一种基于语音识别的麦克风系统的制作方法
本发明涉及语音识别,尤其涉及一种基于语音识别的麦克风系统。
背景技术:
1、智能家居领域是现代生活水平不断提升而产生的新领域,随着人民生活水平的提升,住户对居住环境提出了更舒适、安全与便捷的要求,智能家居融合了计算机、自动化控制、人工智能等多项技术,将家庭环境中的各种设备终端连接在一起,实现智能化控制。
2、在智能家居中语音控制是最基础且最便捷的交互方式,智能语音技术使住户与各终端设备的控制方式向快捷方便的方向大幅迈进,集成语音识别的麦克风系统可以更好地实现对住户语音指令的清晰采集以及更加适用各种家庭场景,相关领域技术人员针对复杂的家庭环境不断优化语音识别麦克风系统的功能,使得语音交互方式成功为智能家居赋能。
3、例如,中国专利:cn105427861a,该发明公开了智能家居协同麦克风语音控制系统及控制方法,所述控制系统包括信号采集模块、控制中枢模块和云服务器;控制中枢模块包括语音监听模块、数据融合模块和降混响预处理模块,控制方法为:信号采集模块采集语音信号;控制中枢模块对语音信号进行降噪处理;云服务器识别语音信号,解析语音指令。
4、现有技术中还存在以下问题;
5、现有技术未考虑幼童通过语音交互对智能家居发出控制指令造成控制对象随意工作引发危险,现有技术不能直接根据声源的特定特征数据化直观地表征声源年龄,并对不同声源发出的指令进行选择性的执行,影响智能家居语音交互的安全性,且,现有技术通过声纹特征对语音进行识别,影响智能家居语音交互的效率。
技术实现思路
1、为此,本发明提供一种基于语音识别的麦克风系统,用以克服现有技术中不能直接根据声源的特定特征数据化直观地表征声源年龄,且不能对不同声源发出的指令进行选择性的执行的问题。
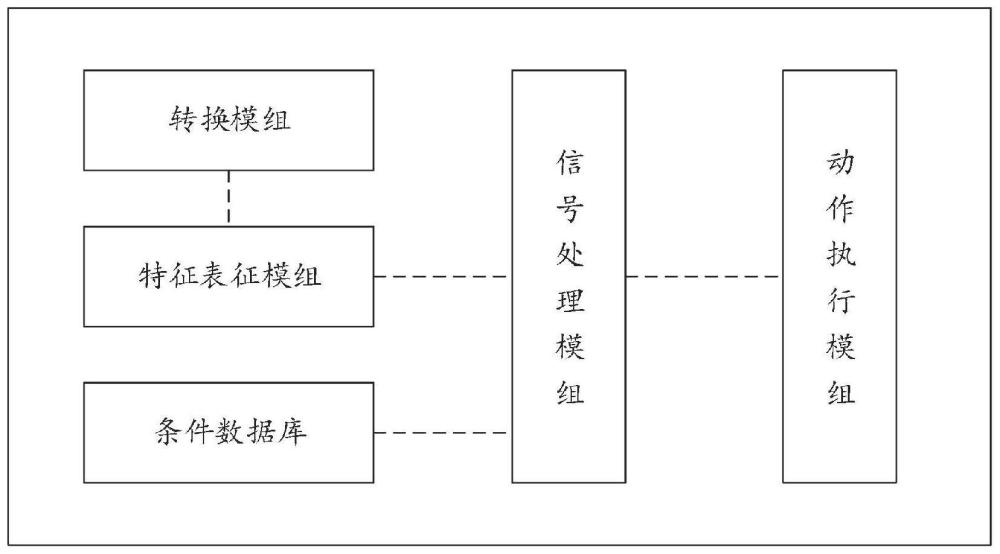
2、为实现上述目的,本发明提供基于语音识别的麦克风系统,包括:
3、转换模组,用以将采集的语音转换为声波信号,绘制声波时域图;
4、特征表征模组,其与所述转换单元连接,包括划分单元以及显性计算单元,所述划分单元用以基于所述声波时域图的振幅变化情况将所述声波时域图划分为若干第一显性声波时域子图以及若干第二显性声波时域子图;
5、所述显性计算单元用以基于各所述第一显性声波时域子图确定对应振幅值以及基于各所述第二显性声波时域子图确定对应时长,基于所述对应振幅值以及所述对应时长计算声源年龄评估系数,以判定是否需要对所述语音进行文本转换;
6、条件数据库,用以存储各控制对象关联的指令文本,并预先构建各指令文本所关联的触发条件,所述触发条件基于声源年龄评估系数预先设定;
7、信号处理模组,其与所述特征表征模组以及所述条件数据库连接,用以将所述语音转换为语音文本,以及基于所述语音文本与所述指令文本的语义相似度判定所述语音文本是否可以触发所述指令文本;
8、动作执行模组,其与所述信号处理模组连接,用以将所述语音文本对应的声源年龄评估系数与触发的指令文本所关联的触发条件进行匹配,根据匹配结果判定是否执行所述指令文本。
