基于隐变量空间添加水印的语音合成方法、装置及设备
本公开涉及语音合成和人工智能,尤其涉及一种基于隐变量空间添加水印的语音合成方法、装置及设备。
背景技术:
1、随着人工智能技术的发展,语音合成技术也随之不断演进。例如文字转语音(tts)和语音转换(vc)技术的进步使得合成语音不仅自然,还能个性化地应用于各种场景,如虚拟助手和辅助技术等。在应用场景中,可以将一段文字转变为某个音色对应的语音且具有较为顺畅的听感。然而,随着技术的演进,也出现了很多技术滥用或非法利用导致的潜在风险,例如利用语音合成技术来伪造个体的语音导致人身、财产损失或舆论风险等,因此有必要提供一种能够防止语音合成被滥用或非法利用的安全策略。
2、在实现本公开构思的过程中,发明人发现相关技术中至少存在如下技术问题:为了防止语音合成被滥用或非法利用,相关技术在合成语音技术提出了添加水印的方式,利用水印进行语音数据的合法监管,避免非法使用;然而,相关技术中,大多是先通过语音合成方式生成语音信号,然后通过后处理的方式在语音信号中添加水印,这种方法需要确保待添加的水印对语音的质量(流利度、发音等)的负面影响尽可能低,这对于后期添加的算法有较高要求,同时由于这种方式是通过后处理的方式添加,容易被攻击且破解后拆除水印。
技术实现思路
1、为了解决上述技术问题或者至少部分地解决上述技术问题,本公开的实施例提供了一种基于隐变量空间添加水印的语音合成方法、装置及设备。
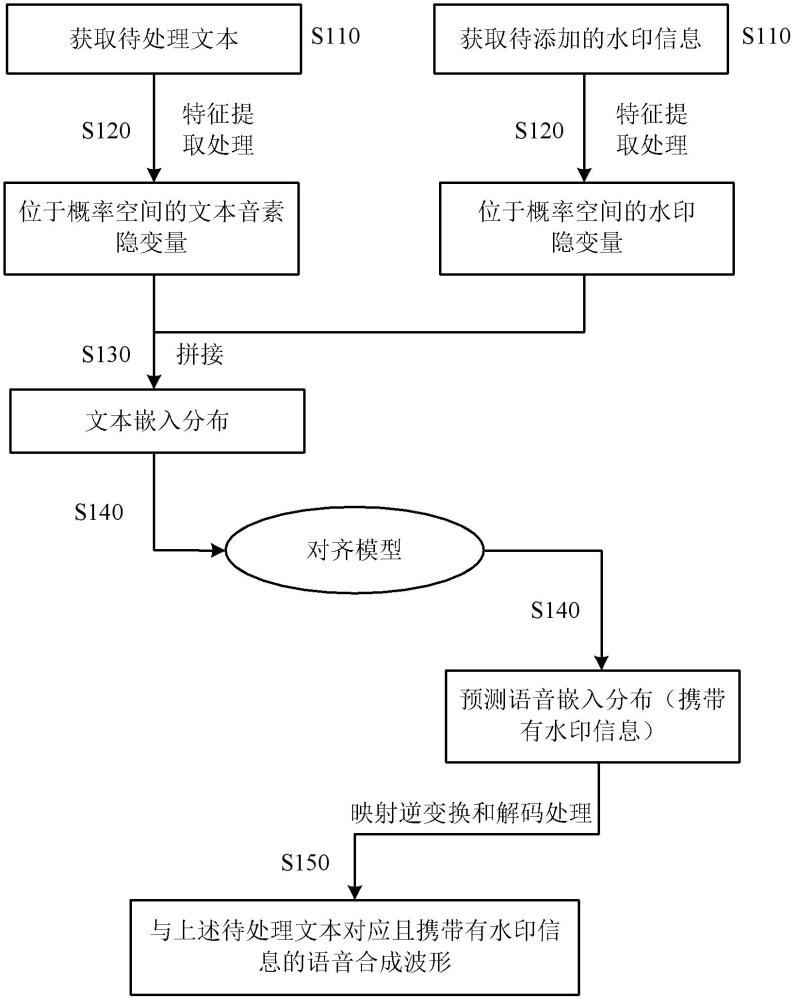
2、第一方面,本公开的实施例提供一种基于隐变量空间添加水印的语音合成方法。上述语音合成方法包括:获取待处理文本和待添加的水印信息;对上述待处理文本的文本音素序列、上述水印信息进行特征提取处理,得到位于概率空间的文本音素隐变量和水印隐变量;拼接上述文本音素隐变量和上述水印隐变量,得到文本嵌入分布;将上述文本嵌入分布输入至预先训练好的对齐模型中,输出预测音素时长与语音对齐、并进行语音转换后的预测语音嵌入分布;对上述预测语音嵌入分布进行映射逆变换和解码处理,得到与上述待处理文本对应且携带有水印信息的语音合成波形。
3、在一些实施例中,在训练阶段,上述对齐模型的输入为训练文本音素序列对应的训练文本嵌入分布和预测音素时长,输出为预测语音嵌入分布;上述预测音素时长由时长预测模型根据输入的训练文本音素特征向量和噪声进行预测得到,上述训练文本音素特征向量由上述训练文本音素序列进行编码处理得到;上述对齐模型的训练标签为训练语音频谱对应的训练语音嵌入分布;通过根据训练文本嵌入分布和对应的训练语音嵌入分布的对齐信息来迭代更新上述时长预测模型的模型参数。
4、在一些实施例中,对上述待处理文本的文本音素序列、上述水印信息进行特征提取处理,得到位于概率空间的文本音素隐变量和水印隐变量,包括:基于预训练好的文本编码器,对上述待处理文本的文本音素序列进行编码处理,得到文本音素特征向量;基于预训练好的第一映射模型,将上述文本音素特征向量映射转换至概率空间,得到位于概率空间的文本音素隐变量;基于预训练好的水印编码器,对上述水印信息进行特征提取处理,得到位于概率空间的水印隐变量。
