音频调整方法、系统、计算机设备和计算机可读存储介质
所属的技术人员知道,本发明可以实现为系统、方法或计算机程序产品,因此,本公开可以具体实现为以下形式,即:可以是完全的硬件、也可以是完全的软件(包括固件、驻留软件、微代码等),还可以是硬件和软件结合的形式,本文一般称为“电路”、“模块”或“系统”。此外,在一些实施例中,本发明还可以实现为在一个或多个计算机可读介质中的计算机程序产品的形式,该计算机可读介质中包含计算机可读的程序代码。可以采用一个或多个计算机可读的介质的任意组合。计算机可读介质可以是计算机可读信号介质或者计算机可读存储介质。计算机可读存储介质例如可以是一一但不限于——电、磁、光、电磁、红外线、或半导体的系统、装置或器件,或者任意以上的组合。计算机可读存储介质的更具体的例子(非穷举的列表)包括:具有一个或多个导线的电连接、便携式计算机磁盘、硬盘、随机存取存储器(ram),只读存储器(rom)、可擦式可编程只读存储器(eprom或闪存)、光纤、便携式紧凑磁盘只读存储器(cd-rom)、光存储器件、磁存储器件、或者上述的任意合适的组合。在本文件中,计算机可读存储介质可以是任何包含或存储程序的有形介质,该程序可以被指令执行系统、装置或者器件使用或者与其结合使用。尽管上面已经示出和描述了本发明的实施例,可以理解的是,上述实施例是示例性的,不能理解为对本发明的限制,本领域的普通技术人员在本发明的范围内可以对上述实施例进行变化、修改、替换和变型。
背景技术:
1、目前,若使同一首歌实现男女对唱效果、多人混唱效果或单人演唱效果时,需要录制该首歌的不同演唱版本,具有经济成本高、时间成本高的技术问题,且录制该首歌时,还可能会发生演唱失误等情况,进一步提高了时间成本。
技术实现思路
1、本发明所要解决的技术问题是针对现有技术的不足,具体针对现在录制歌曲中存在的经济成本高和时间成本高等问题,具体提供了一种音频调整方法、系统、计算机设备和计算机可读存储介质,以降低经济成本和时间成本,具体如下:
2、1)第一方面,本发明提供一种音频调整方法,具体技术方案如下:
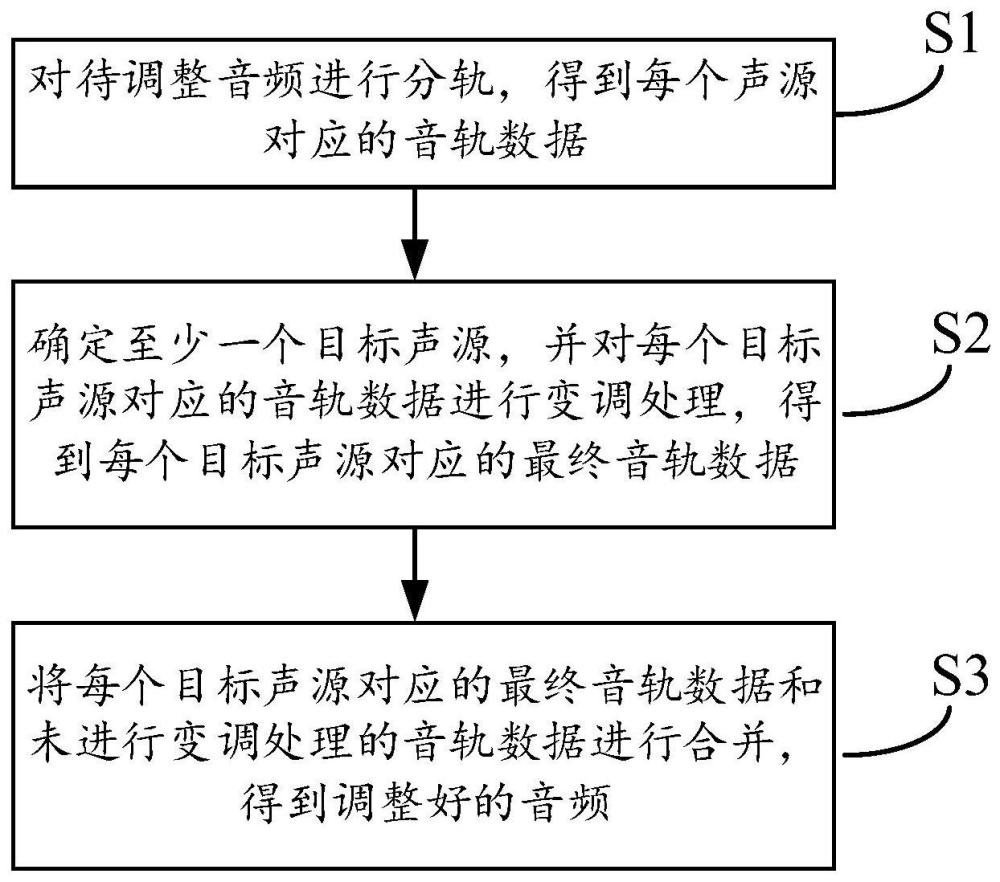
3、对待调整音频进行分轨,得到每个声源对应的音轨数据;
4、确定至少一个目标声源,并对每个目标声源对应的音轨数据进行变调处理,得到每个目标声源对应的最终音轨数据;
5、将每个目标声源对应的最终音轨数据和未进行变调处理的音轨数据进行合并,得到调整好的音频。
6、本发明提供的一种音频调整方法的有益效果如下:
7、只需要录制一次音频,通过对声源对应的音轨数据进行变调处理,能够更灵活地实现不同的音频效果,极大降低经济成本和时间成本。
8、在上述方案的基础上,本发明的一种音频调整方法还可以做如下改进。
9、进一步,还包括:
