一种利用元数据生成音频预测未知异常的异音检测方法
本发明涉及的是一种利用元数据生成音频预测未知异常的异音,具体地说是一种利用元数据生成音频预测未知异常的异音检测方法。
背景技术:
1、异常声音检测(anomalous sound detection,asd)任务的目的是自动识别目标(如机器或设备)是否发出异常的声音,由此判断目标是否出现异常的行为或状态。然而,由于异常声音极少发生且存在多样性,难以收集覆盖所有异常情况的声音样本用于模型训练。为了缓解这个问题,现有研究提出了无监督场景下的异常声音检测,即仅使用正常声音进行异常声音检测模型的训练。
2、然而,尽管无监督场景定义了仅能使用正常声音进行异常声音检测模型的训练,但机器的异常声音样本仍然可以在异常声音检测模型的训练过程中被用于确定模型的超参数(如训练迭代次数、多分类损失权重、特征处理加权权重等),这与现实场景不符,导致训练过程无法在实际应用中实现。这是由于深度学习模型的训练需要训练集、测试集和评估集,在异常声音检测模型训练中,测试集和评估集均包含了异常音频样本,使得很多模型通过测试集上的表现选择使模型性能更好的超参数。
3、为了满足现实场景需求,最新的研究提出了first-shot场景下的异常声音检测。first-shot场景是指仅允许使用参考机器的正常和异常声音样本、目标机器的正常声音样本以及声音样本对应的元数据信息来训练异音检测模型,而目标机器的异常声音样本在训练阶段对模型不可见,且要求异音检测模型可以准确识别目标机器的异常声音。在first-shot场景下,参考机器和目标机器不同,且目标机器的异常样本完全不可见,避免了目标机器的异常样本泄露到异常声音检测模型训练中,更符合现实场景下的无监督异常声音检测。然而在first-shot场景下,现有异音检测模型难以获取准确的超参数,异音检测精度低且稳定性较差。
技术实现思路
1、为了解决first-shot场景下由于目标机器异常音频样本不可见导致的异音检测系统性能受限的问题,本发明提供了一种利用元数据生成音频预测未知异常的异音检测方法,实现了从参考机器的异常音频和目标机器的元数据信息预测目标机器异常音频特征,进而生成对应异常音频,帮助现有异音检测模型在训练过程中预测超参数,以此提高异音检测系统在first-shot场景下的性能。此外,本发明仅使用参考机器的异常样本微调生成模型,提供了一种针对不同声学目标类型时的统一的异常特征预测方法,缓解了现实场景下难以获取足以训练异常检测模型的异常样本的问题。
2、为了实现上述目的,本发明采用如下技术方案:
3、一种利用元数据生成音频预测未知异常的异音检测方法,包括以下步骤:
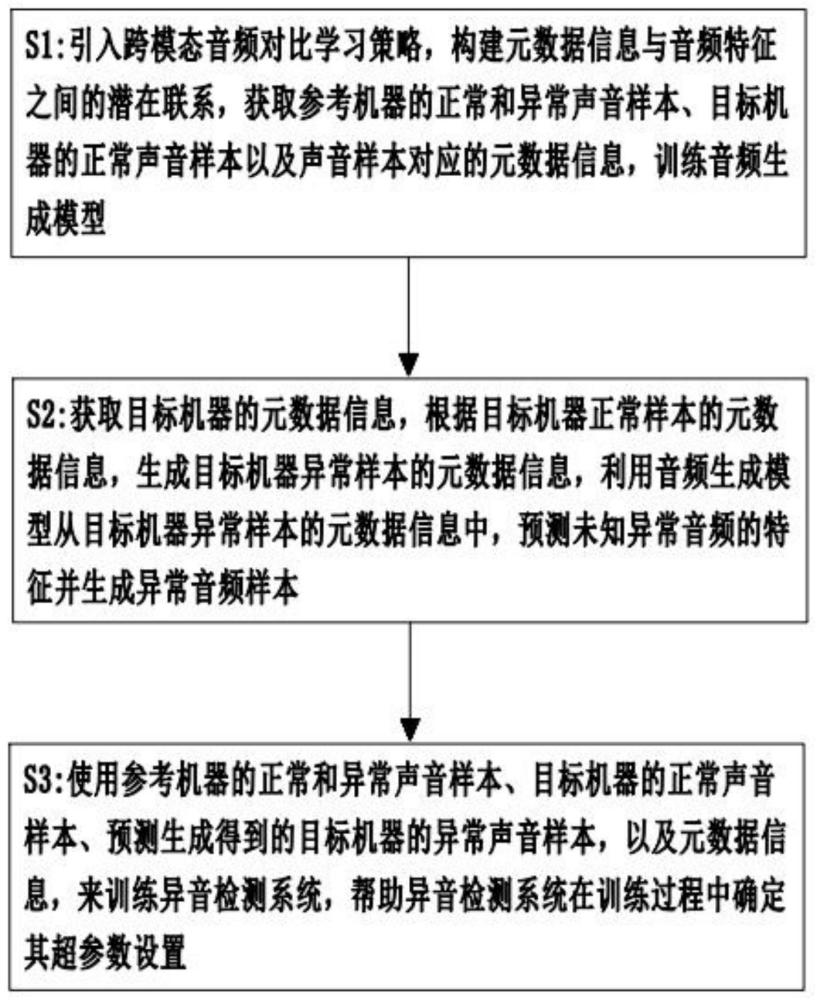
4、s1:引入跨模态音频对比学习策略,构建元数据信息与音频特征之间的潜在联系,获取参考机器的正常和异常声音样本、目标机器的正常声音样本以及声音样本对应的元数据信息,训练音频生成模型;
5、s2:获取目标机器的元数据信息,根据目标机器正常样本的元数据信息,生成目标机器异常样本的元数据信息,利用音频生成模型从目标机器异常样本的元数据信息中,预测未知异常音频的特征并生成异常音频样本;
6、s3:使用参考机器的正常和异常声音样本、目标机器的正常声音样本、预测生成得到的目标机器的异常声音样本,以及元数据信息,来训练异音检测系统,帮助异音检测系统在训练过程中确定其超参数设置;
7、作为优选的,参考机器和目标机器的每个音频样本对应的元数据信息由离散属性值组成;元数据信息是声音样本携带的,描述了声音样本录制状况以及声源运行状况的文本信息。
8、作为优选的,参考机器和目标机器的每个音频样本对应的元数据信息通过字幕转换算法转换成其对应的自然语言描述,用于跨模态音频对比学习策略提取其元数据信息的特征;
