用于自体抗体相关疾病的适体的制作方法
本发明涉及了用于治疗和/或诊断与针对G-蛋白偶联受体的自体抗体相关的自体免疫疾病的新适体分子、包含这类适体分子的药物组合物、包含这类适体分子的血液成分分离柱和用于确定用作适体分子的序列的核苷酸序列的方法。
背景技术:
免疫系统形成每种哺乳动物的必需部分。哺乳动物在防御微生物、检测及移除异常细胞例如肿瘤细胞和在组织再生方面利用其免疫系统。因而,生物依赖于两种相互联系的防御机制:体液免疫和细胞免疫。
当与其抗原结合时,抗体是体液免疫应答的触发者。抗体可以按多种方式发挥作用。除中和抗原之外,抗体还激活补体系统。还存在针对身体自身抗原的抗体。作为产生这些所谓自体抗体的原因,观察到分子模拟和/或旁观者激活作用。自体抗体与自身抗原的特异性结合可以活化能够促进这些抗原降解的天然杀伤细胞(NK细胞)。
自体免疫疾病基于这类针对身体自身组成部分的抗体的特异性识别和结合,所述识别和结合触发针对自身细胞或组织的免疫应答。除这种免疫刺激性效应之外,自体抗体还可以通过其他机制促进致病表型的形成。
众所周知,存在这样的自体抗体,所述自体抗体对G-蛋白偶联受体(如:肾上腺素能α-1受体、肾上腺素能β-1受体、肾上腺素能β-2受体、内皮素ETA受体、毒蕈碱M受体、血管紧张素II AT1受体、蛋白酶激活的受体(PAR)受体、MAS-受体、5HT4-受体和/或M3-受体)的胞外部分具有特异性并且特异性结合时可以激活或阻断这些受体。
G-蛋白偶联受体是从胞外间隙转导信息至细胞中的信号转导分子。它们属于涵盖超过1000种不同受体并划分成五个亚组的受体家族。它们代表了许多不同物种中存在的经细胞膜进入细胞的信号转导原理。
GPCR的常见特性是它们具有三个不同的胞外环,所述胞外环具有物质可以与之结合并引起不同胞内反应的不同表位。体液蛋白质肾上腺素(adrenaline)能够与肾上腺素能β-1受体结合以增加心肌细胞搏动的力量和频率。
针对GPCR的功能性致病的自体抗体往往但并非总是IgG3(糖蛋白免疫球蛋白G,亚类3)亚型并具有与不同的GPCR环及这些环内部不同位置结合的能力。这些功能性致病的抗体通过它们与GPCR的相互作用产生病态细胞功能并转而产生机体功能。
因此,存在针对不同受体的许多不同自体抗体。在心肌的情况下,这些抗体例如是针对肾上腺素能β-1受体或毒蕈碱性乙酰胆碱受体的自体抗体。在其他疾病中具有重要作用的其他抗体是针对肾上腺素能α-1受体、肾上腺素能α-2受体、肾上腺素能β-2受体、内皮素1ETA受体、毒蕈碱M2受体、血管紧张素II AT1受体、蛋白酶激活的受体(PAR)受体、MAS-受体、5HT4-受体、M3-受体和其他受体的。
从永久性激活或阻断在疾病形成中发挥作用的相应受体意义上,生物中这类自体抗体的存在可以导致激动作用或拮抗作用。
扩张性心肌病(DCM)是这样的疾病之一,其中高百分数的患者具有与肾上腺素能β-1受体的胞外部分、尤其与肾上腺素能β-1受体的第一或第二环结合的这类激活性自体抗体。因此,提出DCM在这些患者中的自身免疫发病机制。一旦结合这些自体抗体,这些受体持续激活,因为限制GPCR激活的生理反馈机制受到抑制。
存在被提出与针对G-蛋白偶联受体的自体抗体相关的其他心血管系统疾病,如,查加斯心肌病(Chagas’cardiomyopathy)、围产期心肌病、心肌炎、肺动脉高血压(pulmonary hypertension)和恶性高血压。针对G-蛋白偶联受体的自体抗体还存在于例如青光眼、糖尿病、良性前列腺增生、硬皮病、雷诺氏综合症(Raynaud syndrome)和先兆子痫患者中和慢性查加斯病(Chaga’s disease)中以及那些肾同种异体移植排异的患者中。
通常,这些受体的表位区域由包含约20个氨基酸的肽链组成,而疾病特异性表位构成这些区域之一的3至5个氨基酸的序列。然而,对于几种自体免疫疾病的形成和慢性化,自体抗体与这些表位的不希望的相互作用发挥重要作用。
在最近研究中,可以证实,通过免疫球蛋白吸附从血液移除这些自体抗体有助于心肌再生(Wallukat G,Reinke P,Dorffel WV,Luther HP,Bestvater K,Felix SB,Baumann G.(1996)Removal of autoantibodies in dilated cardiomyopathy by immunoadsorption.lnt J Cardiol.54:191-195;Müller J,Wallukat G,Dandel M,Bieda H,Brandes K,Spiegelsberger S,Nissen E,Kunze R,Hetzer R(2000)Immunoglobulin adsorption in patients with idiopathic dilated cardiomyopathy.Circulation.101:385-391.W.V.Dorffel,S.B.Felix,G.Wallukat,S.Brehme,K.Bestvater,T.Hofmann,F.K.Kleber,G.Baumann,P.Reinke(1997)Short-term hemodynamic effects of immunoadsorption in dilated cardiomyopathy.Circulation 95,1994-1997和W.V.Dorffel,G.Wallukat,Y.Dorffel,S.B.Felix,G.Baumann(2004)lmmunoadsorption in idiopathic dilated cardiomyopathy,a 3-year follow-up.lnt J.Cardiol.97,20 529-534)。
已经进一步发现,某些适体可以用来干扰抗体、尤其对人β-1-肾上腺素能受体第二胞外环特异的自体抗体与其靶的相互作用(WO 2012/000889 A1)。适体是以对其靶分子的高亲和力为特征的短链寡核苷酸。通过抑制相互作用,适体能够在不需要移除这些抗体的情况下削弱或甚至永久消除对β-1-肾上腺素能受体的永久性激活。另外,用于治疗和/或诊断与存在针对G-蛋白偶联受体的自体抗体相关的自体免疫疾病的适体已经在WO 2012/119938 A2中公开。
根据一个优选的实施方案,这些适体用来削弱或消除相应的自体抗体对G-蛋白偶联受体的激活。根据另一个优选实施方案,适体用来中和针对G-蛋白偶联受体的自体抗体和/或减少该自体抗体对它们针对的G-蛋白偶联受体的影响。
然而,目前仅可获得数目非常有限的可以针对上述具体自体免疫疾病应用的适体并且它们在人类患者中应用时的有效性和无害性仍待证实。因此需要额外的适体,所述适体显示对自体抗体与GPCR的相互作用的增强干扰。
因此,本发明的目的是提供新适体用于治疗和/或诊断与针对G-蛋白偶联受体的自体抗体相关的自体免疫疾病。
另外,本发明的另一个目的是提供包含这类适体分子的药物组合物以及包含这类适体的血液成分分离柱(apheresis column)。
因此,本发明的目的还是提供种一种用于确定新适体的核苷酸序列的方法,所述的新适体用于治疗和/或诊断与针对G-蛋白偶联受体的自体抗体相关的自体免疫疾病。
技术实现要素:
这个目的通过如下文阐述的本发明多个方面解决。
根据本发明的第一方面,提供一种适体,所述适体包含满足产生规则集合P定义的语法的核苷酸序列:
条件为
a.)Q是自然数集
b.)F是如下定义的自然数子集
F:={X∈Q|(X>1)}
c.)使用F,定义:
d.)U是如下定义的非终结符集
U={S,M,N,D,E,Y,H,R,Z,L,BX,CX,K,V}
对于BX和CX,见c)
e.)W是如下定义的终结符集
W={A,C,G,T,GX}
GX指可以根据b.)和c.)导出的全部终结符(5)
f.)S∈U是起始符号
所述适体用于治疗和/或诊断与针对G-蛋白偶联受体的自体抗体相关的自体免疫疾病,其中“A”意指腺嘌呤核苷酸,“C”意指胞嘧啶核苷酸,“G”意指鸟嘌呤核苷酸并且如果核苷酸序列是DNA序列,则“T”意指胸腺嘧啶核苷酸,并且如果核苷酸序列是RNA序列,则“T”意指尿嘧啶核苷酸,其中所述适体不包含核苷酸序列GGTTGGTGTGGTTGG(SEQ ID No:22)、GGTTGGTGTGGT(SEQ ID NO:23)或CGCCTAGGTTGGGTAGGGTGGTGGCG(SEQ ID No:24)。
在本发明第一方面的优选实施方案中,适体的核苷酸序列具有至多593个核苷酸的长度。
在本发明第一方面的另一个优选实施方案中,核苷酸序列是DNA序列。
在本发明第一方面的又一个优选的实施方案中,核苷酸序列是RNA序列。
在本发明第一方面的优选实施方案中,包含于适体中的核苷酸序列是以下任一个序列:
(5'-GTTGTTTGGGGTGG-3'SEQ ID No:1)、
(5'-GTTGTTTGGGGTGGT-3'SEQ ID No:2)
(5'-GGTTGGGGTGGGTGGGGTGGGTGGG-3'SEQ ID No:3)、
(5'-TTTGGTGGTGGTGGTTGTGGTGGTGGTG-3'SEQ ID No:4)、
(5'-TTTGGTGGTGGTGGTTGTGGTGGTGGTGG-3'SEQ ID No:5)、
(5'-TTTGGTGGTGGTGGTTTTGGTGGTGGTGG-3'SEQ ID No:6)、
(5'-TTTGGTGGTGGTGGTGGTGGTGGTGGTGG-3'SEQ ID No:7)、
(5'-TTTGGTGGTGGTGGTTTGGGTGGTGGTGG-3'SEQ ID No:8)、
(5'-TGGTGGTGGTGGT-3'SEQ ID No:9)、
(5'-GGTGGTGGTGG-3'SEQ ID No:10)、
(5'-GGTGGTTGTGGTGG-3'SEQ ID No:11)、
(5'-GGTGGTGGTGGTTGTGGTGGTGGTGG-3'SEQ ID No:12)、
(5'-GGTGGTGGTGGTTGTGGTGGTGGTGGTTGTGGTGGTGGTGGTTGTGGTGGTGG TGG-3'SEQ ID No:13)、
(5'-GGTGGTTGTGGTGGTTGTGGTGGTTGTGGTGG-3'SEQ ID No:14)、
(5'-TTTGGTGGTGGTGGTTGTGGTGGTGGTGGTTT-3'SEQ ID No:15)、
(5'-GGTGGTGGTGTTGTGGTGGTGGTGGTTT-3'SEQ ID No:16)、
(5'-TTTGGTGGTGGTGGTGTGGTGGTGGTGG-3'SEQ ID No:17)、
(5'-TGGTGGTGGT-3'SEQ ID No:18)、
(5'-TTAGGGTTAGGGTTAGGGTTAGGG-3'SEQ ID NO:20),
在本发明第一方面的优选实施方案中,适体的核苷酸序列具有至少4个核苷酸、优选地至少8个核苷酸、更优选地至少12个核苷酸的长度。
在本发明第一方面的优选实施方案中,适体的核苷酸序列具有至多120个核苷酸、优选地至多100个核苷酸、更优选地至多80个核苷酸的长度。