5、在一些实施例中,对上述预测语音嵌入分布进行映射逆变换和解码处理,得到与上述待处理文本对应且携带有水印信息的语音合成波形,包括:基于映射逆变换模型,对位于概率空间的上述预测语音嵌入分布进行映射逆变换处理,得到目标语音嵌入分布;基于预训练好的频谱解码器,对上述目标语音嵌入分布进行解码处理,得到与上述待处理文本对应且携带有水印信息的语音合成波形。其中,上述映射逆变换模型是预训练好的第二映射模型的逆变换模型;在训练阶段,上述第二映射模型的输入为训练语音频谱经过频谱编码器编码处理后的训练语音特征向量,输出为位于概率空间的训练语音隐变量;上述对齐模型的训练标签是通过以下方式生成的:将上述训练语音隐变量与训练水印隐变量进行拼接,得到训练语音嵌入分布。
6、在一些实施例中,在训练阶段,同步对上述文本编码器、上述第一映射模型、上述水印编码器、上述频谱编码器、上述第二映射模型、上述对齐模型和上述频谱解码器进行训练。在训练阶段,上述频谱编码器的输出分为两个分支,其中一个分支作为上述第二映射模型的输入,另一个分支作为上述频谱解码器的输入。
7、在一些实施例中,上述第一映射模型包括线性映射模型,上述第二映射模型包括流模型,上述流模型是一种基于可逆变换的模型。
8、第二方面,本公开的实施例提供一种构建语音合成模型的方法。上述构建语音合成模型的方法包括:获取训练文本与训练语音频谱构成的数据对以及待添加的训练水印信息;将上述训练文本的文本音素序列输入至待训练的文本编码器和第一映射模型,输出位于概率空间的训练文本音素隐变量;将上述训练水印信息输入至待训练的水印编码器,输出位于概率空间的训练水印隐变量;将上述训练语音频谱输入至待训练的频谱编码器和第二映射模型,输出位于概率空间的训练语音隐变量;基于相同的拼接方式,将上述训练水印隐变量分别与上述训练文本音素隐变量、上述训练语音隐变量进行拼接,对应得到训练文本嵌入分布、训练语音嵌入分布;将上述训练文本嵌入分布输入至待训练的对齐模型,输出预测音素时长对应的训练预测语音嵌入分布;上述对齐模型的训练标签为训练语音嵌入分布;将上述频谱编码器输出的训练语音特征向量输入至频谱解码器,输出得到训练重构语音波形;在训练阶段,同步对上述文本编码器、上述第一映射模型、上述水印编码器、上述频谱编码器、上述第二映射模型、上述对齐模型和上述频谱解码器进行训练;将训练好的第二映射模型对应的逆变换模型确定为映射逆变换模型;基于上述映射逆变换模型、训练好的文本编码器、第一映射模型、水印编码器、对齐模型和频谱解码器,生成语音合成模型;其中,在上述语音合成模型中,上述映射逆变换模型的输入端与上述对齐模型的输出端连接,上述映射逆变换模型的输出端与上述频谱解码器的输入端连接。
9、在一些实施例中,上述预测音素时长由时长预测模型根据输入的训练文本音素特征向量和噪声进行预测得到,其中,上述文本编码器的输出端分别连接至上述时长预测模型的输入端和上述第一映射模型的输入端;上述文本编码器输出的文本音素特征向量和噪声输入至待训练的时长预测模型,输出得到与输入对应的预测音素时长。
