一种语音交互方法、装置、电子设备及存储介质与流程
本技术涉及车辆,具体涉及一种语音交互方法、装置、电子设备及存储介质。
背景技术:
1、随着语音识别技术和语义解析技术的发展,语音助手逐渐成为新能源汽车中的高频率使用功能。提升语音助手的用户体验,也成为了各大车企的工作重点。
2、相关技术中的语音助手可以对同一条指令做出不同的回复,但是将用户的语音指令发送至服务器进行分析,然后将分析结果返回车端,再将车辆的相关状态发送至服务器,以使服务器根据车辆状态等选择回复内容,不仅增加了车端与服务端的交互次数、数据流量消耗和响应的时间,还提高了出错的概率,且当车辆处于网络信号不佳的地方时,甚至不能响应用户的语音指令。显然,目前亟需一种新的语音交互方法,以解决上述问题中至少之一。
3、需要说明的是,上述内容仅提供了与本技术相关的背景技术信息,不必然构成在先技术。
技术实现思路
1、鉴于以上所述现有技术的缺点,本技术提供一种语音交互方法、装置、电子设备及存储介质,以实现减少车端与服务端的交互次数、减少数据流量消耗、降低响应时间、提高语音交互的准确率和提升用户体验感中至少之一。
2、本技术的其他特性和优点将通过下面的详细描述变得显然,或部分地通过本技术的实践而习得。
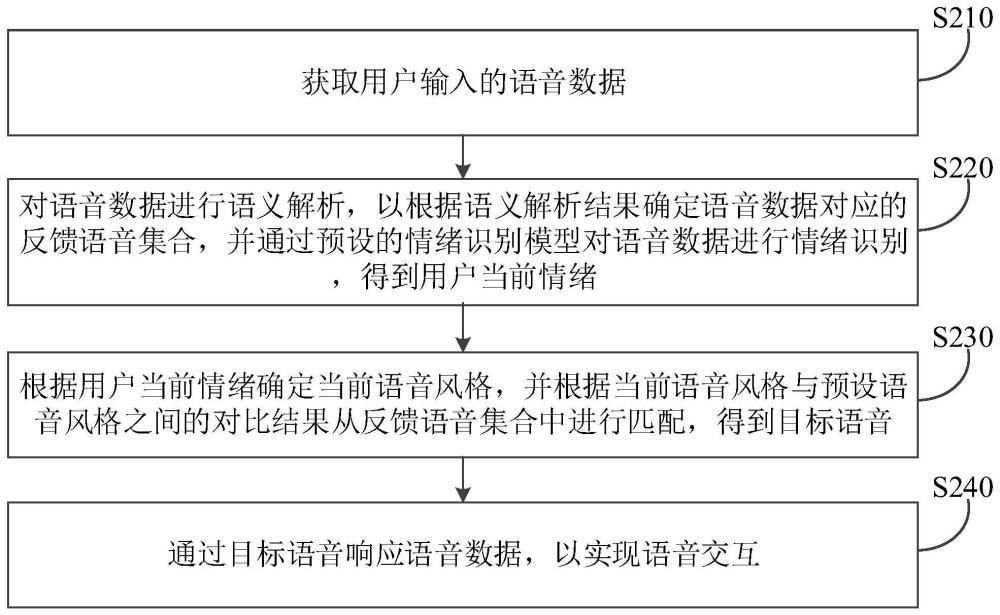
3、根据本技术实施例的一个方面,提供了一种语音交互方法,包括:获取用户输入的语音数据;对所述语音数据进行语义解析,以根据语义解析结果确定所述语音数据对应的反馈语音集合,所述反馈语音集合包括多个预设语音风格分别对应的反馈语音,并通过预设的情绪识别模型对所述语音数据进行情绪识别,得到用户当前情绪,其中,所述情绪识别模型根据带有用户情绪标签的语音样本进行训练得到;根据所述用户当前情绪确定当前语音风格,并根据所述当前语音风格与预设语音风格之间的对比结果从所述反馈语音集合中进行匹配,得到目标语音;通过所述目标语音响应所述语音数据,以实现语音交互。
4、在本技术的一个实施例中,基于前述方案,对所述语音数据进行语义解析,包括:将所述语音数据发送至服务端,使得所述服务端对所述语音数据进行语义解析,得到语义解析结果;接收所述服务端发送的语义解析结果。
5、在本技术的一个实施例中,基于前述方案,根据语义解析结果确定所述语音数据对应的反馈语音集合,包括:定义与所述预设语音风格对应的集合;获取反馈语音资源,根据所述语义解析结果中的资源标识在所述反馈语音资源中确定资源数组;遍历所述资源数组,并根据预设分割标记对所述资源数组中的文本进行分割操作,得到语音风格;通过所述语音风格选择定义后的集合对所述资源数组进行装载,直到所述资源数组装载完成,得到所述反馈语音集合。
6、在本技术的一个实施例中,基于前述方案,根据预设分割标记对所述资源数组中的文本进行分割操作,得到语音风格之后,所述方法还包括:若所述语音风格为方言,则获取当前设定方言的方言标识;根据所述方言标识过滤所述资源数组,得到所述方言标识对应的反馈语音集合。
7、在本技术的一个实施例中,基于前述方案,获取反馈语音资源之前,所述方法还包括:将所述反馈语音资源设置在本地终端,以在本地终端获取所述反馈语音资源。
8、在本技术的一个实施例中,基于前述方案,所述情绪识别模型根据带有用户情绪标签的语音样本进行训练得到,包括:获取用户情绪标签和样本语音数据;根据所述用户情绪标签对所述样本语音数据进行标注,生成带有用户情绪标签的语音样本;基于所述带有用户情绪标签的语音样本对预设情绪识别模型进行训练,得到所述情绪识别模型。