9、字幕转换算法可以表示如下:
10、c=fc(l1,l2,…,ln)
11、其中,l1,l2,...,ln分别表示组成元数据信息的各个离散属性值,fc(·)表示字幕转换算法,为由字幕转换算法从元数据信息得到的对音频样本的自然语言描述。
12、作为优选的,所述字幕转换算法为:其将音频样本对应的元数据信息以固定标准模板整合为一条对该音频样本的自然语言描;其中,固定标准模板是针对不同机器类型和不同元数据信息设计;
13、由于跨模态音频对比学习策略的预训练数据由自然语言描述组成,所述的first-shot场景下的asd问题中只有离散属性值,使用离散属性值与音频特征对齐会影响其潜在联系的构建;所以本发明中设计了以克服由跨模态音频对比学习策略的预训练过程带来的分布差异,提高元数据信息与音频特征之间潜在联系的构建效果为目的的固定标准模板;
14、作为优选的,所述的元数据生成音频预测未知异常的异音检测方法为:
15、其采用对比语言-音频预训练(clap)作为跨模态音频对比学习策略;
16、clap由可学习的音频特征提取网络、可学习的文本特征提取网络和对齐损失函数组成。
17、作为优选的,所述的对比语言-音频预训练策略为:
18、其音频特征提取网络用于提取参考机器的正常和异常声音样本以及目标机器的正常声音样本的音频特征,其文本特征提取网络用于提取音频样本对应的自然语言描述的文本特征,分别可以表示如下:
19、ea=faudio(a)
20、ec=ftext(c)
21、其中,a和c分别表示声音样本和声音样本对应的自然语言描述,faudio(·)和ftext(·)分别表示音频编码器和文本编码器,和分别表示声音样本a和a的自然语言描述c对应的特征;
22、音频编码器和文本编码器分别基于htsat模型和roberta模型实现。
23、作为优选的,所述的对比语言-音频预训练策略为:
24、其对齐损失函数可以表示如下:
25、
26、
27、
28、其中,τ表示可学习的温度系数,d表示训练时设定的批处理大小,n表示当前正在训练的机器类型下的样本数量;
29、l1表示用于约束音频编码器faudio(·)的对齐损失,
30、l2表示用于约束文本编码器ftext(·)的对齐损失;
31、训练过程中,对齐损失函数中的l1和l2分别用于约束音频编码器faudio(·)和文本编码器ftext(·),使两个编码器输出的特征趋同;
32、由于自然语言描述携带的元数据信息与声音样本的特征紧密相关,推理时就可以仅使用自然语言描述的特征代表其对应的所有声音样本的总体特征;
33、由此构建了元数据信息与机器音频特征之间的潜在联系。
34、作为优选的,通过参考机器的正常声音样本集arn、参考机器的异常声音样本集ara、目标机器的正常声音样本集atn及其对应的元数据信息集crn、cra、ctn来微调机器声音预测器该过程可以表示如下:
35、
36、其中,a和c分别代表机器的声音样本集和对应的元数据信息集,如下所示:
37、
38、通过声音样本集和元数据信息集的微调,机器声音预测器可以受到元数据信息的约束,从输入的自然语言描述特征ec生成自然语言描述c对应的预测声音样本
39、作为优选的,其机器声音预测器是一个基于去噪扩散概率模型的音频波形生成器,但也可替换为其他基于文本的生成神经网络;
40、从输入的自然语言描述特征ec生成自然语言描述c对应的预测声音样本的过程可表示如下:
41、
42、其中,是以目标机器的正常声音样本元数据信息集作为输入获得的正常类型预测声音样本构成的集合,包含了预估的目标机器类型正常声音样本,是以目标机器的异常声音样本元数据信息集作为输入获得的异常类型预测声音样本构成的集合,包含了预估的目标机器类型异常声音样本;