10、在一些实施例中,在训练阶段,通过根据训练文本嵌入分布和对应的训练语音嵌入分布的对齐信息来迭代更新上述时长预测模型的模型参数;利用kl散度测量训练文本嵌入分布和训练语音嵌入分布之间的差异,在进行对齐模型的训练时采用变分推理方式,基于最大化对数似然的变分下界算法进行模型参数迭代;通过根据训练语音频谱对应的真实语音波形与训练重构语音波形的重构损失来迭代更新上述频谱解码器的模型参数。
11、在一些实施例中,上述语音合成模型包括:文本编码器、第一映射模型、水印编码器、对齐模型、时长预测模型、频谱解码器和映射逆变换模型,上述映射逆变换模型是预训练好的第二映射模型的逆变换模型。上述文本编码器的输出分别作为第一映射模型的输入、时长预测模型的输入;上述第一映射模型的输出与上述水印编码器的输出进行拼接处理后作为上述对齐模型的一个输入,上述时长预测模型的输出作为上述对齐模型的另一个输入;上述对齐模型的输出作为映射逆变换模型的输入;上述映射逆变换模型的输出作为上述频谱解码器的输入;上述文本音素序列用于输入至上述文本编码器,上述水印信息用于输入至上述水印编码器,上述频谱解码器的输出作为上述语音合成模型的输出。
12、第三方面,本公开的实施例提供一种语音合成方法。上述语音合成方法包括:获取待处理文本和待添加的水印信息;将上述待处理文本的文本音素序列和上述水印信息输入至预先构建好的语音合成模型中,输出得到与上述待处理文本对应且携带有上述水印信息的合成语音波形;上述语音合成模型采用第二方面实施例提供的方法构建得到。
13、第四方面,本公开的实施例提供一种基于隐变量空间添加水印的语音合成装置。上述语音合成装置包括:数据获取模块、特征提取模块、拼接模块、文本向语音对齐模块和重构模块。上述数据获取模块用于获取待处理文本和待添加的水印信息。上述特征提取模块用于对上述待处理文本的文本音素序列、上述水印信息进行特征提取处理,得到位于概率空间的文本音素隐变量和水印隐变量。上述拼接模块用于拼接上述文本音素隐变量和上述水印隐变量,得到文本嵌入分布。上述文本向语音对齐模块用于将上述文本嵌入分布输入至预先训练好的对齐模型中,输出预测音素时长与语音对齐、并进行语音转换后的预测语音嵌入分布。上述重构模块用于对上述预测语音嵌入分布进行映射逆变换和解码处理,得到与上述待处理文本对应且携带有水印信息的语音合成波形。
14、第五方面,本公开的实施例提供一种构建语音合成模型的装置。上述构建语音合成模型的装置包括:训练数据获取模块、训练特征提取模块、训练拼接模块、训练文本向语音对齐模块、训练重构模块、训练模块、逆变换模块和模型生成模块。上述训练数据获取模块用于获取训练文本与训练语音频谱构成的数据对以及待添加的训练水印信息。上述训练特征提取模块用于将上述训练文本的文本音素序列输入至待训练的文本编码器和第一映射模型,输出位于概率空间的训练文本音素隐变量;将上述训练水印信息输入至待训练的水印编码器,输出位于概率空间的训练水印隐变量;将上述训练语音频谱输入至待训练的频谱编码器和第二映射模型,输出位于概率空间的训练语音隐变量。上述训练拼接模块用于基于相同的拼接方式,将上述训练水印隐变量分别与上述训练文本音素隐变量、上述训练语音隐变量进行拼接,对应得到训练文本嵌入分布、训练语音嵌入分布。