一种基于语音识别的虚拟交互方法及系统
本发明涉及语音交互领域,具体是一种基于语音识别的虚拟交互方法及系统。
背景技术:
1、现有技术中的可用于进行语音交互的智能助手、程序等,其在与用户进行语音交互输出中,输出的语音大多是语气情感固定的,或是基于输出语音的文字语义内容匹配相对应的语气氛围,例如输出的语音为训斥,则可以使用预设的偏向于凶狠的语气输出。
2、但是这种执行方式在用户需要进行心理沟通交互的场景下,则不太适用,当前ai技术快速发展,使用ai作为日常交互对象的技术将会在未来快速普及,因此使得ai在交互的过程中显得更加智能和人性化是有必要的,尤其可以在生活中作为用户的陪伴性存在,在当前的快节奏生活下为用户提供生活疏导及心理辅导等。
技术实现思路
1、本发明的目的在于提供一种基于语音识别的虚拟交互方法及系统,以解决上述背景技术中提出的问题。
2、为实现上述目的,本发明提供如下技术方案:
3、一种基于语音识别的虚拟交互方法,包含:
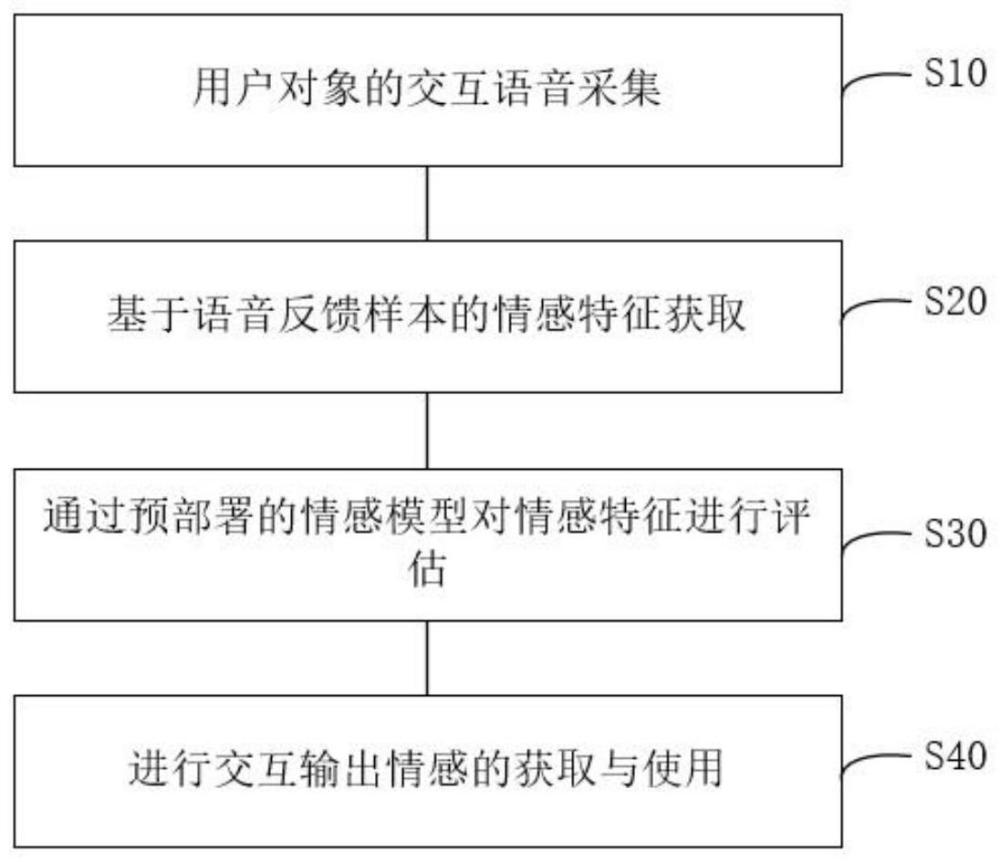
4、用户对象的交互语音采集;通过预设的情感交互程序获取用户的语音反馈样本,并对所述语音反馈样本进行预处理,所述情感交互程序用于输出情感评估内容并获取对象反馈,所述预处理包括采样率调整以及降噪增强;
5、基于语音反馈样本的情感特征获取;基于预设的特征提取方法对语音反馈样本进行处理,获取用户对象的情感特征,所述情感特征包括语义特征以及情感融合特征;
6、通过预部署的情感模型对情感特征进行评估;将所述情感特征在预部署的情感模型中进行情感评估,获取用户情感数据,所述用户情感数据包括情感交互需求以及情感状态偏向;
7、进行交互输出情感的获取与使用;通过基于大数据训练的场景情感匹配模型对所述用户情感特征数据进行匹配,获取与用户当前状态相匹配的最优交互输出情感,并根据所述交互输出情感对交互输出语音进行情感润色。
8、作为本发明的进一步方案:所述语义特征用于语音反馈样本的文字含义表达,所述情感融合特征具体包括韵律特征、谱特征以及音质特征,所述韵律特征具体包括时长相关特征、基频相关特征以及能量相关特征;所述谱特征用于通过频谱间的能量差异表征声音信号在频域的特性;所述音质特征包括发声者语态、喘息颤音及哽咽;所述情感模型的部署步骤包括:
9、获取情感训练样本,并对所述情感样本的数据进行预处理,所述情感训练样本包括情感特征以及相对应用户对象的情感状态评估结果,所述情感训练样本由专业心理人员评估获得;
10、建立pad情感空间模型,并通过情感训练样本对所述pad情感空间模型进行训练,以对不同强度的情感进行空间定位校正,以获取训练后的情感模型并部署。
11、作为本发明的再进一步方案:所述场景情感匹配模型用于表征用户对象在不同情感融合特征下,交互语音的不同情感类型对于用户对象的情绪抚慰反馈效果,即对应用户情感状态的最优交互输出情感,所述进行交互输出情感的获取与使用的步骤包括:
12、获取用户情感特征的语义特征,基于所述语义特征对用户对象的交互需求进行判断,并基于交互ai生成交互反馈内容,所述交互反馈内容用于表征对用户对象的文字解答内容;
13、获取用户情感特征的情感融合特征,基于场景情感匹配模型对情感融合特征进行匹配,获取相对应的最优交互输出情感;
14、基于所述最优交互输出情感对所述交互反馈内容进行转语音处理,生成并输出交互输出语音。
15、作为本发明的再进一步方案:还包括个性化收集训练步骤,具体包括:
16、获取用户的日常交互内容,并基于日常交互内容进行个性化情感特征获取,基于所述个性化情感特征对情感模型进行训练,以产生基于用户对象的个性化偏移校正;
17、获取用户对象对于不同类型输出语音特征的情感反馈,以统计获取用户对象的语音特征偏好,所述语音特征偏好用于生成最优交互输出情感。
18、作为本发明的再进一步方案:还包括辅助情感判定步骤,具体包括:
19、通过图像采集模块在交互语音采集中对用户对象进行表情动作的图像采集,并基于前后帧进行差值评估,获取用户对象的微表情变化,所述微表情变化用于判断用户情绪变化。
20、本发明实施例旨在提供一种基于语音识别的虚拟交互系统,包含:
21、交互样本采集模块,用于用户对象的交互语音采集;通过预设的情感交互程序获取用户的语音反馈样本,并对所述语音反馈样本进行预处理,所述情感交互程序用于输出情感评估内容并获取对象反馈,所述预处理包括采样率调整以及降噪增强;
22、情感特征提取模块,用于基于语音反馈样本的情感特征获取;基于预设的特征提取方法对语音反馈样本进行处理,获取用户对象的情感特征,所述情感特征包括语义特征以及情感融合特征;
23、情感偏向评估模块,用于通过预部署的情感模型对情感特征进行评估;将所述情感特征在预部署的情感模型中进行情感评估,获取用户情感数据,所述用户情感数据包括情感交互需求以及情感状态偏向;
24、输出情感反馈模块,用于进行交互输出情感的获取与使用;通过基于大数据训练的场景情感匹配模型对所述用户情感特征数据进行匹配,获取与用户当前状态相匹配的最优交互输出情感,并根据所述交互输出情感对交互输出语音进行情感润色。
25、作为本发明的进一步方案:所述语义特征用于语音反馈样本的文字含义表达,所述情感融合特征具体包括韵律特征、谱特征以及音质特征,所述韵律特征具体包括时长相关特征、基频相关特征以及能量相关特征;所述谱特征用于通过频谱间的能量差异表征声音信号在频域的特性;所述音质特征包括发声者语态、喘息颤音及哽咽;还包括情感模型部署模块,所述情感模型部署模块包括:
26、样本获取单元,用于获取情感训练样本,并对所述情感样本的数据进行预处理,所述情感训练样本包括情感特征以及相对应用户对象的情感状态评估结果,所述情感训练样本由专业心理人员评估获得;
27、模型建立单元,用于建立pad情感空间模型,并通过情感训练样本对所述pad情感空间模型进行训练,以对不同强度的情感进行空间定位校正,以获取训练后的情感模型并部署。
28、作为本发明的再进一步方案:所述场景情感匹配模型用于表征用户对象在不同情感融合特征下,交互语音的不同情感类型对于用户对象的情绪抚慰反馈效果,即对应用户情感状态的最优交互输出情感,所述输出情感反馈模块具体包括:
29、文字交互单元,用于获取用户情感特征的语义特征,基于所述语义特征对用户对象的交互需求进行判断,并基于交互ai生成交互反馈内容,所述交互反馈内容用于表征对用户对象的文字解答内容;
30、情感交互单元,用于获取用户情感特征的情感融合特征,基于场景情感匹配模型对情感融合特征进行匹配,获取相对应的最优交互输出情感;
31、输出融合单元,用于基于所述最优交互输出情感对所述交互反馈内容进行转语音处理,生成并输出交互输出语音。
32、作为本发明的再进一步方案:还包括个性化模块,具体包括:
33、情感个性化单元,用于获取用户的日常交互内容,并基于日常交互内容进行个性化情感特征获取,基于所述个性化情感特征对情感模型进行训练,以产生基于用户对象的个性化偏移校正;
34、语音个性化单元,用于获取用户对象对于不同类型输出语音特征的情感反馈,以统计获取用户对象的语音特征偏好,所述语音特征偏好用于生成最优交互输出情感。
35、作为本发明的再进一步方案:还包括辅助判定模块;
36、所述辅助判定模块,用于通过图像采集模块在交互语音采集中对用户对象进行表情动作的图像采集,并基于前后帧进行差值评估,获取用户对象的微表情变化,所述微表情变化用于判断用户情绪变化。
37、与现有技术相比,本发明的有益效果是:在现有技术的语音识别与交互的基础上,通过对用户语音的声音特征变化对语音所包含的情绪内容进行判断,从而了解用户在语音交互过程中的情绪需求,从而可以根据用户的需求选择合适的语音情感模式,在对用户输出反馈语音时,提供更为舒适的共同氛围,相较于现有技术的根据语义的固定式语音情感氛围,更具有人性化,适用于心理情感交互等场景。
- 还没有人留言评论。精彩留言会获得点赞!