在本发明第一方面的优选实施方案中,适体能够相互作用于自体抗体、优选地相互作用于对G-蛋白偶联受体特异的自体抗体、优选地相互作用于对以下任一种人G-蛋白偶联受体特异的自体抗体:肾上腺素能α-1受体、肾上腺素能β-1受体、肾上腺素能β-2受体、内皮素1ETA受体、毒蕈碱M受体、血管紧张素II AT1受体、PAR受体、MAS-受体、5HT4-受体和/或M3受体。
在本发明第一方面的优选实施方案中,适体用作患有自体免疫疾病的患者的血液或其成分(constituent)的治疗性血液成分分离(apheresis)期间的选择性组分(selective ingredient),所述自体免疫疾病与针对G-蛋白偶联受体的自体抗体的出现相关。
在本发明第一方面的优选实施方案中,自体免疫疾病是以下之一:心肌病、缺血性心肌病(iCM)、扩张型心肌病(DCM)、围产期心肌病(PPCM)、特发性心肌病、查加斯心肌病、化疗所致心肌病、查加斯巨结肠症(Chagas’megacolon)、查加斯巨食道症(Chagas’megaesophagus)、查加斯神经病(Chagas’neuropathy)、良性前列腺增生、硬皮病、雷诺氏综合症、外周动脉闭塞性疾病(PAOD)、先兆子痫、肾同种异体移植排异、心肌炎、青光眼、高血压、肺动脉高血压、恶性高血压、代谢综合征、脱发、斑秃、偏头痛、帕金森病、癫痫、丛集性头痛、多发性硬化症、抑郁、区域疼痛综合征、不稳定型心绞痛、系统性红斑狼疮(SLE)、精神分裂症、舍格伦综合征( syndrome)、牙周炎、心房颤动、白斑病、溶血性尿毒症综合征、僵人综合征和/或先天性心脏传导阻滞。
在本发明第一方面的优选实施方案中,适体用于体外检测对G-蛋白偶联受体、优选地对如下的人G-蛋白偶联受体:肾上腺素能α-1受体、肾上腺素能β-1受体、肾上腺素能β-2受体、内皮素1ETA受体、毒蕈碱M受体、血管紧张素II AT1受体、PAR受体、MAS-受体、5HT4-受体和/或M3受体特异的抗体。
在本发明第一方面的另一个优选实施方案中,待检测的抗体是自体抗体。
在本发明第一方面的又一个优选的实施方案中,抗体存在于或来源于体液,优选地人体的流体、更优选地人血、血浆、血清、尿、粪便、滑液、间质液、淋巴液、唾液、脊髓液和/或泪液。
在本发明第一方面的又一个优选的实施方案中,身体流体取自患有或疑似患有自体免疫疾病的个体,优选地所述自体免疫疾病为与患者血清中存在对G蛋白偶联受体特异的自体抗体相关的自体免疫疾病,更优选地所述自体免疫疾病为与患者血清中存在对肾上腺素能α-1受体、肾上腺素能β-1受体、肾上腺素能β-2受体、内皮素1ETA受体、毒蕈碱M受体、血管紧张素II AT1受体、PAR受体、MAS-受体、5HT4-受体和/或M3受体特异的自体抗体相关的自体免疫疾病。
在本发明第一方面的又一个优选的实施方案中,适体包含以下核苷酸序列(5’-GGTGGTGGTGGTTGTGGTGGTGGTGG-3’SEQ ID No.12)。
根据本发明第二方面的,提供一种药物组合物,所述药物组合物包含至少一种本发明的适体和任选地至少一种药学上可接受的赋形剂。
在本发明第二方面的优选实施方案中,提供一种药物组合物,所述药物组合物用于治疗与针对G-蛋白偶联受体的自体抗体相关的自体免疫疾病。
根据本发明第三方面的,提供包含根据本发明第一方面的适体的血液成分分离柱。
在本发明第三方面的优选实施方案中,提供用于治疗和/或诊断自体免疫疾病的血液成分分离柱,其中自体免疫疾病是心肌病、扩张型心肌病(DCM)、缺血性心肌病(iCM)、围产期心肌病(PPCM)、特发性心肌病、查加斯心肌病、化疗所致心肌病、查加斯巨结肠症、查加斯巨食道症、查加斯神经病、良性前列腺增生、硬皮病、雷诺氏综合症、外周动脉闭塞性疾病(PAOD)、先兆子痫、肾同种异体移植排异、心肌炎、青光眼、高血压、肺动脉高血压、恶性高血压、代谢综合征、脱发、斑秃、偏头痛、帕金森病、癫痫、丛集性头痛、多发性硬化症、抑郁、区域疼痛综合征、不稳定型心绞痛、系统性红斑狼疮(SLE)、精神分裂症、舍格伦综合征、牙周炎、心房颤动、白斑病、溶血性尿毒症综合征、僵人综合征和/或先天性心脏传导阻滞。
根据本发明的第四方面,提供一种用于制备适体寡核苷酸的方法,所述方法包括步骤:确定用作适体序列的核苷酸序列,其包括应用以下的产生规则集合P:
条件为
a.)Q是自然数集
b.)F是如下定义的自然数子集
F:={X∈Q|(X>1)}
c.)使用F,定义:
d.)U是如下定义的非终结符集
U={S,M,N,D,E,Y,H,R,Z,L,BX,CX,K,V}
对于BX和CX,参见c)
e.)W是如下定义的非终结符集
W={A,C,G,T,GX}
GX指可以根据b.)和c.)导出的全部终结符(5)
f.)S∈U是起始符号
其中“A”意指腺嘌呤核苷酸,“C”意指胞嘧啶核苷酸,“G”意指鸟嘌呤核苷酸并且如果核苷酸序列是DNA序列,则“T”意指胸腺嘧啶核苷酸,并且如果核苷酸序列是RNA序列,则“T”意指尿嘧啶核苷酸,以及生产具有第一步骤中获得的核苷酸序列的适体寡核苷酸。
附图说明
图1显示通过适体(2μl)中和α1肾上腺素能受体AAB。
图2显示通过适体(2μl)中和β1肾上腺素能受体AAB。
图3显示适体对AAB作用于PAR1/PAR2受体的影响。
图4显示适体(2μl)中和内皮素1ETA受体AAB。
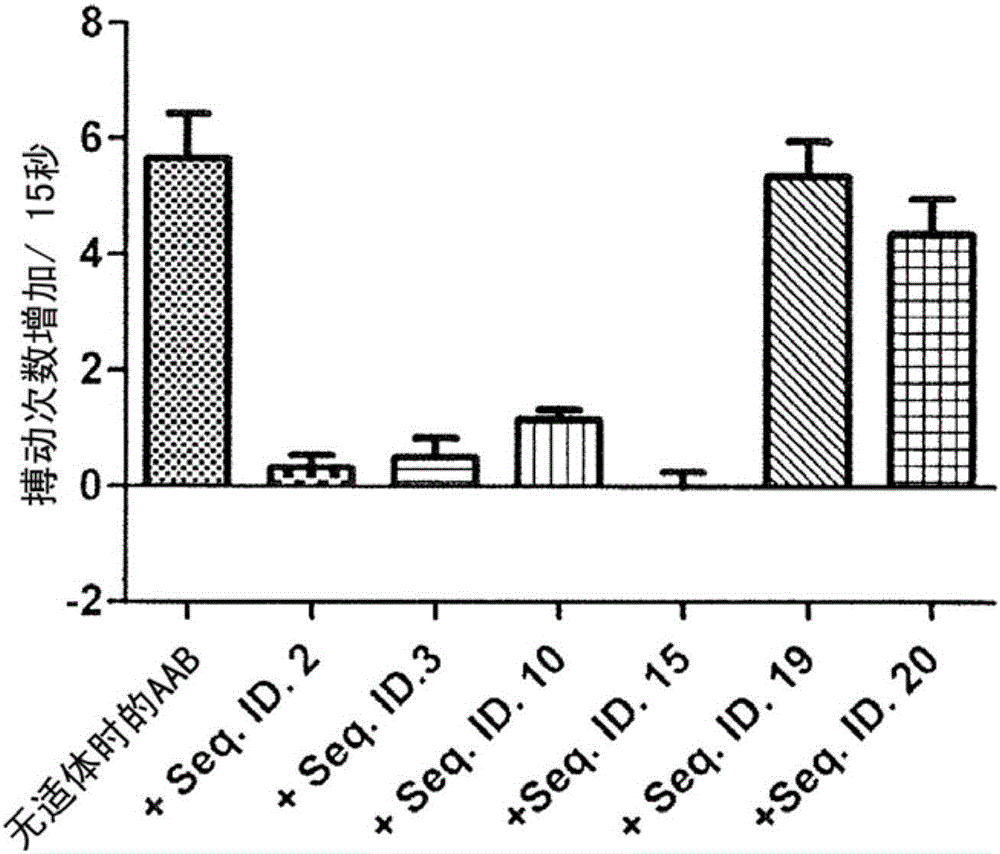
图5显示通过SEQ ID No.10、SEQ ID No.19和SEQ ID No.20的适体中和β1-肾上腺素能受体AAB的作用。
图6显示不同适体(2μl)对心肌细胞搏动率的作用。
图7显示SEQ ID No.12的适体对针对不同G-蛋白偶联受体的AAB的作用。
图8显示本发明的100nM、400nM和1000nM不同适体(SEQ ID No.:1、4至9、11至14和16至18)(2μl)中和β1肾上腺素能受体AAB。
图9显示使用根据本发明给定的语法算得的适体彼此(SEQ ID No.:25至45)及与非本发明的对照序列(SEQ ID No.:46至50)的相互序列同一性(mutual sequence identities)。
图10显示本发明的100nM不同适体(SEQ ID No.:25至45)(2μl)中和β1肾上腺素能受体AAB。
图11显示本发明的400nM不同适体(SEQ ID No.:31至34、44和45)(2μl)中和β1肾上腺素能受体AAB。
图12显示非本发明的100nM、400nM和1000nM不同对照序列(SEQ ID No.:46至50)(2μl)中和β1肾上腺素能受体AAB。
图13显示在100nM SEQ ID No.:12的本发明适体不存在或存在下,从遭受抑郁或查加斯心肌病的患者(从左至右)分离的β1肾上腺素能受体AAB的活性。
图14显示在100nM SEQ ID No.:12的本发明适体不存在或存在下,从遭受青光眼、精神分裂症、查加斯心肌病、溶血性尿毒症综合征(EHEC)或阿尔茨海默病的患者(从左至右)分离的β2肾上腺素能受体AAB的活性。
图15显示在100nM SEQ ID No.:12的本发明适体不存在或存在下,从遭受脱发,肾同种异体移植排异或肾病下的高血压(high blood pressure at kidney disease)的患者(从左至右)分离的AT1AAB的活性。
图16显示在100nM SEQ ID No.:12的本发明适体不存在或存在下,从遭受肺动脉高血压、雷诺氏病(Raynaud’s disease)、心绞痛或肾病下的高血压的患者(从左至右)分离的ETA AAB的活性。
图17显示在100nM SEQ ID No.:12的本发明适体不存在或存在下,从遭受肺动脉高血压、化疗、多发性硬化症、脱发、斑秃、溶血性尿毒症综合征(EHEC)、舍格伦综合征、阿尔茨海默病、神经性皮炎、I型糖尿病或银屑癣的患者(从左至右)分离的α1AAB的活性。
图18显示在100nM SEQ ID No.:12的本发明适体不存在或存在下,从遭受雷诺氏病、心绞痛或舍格伦综合征的患者(从左至右)分离的PAR AAB的活性。
图19显示在100nM SEQ ID No.:12的本发明适体不存在或存在下,从遭受化疗、多发性硬化症或I型糖尿病的患者(从左至右)分离的MAS AAB的活性。
图20显示在100nM SEQ ID No.:12的本发明适体不存在或存在下,从遭受抑郁,精神分裂症或偏头痛/帕金森病的患者(从左至右)分离的5HT4AAB的活性。
图21显示在100nM SEQ ID No.:12的本发明适体不存在或存在下,从遭查加斯心肌病、斑秃、偏头痛/帕金森病或舍格伦综合征的患者(从左至右)分离的M2AAB的活性。
具体实施方式
发明详述
发明人认识到,能够与对G-蛋白偶联受体特异的自体抗体相互作用并且干扰这两种分子之间致病型相互作用的寡核苷酸共有确定的分子样式。从这个认识出发,发明人成功地设想了由根据权利要求1的产生规则集合P定义的语法,复现了作为GPCR-自体抗体的有效结合物的适体的结构样式。
此前,本领域仅已知数目非常有限的似乎干扰自体抗体与G-蛋白偶联受体结合的适体。尝试鉴定适于治疗和/或诊断与针对G-蛋白偶联受体的自体抗体相关的自体免疫疾病的新适体是非常繁琐的并且没有前景最终确定合适的核苷酸序列,就适体以药物方式应用于人类患者的诊断或治疗的严格要求而言尤其如此。为此目的,迫切需要提供用于对抗这些自体免疫疾病的额外适体。
发明人现在首次鉴定了有效对抗与G-蛋白偶联受体自体抗体相关的疾病的适体的结构共性,并且能够确定产生规则集合以确定如适体那样有功能并且有效的核苷酸序列集。因此,现在首次可以提供数目增加的干扰GPCR-自体抗体的适体。
鉴定共享相同或几乎高度相同特性的序列的常见方案是过滤与具有这类特性的给定序列显示例如至少80%或90%序列同一性的全部那些序列。这种方案背后的构思是高度相似的序列应当共有高度相似的特性。
已经使用并应用在序列相似性和功能特性保留性之间的这种关系多年,例如在基于建模的知识背景下。然而,已知存在共有低相互序列同一性但是仍具有高度相似特性的核苷酸或氨基酸序列。为了识别并描述尽管序列相似性低但保留功能的那些序列,需要更复杂的方法。
本文展示的发明人认识是,开发并利用在不考虑序列同一性的情况下特异性识别并且确定有效和有功能序列的语法。使用这种语法,可以仅算得具有所追求的特定序列特性的序列。相同的语法也可以用来在任意序列汇集物中特异性识别具有所需特性的序列。
语法的准确性通常由以下事实反映:仅一个错误字符或在错误位置的字符就可能导致不能由语法识别的序列。这对本发明及其应用具有高度意义。在要求保护的适体序列和序列的关键位置处的一个错误核苷酸会无法由语法识别。
使用这种方法,本发明允许特异性排除依据语法不符合序列标准并且因此将导致不能结合GPCR自体抗体的全部序列。在另一方面,这种方法允许算得和/或过滤符合设定标准的全部序列,无论复杂性或与给定模板的序列同一性如何。
为了显示已算得序列的功能特性不是序列同一性或相似性的函数,而是语法的函数(相互序列同一性低的功能性序列具有相等或高度相似的特性),应用给定语法的规则,同时考虑边界条件以算得显示低相互序列同一性的几个序列。然而,本文中将展示,如此依据语法产生的全部序列均具有要求保护的与GPCR自体抗体结合的特性。
