一种语音合成方法、装置、电子设备及存储介质与流程
本技术涉及语音合成,尤其是涉及一种语音合成方法、装置、电子设备及存储介质。
背景技术:
1、随着人机语音交互技术的发展,语音合成的应用范围越来越广。如生活中常见的语音助手,智能音箱,地图导航等,以及近年来逐渐发展的有声读物,ai主播,歌唱合成等应用逐渐深入人们的生活。语音合成旨在对给定文本合成高质量语音,其中,小样本语音合成的研究目标是仅用很少语音数据学习该说话人声音的特点并进行语音合成。传统的语音合成模型在单个人的语音生成方面表现出色,但面临多样性、自然性和真实感等方面的限制。传统语音合成模型通常使用在录音室中高清音频录制的数据进行训练,但这限制了模型对真实世界多样性的理解。所以如何使语音合成系统更加灵活性适应更多的语音场景成为了不容小觑的技术问题。
技术实现思路
1、有鉴于此,本技术的目的在于提供一种语音合成方法、装置、电子设备及存储介质,通过提示音频学习目标音色的特征,而无需在训练阶段接触到特定说话人的语音样本,这种灵活性使得语音合成系统能够适应广泛的音色需求,从而更好地满足用户对合成语音的个性化要求,实现了可以通过零样本学习就可以复刻某个指定人的声音,并且可以达到很好的语音合成效果。
2、本技术实施例提供了一种语音合成方法,所述语音合成方法包括:
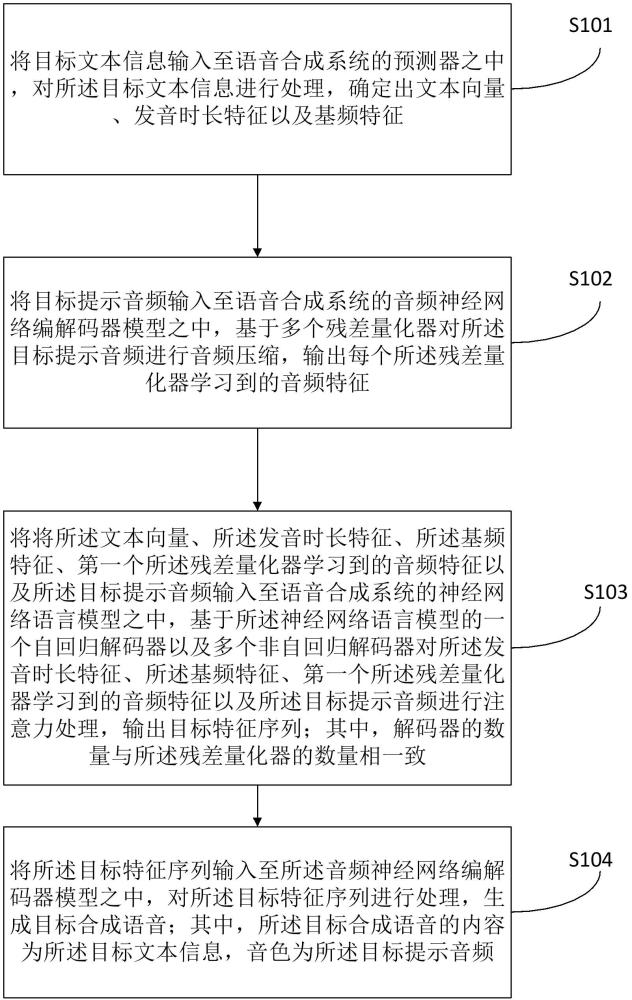
3、将目标文本信息输入至语音合成系统的预测器之中,对所述目标文本信息进行处理,确定出文本向量、发音时长特征以及基频特征;
4、将目标提示音频输入至语音合成系统的音频神经网络编解码器模型之中,基于多个残差量化器对所述目标提示音频进行音频压缩,输出每个所述残差量化器学习到的音频特征;
5、将所述文本向量、所述发音时长特征、所述基频特征、第一个所述残差量化器学习到的音频特征以及所述目标提示音频输入至语音合成系统的神经网络语言模型之中,基于所述神经网络语言模型的一个自回归解码器以及多个非自回归解码器对所述发音时长特征、所述基频特征、第一个所述残差量化器学习到的音频特征以及所述目标提示音频进行注意力处理,输出目标特征序列;其中,解码器的数量与所述残差量化器的数量相一致;
6、将所述目标特征序列输入至所述音频神经网络编解码器模型之中,对所述目标特征序列进行处理,生成目标合成语音;其中,所述目标合成语音的内容为所述目标文本信息,音色为所述目标提示音频。
7、在一种可能的实施方式之中,所述将目标文本信息输入至语音合成系统的预测器之中,对所述目标文本信息进行处理,确定出文本向量、发音时长特征以及基频特征,包括:
8、对所述目标文本信息进行编码处理,确定出所述目标文本信息的文本向量;
9、将所述文本向量输入至所述预测器的时长预测层之中,对所述文本向量的每个音素的发音时长进行预测,确定出所述文本向量的发音时长特征;
10、将所述文本向量输入至所述预测器的基频预测层之中,对所述文本向量的每个音素的基频进行预测,确定出所述文本向量的基频特征。
11、在一种可能的实施方式之中,所述将目标提示音频输入至语音合成系统的音频神经网络编解码器模型之中,基于多个残差量化器对所述目标提示音频进行音频压缩,输出每个所述残差量化器学习到的音频特征,包括:
12、基于八个所述残差量化器对所述目标提示音频进行音频压缩,确定所述目标提示音频的声学编码矩阵;其中,所述声学编码矩阵的行向量代表不同音频帧对应的编码信息,所述声学编码矩阵的列向量代表不同残差量化器的编码序列;
13、基于所述声学编码矩阵,确定出每个所述残差量化器学习到的音频特征。
14、在一种可能的实施方式之中,所述将所述文本向量、所述发音时长特征、所述基频特征、第一个所述残差量化器学习到的音频特征以及所述目标提示音频输入至语音合成系统的神经网络语言模型之中,基于所述神经网络语言模型的一个自回归解码器以及多个非自回归解码器对所述发音时长特征、所述基频特征、第一个所述残差量化器学习到的音频特征以及所述目标提示音频进行注意力处理,输出目标特征序列,包括:
15、将所述文本向量、所述发音时长特征、所述基频特征以及第一个所述残差量化器学习到的音频特征输入至所述自回归解码器进行注意力处理,生成第一特征序列;
16、将所述第一特征序列、所述文本向量、所述发音时长特征、所述基频特征以及所述目标提示音频输入至相对应的所述非自回归解码器之中进行注意力处理,生成多个特征序列;
17、将所述第一特征序列以及多个所述特征序列进行融合,生成所述目标特征序列。
18、在一种可能的实施方式之中,所述将所述文本向量、所述发音时长特征、所述基频特征以及第一个所述残差量化器学习到的音频特征输入至所述自回归解码器进行注意力处理,生成第一特征序列,包括:
19、将所述文本向量、所述发音时长特征、所述基频特征以及第一个所述残差量化器学习到的音频特征进行特征拼接,确定出拼接特征序列;
20、将所述拼接特征序列输入至所述自回归解码器之中,对时间步相对应的所述拼接特征序列中的维度特征进行注意力处理,输出的注意力处理后的维度特征会作为下一个时间步的输入,与下一时间步的维度特征共同进行自注意处理,直至t-1个时间步之前的所述拼接特征序列中的多个维度特征进行注意力处理结束后,生成所述第一特征序列。
21、在一种可能的实施方式之中,所述将所述第一特征序列、所述文本向量、所述发音时长特征、所述基频特征以及所述目标提示音频输入至相对应的所述非自回归解码器之中进行注意力处理,生成多个特征序列,包括:
22、将所述第一特征序列、所述文本向量、所述发音时长特征、所述基频特征以及所述目标提示音频的声学特征进行特征拼接,将拼接后的特征输入至第一个所述非自回归解码器之中进行注意力处理,生成第二特征序列;
23、将所述第一特征序列、所述文本向量、所述发音时长特征、所述基频特征、所述第二特征序列以及所述声学特征进行特征拼接,将拼接后的特征输入至第二个所述非自回归解码器之中进行注意力处理,以此类推,生成多个所述特征序列。
24、在一种可能的实施方式之中,通过以下步骤确定出所述神经网络语言模型:
25、将存在说话人信息的第一样本音色音频输入至所述音频神经网络编解码器模型之中,输出每个所述残差量化器学习到的样本音频特征;
26、将样本文本向量、样本发音时长特征、样本基频特征以及第一个残差量化器学习到的样本音频特征输入至初始神经网络语言模型的初始自回归解码器进行注意力处理,生成第一样本特征序列;
27、将所述样本文本向量、所述样本发音时长特征、所述样本基频特征以及不存在说话人信息的第二样本音色音频输入至所述初始神经网络语言模型之中相对应的初始非自回归解码器进行注意力计算,生成多个样本特征序列;
28、基于多个所述样本特征序列、所述样本第一特征序列以及多个所述样本音频特征确定出所述初始神经网络语言模型的损失值;