上述训练文本向语音对齐模块用于将上述训练文本嵌入分布输入至待训练的对齐模型,输出预测音素时长对应的训练预测语音嵌入分布;上述对齐模型的训练标签为训练语音嵌入分布。上述训练重构模块用于将上述频谱编码器输出的训练语音特征向量输入至频谱解码器,输出得到训练重构语音波形。上述训练模块用于在训练阶段,同步对上述文本编码器、上述第一映射模型、上述水印编码器、上述频谱编码器、上述第二映射模型、上述对齐模型和上述频谱解码器进行训练。上述逆变换模块用于将训练好的第二映射模型对应的逆变换模型确定为映射逆变换模型。上述模型生成模块用于基于上述映射逆变换模型、训练好的文本编码器、第一映射模型、水印编码器、对齐模型和频谱解码器,生成语音合成模型;其中,在上述语音合成模型中,上述映射逆变换模型的输入端与上述对齐模型的输出端连接,上述映射逆变换模型的输出端与上述频谱解码器的输入端连接。
15、第六方面,本公开的实施例提供一种语音合成装置。上述语音合成装置包括:数据获取模块和处理模块。上述数据获取模块用于获取待处理文本和待添加的水印信息。上述处理模块用于将上述待处理文本的文本音素序列和上述水印信息输入至预先构建好的语音合成模型中,输出得到与上述待处理文本对应且携带有上述水印信息的合成语音波形;上述语音合成模型采用第二方面实施例提供的方法构建得到或采用第五方面实施例提供的装置构建得到。
16、第七方面,本公开的实施例提供了一种电子设备。上述电子设备包括处理器、通信接口、存储器和通信总线,其中,处理器、通信接口和存储器通过通信总线完成相互间的通信;存储器,用于存放计算机程序;处理器,用于执行存储器上所存放的程序时,实现第一方面实施例提供的基于隐变量空间添加水印的语音合成方法、第二方面实施例提供的构建语音合成模型的方法或第三方面实施例提供的语音合成方法。
17、第八方面,本公开的实施例提供了一种计算机可读存储介质。上述计算机可读存储介质上存储有计算机程序,上述计算机程序被处理器执行时实现第一方面实施例提供的基于隐变量空间添加水印的语音合成方法、第二方面实施例提供的构建语音合成模型的方法或第三方面实施例提供的语音合成方法。
18、本公开实施例提供的上述技术方案至少具有如下优点的部分或全部:
19、通过对待处理文本的文本音素序列、待添加的水印信息进行特征提取处理,得到位于概率空间的文本音素隐变量和水印隐变量;拼接上述文本音素隐变量和上述水印隐变量,得到文本嵌入分布;将上述文本嵌入分布输入至预先训练好的对齐模型中,输出预测音素时长与语音对齐、并进行语音转换后的预测语音嵌入分布;对上述预测语音嵌入分布进行映射逆变换和解码处理,得到与上述待处理文本对应且携带有水印信息的语音合成波形;上述方案中,通过将水印信息和文本音素序列均转换到隐变量空间,并在隐变量空间内进行拼接,对齐模型能够实现从文本音素向语音的时长对齐并转换为对应的预测语音嵌入分布,在解码过程中预测语音嵌入分布携带有水印和语音相关信息,同步在映射逆变换和解码处理后得到语音合成波形,避免通过后处理方式添加水印容易被攻击且破解的问题,提升安全防御能力;同时还能够有效降低水印对于所生成语音的质量的负面影响,有效提升添加水印的语音合成波形的自然度和语音质量。
- 还没有人留言评论。精彩留言会获得点赞!