9、在本技术的一个实施例中,基于前述方案,通过预设的情绪识别模型对所述语音数据进行情绪识别,得到用户当前情绪,包括:初始化环境;基于初始化后的环境植入情绪监听器;响应于所述情绪监听器识别到的语音数据,将所述语音数据输入预设的情绪识别模型,得到模型输出结果;根据关键字从所述模型输出结果中提取所述用户当前情绪。
10、在本技术的一个实施例中,基于前述方案,根据所述用户当前情绪确定当前语音风格,包括:根据所述用户当前情绪和预设风格概率确定各预设语音风格的所处区间,其中,各预设语音风格的所处区间的大小与所述预设风格概率之间呈正相关关系;获取随机数,判定所述随机数的所处区间,根据判定结果确定所述当前语音风格。
11、在本技术的一个实施例中,基于前述方案,根据所述当前语音风格与预设语音风格之间的对比结果从所述反馈语音集合中进行匹配,得到目标语音,包括:将所述当前语音风格与所述预设语音风格进行对比,得到对比结果;根据所述对比结果从所述反馈语音集合中匹配候选语音;将所述候选语音进行随机排序,并将排序第一的候选语音确定为所述目标语音。
12、根据本技术实施例的一个方面,提供了一种语音交互装置,包括:获取模块,用于获取用户输入的语音数据;确定模块,用于对所述语音数据进行语义解析,以根据语义解析结果确定所述语音数据对应的反馈语音集合,所述反馈语音集合包括多个预设语音风格分别对应的反馈语音,并通过预设的情绪识别模型对所述语音数据进行情绪识别,得到用户当前情绪,其中,所述情绪识别模型根据带有用户情绪标签的语音样本进行训练得到;匹配模块,用于根据所述用户当前情绪确定当前语音风格,并根据所述当前语音风格与预设语音风格之间的对比结果从所述反馈语音集合中进行匹配,得到目标语音;响应模块,用于通过所述目标语音响应所述语音数据,以实现语音交互。
13、根据本技术实施例的一个方面,提供了一种电子设备,所述电子设备包括:一个或多个处理器;存储装置,用于存储一个或多个程序,当所述一个或多个程序被所述一个或多个处理器执行时,使得所述电子设备实现如上述各实施例中任一项所述的语音交互方法。
14、本技术还提供一种计算机可读存储介质,其上存储有计算机程序,当所述计算机程序被计算机的处理器执行时,使计算机执行如上述各实施例中任一项所述的语音交互方法。
15、本技术的有益效果:本技术中提供一种语音交互方法、装置、电子设备及存储介质。本技术通过获取用户输入的语音数据,对语音数据进行语义解析,以根据语义解析结果确定语音数据对应的反馈语音集合,并通过预设的情绪识别模型对语音数据进行情绪识别,得到用户当前情绪,根据用户当前情绪确定当前语音风格,并根据当前语音风格与预设语音风格之间的对比结果从反馈语音集合中进行匹配,得到目标语音,通过目标语音响应语音数据,以实现语音交互。通过多种预设语音风提升语音交互时的用户体验,根据用户当前情绪,采用不同类型回复,提供更符合用户当前情绪的反馈语音,帮助用户改善情绪,提升用户体验感,通过语义解析结果和用户当前情绪选择反馈语音,减少出错的概率,提升语音交互的准确率及效率。
16、另外,本技术还能够通过将反馈语音资源设置在本地终端,减少终端与服务端的交互次数,提升程序稳定性,减少数据流量的消耗,缩短语音回复响应时间。利用安卓系统现有的多语言机制,无需单独开发一套逻辑来处理多语言切换问题,降低了多语言反馈语音的维护难度。还可以配置多语言资源,避免了多语言资源配置不全等问题,在系统语言环境改变时,系统会自动寻找对应语言配置下的文字资源。
17、应当理解的是,以上的一般描述和后文的细节描述仅是示例性和解释性的,并不能限制本技术。
- 还没有人留言评论。精彩留言会获得点赞!