10、当所述待调整音频为音乐时,且当用户正在听调整好的音乐时,获取所述用户的面部图像;
11、根据所述用户的面部图像,对所述用户的情绪进行识别,得到所述用户的情绪识别结果;
12、根据所述用户的情绪识别结果,调整正在播放的所述调整好的音乐的音量和节奏。
13、采用上述进一步方案的有益效果是:通过对用户情绪进行准确识别,然后调整正在播放的所述调整好的音乐的音量和节奏,以达到为用户调节情绪的目的。
14、进一步,还包括:
15、当所述待调整音频为音乐时,且当用户正在听调整好的音乐时,获取含有所述用户的面部的视频,从所述视频中提取多个关键帧,将每个关键帧分别输入训练好的情绪识别模型,得到每个关键帧对应的情绪识别结果;
16、根据每个关键帧对应的情绪识别结果,确定所述用户的最终的情绪识别结果;
17、根据所述用户的最终的情绪识别结果,调整正在播放的所述调整好的音乐的音量和节奏。
18、采用上述进一步方案的有益效果是:通过对用户情绪进行准确识别,然后调整正在播放的所述调整好的音乐的音量和节奏,以达到为用户调节情绪的目的。
19、进一步,还包括:对初始音频进行去噪处理后,得到所述待调整音频。
20、采用上述进一步方案的有益效果是:通过对初始音频进行去噪处理,能够获取更高质量的待调整音频如音乐等,能够满足用户需求,提高用户体验度。
21、2)第二方面,本发明还提供一种音频调整系统,具体技术方案如下:
22、包括分轨模块、变调处理模块和合并模块;
23、所述分轨模块用于:对待调整音频进行分轨,得到每个声源对应的音轨数据;
24、所述变调处理模块用于:确定至少一个目标声源,并对每个目标声源对应的音轨数据进行变调处理,得到每个目标声源对应的最终音轨数据;
25、所述合并模块用于:将每个目标声源对应的最终音轨数据和未进行变调处理的音轨数据进行合并,得到调整好的音频。
26、在上述方案的基础上,本发明的一种音频调整系统还可以做如下改进。
27、进一步,还包括第一识别调整模块,所述第一识别调整模块用于:
28、当所述待调整音频为音乐时,且当用户正在听调整好的音乐时,获取所述用户的面部图像;
29、根据所述用户的面部图像,对所述用户的情绪进行识别,得到所述用户的情绪识别结果;
30、根据所述用户的情绪识别结果,调整正在播放的所述调整好的音乐的音量和节奏。
31、进一步,还包括第二识别调整模块,所述第二识别调整模块用于:
32、当所述待调整音频为音乐时,且当用户正在听调整好的音乐时,获取含有所述用户的面部的视频,从所述视频中提取多个关键帧,将每个关键帧分别输入训练好的情绪识别模型,得到每个关键帧对应的情绪识别结果;
33、根据每个关键帧对应的情绪识别结果,确定所述用户的最终的情绪识别结果;
34、根据所述用户的最终的情绪识别结果,调整正在播放的所述调整好的音乐的音量和节奏。