29、基于所述损失值对所述初始神经网络语言模型进行迭代训练,生成所述神经网络语言模型。
30、本技术实施例还提供了一种语音合成装置,所述语音合成装置包括:
31、文本处理模块,用于将目标文本信息输入至语音合成系统的预测器之中,对所述目标文本信息进行处理,确定出文本向量、发音时长特征以及基频特征;
32、音频压缩模块,用于将目标提示音频输入至语音合成系统的音频神经网络编解码器模型之中,基于多个残差量化器对所述目标提示音频进行音频压缩,输出每个所述残差量化器学习到的音频特征;
33、特征处理模块,用于将所述文本向量、所述发音时长特征、所述基频特征、第一个所述残差量化器学习到的音频特征以及所述目标提示音频输入至语音合成系统的神经网络语言模型之中,基于所述神经网络语言模型的一个自回归解码器以及多个非自回归解码器对所述发音时长特征、所述基频特征、第一个所述残差量化器学习到的音频特征以及所述目标提示音频进行注意力处理,输出目标特征序列;其中,解码器的数量与所述残差量化器的数量相一致;
34、音频生成模块,用于将所述目标特征序列输入至所述音频神经网络编解码器模型之中,对所述目标特征序列进行处理,生成目标合成语音;其中,所述目标合成语音的内容为所述目标文本信息,音色为所述目标提示音频。
35、本技术实施例还提供一种电子设备,包括:处理器、存储器和总线,所述存储器存储有所述处理器可执行的机器可读指令,当电子设备运行时,所述处理器与所述存储器之间通过总线通信,所述机器可读指令被所述处理器执行时执行如上述的语音合成方法的步骤。
36、本技术实施例还提供一种计算机可读存储介质,该计算机可读存储介质上存储有计算机程序,该计算机程序被处理器运行时执行如上述的语音合成方法的步骤。
37、本技术实施例提供的一种语音合成方法、装置、电子设备及存储介质,所述语音合成方法包括:将目标文本信息输入至语音合成系统的预测器之中,对所述目标文本信息进行处理,确定出文本向量、发音时长特征以及基频特征;将目标提示音频输入至语音合成系统的音频神经网络编解码器模型之中,基于多个残差量化器对所述目标提示音频进行音频压缩,输出每个所述残差量化器学习到的音频特征;将所述文本向量、所述发音时长特征、所述基频特征、第一个所述残差量化器学习到的音频特征以及所述目标提示音频输入至语音合成系统的神经网络语言模型之中,基于所述神经网络语言模型的一个自回归解码器以及多个非自回归解码器对所述发音时长特征、所述基频特征、第一个所述残差量化器学习到的音频特征以及所述目标提示音频进行注意力处理,输出目标特征序列;其中,解码器的数量与所述残差量化器的数量相一致;将所述目标特征序列输入至所述音频神经网络编解码器模型之中,对所述目标特征序列进行处理,生成目标合成语音;其中,所述目标合成语音的内容为所述目标文本信息,音色为所述目标提示音频。本方案的有益效果为通过提示音频学习目标音色的特征,而无需在训练阶段接触到特定说话人的语音样本,这种灵活性使得语音合成系统能够适应广泛的音色需求,从而更好地满足用户对合成语音的个性化要求,实现了可以通过零样本学习就可以复刻某个指定人的声音,并且可以达到很好的语音合成效果。
38、为使本技术的上述目的、特征和优点能更明显易懂,下文特举较佳实施例,并配合所附附图,作详细说明如下。
- 还没有人留言评论。精彩留言会获得点赞!