9、进一步地,所述划分单元还用以获取一定时间长度区间内所述声波时域图上每隔预定时间间隔的采集点的振幅值,计算若干采集点振幅值的标准差,将所述标准差确定为振幅标准差。
10、进一步地,所述划分单元将所述振幅标准差与预设的振幅标准差参考值进行对比,以对所述声波时域图进行划分,
11、若所述振幅标准差小于或等于所述振幅标准差参考值,则所述划分单元将所述时间长度区间内的声波时域子图划分为第一显性声波时域子图;
12、若所述振幅标准差大于所述振幅标准差参考值,则所述划分单元将所述时间长度区间内的声波时域子图划分为第二显性声波时域子图。
13、进一步地,所述显性计算单元还用以确定所述第一显性声波时域子图内各波峰的振幅值,基于各所述波峰的振幅值计算波峰振幅平均值,将所述波峰振幅平均值确定为所述对应振幅值;
14、所述显性计算单元还用以确定所述第二显性声波时域子图的时间长度,将所述时间长度确定为所述对应时长。
15、进一步地,所述显性计算单元用以按照公式(1)计算声源年龄评估系数,
16、
17、公式(1)中,r为声源年龄评估系数,dav为若干对应振幅值的平均值,d0为预设的振幅值参考平均值,dc为若干对应振幅值的标准差,dc0为预设的振幅值参考标准差,tc为若干对应时长的标准差,tc0为预设的时长参考标准差,α为振幅值的平均值权重系数,β为振幅值的标准差权重系数,γ为时长的标准差权重系数,α+β+γ=1,e为常数。
18、进一步地,所述显性计算单元还用以将所述声源年龄评估系数与预设的声源年龄评估系数阈值进行对比,
19、若所述声源年龄评估系数小于或等于所述声源年龄评估系数阈值,则所述显性计算单元判定不需要对所述语音进行文本转换;
20、若所述声源年龄评估系数大于所述声源年龄评估系数阈值,则所述显性计算单元判定需要对所述语音进行文本转换。
21、进一步地,所述条件数据库内预先设定的所述触发条件由所述声源年龄评估系数的不同数值区间确定。
22、进一步地,所述信号处理模组还用以将所述语音文本与所述指令文本的语义相似度与预设的语义相似度阈值进行对比,
23、若所述语音文本与所述指令文本的语义相似度大于所述语义相似度阈值,则所述信号处理模组判定所述语音文本可以触发所述指令文本。
24、进一步地,所述动作执行模组还用以确定所述语音文本对应的声源年龄评估系数以及确定触发的指令文本所关联的触发条件对应的声源年龄评估系数的对应数值区间。
25、进一步地,所述动作执行模组将所述语音文本对应的声源年龄评估系数与所述对应数值区间进行匹配,
26、若所述语音文本对应的声源年龄评估系数在所述对应数值区间内,则所述动作执行模组判定执行所述指令文本。
