一种基于深度学习的客服机器人与对话处理系统及方法与流程
本发明属于机器人,尤其涉及一种基于深度学习的客服机器人与对话处理系统及方法。
背景技术:
1、机器人是网络物理系统,它结合了硬件和软件组件、网络和通信过程、机械执行器、控制器、操作系统和传感器来和物理世界进行交互。传统机器人应用技术中大多是以单独的视觉机器人或者听觉机器人的形式存在的,而将视觉和听觉进行有效融合的情况还比较少,机器人不易对视觉听觉信息进行有效地交互感知,而无论是单独使用视觉信息还是听觉信息,都会存在一定的局限。而在客服机器人对老年人很难理解老人通过身体表达的意图,交互模式单一,多采用一问一答方式,且对环境因素非常敏感,不能及时有效地感知自身所处的环境状况,也很难及时地选择最有利于自己的任务执行,出现协助过程的卡顿或者死机现象,这样会导致复杂场景下的人机协作能力较差,的问题。
技术实现思路
1、有鉴于此,本发明提供了一种视听觉交互的人机交互系统、听觉感知的声源定位和基于视觉感知的人脸识别的基于深度学习的客服机器人与对话处理系统及方法,可以实现对目标快速搜索和提升环境信息感知能力,快速对目标声源进行定位,也大大减少系统计算量,具体采用以下技术方案来实现。
2、第一方面,本发明提供了一种基于深度学习的客服机器人与对话处理系统,包括:
3、听觉信息感知模块,用于对音频信号采集与处理,根据人的听觉系统构建多路麦克风阵列,采用其中一路麦克风作为基准麦克风,通过模拟人的听觉感知原理判断出相关信号,并将其他无关信息滤除,对接收到的信号进行有效语音检测处理,提取出所需的语音信号;
4、导航模块,用于通过声源定位得到声源所在位置的估计值和声源方位角信息,并进行朝向的改变和运动控制、舵机的控制处理使机器人运动至声源位置,将光学摄像头朝向声源位置;
5、视觉信息感知模块,用于模拟人的视觉原理构建机器人视觉感知系统,光学摄像头通过采集视频图像来感知外界图像信息,光学摄像头朝向的改变可通过云台电机控制或机器人导航模块来调整机器人的位姿,机器人控制摄像头使其朝向声源,捕获到的视频图像序列传给控制中心进行可疑动态目标的检测,在转到目标声源位置附加后,视频开始逐帧扫描以检测人脸图像,对检测到的人脸图像与数据库内的人脸数据进行匹配以识别出说话者的身份;
6、无线通讯模块,用于当机器人对目标进行识别后需要将所得的数据发送出去,机器人将识别信息由无线通讯模块发送到远程控制端以完成对话处理。
7、作为上述技术方案的进一步优选,视觉信息感知模块的执行过程包括:
8、根据目标检测获取物体和人的坐标,并将坐标转换到机器人的机械臂的坐标系中,求取人与物体的距离,根据目标检测的包围框顶点坐标计算物体的中心位置,预设包围框对角二维像素坐标(xmin,ymin)、(xmax,ymax),则可求取中心点像素坐标(xj,yj),对应的表达式为数据中心像素点坐标采用表达式为
9、其中,cx和cy表示在x轴和y轴上的一般笛卡尔点,fx和fy中是沿x轴和y轴的焦距,dp表示像素的深度,(xi,yi)表示图像上的像素坐标,(xr,yr,zr)表示kinect坐标系中的实际坐标;
10、计算人体的中心坐标(xm,ym,zm)与视野中其他物体i的中心坐标(xi,yi,zi)之间的距离的表达式为
