跨语言语音生成方法、系统及存储介质与流程
本发明涉及语音合成,尤其涉及一种跨语言语音生成方法、系统及存储介质。
背景技术:
1、tts技术(文本转语音技术)隶属于语音合成,语音合成解决的主要问题就是如何将计算机自己产生的、或外部输入的文字信息转化为特定说话人说出让人可以听得懂的、流利的声音信息。相关技术中,在使用端到端的神经网络tts模型时,大多数说话者的数据只有一种语言,收集双语者的录音也很昂贵。同时,要经过长达数小时甚至数天的训练时间才能完成训练,并且需要多次部署训练后的模型才能交付产品。另外,通过预训练(无需再训练)迁移克隆模型的方式效果不佳,对输入的说话人语音有长度和数量的限制,输入只能指定一种语言,当输入混合语言的文本,将会跳过其他语言的文本,获得的仅有指定语言的语音。因此,以上技术问题亟需解决。
技术实现思路
1、为了解决上述技术问题的至少之一,本发明提出一种跨语言语音生成方法、系统及存储介质,能够实现在不同语言之间目标对象的语音生成,并且能够有效提高语音生成的完整性和可靠性。
2、一方面,本发明实施例提供了一种跨语言语音生成方法,包括以下步骤:
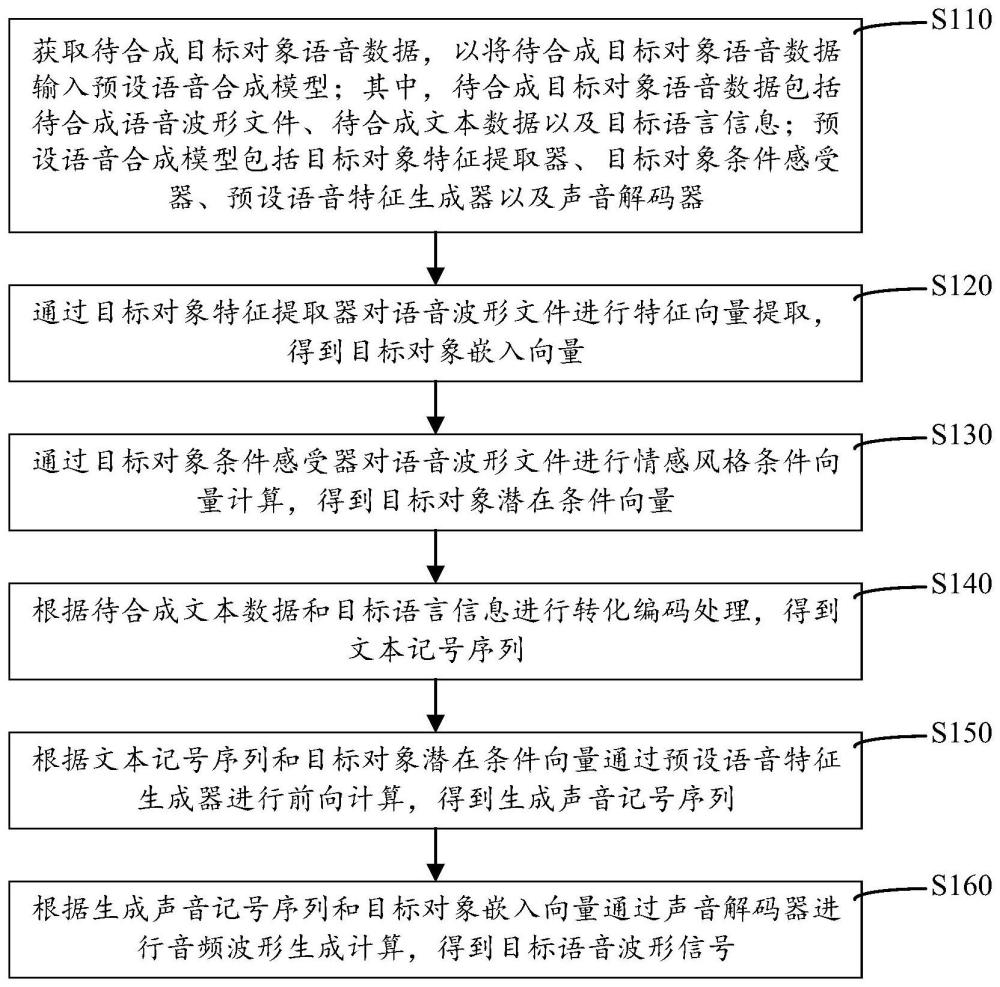
3、获取待合成目标对象语音数据,以将所述待合成目标对象语音数据输入预设语音合成模型;其中,所述待合成目标对象语音数据包括目标对象语音波形文件、待合成文本数据以及目标语言信息;所述预设语音合成模型包括目标对象特征提取器、目标对象条件感受器、预设语音特征生成器以及声音解码器;
4、通过所述目标对象特征提取器对所述语音波形文件进行特征向量提取,得到目标对象嵌入向量;
5、通过所述目标对象条件感受器对所述语音波形文件进行情感风格条件向量计算,得到目标对象潜在条件向量;
6、根据所述待合成文本数据和所述目标语言信息进行转化编码处理,得到文本记号序列;
7、根据所述文本记号序列和所述目标对象潜在条件向量通过所述预设语音特征生成器进行前向计算,得到生成声音记号序列;
8、根据所述生成声音记号序列和所述目标对象嵌入向量通过所述声音解码器进行音频波形生成计算,得到目标语音波形信号。
9、根据本发明的一些实施例,在执行所述通过所述目标对象特征提取器对所述语音波形文件进行特征向量提取,得到目标对象嵌入向量这一步骤之前,所述方法还包括:
10、根据预设静默阈值对所述语音波形文件进行裁剪,得到第一语音信号;
11、对所述第一语音信号进行振幅标准化处理,得到第二语音信号。
12、根据本发明的一些实施例,所述根据所述待合成文本数据和所述目标语言信息进行转化编码处理,得到文本记号序列,包括:
13、根据所述目标语言信息将所述待合成文本数据进行可读转化处理,得到发音文本数据;
14、根据预设映射规则对所述发音文本数据进行音素映射,得到音素序列;