图9显示根据本发明算得的适体的ID(SEQ ID No.:25至45)及其相互序列同一性。已经通过使用Kalign软件连同设定至最大的开放罚分(open penalty)和延长罚分(extension penalty),确定序列同一性。这种软件已经在Lassmann和Sonnhammer,Kalign--an accurate and fast multiple sequence alignment algorithm.(2005)BMC bioinformatics 6:298;Lassmann等人,Kalign2:high-performance multiple alignment of protein and nucleotide sequences allowing external features.(2009Feb)Nucleic acids research 37(3):858-65;Goujon等人,A new bioinformatics analysis tools framework at EMBL-EBI.(2010Jul)Nucleic acids research 38(网络服务器发布):W695-9;McWilliam等人,Analysis Tool Web Services from the EMBL-EBI.(2013Jul)Nucleic acids research 41(网络服务器发布):W597-600以及Li等人,The EMBL-EBI bioinformatics web and programmatic tools framework.(2015Jul 01)Nucleic acids research 43(W1):W580-4中描述。
根据本发明的一个实施方案,两个核苷酸序列之间的同一性在可以如上所述确定。根据本发明的另一个实施方案,两个核苷酸序列之间的同一性在可以根据上文援引的一个或多个文件确定。
已经算得类型广泛的要求保护的本发明不同序列,基本上涵盖理论上可能的序列同一性的完整范围。可以从图9见到,功能性适体序列之间的相互序列同一性范围从90%(在SEQ ID No.:38和42或40和41之间)至11%(在SEQ ID No.:28和29之间)。
对序列SEQ ID No:12、3、10和15使用如下文显示的移位-归约解析器(Shift-Reduce-Parser),全部序列可以通过给定语法规则算得和/或识别。
已经使用不根据本发明的随机化寡核苷酸作为对照序列(SEQ ID No.:46至50)。这些序列不由给定语法识别。对照与本发明功能性适体显示在10%(在SEQ ID No.:30和47之间)至60%(在SEQ ID No.:39和48之间)范围内的序列同一性。
值得注意地,本发明适体SEQ ID No:28与对照序列SEQ ID No:48具有44%的序列同一性,如下文将显示,所述对照序列是无功能的(参见实施例11和图12)。与之相反,本发明适体SEQ ID No:29与SEQ ID No:28显示出仅11%的很低序列同一性,而两个序列均有活性,如下文将显示(参见实施例9和实施例10和图10和图11)。显示本发明序列之间序列同一性很低和与无功能序列的同一性相比而言更高(即4倍更高)的这个实例清楚地显示,序列的活性是由语法代表的序列共性的函数,而不是序列同一性的函数。
这些结果显示了给定语法编码的序列特性和借助该语法产生或识别的序列抑制自体抗体的能力之间的清晰关系。这种关系并不基于序列同一性,而基于语法本身,这通过算得相互序列同一性很低的有效序列展示。以相同方式,本发明适体的测量活性与对照序列的结果的比较证实了关于本文要求保护的全部适体序列之功能的结果。
本发明的适体以满足下述语法为特征,所述语法由如通过权利要求1进一步限定的产生规则集合定义。所述语法反映了有效对抗与针对G-蛋白偶联受体的自体抗体相关的自体免疫疾病的适体的结构性要求。
在本发明的一个优选实施方案中,适体包含满足下述语法的核苷酸序列,所述语法表征无语境语言(乔姆斯基层次(Chomsky hierarchy)中的2型语法)或语境敏感语言(乔姆斯基层次中的1型语法)或由短语结构语法(乔姆斯基层次中的0型语法)描述的语言(递归可枚举)。在一个更优选的实施方案中,适体包含包含满足下述语法的核苷酸序列,所述语法表征无语境语言(乔姆斯基层次中的2型语法)。
出于的目的本发明,术语“适体”指特异性并以高亲和力结合于靶分子的寡核苷酸。在限定的条件下,适体可以折叠成特定的三维结构。
本发明的适体包含核酸分子的序列、核苷酸或由其组成。根据一个优选实施方案,本发明的适体由满足本发明语法的核苷酸序列组成或由本文另行限定的核苷酸序列组成。
本发明的适体优选地包含未修饰和/或修饰的D-和/或L-核苷酸。根据常见的核酸单字母代码,碱基“C”代表胞嘧啶,“A”代表腺嘌呤,”G”代表鸟嘌呤,并且如果核苷酸序列是DNA序列,则“T”代表胸腺嘧啶,以及如果核苷酸序列是RNA序列,“T”代表尿嘧啶核苷酸。如果下文不相反指示,术语“核苷酸”应当指核糖核苷酸和脱氧核糖核苷酸。
本发明的适体可以包含DNA核苷酸序列或nRNA-核苷酸序列或由其组成并且因此,可以分别称作DNA-适体或RNA-适体。可以理解,如果本发明的适体在本发明各处具体说明的序列基序内部包含RNA-核苷酸序列,则“T”代表尿嘧啶。
为了本发明各处的简洁性,主要提到明确的DNA-核苷酸序列。然而,可以理解,相应的RNA-核苷酸序列也包含于本发明包含。
根据一个实施方案,优选使用DNA-适体。DNA-适体通常比RNA-适体在血浆中更稳定。然而,根据备选实施方案,RNA-适体是优选的。
本发明的适体可以包含含有2'-修饰的核苷酸(例如2'-氟-、2'-甲氧基-、2'-甲氧乙基-和/或2'-氨基修饰的核苷酸)的核苷酸序列。本发明的适体还可以包含脱氧核糖核苷酸、修饰的脱氧核糖核苷酸、核糖核苷酸和/或修饰的核糖核苷酸的混合。术语“2'-氟-修饰的核苷酸”、“2'-甲氧基-修饰的核苷酸”、“2'-甲氧乙基-修饰的核苷酸”和/或“2-氨基-修饰的核苷酸"分别指修饰的核糖核苷酸和修饰的脱氧核糖核苷酸。
本发明的适体可以包含修饰。这类修饰涵盖例如烷基化(即甲基化)、芳基化或乙酰化至少一个核苷酸、纳入对映异构体和/或适体与一个或多个其他核苷酸或核酸序列融合。这类修饰可以包含例如5'-和/或3’-PEG-或5’-和/或3'-CAP-修饰。备选地或额外地,本发明的适体可以包含修饰的核苷酸,优选地选自锁核酸、2'-氟-、2'-甲氧基-和/或2'-氨基修饰的核苷酸。
锁核酸(LNA)代表相应RNA核苷酸的类似物,其中构象已经固定。锁核酸的寡核苷酸包含一个或多个双环核糖核苷,其中2'-OH基团借助曱基与C4-碳原子连接。与相应的未修饰RNA-适体对应物相比,锁核酸显示出对于核酸酶的改善的稳定性。杂交特性也改善,这允许适体的亲和力和特异性增强。
另一个优选的修饰是添加所谓3'-CAP-、5'-CAP-结构和/或修饰的鸟苷-核苷酸(例如7-甲基-鸟苷)至适体的3'-和/或5'-端。这种3'-和/或5'-端修饰具有以下作用:保护适体免遭核酸酶快速降解。
备选地或额外地,本发明的适体可以显示出聚乙二醇化3'或5'-端。3'-或5'-PEG修饰包括添加至少一个聚乙二醇(PEG)单位,优选地PEG基团包含1至900个亚乙基、更优选地1至450个亚乙基。在优选的实施方案中,适体包含具有HO-(CH2CH2O)n-H的线性PEG单位,其中n是从1至900的整数,优选地n是1至450的整数。
本发明的适体可以包含具有硫代磷酸酯主链的核酸序列或由其组成或可以完全或部分地配置为肽核酸(PNA)。还可以如Keefe AD等人,Nat Rev Drug Discov.2010Jul;9(7):537-50或Mayer G,Angew Chem Int Ed Engl.2009;48(15):2672-89或Mayer,G.和Famulok M.,Pharmazie in unserer Zeit 2007;36:432–436中所述那样修饰本发明的适体。
另外,适体可以在合适的载体中包囊化以保护其结构完整性以及促进它们在细胞内部递送。优选的载体包括脂质体、脂质囊泡、微粒子等。
脂质囊泡类似于质膜,并且可以使它们与细胞膜融合。大部分脂质体和多层囊泡并不轻易融合,主要因为囊泡曲率半径储存的能量最小。优选的脂质囊泡包括单层小囊泡。构思用于包囊化本发明适体的单层小囊泡极有融合性,因为它们具有非常紧凑的曲率半径。单层小囊泡的平均直径是5nm至500nm;优选地10nm至100nm、更优选地20nm至60nm,包括40nm。这种尺寸允许囊泡穿过内皮细胞之间的间隙,因而允许静脉内施用后全身性递送含有适体的囊泡。有用的囊泡可以在尺寸上大幅度变动并且根据适体的特定应用而选择。
单层小囊泡可以使用本领域可获得的程序(如例如WO 2005/037323 A2中公开)在体外轻易地制备。从中形成囊泡的组合物含有作为稳定囊泡前体的磷脂、优选地连同另一种极性脂质,和任选地连同一种或多种额外的极性脂质和/或筏前体。作为稳定囊泡前体的优选磷脂包括1-棕榈酰-2-二十二碳六烯酰-sn-甘油-3-磷酰胆碱和1,2-二油酰-sn-甘油-3-磷酰胆碱。优选的极性脂质包括:1-棕榈酰-2-油酰-sn-甘油酰-3-磷酸酯、1,2-二油酰-sn-甘油酰-3-乙基磷酰胆碱、1,2-二油酰-sn-甘油酰-3-磷脂酰乙醇胺、1,2-二油酰-sn-甘油酰-3-[磷酰-l-丝氨酸](常见的鞘磷脂)、1,2-二肉豆蔻酰-sn-甘油和1-棕榈酰-2-羟基-sn-甘油-3-磷酰胆碱。
其他优选的极性脂质包括磷脂酰丝氨酸、磷脂酰甘油、混合链磷脂酰胆碱、磷脂酰乙醇和含有二十碳六烯酸的磷脂。优选的筏前体的一个例子是胆固醇。
通过上文提到的方式之一修饰本发明适体的一个优点是,适体可以对抗多种不利影响(例如在其中使用适体的环境中存在的核酸酶)而被稳定化。所述修饰也适于适应适体的药理学特性。修饰优选地不改变适体的亲和力或特异性。
本发明的适体也可以与载体分子和/或报道分子缀合。载体分子包括这类分子,与适体缀合时,所述分子延长缀合的适体在人血浆中的血浆半寿期,例如通过增强稳定性和/或通过影响排泄率。合适载体分子的一个例子是PEG。
报道分子包括允许检测缀合的适体的分子。这类报道分子的例子是GFP、生物素、胆固醇、染料例如荧光染料、电化学活性的报道分子和/或包含放射性残余物、尤其适于PET(正电子发射断层摄影术)检测的放射性核素例如18F、11C、13N、15O、82Rb或68Ga的化合物。技术人员非常清楚合适的载体和报道分子以及如何将其与本发明适体缀合的方式。
在优选的实施方案中,本发明适体的核苷酸序列具有至少4个核苷酸、更优选地至少8个核苷酸、甚至更优选地至少12个核苷酸和甚至更优选地至少16个核苷酸的长度。在另一个优选实施方案中,本发明适体的核苷酸序列具有至多120个核苷酸、更优选地至多100个核苷酸、甚至更优选地至多80个核苷酸和甚至更优选地至多60个核苷酸的长度。根据一个实施方案,本发明适体的核苷酸序列具有至多40个核苷酸、尤其至多20个核苷酸的长度。
根据本发明的,适体不由以下任何核苷酸序列组成或不包含以下任何核苷酸序列GGTTGGTGTGGTTGG(SEQ ID No:22)、GGTTGGTGTGGT(SEQ ID NO:23)或CGCCTAGGTTGGGTAGGGTGGTGGCG(SEQ ID No:24)。这个前提应当适用于如本文所述或定义的本发明适体或适体基团的任何定义。