11、作为上述技术方案的进一步优选,采用多模态融合算法计算出人的意图,多模态融合算法包括多模态信息的输入与识别、基于信息熵的意图推测和多模态信息的加权融合以及融合后结果的输出,在多模态信息的输入与识别过程中,以kinect和麦克风作为输入设备,将获取的信息经过手势识别、目标检测、语音识别和场景感知加工后,再分别做基于手势的意图推测、基于距离的意图推测和基于语音的意图推测,采用推测的结果计算每个通道的权重,最后进行基于信息熵加权的多模态融合,融合结果将作为输入进一步推测人想进行的活动,活动结果继续作为任务选择策略的输入,直到整个协同事件完成;
12、其中,基于手势的置信度推测:将手势识别结果的向量去除,将手势的识别概率记为gi(i=1,2...n),再通过信息熵方程得到置信度h(gi)的表达式为
13、基于语音的置信度推测:获取当前语音识别结果与语音指令库中指令的匹配度,将指令的匹配概率记为vi(i=1,2...n),再通过表达式为计算得到置信度h(vi);
14、基于距离的置信度推测:采用场景感知中求得的人与机器人视野内物体的距离计算物体的权重di(i=1,2...n),再通过表达式为和表达式为
15、作为上述技术方案的进一步优选,计算出每个模态的置信度后,再采用表达式为计算每个通道的权重值,手势信息通道权重记为语音信息通道权重记为语音信息通道权重记为语音信息通道权重记为
16、使用表达式为求得最后的融合结果,最大值对应的意图是经过多模态融合算法得到的意图,基于信息熵的多模态融合算法通过增大可信度高的输入通道所占的权重值,弱化因环境因素无法正常工作的通道所占的权重的方式实现各多模态信息的融合。
17、作为上述技术方案的进一步优选,信息交互控制模块,用于根据机器人通过有效语音检测判断信号中是否含有说话声,在有声音感知情况下,进行目标声源的粗定位,根据声源定位调整机器人朝向,启动机器人导航模块,通过红外、超声传感器判断路况信息以控制机器人移向声源方位;
18、其中,移动中启动视觉搜索模块进行动态目标检测,当检测到动态目标后,对当前视频采集到的图像进行扫描,对需要搜索的区域进行遍历,采用对人体特征的检测,直到检测到人脸图像并识别,通过无线通讯模块发送数据,监控端会接收到各个传感器传来的实时信息,通过对信息的分析处理完成对机器人进行控制。
19、作为上述技术方案的进一步优选,语音活性检测通过对语音原始信号进行处理,并从中分离出有效语音片段的过程,在进行定位操作之前,需要对接收到的音频信号进行有效语音检测,其中,采用短时平均过零率进行有效语音检测;
20、过零是指相邻两个时刻信号的采样值异号,短时过零是指在单位时间间隔内过零的次数,采用表达式为其中,x(m)表示在m时刻所采集到的信号,sgn[x]表示符号函数,w(n)表示窗函数,n表示窗长。
21、作为上述技术方案的进一步优选,短时平均过零率对应的短时平均能量是指在单位时间间隔内信号的能量平均值,在满足预设信噪比的条件下将清音段和浊音段区分开来,短时能量的表达式为采用双门限结合短时平均能量和短时平均过零率,采用能量阈值tlow、thigh以及过零率阈值tzcr这三个阈值,这些阈值由环境噪声决定,采用双门限阈值进行有效语音检测的过程包括:
22、选取一路麦克风作为接收端,对接收到的信号采取分帧处理;
23、计算所接收信号的短时帧能量;
24、根据所设的短时能量的高门限值thigh进行粗判断;
25、由低门限阈值tlow进行第二次判断,根据第一次的判断所确定的两侧门限在其附近分别进行搜索以找到门限tlow与短时能量相交的两个点,所得两点即为通过短时平均能量所得的有效语音的端点;
26、通过计算得到信号的短时帧过零率,将所得的两个端点分别向两侧搜索,结合短时平均过零率继续判断,其值首次小于tzcr时的临界点是有效语音信号的端点。