15、将所述音素序列映射至相应的整数编码,得到音素编码信息;
16、按照预设字符字典将所述待合成文本数据中的字符进行转化处理,得到文本标记;
17、根据所述文本标记和所述音素编码信息生成所述文本记号序列。
18、根据本发明的一些实施例,所述目标对象条件感受器包括第一注意力机制模块和第二注意力机制模块;
19、所述通过所述目标对象条件感受器对所述语音波形文件进行情感风格条件向量计算,得到目标对象潜在条件向量,包括:
20、将所述语音波形文件输入所述第一注意力机制模块进行编码,以提取得到目标对象情感风格信息;
21、将所述目标对象情感风格信息输入所述第二注意力机制模块进行重采样操作,得到所述目标对象潜在条件向量。
22、根据本发明的一些实施例,在执行所述获取待合成目标对象语音数据,以将所述待合成目标对象语音数据输入预设语音合成模型这一步骤之前,所述方法还包括:
23、将所述第二语音信号输入向量量化变分自编码器模型进行离散潜在表示计算,得到目标声音记号序列;其中,所述向量量化变分自编码器模型通过预训练得到;
24、根据所述目标声音记号序列和所述生成声音标记序列对所述预设语音合成模型进行权重更新。
25、根据本发明的一些实施例,所述向量量化变分自编码器模型包括编码器、量化器以及解码器;
26、所述将所述第二语音信号输入所述向量量化变分自编码器模型进行离散潜在表示计算,得到目标声音记号序列,包括:
27、通过所述编码器将所述第二语音信号映射至潜在空间,生成潜在表示数据;
28、通过所述量化器将所述潜在表示数据进行离散化处理,得到量化表示数据;
29、通过所述解码器对所述量化表示数据进行数据重构,得到所述目标声音记号序列。
30、根据本发明的一些实施例,所述根据所述目标声音记号序列和所述生成声音标记序列对所述预设语音合成模型进行权重更新,包括:
31、根据所述目标声音记号序列和所述生成声音记号序列进行损失计算,得到第一损失数据;
32、根据所述第二语音信号和所述目标语音波形信号进行损失计算,得到第二损失数据;
33、根据所述第一损失数据和所述第二损失数据构建预设目标函数,并通过梯度下降法对所述预设目标函数进行优化,得到损失函数梯度;
34、通过所述损失函数梯度对所述预设语音合成模型进行权重更新。
35、另一方面,本发明实施例还提供了一种跨语言语音生成系统,包括:
36、第一模块,用于获取待合成目标对象语音数据,以将所述待合成目标对象语音数据输入预设语音合成模型;其中,所述待合成目标对象语音数据包括目标对象语音波形文件、待合成文本数据以及目标语言信息;所述预设语音合成模型包括目标对象特征提取器、目标对象条件感受器、预设语音特征生成器以及声音解码器;
37、第二模块,用于通过所述目标对象特征提取器对所述语音波形文件进行特征向量提取,得到目标对象嵌入向量;
