本发明的实施方式还提供了一种生成器,包括:前置模型与多个子模型;
6、所述前置模型用于对输入的梅尔频谱进行第一倍数的上采样,得到中间音频数据;
7、所述多个子模型用于对所述中间音频数据分别进行不同的第二倍数的上采样,得到多个采样率不同的目标音频数据。
8、本发明的实施方式还提供了一种计算机可读存储介质,存储有计算机程序,所述计算机程序被处理器执行时实现如上所述的多采样率的音频数据生成方法。
9、本发明实施方式相对于现有技术而言,通过采用前置模型对输入的梅尔频谱进行第一倍数的上采样,得到中间音频数据;对中间音频数据采用多个子模型分别进行不同的第二倍数的上采样,得到多个采样率不同的目标音频数据。本申请方案经前置模型进行梅尔频谱进行一次上采样后,中间音频数据可以输入与前置模型相连的多个子模型中任意一个子模型中,以输出对应采样率的音频数据。即,本申请方法能够选择性输出多种采样率的音频数据,适用于不同的使用场景,提高了设备在不同场景下的音频数据生成效率。
10、在一些实施例中,确定所述前置模型进行上采样的所述第一倍数,包括:确定在预设时长内以所述多个采样率分别对所述梅尔频谱进行上采样后所得到的各音频数据所对应的采样数量;选择所述各音频数据所对应的采样数量中,除1以外的任一公约数作为所述第一倍数,所述各音频数据所对应的采样数量具有至少两个公约数。
11、在一些实施例中,确定所述子模型进行上采样的所述第二倍数包括:将在所述预设时长内以该子模型所输出的目标音频数据的采样率对所述梅尔频谱上采样得到的音频数据所对应的采样数量除以所述第一倍数所得到的商值作为该子模型所对应的所述第二倍数。
12、在一些实施例中,确定所述子模型进行上采样的所述第二倍数包括:在确定出任一个所述子模型进行上采样的所述第二倍数后,根据该第二倍数、剩余各子模型所输出的目标音频数据的采样率与该任一个所述子模型所输出的目标音频数据的采样率之间的比值,确定所述剩余各子模型所对应的所述第二倍数。
13、在一些实施例中,所述预设时长为短时傅里叶变换的帧移。
14、在一些实施例中,所述多个采样率分别为8k、16k、24k和32k。
15、在一些实施例中,所述前置模型包括具有上采样功能的至少一个串接的前置模块;各所述前置模块进行上采样的倍数的乘积为所述第一倍数。
16、在一些实施例中,每个所述子模型包括具有上采样功能的至少一个串接的子模块;各所述子模块进行上采样的倍数的乘积为所述第二倍数。
技术特征:
1.一种多采样率的音频数据生成方法,其特征在于,包括:
2.根据权利要求1所述的方法,其特征在于,确定所述前置模型进行上采样的所述第一倍数,包括:
3.根据权利要求2所述的方法,其特征在于,确定所述子模型进行上采样的所述第二倍数包括:
4.根据权利要求2所述的方法,其特征在于,确定所述子模型进行上采样的所述第二倍数包括:
5.根据权利要求2所述的方法,其特征在于,所述预设时长为短时傅里叶变换的帧移。
6.根据权利要求1所述的方法,其特征在于,所述多个采样率分别为8k、16k、24k和32k。
7.根据权利要求1所述的方法,其特征在于,所述前置模型包括具有上采样功能的至少一个串接的前置模块;各所述前置模块进行上采样的倍数的乘积为所述第一倍数。
8.根据权利要求1所述的方法,其特征在于,每个所述子模型包括具有上采样功能的至少一个串接的子模块;各所述子模块进行上采样的倍数的乘积为所述第二倍数。
9.一种生成器,其特征在于,包括:前置模型与多个子模型;
10.一种计算机可读存储介质,存储有计算机程序,其特征在于,所述计算机程序被处理器执行时实现权利要求1至8中任一项所述的多采样率的音频数据生成方法。
技术总结
本发明实施例涉及信号处理领域,公开了一种多采样率的音频数据生成方法、生成器及存储介质。其中,方法包括:采用前置模型对输入的梅尔频谱进行第一倍数的上采样,得到中间音频数据;对所述中间音频数据采用多个子模型分别进行不同的第二倍数的上采样,得到多个采样率不同的目标音频数据。本申请方案能够选择性输出多种采样率的音频数据,适用于不同的使用场景,提高了设备在不同场景下的音频数据生成效率。
技术研发人员:董天旭,车云飞
受保护的技术使用者:达闼机器人股份有限公司
技术研发日:
技术公布日:2024/4/17
- 还没有人留言评论。精彩留言会获得点赞!