43、由于目标机器的异常声音样本不可见,其元数据信息集是通过目标机器的正常声音样本元数据信息集生成的,该过程仅需将目标机器的正常声音样本元数据信息集中的“正常”修改为“异常”,即可得到目标机器的异常声音样本元数据信息。
44、得益于对比语言-音频预训练策略和机器声音预测器的微调过程,机器声音预测器会将参考机器的正常声音样本和参考机器的异常声音样本中的差异化特征迁移到预测目标机器的声音样本过程中,帮助预估目标机器的未知异常音频的特征并生成异常音频样本用于后续异常声音检测模型训练。
45、作为优选的,基于目标机器的正常预测声音样本目标机器的正常声音样本元数据信息集ctn、目标机器的异常预测声音样本以及目标机器的异常声音样本元数据信息集cta,将视为标机器的异常样本用于预测异常声音检测模型的超参数,在训练过程中选择性能更高的异常声音检测模型,用于解决first-shot场景下由于目标机器异常音频样本不可见导致的异音检测系统性能受限的作用。
46、音频特征提取、元数据信息特征提取、音频特征和元数据信息特征对齐、基于元数据信息的音频生成:
47、首先,将参考机器类型的所有音频样本和目标机器类型的正常音频样本通过频率数据域的log-mel谱空间滤波器组得到频域的log-mel谱空间特征,再将log-mel谱空间特征经过可学习的音频特征提取网络得到音频特征。
48、其次,将参考机器类型的所有样本和目标机器类型的正常样本对应的元数据信息通过字幕转换算法转换为对音频样本的自然语言描述,再将自然语言描述经过可学习的文本特征提取网络得到元数据信息特征。
49、随后,采用对比语言-音频预训练(contrastive language-audio pretraining,clap)作为跨模态音频对比学习策略,将参考机器类型的所有音频样本和目标机器类型的正常音频样本与其对应的元数据信息的特征建立联系。由于元数据信息是声音样本携带的,描述了声音样本的录制状况以及声源运行状况的文本信息,所以clap构建的音频和元数据信息之间的联系可以实现从元数据信息特征检索并获取该元数据信息对应的所有音频样本的整体特征。
50、最后,根据clap构建的音频和元数据信息之间的联系,人为拟定目标机器测试样本元数据信息,并经过文本特征提取网络得到目标机器测试样本的元数据信息特征,最终通过微调后的机器声音预测器从目标机器测试样本的元数据信息特征生成预测声音样本。
51、对现有的异常声音检测模型,因为原有测试集由参考机器的声音样本组成,预测的模型超参数无法用于目标机器。所以其训练过程可以将预测声音样本作为测试集用于预测模型超参数,提高了异音检测系统在first-shot场景下的性能,解决了first-shot场景下由于目标机器异常音频样本不可见导致的异音检测系统性能受限的问题。
52、有益效果:
53、针对first-shot场景下由于目标机器异常音频样本不可见导致现有异音检测模型难以获取准确的超参数,进而造成异音检测系统性能受限的问题,本发明设计了参考机器和目标机器的音频以及对应的元数据信息之间的跨模态音频对比学习策略,通过元数据信息对声音样本的描述挖掘和构建了元数据信息与机器音频特征之间的潜在联系,准确提取了相同元数据信息的所有音频样本的元数据相关音频特征。
54、同时,本发明通过机器声音预测器生成目标机器异常音频样本,解决了目标机器异常音频样本对现有异音检测模型不可见导致异音检测模型无法选择超参数,异音检测系统性能受限的问题。
55、另外,本发明仅使用参考机器的异常样本微调生成模型,能够针对不同声学目标类型形成统一的异常特征预测方法,不仅可以预测目标机器的异常音频样本,还实现了仅需使用参考机器异常样本的一次训练,就可通过目标机器的正常样本预测其异常样本的策略,构建了一个统一的泛化的生成模型,缓解了异常样本稀缺问题,有效降低了异音检测方法的工业化部署难度。
- 还没有人留言评论。精彩留言会获得点赞!