38、第三模块,用于通过所述目标对象条件感受器对所述语音波形文件进行情感风格条件向量计算,得到目标对象潜在条件向量;
39、第四模块,用于根据所述待合成文本数据和所述目标语言信息进行转化编码处理,得到文本记号序列;
40、第五模块,用于根据所述文本记号序列和所述目标对象潜在条件向量通过所述预设语音特征生成器进行前向计算,得到生成声音记号序列;
41、第六模块,用于根据所述生成声音记号序列和所述目标对象嵌入向量通过所述声音解码器进行音频波形生成计算,得到目标语音波形信号。
42、另一方面,本发明实施例还提供了一种跨语言语音生成系统,包括:
43、至少一个处理器;
44、至少一个存储器,用于存储至少一个程序;
45、当所述至少一个程序被所述至少一个处理器执行,使得至少一个所述处理器实现如上述实施例所述的跨语言语音生成方法。
46、另一方面,本发明实施例还提供了一种计算机存储介质,其中存储有处理器可执行的程序,所述处理器可执行的程序在由所述处理器执行时用于实现如上述实施例所述的跨语言语音生成方法。
47、根据本发明实施例的一种跨语言语音生成方法、系统及存储介质,至少具有如下有益效果:本发明实施例首先获取待合成目标对象语音数据,以将待合成目标对象语音数据输入至预设语音合成模型。相应地,本发明实施例中待合成目标对象语音数据包括目标对象语音波形文件、待合成文本数据以及目标语言信息。另外,本发明实施例中预设语音合成模型包括目标对象特征提取器、目标对象条件感受器、预设语音特征生成器以及声音解码器。接着,本发明实施例通过目标对象特征提取器对语音波形文件进行特征向量提取,得到目标嵌入向量。然后,本发明实施例通过目标对象条件感受器对语音波形文件进行情感风格条件向量计算,得到目标对象潜在条件向量。同时,本发明实施例根据待合成文本数据和目标语言信息进行转化编码处理,得到文本记号序列。进一步地,本发明实施例根据文本记号序列和目标对象潜在条件向量通过预设语音特征生成器进行前向计算,得到相应的生成声音记号序列,进而根据生成声音记号序列和目标对象嵌入向量通过声音解码器进行音频波形生成计算,得到目标语音波形信号,从而实现目标对象的语音生成。容易理解的是,本发明实施例通过根据待合成文本数据以及目标语言信息进行转化编码处理,并根据文本记号序列和目标对象潜在条件向量通过预设语音特征生成器进行前向计算的方式,能够将待合成文本数据转化成相应的语言的可度发音文本,得到相应的生成声音记号序列,从而缓解了生成的语音不完整的问题,同时,通过结合生成声音记号序列以及目标对象嵌入向量的方式,从而能够生成目标对象在相应语言下的语音,从而实现在不同语言之间目标对象的语音生成,并有效提高语音生成的完整性和可靠性。
- 还没有人留言评论。精彩留言会获得点赞!