根据一个优选实施方案,本发明的适体不由核苷酸序列SEQ ID NO:22、23或24中任一者或与核苷酸序列SEQ ID NO:22、23或24中任一者大于90%相同的任何序列组成或不包含前述序列。根据另一个优选实施方案,本发明的适体不由核苷酸序列SEQ ID NO:22、23或24中任一者或与核苷酸序列SEQ ID NO:22、23或24中任一者大于85%相同的任何序列组成或不包含前述序列。根据一个具体实施方案,本发明的适体不由核苷酸序列SEQ ID NO:22、23或24中任一者或与核苷酸序列SEQ ID NO:22、23或24中任一者至少80%相同的任何序列组成或不包含前述序列。
根据另一个本发明的优选实施方案,适体序列形成本发明的部分,所述的部分由与本文公开的单个适体序列至少85%相同、更优选至少90%相同,甚至更优选至少95%相同的核酸序列组成或包含这种核酸序列。
根据本发明通过使用Karlin和Altschul的数学算法完成两个序列之间同一性百分数的确定(Proc.Natl.Acad.Sci.USA (1993)90:5873-5877)。这种算法是Altschul等人的BLASTN和BLASTP程序(J.Mol.Biol.(1990)215:403-410)的基础。用BLAST程序执行BLAST核苷酸检索。为了比较目的而获得带空位的比对结果,如Altschul等人中所述那样(Nucleic Acids Res.(1997)25:3389-3402)使用空位BLAST(Gapped BLAST)。使用BLAST程序和空位BLAST程序时,可以使用相应程序的默认参数。
根据本发明的一个优选实施方案,包含于适体中的核苷酸序列是以下任一个序列:(5'-GTTGTTTGGGGTGG-3'SEQ ID No:1)、
(5'-GTTGTTTGGGGTGGT-3'SEQ ID No:2)、
(5'-GGTTGGGGTGGGTGGGGTGGGTGGG-3'SEQ ID No:3)、
(5'-TTTGGTGGTGGTGGTTGTGGTGGTGGTG-3'SEQ ID No:4)、
(5'-TTTGGTGGTGGTGGTTGTGGTGGTGGTGG-3'SEQ ID No:5)、
(5'-TTTGGTGGTGGTGGTTTTGGTGGTGGTGG-3'SEQ ID No:6)、
(5'-TTTGGTGGTGGTGGTGGTGGTGGTGGTGG-3'SEQ ID No:7)、
(5'-TTTGGTGGTGGTGGTTTGGGTGGTGGTGG-3'SEQ ID No:8)、
(5'-TGGTGGTGGTGGT-3'SEQ ID No:9)、(5'-GGTGGTGGTGG-3'SEQ ID No:10)、(5'-GGTGGTTGTGGTGG-3'SEQ ID No:11)、
(5'-GGTGGTGGTGGTTGTGGTGGTGGTGG-3'SEQ ID No:12)、
(5'-GGTGGTGGTGGTTGTGGTGGTGGTGGTTGTGGTGGTGGTGGTTGTGGTGGTGGTGG-3'SEQ ID No:13)、
(5'-GGTGGTTGTGGTGGTTGTGGTGGTTGTGGTGG-3'SEQ ID No:14)、
(5'-TTTGGTGGTGGTGGTTGTGGTGGTGGTGGTTT-3'SEQ ID No:15)、
(5'-GGTGGTGGTGTTGTGGTGGTGGTGGTTT-3'SEQ ID No:16)、
(5'-TTTGGTGGTGGTGGTGTGGTGGTGGTGG-3'SEQ ID No:17)、
(5'-TGGTGGTGGT-3'SEQ ID No:18)、
(5'-TTAGGGTTAGGGTTAGGGTTAGGG(SEQ ID NO:20)。根据另一个优选实施方案,本发明的适体具有前述核苷酸序列之一。
根据更优选的实施方案,包含于适体中的核苷酸序列是以下任一个序列:(5'-GTTGTTTGGGGTGGT-3'SEQ ID No:2)、
(5'-GGTTGGGGTGGGTGGGGTGGGTGGG-3'SEQ ID No:3)、
(5'-GGTGGTGGTGG-3'SEQ ID No:10)、
(5'-GGTGGTGGTGGTTGTGGTGGTGGTGG-3'SEQ ID No:12)、
(5'-TTTGGTGGTGGTGGTTGTGGTGGTGGTGGTTT-3'SEQ ID No:15)。根据另一个更优选的实施方案,本发明的适体具有前述核苷酸序列之一。
根据特别优选的实施方案,适体包含核苷酸序列
(5’-GGTGGTGGTGGTTGTGGTGGTGGTGG-3’SEQ ID No.12)。根据另一个特别优选的实施方案,适体具有核苷酸序列
(5’-GGTGGTGGTGGTTGTGGTGGTGGTGG-3’SEQ ID No.12)。
根据本发明的一个不同优选实施方案,包含于适体中的核苷酸序列是以下任一个序列:(5'-GCGGTGGTGGGATGGGTTGGATCCGC-3'SEQ ID No:25)、(5'-GGGTCGGGATCTAGGGTCAGG-3'SEQ ID No:26)、(5'-
GGTGGGTCGGTAGGGTTT-3'SEQ ID No:27)、(5'-
TTGGCTGGATCGGACGGT-3'SEQ ID No:28)、
(5'-GGTCGGGTTCGGTGGTTA-3'SEQ ID No:29)、
(5'-GGGATCGGTTCGGTAGGTGGGTGGGTTGG-3'SEQ ID No:30)、
(5'-GGCCGGCGCGGCCGG-3'SEQ ID No:31)、
(5'-GGAAGGATCGGAAGG-3'SEQ ID No:32)、(5'-GGTAGGCTCGGTAGG-3'SEQ ID No:33)、(5'-GGATGGTTAGGATGG-3'SEQ ID No:34)、
(5'-CCGTCGGTCCGTTCGGTATTTTTTTCTGGGTGGCTGAGGATCG-3'
SEQ ID No:35)、
(5'-GGGTTGGTCCGTTGGGTATTTTTTTATGGGTTGCCTGGTTGGG-3'
SEQ ID No:36)、
(5'-TCCCATCGGGTAGGGTTATTTGGGTTCTGGGTGGCTGAGGATCGATC-3'SEQ ID No:37)、(5'-TGGCGGTGGT-3'SEQ ID No:38)、
(5'-TGGAGGTGGA-3'SEQ ID No:39)、(5'-AGGTGGTGGA-3'SEQ ID No:40)、(5'-AGGTGGCGGA-3'SEQ ID No:41)、
(5'-GTGGTGGTGGTGTTGGTGGTGGTGGG-3'SEQ ID No:42)、
(5'-TGGGTTGGGTTGTTGTTGTTGGGTTGGGT-3'SEQ ID No:43)、
(5'-GGTGGTGGTGGTGGTTGGTTTTTGGTTGGTGGTGGTGGTGG-3'SEQ ID No:44)、
(5'-CTGGGGTTGGGTTTGGTTTTGTTTTGGTTTGGGTTGGGGTC-3'SEQ ID No:45)。根据另一个优选实施方案,本发明的适体具有前述核苷酸序列之一。
根据更优选的实施方案,包含于适体中的核苷酸序列是以下任一个序列:(5'-GGTGGGTCGGTAGGGTTT-3'SEQ ID No:27)、
(5'-TTGGCTGGATCGGACGGT-3'SEQ ID No:28)、(5'-GGTCGGGTTCGGTGGTTA-3'SEQ ID No:29)、(5'-TGGCGGTGGT-3'SEQ ID No:38)、(5'-TGGAGGTGGA-3'SEQ ID No:39)、(5'-AGGTGGTGGA-3'SEQ ID No:40)、(5'-AGGTGGCGGA-3'SEQ ID No:41)。根据另一个更优选的实施方案,本发明的适体具有前述核苷酸序列之一。
根据另一个更优选的实施方案,包含于适体中的核苷酸序列是以下任一个序列:5'-GGTGGGTCGGTAGGGTTT-3'SEQ ID No:27)、(5'-GGTCGGGTTCGGTGGTTA-3'SEQ ID No:29)、(5'-TGGCGGTGGT-3'SEQ ID No:38)、(5'-TGGAGGTGGA-3'SEQ ID No:39)、(5'-AGGTGGTGGA-3'SEQ ID No:40)、(5'-AGGTGGCGGA-3'SEQ ID No:41)。根据另一个更优选的实施方案,本发明的适体具有前述核苷酸序列之一。
根据另一个更优选的实施方案,包含于适体中的核苷酸序列是以下任一个序列:5'-GGTGGGTCGGTAGGGTTT-3'SEQ ID No:27)、(5'-GGTCGGGTTCGGTGGTTA-3'SEQ ID No:29)、(5'-TGGCGGTGGT-3'SEQ ID No:38)、(5'-TGGAGGTGGA-3'SEQ ID No:39)。根据另一个更优选的实施方案,本发明的适体具有前述核苷酸序列之一。
根据特别优选的实施方案,适体包含核苷酸序列(5'-TGGCGGTGGT-3'SEQ ID No:38)。根据另一个特别优选的实施方案,适体具有核苷酸序列(5’-TGGCGGTGGT-3'SEQ ID No:38)。
本发明的适体可用于治疗和/或诊断与针对G-蛋白偶联受体的自体抗体相关的自体免疫疾病。在本发明的上下文中,认为适体可用于人类受试者以及用于动物受试者。根据一个实施方案,适体用于人受试者中。根据另一个实施方案,适体用于动物受试者中。根据一个优选的实施方案,本发明的适体用于治疗如本文定义的自体免疫疾病。
与针对G-蛋白偶联受体的自体抗体相关的疾病是其中可以在受这种疾病侵袭的患者中使用如本领域已知的标准方法检测到这类自体抗体的疾病。根据一个优选实施方案,疾病由针对G-蛋白偶联受体的自体抗体引起。根据一个实施方案,其中可以检测到针对G-蛋白偶联受体的自体抗体、但是其他症状不明显的患者的状态可以视为与针对G-蛋白偶联受体的自体抗体相关的自体免疫疾病。
因此,本发明的适体优选地用于治疗体液中具有针对G-蛋白偶联受体的抗体的患者。根据本发明的一个优选实施方案,使用本发明适体待处理或诊断的患者是其中可以检测到针对G-蛋白偶联受体的抗体的患者。
已经报告或在文献中已知几种疾病与针对G-蛋白偶联受体的自体抗体相关。发明人已经就这种相关性实施进一步研究并且已经发现,比先前报道更多的疾病与这类自体抗体相关(数据未显示)。
归因于要求保护的适体对GPCR自体抗体的亲和力,可信的是,与存在这类自体抗体相关的任何疾病有效地用本文中提出和要求保护的适体治疗。因此,根据本发明的一个优选实施方案,自体免疫疾病是以下之一:心肌病、扩张型心肌病(DCM)、缺血性心肌病(iCM)、围产期心肌病(PPCM)、特发性心肌病、查加斯心肌病、化疗所致心肌病、查加斯巨结肠症、查加斯巨食道症、查加斯神经病、良性前列腺增生、硬皮病、雷诺氏综合症、外周动脉闭塞性疾病(PAOD)、先兆子痫、肾同种异体移植排异、心肌炎、青光眼、高血压、肺动脉高血压、恶性高血压、代谢综合征、脱发、斑秃、偏头痛、帕金森病、癫痫、丛集性头痛、多发性硬化症、抑郁、区域疼痛综合征、不稳定型心绞痛、系统性红斑狼疮(SLE)、精神分裂症、舍格伦综合征、牙周炎、心房颤动、白斑病、溶血性尿毒症综合征、僵人综合征、先天性心脏传导阻滞、I型糖尿病、银屑病、阿尔茨海默病、疲乏、神经性皮炎、肾脏疾病、肌萎缩侧索硬化(ALS)、Leber遗传性视神经病(LHON综合征)、过敏性哮喘、心率失常、难治性高血压、II型糖尿病、血管性痴呆、非查加斯巨结肠症和/或体位性高血压。