35、进一步,还包括去噪模块,所述去噪模块用于:对初始音频进行去噪处理后,得到所述待调整音频。
36、3)第三方面,本发明还提供一种计算机设备,计算机设备包括处理器,处理器与存储器耦合,存储器中存储有至少一条计算机程序,至少一条计算机程序由处理器加载并执行,以使计算机设备实现上述任一种音频调整方法。
37、4)第四方面,本发明还提供一种计算机可读存储介质,计算机可读存储介质中存储有至少一条计算机程序,至少一条计算机程序由处理器加载并执行,以使计算机实现上述任一种音频调整方法。
38、需要说明的是,本发明的第二方面至第四方面的技术方案及对应的可能的实现方式所取得的有益效果,可以参见上述对第一方面及其对应的可能的实现方式的技术效果,此处不再赘述。
技术特征:
1.一种音频调整方法,其特征在于,包括:
2.根据权利要求1所述的一种音频调整方法,其特征在于,还包括:
3.根据权利要求1所述的一种音频调整方法,其特征在于,还包括:
4.根据权利要求1至3任一项所述的一种音频调整方法,其特征在于,还包括:对初始音频进行去噪处理后,得到所述待调整音频。
5.一种音频调整系统,其特征在于,包括分轨模块、变调处理模块和合并模块;
6.根据权利要求5所述的一种音频调整系统,其特征在于,还包括第一识别调整模块,所述第一识别调整模块用于:
7.根据权利要求5所述的一种音频调整系统,其特征在于,还包括第二识别调整模块,所述第二识别调整模块用于:
8.根据权利要求5至7任一项所述的一种音频调整系统,其特征在于,还包括去噪模块,所述去噪模块用于:
9.一种计算机设备,其特征在于,所述计算机设备包括处理器,所述处理器与存储器耦合,所述存储器中存储有至少一条计算机程序,所述至少一条计算机程序由所述处理器加载并执行,以使所述计算机设备实现权利要求1至4任一项所述的一种音频调整方法。
10.一种计算机可读存储介质,其特征在于,所述计算机可读存储介质中存储有至少一条计算机程序,所述至少一条计算机程序由处理器加载并执行,以使计算机实现权利要求1至4任一项所述的一种音频调整方法。
技术总结
本发明公开了一种音频调整方法、系统、计算机设备和计算机可读存储介质,涉及音频处理技术领域,方法包括:对待调整音频进行分轨,得到每个声源对应的音轨数据;确定至少一个目标声源,并对每个目标声源对应的音轨数据进行变调处理,得到每个目标声源对应的最终音轨数据;将每个目标声源对应的最终音轨数据和未进行变调处理的音轨数据进行合并,得到调整好的音频。本发明只需要录制一次音频,通过对声源对应的音轨数据进行变调处理,能够更灵活地实现不同的音频效果,极大降低经济成本和时间成本。
技术研发人员:岳伯禹,李成
受保护的技术使用者:北京航空航天大学
技术研发日:
技术公布日:2024/4/17
- 还没有人留言评论。精彩留言会获得点赞!