27、作为上述技术方案的进一步优选,采用三帧差法采集连续的三帧图像,对三帧图像进行两两作差,对作差后的图像进行逻辑运算以减小背景移动带来的影响;
28、预设第k-1、k和k+1帧连续的三幅图像分别为fk-1(x,y)、fk(x,y)和fk+1(x,y),相邻两帧图像差分后的二值图像为dk-1,k(x,y)和dk,k+1(x,y),对应的表达式分别为和其中,t1、t2表示所选取的二值化阈值,对差分图像dk-1,k(x,y)、dk,k+1(x,y)再次进行逻辑运算以得到最终的差分图像sk(x,y),
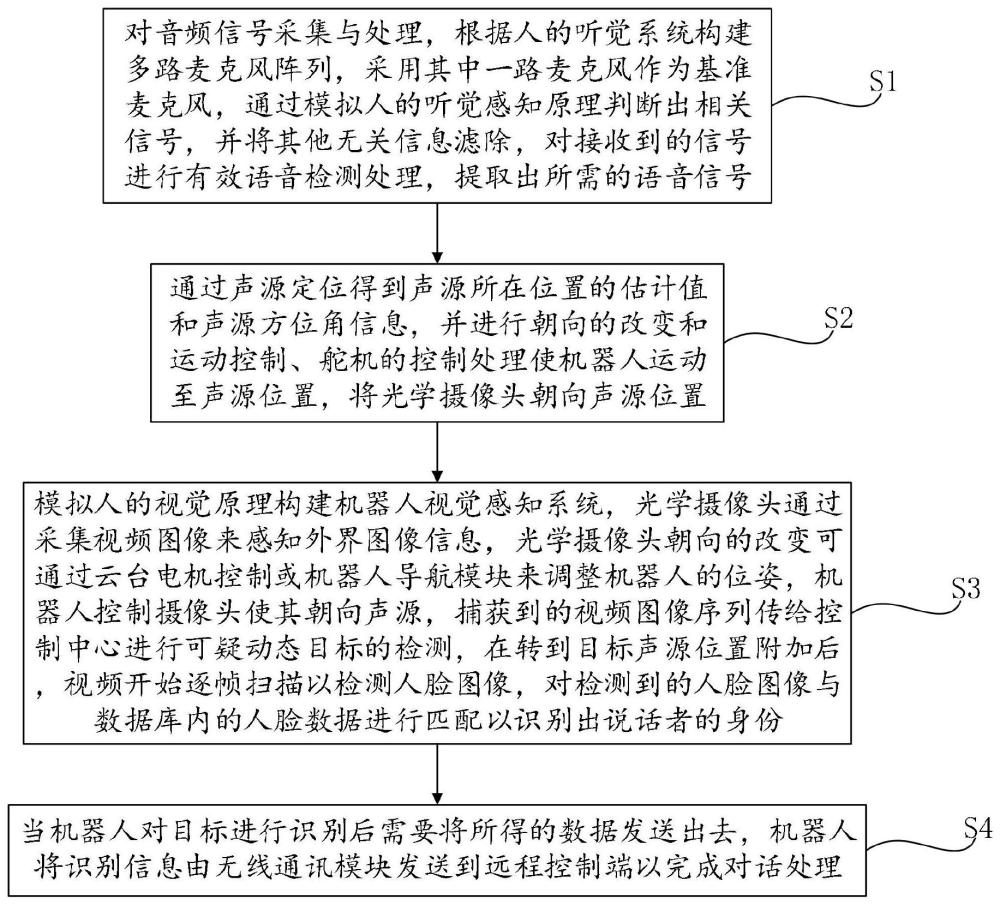
29、作为上述技术方案的进一步优选,语音信号的特征提取过程包括:
30、将原始的语音信号先进行傅里叶变换转换到频域,再分析语音信号的相关特征,通过使用数字滤波器对语音信号的帧中所包含的采样点进行加重预处理,再对处理过的信号加窗函数并进行自相关分析,将得到的相关结果加以p阶线性预测计算以得到长度为p的序列x,最终得到语音信号帧的lpcc倒谱系数,lpcc提取语音信号特征的过程为:
31、计算短时语音信号的自相关系数rn(j),j=0,1,2…16,对应的表达式为其中xw(n)表示加窗处理后的短时语音信号。
32、第二方面,本发明还提供了一种基于深度学习的客服机器人与对话处理方法,包括以下步骤:
33、对音频信号采集与处理,根据人的听觉系统构建多路麦克风阵列,采用其中一路麦克风作为基准麦克风,通过模拟人的听觉感知原理判断出相关信号,并将其他无关信息滤除,对接收到的信号进行有效语音检测处理,提取出所需的语音信号;
34、通过声源定位得到声源所在位置的估计值和声源方位角信息,并进行朝向的改变和运动控制、舵机的控制处理使机器人运动至声源位置,将光学摄像头朝向声源位置;
35、模拟人的视觉原理构建机器人视觉感知系统,光学摄像头通过采集视频图像来感知外界图像信息,光学摄像头朝向的改变可通过云台电机控制或机器人导航模块来调整机器人的位姿,机器人控制摄像头使其朝向声源,捕获到的视频图像序列传给控制中心进行可疑动态目标的检测,在转到目标声源位置附加后,视频开始逐帧扫描以检测人脸图像,对检测到的人脸图像与数据库内的人脸数据进行匹配以识别出说话者的身份;
36、当机器人对目标进行识别后需要将所得的数据发送出去,机器人将识别信息由无线通讯模块发送到远程控制端以完成对话处理。
37、本发明提供了一种基于深度学习的客服机器人与对话处理系统及方法,通过对音频信号采集与处理,根据人的听觉系统构建多路麦克风阵列,采用其中一路麦克风作为基准麦克风,通过模拟人的听觉感知原理判断出相关信号,并将其他无关信息滤除,对接收到的信号进行有效语音检测处理,提取出所需的语音信号,通过声源定位得到声源所在位置的估计值和声源方位角信息,并进行朝向的改变和运动控制、舵机的控制处理使机器人运动至声源位置,将光学摄像头朝向声源位置,模拟人的视觉原理构建机器人视觉感知系统,光学摄像头通过采集视频图像来感知外界图像信息,光学摄像头朝向的改变可通过云台电机控制或机器人导航模块来调整机器人的位姿,机器人控制摄像头使其朝向声源,捕获到的视频图像序列传给控制中心进行可疑动态目标的检测,可以使机器人智能的根据所处环境不同选择不同的定位算法,自适应的调节自身参数,从而有效提升了机器人对话处理效率。
- 还没有人留言评论。精彩留言会获得点赞!