尽管本文展示的数据证实了广泛类型疾病与本发明适体的靶分子的相关性,但原则上,发明人已经认识到本文所提到的全部疾病均与针对G-蛋白偶联受体的自体抗体相关并且因此是有前景的可用本发明适体治疗的目标疾病。
根据本发明的一个优选实施方案,自体免疫疾病是以下之一:心肌病、扩张型心肌病(DCM)、缺血性心肌病(iCM)、围产期心肌病(PPCM)、特发性心肌病、查加斯心肌病、化疗所致心肌病、查加斯巨结肠症、查加斯巨食道症、查加斯神经病、良性前列腺增生、硬皮病、雷诺氏综合症、外周动脉闭塞性疾病(PAOD)、先兆子痫、肾同种异体移植排异、心肌炎、青光眼、高血压、肺动脉高血压、恶性高血压、代谢综合征、脱发、斑秃、偏头痛、帕金森病、癫痫、丛集性头痛、多发性硬化症、抑郁、区域疼痛综合征、不稳定型心绞痛、系统性红斑狼疮(SLE)、精神分裂症、舍格伦综合征、牙周炎、心房颤动、白斑病、溶血性尿毒症综合征、僵人综合征和/或先天性心脏传导阻滞,更优选地,自体免疫疾病是扩张型心肌病(DCM)。
根据本发明的另一个实施方案,自体免疫疾病是心脏病、神经系统疾病、血管疾病、结缔组织病(CTD)、皮肤病或查加斯病,自体免疫疾病尤其是心脏病、神经性疾病或血管疾病。根据一个具体实施方案,自体免疫疾病是心脏病。
处于本发明含义范围内的心脏病可以是心肌病、扩张型心肌病、缺血性心肌病、特发性心肌病、围产期心肌病、查加斯心肌病、心房颤动、急性和慢性心肌炎、先天性心脏传导阻滞、不稳定型心绞痛、化疗所致心肌病或肥厚型心肌病。
本发明含义范围内的神经性疾病可以是偏头痛、抑郁、癫痫、帕金森病、多发性硬化症、丛集性头痛、精神分裂症、僵人综合征、查加斯神经病或复合性区域性疼痛综合征。
本发明含义范围内的血管疾病可以是高血压、肺动脉高血压、外周动脉闭塞性疾病、恶性高血压或雷诺氏综合症。
本发明含义范围内的结缔组织病(CTD)可以是硬皮病、系统性红斑狼疮SLE或舍格伦综合征。本发明含义范围内的皮肤病可以是斑秃、脱发或白斑病。本发明含义范围内的查加斯病可以是查加斯巨结肠症或查加斯巨食道症。
在一个备选实施方案中,自体免疫疾病是以下之一:青光眼、代谢综合征、牙周炎、溶血性尿毒症综合征、先兆子痫、良性前列腺增生或肾同种异体移植排异。
根据另一个备选实施方案,自体免疫疾病是以下之一:扩张型心肌病、特发性心肌病、急性和慢性心肌炎、查加斯心肌病、围产期心肌病、肺动脉高血压、高血压、先兆子痫、恶性高血压、不稳定型心绞痛、缺血性心肌病、偏头痛、抑郁、多发性硬化症、帕金森病或癫痫、尤其以下之一:扩张型心肌病、特发性心肌病、急性和慢性心肌炎、查加斯心肌病、围产期心肌病、肺动脉高血压或高血压、任选地以下之一:扩张型心肌病、特发性心肌病或急性和慢性心肌炎。
特别地,本发明的适体能够相互作用于自体抗体、优选地对G-蛋白偶联受体特异的自体抗体、优选地对以下任一种人G-蛋白偶联受体特异的自体抗体:肾上腺素能α-1受体、肾上腺素能β-1受体、肾上腺素能β-2受体、内皮素1ETA受体、毒蕈碱M2受体、血管紧张素II AT1受体、PAR受体、MAS-受体、5HT4-受体和/或M3-受体,并且更优选地能够抑制这些自体抗体与其靶蛋白的特异性相互作用。
本文中,也可以将肾上腺素能β1-受体表示为β1-受体、β1-AR或β1-R.另外,也可以将肾上腺素能β2-受体表示为β2-受体、β2-AR或β2-R。另外,血管紧张素II受体I型可以命名为血管紧张素II AT1受体、血管紧张素AT1受体或AT1-R。可以将内皮素1ETA受体表示为ETA-R或ETA-1-R并且也可以将肾上腺素能α1-受体表示为α1-受体、α1-AR或α1-R。蛋白酶-激活受体可以命名为PAR-R。血管紧张素-II代谢物血管紧张素(1-7)结合受体可以在本文中命名为mas相关的G-蛋白偶联受体A、MAS受体、MAS-R或MAS1。5-羟色胺受体4可以缩写成5HT4-R,而可以将毒蕈碱受体表示为MX-R,其中x表示毒蕈碱能受体的亚型。
根据本发明的一个实施方案,毒蕈碱M受体意在涵盖M1、M2、M3和/或M4受体。根据另一个实施方案,毒蕈碱M1、M2、M3和/或M4-受体可用作具体例子,其中给出M3受体作为自体抗体可以针对的G-蛋白偶联受体的一个例子。
如下文对具有SEQ ID No:12的序列的适体示例性显示,本发明的适体可以用来中和全系列对G-蛋白偶联受体特异的自体抗体。在本文的实施例12至20中,显示这种适体特异性中和多种自体抗体,所述自体抗体取自患有与这些自体抗体相关的自体免疫疾病的患者(参见图13至图21)。因此,可信的是,本发明的适体能够中和针对G-蛋白偶联受体的自体抗体并且因此有效治疗其中患有这种疾病的患者中存在这类自体抗体的疾病。
通过抑制针对G-蛋白偶联受体的自体抗体的病理学行为,本发明适体的中和作用削弱或甚至消除相应G-蛋白偶联受体的永久性激活。作为结果,不需要复杂地移除这些抗体。因此,本发明提供一组化合物,所述化合物适用于治疗和/或诊断与存在识别G-蛋白偶联受体的自体抗体相关的自体免疫疾病,即与存在对肾上腺素能α-1受体、肾上腺素能β-1受体、肾上腺素能β-2受体、内皮素1ETA受体、毒蕈碱M2受体、血管紧张素II AT1受体、PAR受体、MAS-受体、5HT4-受体和/或M3-受体特异的自体抗体相关的自体免疫疾病。
另外在固定化后,本发明的适体能够抓住或固定上文所述的自体抗体。因此,提供一个平台,所述平台建立用于从患者血清清除自体抗体的血液成分分离技术(apheresis technology)并且开发用于测量自体抗体的分析工具。后者可以特别用于诊断自体免疫疾病。
根据一个优选实施方案,本发明的适体用于诊断如本文定义的自体免疫疾病。特别地,适体用于体外检测对G-蛋白偶联受体、优选地对如下的人G-蛋白偶联受体:肾上腺素能α-1受体、肾上腺素能β-1受体、肾上腺素能β-2受体、内皮素1ETA受体、毒蕈碱M受体、血管紧张素II AT1受体、PAR受体、MAS-受体、5HT4-受体和/或M3受体特异的抗体。根据另一个优选实施方案,本发明的适体用于体内诊断如本文定义的自体免疫疾病。根据更优选的实施方案,待检测的抗体是自体抗体。
如本文所用,“自体抗体”意指响应于患者自身组织的抗原性组分而形成并对其反应的抗体。这种抗体可以攻击其中形成它的生物的细胞、组织或天然蛋白并且通常隶属于所述生物中的致病过程。
根据一个优选实施方案,对G-蛋白偶联受体特异的抗体存在或来源于于体液,优选地人体的流体、更优选地人血、血浆、血清、尿、粪便、滑液、间质液、淋巴液、唾液、脊髓液和/或泪液。更优选地,身体流体取患有或疑似患有自体免疫疾病的个体,优选地所述自体免疫疾病为与患者血清中存在对G蛋白偶联受体特异的自体抗体相关的自体免疫疾病,更优选地所述自体免疫疾病为与患者血清中存在对肾上腺素能α-1受体、肾上腺素能β-1受体、肾上腺素能β-2受体、内皮素1ETA受体、毒蕈碱M受体、血管紧张素II AT1受体、PAR受体、MAS-受体、5HT4-受体和/或M3受体特异的自体抗体相关的自体免疫疾病。
当用于治疗或诊断自体免疫疾病时,本发明的适体不必然需要施用至个体或患者。也可以通过将本发明适体用于从身体或从体液消除抗体(例如自体抗体),实现治疗性或诊断性作用。
这种消除可以包括在这样的设定下应用本发明的适体,其中本发明的适体仅与体液离体接触,例如在免疫吸附和/或血液成分分离术期间,从而本发明的适体不进入待治疗个体或患者的身体。因此,本发明还涉及包含本发明适体的血液成分分离柱。
血液成分分离术是一项医学技术,其中供体或患者的血液穿过这样的装置,所述装置分离出一种特定成分并将剩余部分返回供体或患者的循环。因此,通过在封闭回路中连接患者血浆、患者身体和实现治疗作用的装置(即与柱结合的适体),实施血液成分分离术。本发明的适体可以用作在血液成分分离期间的选择性组分。选择性组分负责特异性分离出所需的特定成分,即样品或血液中存在的由本发明适体特异性靶向的抗体或自体抗体。
优选地,本发明的适体用于治疗和/或诊断自体免疫疾病,其中自体免疫疾病是心肌病、扩张型心肌病(DCM)、缺血性心肌病(iCM)、围产期心肌病(PPCM)、特发性心肌病、查加斯心肌病、化疗所致心肌病、查加斯巨结肠症、查加斯巨食道症、查加斯神经病、良性前列腺增生、硬皮病、雷诺氏综合症、外周动脉闭塞性疾病(PAOD)、先兆子痫、肾同种异体移植排异、心肌炎、青光眼、高血压、肺动脉高血压、恶性高血压、代谢综合征、脱发、斑秃、偏头痛、帕金森病、癫痫、丛集性头痛、多发性硬化症、抑郁、区域疼痛综合征、不稳定型心绞痛、系统性红斑狼疮(SLE)、精神分裂症、舍格伦综合征、牙周炎、心房颤动、白斑病、溶血性尿毒症综合征、僵人综合征和/或先天性心脏传导阻滞。进一步优选地,使用本发明的适体用作血液或其成分的治疗性血液成分分离的选择性组分,所述血液或其成分源自如本文进一步定义的患有自体免疫疾病的患者。
本发明还涉及与固相支持物偶联的本发明适体。技术人员非常清楚可以用来产生与固相支持物偶联的这类适体的技术和材料。在优选的实施方案中,固相支持物包括在医学测定法、生物化学测定法或生物测定法中可用的固态材料。
所述固态材料包括通常在医学测定法、生物化学测定法或生物测定法中用作支持物的聚合物。特别地,本发明的适体可以与固相支持物偶联,允许所得产物用于制造适合用于血液成分分离术的柱、优选地适合用于血液成分分离术中从液态样品(优选地从体液)移除对G-蛋白偶联受体特异的抗体的柱。
制造或大量生产本发明的适体是本领域熟知的并且代表仅例行的活动。
本发明还涉及一种药物组合物,所述药物组合物包含本发明的至少一种适体和任选地至少一种药学上可接受的赋形剂。本发明还涉及一种药物组合物,所述药物组合物包含本发明的适体或本发明不同适体的混合物和药学上可接受的赋形剂,例如合适的载体或稀释剂。
优选地,本发明的适体构成药物组合物的有效成分和/或以有效量存在。术语“有效量“指对疾病或病理状况具有预防、诊断或治疗相关效果的本发明适体的量。预防性效果防止疾病的暴发。治疗相关效果缓解疾病的一种或多种症状到某个程度或使得与疾病或病理状况相关或作为其原因的一个或多个生理参数或生物化学参数部分地或完全恢复至正常。
施用本发明适体的相应量足够地高,以实现所需的预防性、诊断或治疗效果。技术人员将理解,向任何特定哺乳动物施用的具体剂量水平、频率和时间段将取决于多种因素,包括所用的具体组分的活性、年龄、体重、总体健康、性别、膳食、施用时间、施用途径、药物联用和特定疗法的严重性(severity)。使用熟知的手段和方法,精确数量可以由本领域技术人员作为例行实验确定。
根据本发明药物组合物的一个实施方案,至少20%、优选地至少50%、更优选地至少75%、最优选的至少95%的总适体含量由本发明的适体构成。
当用于治疗时,药物组合物将通常作为与一种或多种药学上可接受的赋形剂联合的制剂施用。术语“赋形剂“在本文中用来描述除本发明适体之外的任何成分。赋形剂的选择将很大程度取决于特定的施用模式。赋形剂可以是适合的载体和/或稀释剂。
