一种演讲者识别方法及其装置、设备、存储介质与流程
本申请涉及语音识别领域,特别是涉及一种演讲者识别方法及其装置、设备、存储介质。
背景技术:
1、现有的语音识别技术在复杂场景中识别仍然存在一定的难度,需要进一步改进和优化。例如,在多人会话的场景中,目前的语音识别技术往往需要通过匹配发言人的语音特征,从而预测之后的发言人及其发言内容。但是,该方法对于发言人语音特征的提取和匹配仍然存在一定的误差和偏差,导致在动态变化的会话场景中往往难以适应,从而使得预测的准确率较低。
技术实现思路
1、本申请至少提供一种演讲者识别方法及其装置、设备、存储介质,能够提高当前语音之后的发言内容及其目标发言人识别的准确性。
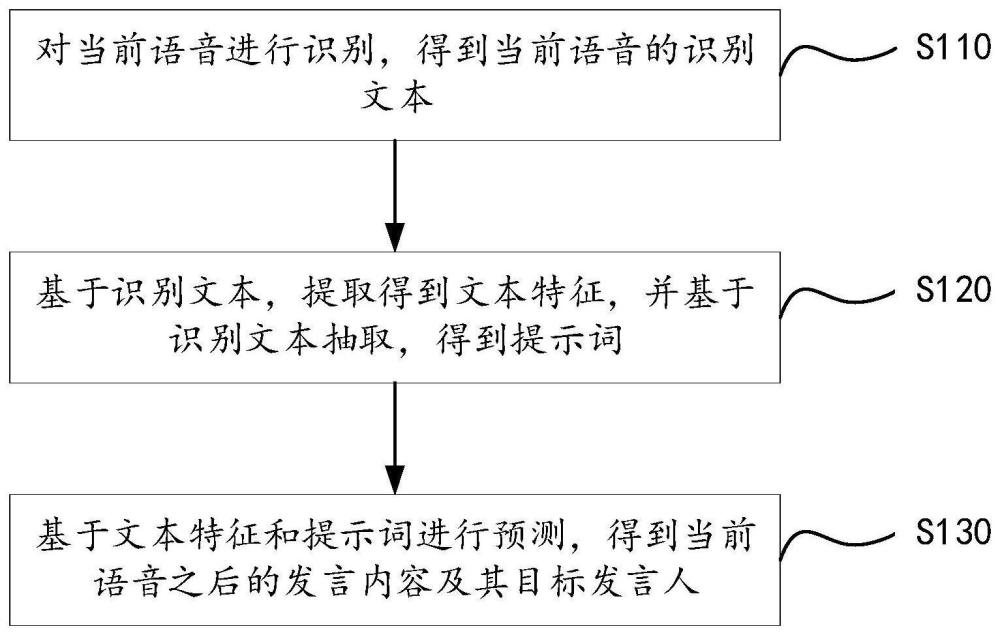
2、本申请第一方面提供了一种演讲者识别方法,该方法包括:对当前语音进行识别,得到当前语音的识别文本;基于识别文本,提取得到文本特征,并基于识别文本抽取,得到提示词,其中,提示词指示当前语音之后的发言内容中涵盖的字词类别;基于文本特征和提示词进行预测,得到当前语音之后的发言内容及其目标发言人。
3、本申请第二方面提供了一种演讲者识别装置,包括:文本识别模块,用于对当前语音进行识别,得到当前语音的识别文本;特征提取模块,用于基于识别文本,提取得到文本特征,并基于识别文本进行抽取,得到提示词;预测模块,用于基于文本特征和提示词进行预测,得到当前语音之后的发言内容及其目标发言人,其中,提示词用于指示当前语音之后的发言内容中的字词所属类别。
4、本申请第三方面提供了一种电子设备,包括相互耦接的存储器和处理器,处理器用于执行存储器中存储的程序指令,以实现上述第一方面中的演讲者识别方法。
5、本申请第四方面提供了一种计算机可读存储介质,其上存储有程序指令,程序指令被处理器执行时实现上述第一方面中的演讲者识别方法。
6、上述方案,通过对当前语音继续宁识别,得到当前语音的识别文本,并利用得到的识别文本进行特征提取,得到文本特征,对识别文本进行文本抽取,得到提示词,通过提示词可提示当前语音之后的内容所涵盖的字词类别,从而可缩小当前语音之后的发言内容的检索范围,并结合文本特征,通过文本特征可在缩小后的检索范围内生成当前语音之后的发言内容,以使得生成的发言内容与识别文本关联度高,并且也可利用文本特征和提示词对当前语音之后的发言人进行预测,得到目标发言人,从而能够提高当前语音之后的发言内容及其目标发言人识别的准确性。
7、应当理解的是,以上的一般描述和后文的细节描述仅是示例性和解释性的,而非限制本申请。
技术特征:
1.一种演讲者识别方法,其特征在于,包括:
2.根据权利要求1所述的方法,其特征在于,所述基于所述识别文本,提取得到文本特征,包括:
3.根据权利要求1所述的方法,其特征在于,所述基于所述文本特征和所述提示词进行预测,得到所述当前语音之后的发言内容,包括:
4.根据权利要求3所述的方法,其特征在于,所述文本特征至少包括上下文特征,所述利用所述文本特征和所述提示词,得到所述当前语音之后的若干预测字词,包括:
5.根据权利要求3所述的方法,其特征在于,所述基于声学信息和所述若干预测字词,确定所述当前语音之后的发言内容,包括:
6.根据权利要求5所述的方法,其特征在于,所述规整操作包括以下至少一个操作:调换所述若干预测字词的位置顺序、在所述若干预测字词中补充隐藏字词。
7.根据权利要求1所述的方法,其特征在于,所述得到目标发言人的确定步骤,包括:
8.根据权利要求7所述的方法,其特征在于,所述文本特征包括语义特征和上下文特征;所述基于所述文本特征,选取所述候选发言人作为所述目标发言人,包括:
9.一种演讲者识别装置,其特征在于,包括:
10.一种电子设备,其特征在于,包括相互耦接的存储器和处理器,所述处理器用于执行所述存储器中存储的程序指令,以实现权利要求1至8任一项所述的演讲者识别方法。
11.一种计算机可读存储介质,其上存储有程序指令,其特征在于,所述程序指令被处理器执行时实现权利要求1至8任一项所述的演讲者识别方法。
技术总结
本申请公开了一种演讲者识别方法及其装置、设备、存储介质,该方法包括:对当前语音进行识别,得到当前语音的识别文本;基于识别文本,提取得到文本特征,并基于识别文本抽取,得到提示词,其中,提示词指示当前语音之后的发言内容中涵盖的字词类别;基于文本特征和提示词进行预测,得到当前语音之后的发言内容及其目标发言人。上述方案,能够提高当前语音之后的发言内容及其目标发言人识别的准确性。
技术研发人员:许乾坤,高建清,马峰,管青松
受保护的技术使用者:科大讯飞股份有限公司
技术研发日:
技术公布日:2024/4/17
- 还没有人留言评论。精彩留言会获得点赞!