27、与现有技术相比,本发明的有益效果在于,本发明通过设置转换模组、特征表征模组、条件数据库、信号处理模组以及动作执行模组,通过划分单元将声波时域图划分为若干第一显性声波时域子图以及若干第二显性声波时域子图,通过显性计算单元计算声源年龄评估系数,判定是否需要对语音进行文本转换,通过条件数据库存储各控制对象关联的指令文本,并预先构建触发各指令文本所关联的触发条件,通过信号处理模组基于语音文本与指令文本的语义相似度判定语音文本是否可以触发指令文本,通过动作执行模组将语音文本对应的声源年龄评估系数与指令文本所关联的触发条件进行匹配,根据匹配结果判定是否执行指令文本,进而,实现了直接根据声源的特定特征数据化直观地表征声源年龄,并对不同声源发出的指令进行选择性的执行,提升了智能家居语音交互的安全性以及高效性。
28、尤其,本发明通过设置划分单元将声波时域图划分为若干第一显性声波时域子图以及若干第二显性声波时域子图,在实际的语音识别过程中,声波时域图在用户发声过程中显示出来的振幅值是不断变化波动的,在语音中逐个字的发音在声波时域图中产生的幅值较大,在字与字之间的衔接发音段对应的声波时域图中幅值会明显减小,本发明通过划分单元将声波时域图中的振幅变化幅度较小的各个时间段内的图像划分为第一显性声波时域子图,将声波时域图中的振幅变化幅度较大的各个时间段内的图像划分为第二显性声波时域子图,进而,实现了直接对声波进行特定的特征提取,提升了智能家居语音交互的高效性。
29、尤其,本发明通过显性计算单元计算声源年龄评估系数,在实际的语音识别过程中,本发明中的第一显性声波时域子图是各发音文字的波形图,第二显性声波时域子图是各文字之间衔接处发音的波形图,语音识别相关领域技术人员熟知的是,儿童的声带和喉咙组织还在发育中,导致声音产生时声带的振动频率较高,儿童的讲话音调通常比成人更高,且,儿童的发音不稳定,相对而言会产生忽高忽低的音调,另外的,儿童的语速变化多端,本发明通过显性计算单元采集各第一显性声波时域子图确定对应振幅值的平均值来表征声源音调的高低,通过显性计算单元采集各第一显性声波时域子图确定对应振幅值的标准差来表征声源音调的波动程度,通过显性计算单元采集各第二显性声波时域子图确定对应时长的标准差来表征声源语速的波动程度,进而,实现了直接根据声源的特定特征,数据化直观地表征声源年龄,提升了智能家居语音交互的高效性。
30、尤其,本发明通过显性计算单元表征语音声源的年龄特征,如果判定声源的年龄特征太小,则不对语音内容进行文本转换,进而,不需要对语音内容进行分析,直接通过年龄特征的筛选可以舍弃一部分语音指令,既保证了儿童语音控制智能家居的安全性,也提高了语音数据识别的效率性,提升了智能家居语音交互的安全性以及高效性。
31、尤其,本发明通过动作执行模组将语音文本对应的声源年龄评估系数与触发的指令文本所关联的触发条件进行匹配,在实际的智能家居使用场景中,有些控制对象的动作会对儿童有危险风险,比如电动窗帘频繁拉合过程中,儿童拉拽绊倒等危险发生,基于各控制对象的动作可能会产生的危险,判定语音文本的声源年龄评估系数是否符合语音文本触发的指令文本对应的触发条件,然后再去选择是否执行,进而,实现了对不同声源发出的指令进行选择性的执行,提升了智能家居语音交互的安全性以及高效性。
- 还没有人留言评论。精彩留言会获得点赞!