本发明的药物组合物可以口服施用。口服施用可以涉及吞咽,从而组合物进入胃肠道,或者可以使用颊部或舌下施用,组合物籍此从口腔直接进入血流。
适于口服施用的制剂包括:固态制剂如片剂;包衣片剂、含有颗粒物、液体或粉末的胶囊剂;锭剂(包括充填液体的锭剂);和咀嚼剂;多颗粒物和纳米颗粒物;凝胶剂;固溶体;脂质体;薄膜剂、珠剂(ovules)、喷雾剂和液态制剂。
液态制剂包括混悬剂、溶液剂、糖浆剂和酏剂。这类制剂可以作为软胶囊剂或硬胶囊剂中的填料使用并且一般包含载体例如,水、乙醇、聚乙二醇、丙二醇、甲基纤维素或合适的油以及一种或多种乳化剂和/或助悬剂。也可以通过复溶(例如,从小袋复溶)固体,配制液态制剂。
对于片剂剂型,取决于剂量,本发明的适体可以构成剂型的0.1重量%至80重量%,更一般地构成剂型的5重量%至60重量%。除本发明的适体之外还,片剂通常含有崩解剂。
崩解剂的例子包括羧基乙酸淀粉钠、羧甲基纤维素钠、羧甲基纤维素钙、交联羧甲基纤维素钠、交联聚维酮、聚乙烯吡咯烷酮、甲基纤维素、微晶纤维素、低级烷基取代的羟丙基纤维素、淀粉、预胶化淀粉和藻酸钠。
通常,崩解剂将占据剂型的1重量%至25重量%、优选地5重量%至20重量%。
片剂可以包含额外的赋形剂,例如粘结剂、表面活性物质、润滑剂和/或其他可能成分,例如抗氧化物质、色料、增味剂、防腐剂和/或掩味剂。
片剂掺合料可以直接压制或由辊压制以形成片剂。片剂掺合料或掺合料的部分可以在造片之前可选地湿法制粒、干法制粒或熔融制粒、熔融凝固或挤出。最终的制剂可以包含一个或多个层并且可以经包衣或未包衣;它可以甚至包囊化。
可以将口服施用的固态制剂配制成速释和/或受调节释放。受调节释放制剂包括延迟释放、持久释放、脉冲释放、受控释放、定向释放和编程释放。
本发明的药物组合物也可以直接施用入血流、肌肉或内脏中。用于肠胃外施用的合适手段包括静脉内、动脉内、腹膜内、鞘内、心室内、尿道内、胸骨内、颅内、肌内和皮下。肠胃外施用的合适装置包括针头(包括微量针头)注射器、无针头注射器和输注技术。
肠胃外制剂一般是水溶液剂,所述水溶液剂可以含有赋形剂如盐、碳水化合物和缓冲剂(优选地,至3至9的pH),但是,对于一些应用,它们可以更适当地配制为无菌非水溶液或配制为与合适溶媒如无菌无热原水一起待使用的干燥形式。
无菌条件下肠胃外制剂的制备(例如通过冻干法)可以使用本领域技术人员熟知的标准药学技术轻易地完成。
可以通过使用适宜的制剂技术,如掺入溶解度增强剂,增加用于配制肠胃外溶液剂的本发明药物组合物的溶解度。
可以将肠胃外施用的制剂配制成速释和/或受调节释放。受调节释放制剂包括延迟释放、持久释放、脉冲释放、受控释放、定向释放和编程释放。因此,可以将本发明的化合物配制为固体剂、半固体剂或触变液体剂作为植入贮库施用,其中所述植入贮库提供活性化合物的受调节释放。这类制剂的例子包括涂药支架和PGLA聚(dl-乳酸-共乙醇酸)(PGLA)微球体。
本发明的药物组合物也可以外用地施用至皮肤或粘膜,即,皮肤或经皮施用。用于该目的的常见制剂包括凝胶剂、水凝胶剂、露剂(lotion)、溶液剂、乳膏剂、油膏剂、撒粉散剂、敷剂(dressing)、泡沫剂、膜剂、皮肤贴剂、薄片剂(wafer)、植入剂、海绵剂、纤维剂、绷带剂和微乳剂。
也可以使用脂质体。常见的载体包括醇、水、矿物油、石蜡油、白凡士林、丙三醇、聚乙二醇和丙二醇。可以掺入渗透促进剂。外用施用法的其他手段包括借助电穿孔法、离子导入法、声透入法(phonophoresis)、超声导入法(sonophoresis)和微量针注射或无针注射(例如,Powderject(TM)、Bioject(TM)等)输送。可以将外用施用的制剂配制成速释和/或受调节释放。受调节释放制剂包括延迟释放、持久释放、脉冲释放、受控释放、定向释放和编程释放。
为了施用至人类患者,本发明适体和/或本发明药物组合物的每日总剂量一般处于0.001mg至5000mg范围内,当然,这取决于施用模式。例如,静脉内每日剂量可以仅需要0.001mg至40mg。每日总剂量可以按单一或或分开的剂量施用并且根据医师的决定,可以落在本文给出的常见范围外。
这些剂量基于具有约75kg至80kg体重的平均人类受试者。医师将轻易能够确定其体重落于该范围之外的受试者(如婴儿和老年人)的剂量。
本发明还涵盖一种试剂盒,所述试剂盒包含本发明的适体、药物组合物、容器和任选地书面使用说明书和/或连同施用手段。
对于治疗和/或诊断疾病,无论施用途径是什么,本发明的适体均每个治疗周期以不多于20mg/kg体重、优选地不多于10mg/kg体重、更优选地选自范围1μg/kg至20mg/kg体重,最优选地选自0.01mg/kg至10mg/kg体重范围的每日剂量施用。
在一个实施方案中,本发明涉及用于体外检测和/或表征对G-蛋白偶联受体、优选地以下G-蛋白偶联受体:肾上腺素能α-1受体、肾上腺素能β-1受体、肾上腺素能β-2受体、内皮素1ETA受体、毒蕈碱M2受体、血管紧张素II AT1受体、PAR受体、MAS-受体、5HT4-受体和/或M3-受体特异的抗体(例如自体抗体)中的本发明适体。因此,本发明的一个优选的实施方案涉及如权利要求1至8中任一项所限定的适体的用途,用于体外检测对G-蛋白偶联受体、优选地对如下的人G-蛋白偶联受体:肾上腺素能α-1受体、肾上腺素能β-1受体、肾上腺素能β-2受体、内皮素1ETA受体、毒蕈碱M受体、血管紧张素II AT1受体、PAR受体、MAS-受体、5HT4-受体和/或M3受体特异的抗体。
这种用途可以包括在大鼠心肌细胞搏动频率测定法中在有效量的本发明适体存在和不存在下检验样品。取决于样品和本发明适体对搏动频率的影响,技术人员可以就相应抗体的存在情况得出结论。也可以获得关于样品中这类抗体的总量或相对量的数据以及这类抗体的其他特性的数据。
所谓大鼠心肌细胞搏动频率测定法是一项充分建立的测定法,其检测并表征对多种人G-蛋白偶联受体例如人肾上腺素能α-1受体、肾上腺素能β-1受体、肾上腺素能β-2受体、内皮素1ETA受体、毒蕈碱M2受体、血管紧张素II AT1受体、PAR受体、MAS-受体、5HT4-受体和/或M3-受体特异的抗体,例如源自患者的自体抗体。
该测定法在以下文献中详述:Wallukat等人,(1987)Effects of the serum gamma globulin fraction of patients with allergic asthma and dilated cardiomyopathy on chromotropic beta adrenoceptor function in cultured neonatal rat heart myocytes,Biomed.Biochim.Acta 46,634-639;Wallukat等人,(1988)Cultivated cardiac muscle cells-a functional test system for the detection of autoantibodies against the beta adrenergic receptor,Acta Histochem.Suppl.35,145-149;和Wallukat等人,(2010)Distinct patterns of autoantibodies against G-protein coupled receptors in Chagas'cardiomyopathy and megacolon.Their potential impact for early risk assessment in asymptomatic Chagas'patients,J.Am.Col.Cardiol.55,463-468。因此,技术人员是非常清楚这个测定法的性质并知道如何应用它。
为了检测和/或表征这类抗体,本发明的适体可以在溶液中或以固定形式使用。
本发明的适体可以用于直接或间接检测和/或表征所述抗体。
根据本发明的另一个方面,提供一种用于制备适体寡核苷酸的方法,所述方法包括步骤:确定用作适体序列的核苷酸序列,包括应用以下的产生规则集合P:
条件为
a.)Q是自然数集
b.)F是如下定义10F:={X∈Q|(X>1)}的自然数子集
F:={X∈Q|(X>1)}
c.)使用F,定义:
d.)U是如下定义的非终结符集
U={S,M,N,D,E,Y,H,R,Z,L,BX,CX,K,V}
对于BX和CX,见c)
e.)W是如下定义的非终结符集
W={A,C,G,T,GX}
GX指可以根据b.)和c.)导出的全部终结符(5)
f.)S∈U是起始符号
其中“A”意指腺嘌呤核苷酸,“C”意指胞嘧啶核苷酸,“G”意指鸟嘌呤核苷酸并且如果核苷酸序列是DNA序列,则“T”意指胸腺嘧啶核苷酸,并且如果核苷酸序列是RNA序列,则“T”意指尿嘧啶核苷酸,以及生产具有第一步骤中获得的核苷酸序列的适体寡核苷酸。
根据一个优选实施方案,确定用作适体序列的核苷酸序列的步骤包括应用以下共有序列
Si-(GGG-S-GGG-S)n-(GGG-S-GGG)k-Sm (1)
其中n>1;
i、m、k=0、1;
S={A、C、G、T}+或{A、C、G}+或{A、C、T}+或{A、G、T}+或{C、G、T}+或{A、C}+或{A、G}+或{A、T}+或{C、G}+或{C、T}+或{G、T}+或{A}+或{C}+或{T}+,其中{}+指给定字母集的正克林闭包(Kleene Closure)。
术语正克林闭包描述了有限非空符号(词汇或字母)集的成员的并置方式。作为这个进程的结果,将产生新词(符号串)。每个词具有大于零的长度。
根据本发明的另一个优选实施方案,提供一种包含满足式(1)共有序列(consensus sequences)的核苷酸序列的适体用于治疗和/或诊断与针对G-蛋白偶联受体的自体抗体相关的自体免疫疾病,其中“A”意指腺嘌呤核苷酸,“C”意指胞嘧啶核苷酸,“G”意指鸟嘌呤核苷酸并且如果核苷酸序列是DNA序列,则“T”意指胸腺嘧啶核苷酸,并且如果核苷酸序列是RNA序列,则“T”意指尿嘧啶核苷酸,其中适体不包含核苷酸序列CGCCTAGGTTGGGTAGGGTGGTGGCG(SEQ ID No:24)。
根据又一个优选的实施方案,确定用作适体序列的核苷酸序列的步骤包括应用以下共有序列
Si-(GG-S-GG-S)n-(GG-S-GG)k-Sm (2)
其中n>1;
i、m、k=0、1;
S={A、C、G、T}+或{A、C、G}+或{A、C、T}+或{A、G、T}+或{C、G、T}+或{A、C}+或{A、G}+或{A、T}+或{C、G}+或{C、T}+或{G、T}+或{A}+或{C}+或{T}+,
其中{}+指给定字母集的正克林闭包。
根据本发明的另一个优选实施方案,提供一种包含满足式(2)共有序列的核苷酸序列的适体用于治疗和/或诊断与针对G-蛋白偶联受体的自体抗体相关的自体免疫疾病,其中“A”意指腺嘌呤核苷酸,“C”意指胞嘧啶核苷酸,“G”意指鸟嘌呤核苷酸并且如果核苷酸序列是DNA序列,则“T”意指胸腺嘧啶核苷酸,并且如果核苷酸序列是RNA序列,则“T”意指尿嘧啶核苷酸,其中适体不包含核苷酸序列GGTTGGTGTGGTTGG(SEQ ID No:22)、GGTTGGTGTGGT(SEQ ID NO:23)或CGCCTAGGTTGGGTAGGGTGGTGGCG(SEQ ID No:24)。
根据另一个优选实施方案,确定用作适体序列的核苷酸序列的步骤包括应用以下共有序列
Si-P-(LM)j-Ek; (3)
其中i,k=0,1;
j>=0;
P=(Gm-(X)-Gm-(Y)-Gm-(Z)-Gm);
M=(Gm-(X)-Gm-(Y)-Gm-(Z)-Gm);
m>1;
S、L、E、X、Y、Z={A、C、G、T}+或{A、C、G}+或{A、C、T}+或{A、G、T}+或{C、G、T}+或{A、C}+或{A、G}+或{A、T}+或{C、G}+或{C、T}+或{G、T}+或{A}+或{C}+或{T}+,其中{}+指给定字母集的正克林闭包。
根据本发明的另一个优选实施方案,提供一种包含满足式(3)共有序列的核苷酸序列的适体用于治疗和/或诊断与针对G-蛋白偶联受体的自体抗体相关的自体免疫疾病,其中“A”意指腺嘌呤核苷酸,“C”意指胞嘧啶核苷酸,“G”意指鸟嘌呤核苷酸并且如果核苷酸序列是DNA序列,则“T”意指胸腺嘧啶核苷酸,并且如果核苷酸序列是RNA序列,则“T”意指尿嘧啶核苷酸,其中适体不包含核苷酸序列GGTTGGTGTGGTTGG(SEQ ID No:22)、GGTTGGTGTGGT(SEQ ID NO:23)或CGCCTAGGTTGGGTAGGGTGGTGGCG(SEQ ID No:24)。
根据另一个优选实施方案,确定用作适体序列的核苷酸序列的步骤包括应用以下共有序列
Si-P-Ej; (4)
其中i,j=0,1;
P=(Gm-(X)-Gm-(Y)-Gm);
m>1;
X、Y、S、E={A、C、G、T}+或{A、C、G}+或{A、C、T}+或{A、G、T}+或{C、G、T}+或{A、C}+或{A、G}+或{A、T}+或{C、G}+或{C、T}+或{G、T}+或{A}+或{C}+或{T}+,其中{}+指给定字母集的正克林闭包。
根据本发明的另一个优选实施方案,提供一种包含满足式(4)共有序列的核苷酸序列的适体用于治疗和/或诊断与针对G-蛋白偶联受体的自体抗体相关的自体免疫疾病,其中“A”意指腺嘌呤核苷酸,“C”意指胞嘧啶核苷酸,“G”意指鸟嘌呤核苷酸并且如果核苷酸序列是DNA序列,则“T”意指胸腺嘧啶核苷酸,并且如果核苷酸序列是RNA序列,则“T”意指尿嘧啶核苷酸,其中适体不包含核苷酸序列GGTTGGTGTGGTTGG(SEQ ID No:22)、GGTTGGTGTGGT(SEQ ID NO:23)或CGCCTAGGTTGGGTAGGGTGGTGGCG(SEQ ID No:24)。
使用本发明的方法,可以确定具有下述结构样式的核苷酸序列,所述结构样式对有效作为治疗适体和/或诊断适体用于治疗和/或诊断与针对G-蛋白偶联受体的自体抗体相关的自体免疫疾病是必要和充分的。
可以通过使用本发明方法,产生本发明适体的序列。在下文中,示例性显示本发明SEQ ID No.:12的序列的导出:
序列#12的导出:(5'-GGTGGTGGTGGTTGTGGTGGTGGTGG-3')
X=2
S→M
→NRM
→MRM
→C2LC2RM
→C2LC2RC2LC2
→B2LB2LC2RC2LC2
→B2LB2LB2LB2RC2LC2
→B2LB2LB2LB2RB2LB2LC2
→B2LB2LB2LB2RB2LB2LB2LB2
→GGLB2LB2LB2RB2LB2LB2LB2
→GGLGGLB2LB2RB2LB2LB2LB2
→GGLGGLGGLB2RB2LB2LB2LB2
→GGLGGLGGLGGRB2LB2LB2LB2
→GGLGGLGGLGGRGGLB2LB2LB2
→GGLGGLGGLGGRGGLGGLB2LB2
→GGLGGLGGLGGRGGLGGLGGLB2
→GGLGGLGGLGGRGGLGGLGGLGG
→GGZGGLGGLGGRGGLGGLGGLGG
→GGTGGLGGLGGRGGLGGLGGLGG
→GGTGGZGGLGGRGGLGGLGGLGG
→GGTGGTGGLGGRGGLGGLGGLGG
→GGTGGTGGZGGRGGLGGLGGLGG
→GGTGGTGGTGGRGGLGGLGGLGG
→GGTGGTGGTGGLGGLGGLGGLGG
→GGTGGTGGTGGZLGGLGGLGGLGG
→GGTGGTGGTGGZZGGLGGLGGLGG
→GGTGGTGGTGGTZGGLGGLGGLGG
→GGTGGTGGTGGTTGGLGGLGGLGG
→GGTGGTGGTGGTTGGZGGLGGLGG
→GGTGGTGGTGGTTGGTGGLGGLGG
→GGTGGTGGTGGTTGGTGGZGGLGG
→GGTGGTGGTGGTTGGTGGTGGLGG
→GGTGGTGGTGGTTGGTGGTGGZGG
→GGTGGTGGTGGTTGGTGGTGGTGGSEQ ID NO:12
使用移位-归约解析器,SEQ ID No.:12的序列也可以在应用下表中列出的语法规则后,在随机化序列的汇集物中作为有效序列被识别。由于输入序列可以归约至起始符号S,序列是所定义语法的有效句子。
下文显示导出要求保护的本发明适体序列SEQ ID No.:3、10和15的其他示例:
序列#3的导出:(5'-GGTTGGGGTGGGTGGGGTGGGTGGG-3')
X=3
S→M
→RM
→LM
→LC3LC3
→ZLC3LC3
→ZZLC3LC3
→ZZZLC3LC3
→ZZZZLC3LC3
→ZZZZZLC3LC3
→ZZZZZZLC3LC3
→ZZZZZZZLC3LC3
→ZZZZZZZZLC3LC3
→ZZZZZZZZZC3LC3
→GZZZZZZZZC3LC3
→GGZZZZZZZC3LC3
→GGTZZZZZZC3LC3
→GGTTZZZZZC3LC3
→GGTTGZZZZC3LC3
→GGTTGGZZZC3LC3
→GGTTGGGZZC3LC3
→GGTTGGGGZC3LC3
→GGTTGGGGTB3LB3LC3
→GGTTGGGGTB3LB3LB3LB3
→GGTTGGGGTGGGLB3LB3LB3
→GGTTGGGGTGGGZB3LB3LB3
→GGTTGGGGTGGGTB3LB3LB3
→GGTTGGGGTGGGTGGGLB3LB3
→GGTTGGGGTGGGTGGGZLB3LB3
→GGTTGGGGTGGGTGGGZZB3LB3
→GGTTGGGGTGGGTGGGGZB3LB3
→GGTTGGGGTGGGTGGGGTB3LB3
→GGTTGGGGTGGGTGGGGTGGGLB3
→GGTTGGGGTGGGTGGGGTGGGZB3
→GGTTGGGGTGGGTGGGGTGGGTB3
→GGTTGGGGTGGGTGGGGTGGGTGGGSEQ ID NO:3
序列#10的导出:(5'-GGTGGTGGTGG-3')
X=2
S→M
→C2LC2
→B2LB2LC2
→GGLB2LC2
→GGZB2LC2
→GGTB2LC2
→GGTGGLC2
→GGTGGZC2
→GGTGGTC2
→GGTGGTB2LB2
→GGTGGTGGLB2
→GGTGGTGGZB2
→GGTGGTGGTB2
→GGTGGTGGTGGSEQ ID NO:10
序列#15的导出:
(5'-TTTGGTGGTGGTGGTTGTGGTGGTGGTGGTTT-3')
X=2
S→M
→RM
→RNRM
→RNRMR
→RMRMR
→LMRMR
→ZLMRMR
→ZZLMRMR
→ZZZMRMR
→TZZMRMR
→TTZMRMR
→TTTMRMR
→TTTC2LC2RMR
→TTTB2LB2LC2RMR
→TTTGGLB2LC2RMR
→TTTGGLB2LC2RMR
→TTTGGZB2LC2RMR
→TTTGGTB2LC2RMR
→TTTGGTGGLC2RMR
→TTTGGTGGZC2RMR
→TTTGGTGGTC2RMR
→TTTGGTGGTB2LB2RMR
→TTTGGTGGTGGLB2RMR
→TTTGGTGGTGGZB2RMR
→TTTGGTGGTGGTB2RMR
→TTTGGTGGTGGTGGRMR
→TTTGGTGGTGGTGGLMR
→TTTGGTGGTGGTGGZLMR
→TTTGGTGGTGGTGGZZLMR
→TTTGGTGGTGGTGGZZZLMR
→TTTGGTGGTGGTGGZZZZMR
→TTTGGTGGTGGTGGTZZZMR
→TTTGGTGGTGGTGGTTZZMR
→TTTGGTGGTGGTGGTTGZMR
→TTTGGTGGTGGTGGTTGTMR
→TTTGGTGGTGGTGGTTGTC2LC2R
→TTTGGTGGTGGTGGTTGTB2LB2LC2R
→TTTGGTGGTGGTGGTTGTGGLB2LC2R
→TTTGGTGGTGGTGGTTGTGGZB2LC2R
→TTTGGTGGTGGTGGTTGTGGTB2LC2R
→TTTGGTGGTGGTGGTTGTGGTGGLC2R
→TTTGGTGGTGGTGGTTGTGGTGGZC2R
→TTTGGTGGTGGTGGTTGTGGTGGTC2R
→TTTGGTGGTGGTGGTTGTGGTGGTB2LB2R
→TTTGGTGGTGGTGGTTGTGGTGGTGGLB2R
→TTTGGTGGTGGTGGTTGTGGTGGTGGZB2R
→TTTGGTGGTGGTGGTTGTGGTGGTGGTB2R
→TTTGGTGGTGGTGGTTGTGGTGGTGGTGGR
→TTTGGTGGTGGTGGTTGTGGTGGTGGTGGL
→TTTGGTGGTGGTGGTTGTGGTGGTGGTGGZL
→TTTGGTGGTGGTGGTTGTGGTGGTGGTGGZZL
→TTTGGTGGTGGTGGTTGTGGTGGTGGTGGZZZ
→TTTGGTGGTGGTGGTTGTGGTGGTGGTGGTZZ
→TTTGGTGGTGGTGGTTGTGGTGGTGGTGGTTZ
→TTTGGTGGTGGTGGTTGTGGTGGTGGTGGTTTSEQ ID NO:15
如本文所述的本发明全部实施方案均视为以任何组合方式可组合,除非技术人员认为这种组合不产生任何技术意义。
实施例
估计自体抗体活性(针对G-蛋白偶联受体的自体抗体,AAB)的功能测定法
能够鉴定并定量针对G-蛋白偶联受体的自体抗体(AAB)的功能测定法用于评估本发明适体的AAB中和能力。
这种功能测定法利用自发搏动的大鼠心肌细胞,与等分试样的纯化IgG级分一起添加时,所述细胞能够对患者AAB做出反应,伴随它们的搏动频率变化–变时性反应。变时性反应是由刺激性AAB(如靶向肾上腺素能β1-、β2-或-α1受体、毒蕈碱M2受体和内皮素受体A型(ETA-受体)的那些)引起的正变时性或负变时性的总和并且表述为相对于基础搏动频率的差异,Δ搏动/时间。
抑制性AAB如过敏性哮喘患者中存在的β2-肾上腺素能受体AAB拮抗由β2-肾上腺素能激动剂引起的正变时作用。
为了就其对变时性反应(正变时性或负变时性)的贡献区分AAB种类,在特定拮抗剂如针对β2-AAB的ICI-118.551、针对M2-AAB的阿托品、针对β1/β2-AAB的普萘洛尔、针对ETA-受体的BQ610或BQ123、针对α1-肾上腺素能受体的哌唑嗪或乌拉地尔和针对AT1-受体的厄贝沙坦或氯沙坦存在下实施分析。剩余活性变化由AAB引起,遭特异性阻断的那些除外。
另外,使用与可以中和AAB活性的受体的胞外结构相对应的G-蛋白偶联受体的肽,更详细地分析AAB的特异性。以相似方式,对适体检验其中和AAB的能力。
这种功能测定法可以检测并定量人血清全部AAB和靶向细胞表面上受体的其他分子,所述受体的序列是人受体的同源物(AAB靶向作用的前提)并且所述受体与调节细胞搏动频率(收缩性、变时性)的蛋白质级联如G-蛋白系统关联。
新生心肌细胞的制备
为了制备新生心肌细胞,将1至3日龄大鼠的心脏在无菌条件下取出并转移至含有青霉素/链霉素的磷酸盐缓冲盐水溶液(PBS)。在分离心室组织后,将它剖分成小片并用10ml PBS洗涤两次。此后,将剖分的心室小片是悬浮于30ml PBS/0.2%胰蛋白酶中并且在37℃温育15分钟。添加5ml冰冷的热灭活新生牛血清,终止胰蛋白酶消化过程。将所产生的悬液离心(130x g,15分钟)并将沉淀物转移至20ml SM20-I培养基。计数细胞,同时用相同体积的台盼蓝溶液稀释所产生悬液的等分试样。
将悬浮于2.0ml用湿润空气平衡并补充有10%热灭活新生牛血清、2μM氟脱氧尿苷的含有葡萄糖的SM20-I培养基中的2.4x106个细胞转移至12.5-cm2Falcon瓶以作为单层在37℃培养4天。在第1天和此后每两天更新培养基。实验在这些瓶中进行。
AAB测量用血清样品的制备
为了制备适于AAB测量的IgG级分,将1ml血清和660μl饱和硫酸铵溶液混合(终浓度40%硫酸铵),在4℃温育18小时并且按6,000x g离心15分钟。
将沉淀物重悬于750μl PBS中,与750μl饱和硫酸铵溶液(终浓度50%硫酸铵)混合并再次离心。将沉淀物悬浮于700μl PBS中并对100倍体积的PBS透析。所产生的IgG级分含有AAB并将其贮存在-20℃直至测量。
AAB测量原理和适体测试设置
实验在12.5-cm2Falcon瓶中进行。标记用于测量的六个独立细胞簇并且在标记的区域记录基础心肌细胞搏动率。
为了测量AAB活性,将制备的IgG样品以如图中所示的最终稀释度(例如AAB 1:50,其对应于如上文所述制备的40μl IgG溶液在2000μl细胞培养基中)添加至细胞。在添加IgG样品后,将瓶在37℃温育60分钟并且再次计数标记的区带处心肌细胞搏动率并且计算相对于基础搏动率的差异,所述差异对应于阳性变时性AAB活性或阴性变时性AAB活性分别为阳性或阴性。
检验适体效应,将含有AAB的IgG样品与相应的适体(如图中所示的SEQ ID No.)预温育15分钟,之后添加混合物至心肌细胞。在温育时间60分钟(37℃)后,评估搏动频率并且计算相对于基础搏动率的差异。
添加2μl适体对应于最终细胞瓶中添加100nM适体(总体积2000μl)。
实施例1:
通过记录新生心肌细胞搏动率的增加,监测α1-肾上腺素能受体AAB的活性(参见图1,列1:AAB 1:50)。图1的列2-5和列7显示在AAB与100nM相应序列(分别是Seq.ID No:2、3、10、15和20)的适体预温育后,AAB活性降低。通过使用100nM不是本发明适体序列的对照适体序列(Seq.ID No.19:TCGAGAAAAACTCTCCTCTCCTTCCTTCCTCTCCA)获得了图1的列6的结果。
实施例2:
通过记录新生心肌细胞搏动率的增加,监测β1-肾上腺素能受体AAB的活性(参见图2,列1:AAB 1:50)。图2的列2-5和列7显示在AAB与100nM相应序列(分别是Seq.ID No:2、3、10、15和20)的适体预温育后,AAB活性降低。通过使用100nM不是本发明适体序列的对照适体序列(Seq.ID No.19)获得了图2的列6的结果。
实施例3:
通过记录新生心肌细胞搏动率的增加,监测PAR1/PAR2-受体AAB的活性(参见图3,列1:AAB 1:50)。图3的列2-5和列7显示在AAB与100nM相应序列(分别是Seq.ID No:2、3、10、15和20)的适体预温育后,AAB活性降低。通过使用100nM不是本发明适体序列的对照适体序列(Seq.ID No.19)获得了图3的列6的结果。
实施例4:
通过记录新生心肌细胞搏动率的减少,监测内皮素1ETA-受体AAB的活性(参见图3,列1:AAB 1:50)。图3的列2-5和列7显示在AAB与100nM相应序列(分别是Seq.ID No:2、3、10、15和20)的适体预温育后,AAB活性降低。通过使用100nM不是本发明适体序列的对照适体序列(Seq.ID No.19)获得了图4的列6的结果。
实施例5:
通过记录新生心肌细胞搏动率的增加,监测SEQ ID NO:10和SEQ ID NO:20的适体对β1-肾上腺素能受体AAB的浓度依赖性影响(x-轴标签中的数据点“无”对应于:AAB 1:50)。曲线使得适体SEQ ID No.:10和20的适体作用的剂量-依赖关系可视化。使用用SEQ ID NO 19获得的曲线充当对照,因为SEQ ID NO 19不是本发明的适体序列。
实施例6:
在实施例6中,显示本发明适体(分别是列1、2、3、4、6和7中所示的SEQ ID NO 2、3、10、15、20和12)本身对基础心肌细胞搏动率的影响。通过使用不是本发明适体序列的对照适体序列(Seq.ID No.19)获得了图6的列5的结果。
实施例7:
通过记录新生心肌细胞搏动率的增加,监测AAB的活性(参见图7,列1:β1-AAB No.1,1:50;列3:β1-AAB No.2,1:50,列5:β1-AAB No.3,1:50;列7:α1-AAB No.1,1:50;列8:α1-AAB No.2,1:50;列11:β2-AAB No.1,1:50;列13:β2-AAB No.2,1:50)。图7的列2、4、6、8、10、12、14显示在100nM SEQ ID NO:12的适体处AAB活性降低(β1AAB1、β1AAB2、β1AAB 3、α1AAB1、α1AAB 2、β2-AAB 1、β2-AAB 2)。AAB No.1、2和3代表从不同患者材料制备的AAB。
实施例8:
实施例8如上文实施例2中那样实施。通过在不添加适体的时(参见图8,列1:AAB 1:50)和添加本发明适体时记录新生心肌细胞搏动率的增加,监测β1-肾上腺素能受体AAB的活性。用本发明适体处理的全部样品显示在AAB与100nM、400nM或1000nM相应序列(分别是图8中的Seq.ID No 1、4至7至9、11至14和16至18)的适体预温育后,AAB活性降低。
实施例9:
实施例9如上文实施例2中那样实施。通过在不添加适体时(参见图10,列1:AAB 1:50)和添加本发明适体时记录新生心肌细胞搏动率的增加,监测β1-肾上腺素能受体AAB的活性。用本发明适体处理的全部样品显示在AAB与100nM相应序列(分别是图8中的Seq.ID No 25至45;对于这些序列的相互同一性,参见图9)的适体预温育后,AAB活性降低。使用400nM每种适体进一步重复适体序列SEQ ID No.:31至34、44和45的实验(参见下文在中的实施例10)。
实施例10:
实施例10如上文实施例2中那样实施。通过在不添加适体的时(参见图11,列1:AAB 1:50)和添加本发明适体时记录新生心肌细胞搏动率的增加,监测β1-肾上腺素能受体AAB的活性。用本发明适体处理的全部样品显示在AAB与100nM相应序列(分别是Seq.ID No 31至34、44和45)的适体预温育后,AAB活性降低。
实施例11:
实施例11如上文实施例2中那样实施。通过在不添加适体时(参见图12,列1:AAB 1:50)和添加不是本发明的对照序列时记录新生心肌细胞搏动率的增加,监测β1-肾上腺素能受体AAB的活性。用对照序列处理的全部样品显示在AAB与100nM、400nM或1000nM相应序列(分别是Seq.ID No 46:5'-ACCTCTCCTTCCTTCCTCTCCTCTCAAAAAGAGCT-3'、SEQ ID No 47:5'-TCCCATCTATTATTTTTCTTCTAATCATC-3'、SEQ ID No 48:5’-ATCTCATGAACGTAAAGCCATTCAAACG-3’、SEQ ID No 49:5’-ACACTAGTAGCCACACTGAG-3’、SEQ ID No 50:5’-CCTGCCCCCTAAA-3’)的对照预温育后,AAB活性不受影响。
实施例12:
实施例12如上文实施例2中那样实施。通过在不添加适体时(参见图13,列1:AAB 1:50)和添加100nM本发明的SEQ ID No:12的适体时记录新生心肌细胞搏动率的增加,监测从患有抑郁或查加斯心肌病的患者(图13中从左至右)分离的β1-肾上腺素能受体AAB的活性。用本发明适体处理的样品显示与尚未添加适体的对照样品相比,在AAB与100nM SEQ ID No:12预温育后,AAB活性降低。
实施例13:
实施例13如上文实施例12中那样实施,其中在这个实施例中,监测在100nM SEQ ID No.:12的本发明适体不存在或存在下,从遭受青光眼、精神分裂症、查加斯心肌病、溶血性尿毒症综合征(EHEC)或阿尔茨海默病的患者(图14中从左至右)分离的β2-肾上腺素能受体AAB的活性。
实施例14:
实施例14如上文实施例12中那样实施,其中在这个实施例中,监测在100nM SEQ ID No.:12的本发明适体不存在或存在下,从遭受脱发、肾同种异体移植排异或肾病下高血压的患者(图15中从左至右)分离的AT1AAB的活性。
实施例15:
实施例15如上文实施例12中那样实施,其中在这个实施例中,监测在100nM SEQ ID No.:12的本发明适体不存在或存在下,从遭受肺动脉高血压、雷诺氏病、心绞痛或肾病下高血压的患者(图16中从左至右)分离的ETA AAB的活性。
实施例16:
实施例16如上文实施例12中那样实施,其中在这个实施例中,监测在100nM SEQ ID No.:12的本发明适体不存在或存在下,从遭受肺动脉高血压、化疗、多发性硬化症、脱发、斑秃、溶血性尿毒症综合征(EHEC)、舍格伦综合征、阿尔茨海默病、神经性皮炎、I型糖尿病或银屑癣的患者(图17中从左至右)分离的α1AAB的活性。
实施例17:
实施例17如上文实施例12中那样实施,其中在这个实施例中,监测在100nM SEQ ID No.:12的本发明适体不存在或存在下,从遭受雷诺氏病、心绞痛或舍格伦综合征的患者(图18中从左至右)分离的PAR AAB的活性。
实施例18:
实施例18如上文实施例12中那样实施,其中在这个实施例中,监测在100nM SEQ ID No.:12的本发明适体不存在或存在下,从遭受化疗、多发性硬化症或I型糖尿病的患者(图19中从左至右)分离的MAS AAB的活性。
实施例19:
实施例19如上文实施例12中那样实施,其中在这个实施例中,监测在100nM SEQ ID No.:12的本发明适体不存在或存在下,从遭受抑郁、精神分裂症或偏头痛/帕金森病的患者(图20中从左至右)分离的5HT4AAB的活性。
实施例20:
实施例20如上文实施例12中那样实施,其中在这个实施例中,监测在100nM SEQ ID No.:12的本发明适体不存在或存在下,从遭受查加斯心肌病、斑秃、偏头痛/帕金森病或舍格伦综合征的患者(图21中从左至右)分离的M2AAB的活性。
序列表
<110> 柏林制药控股公司
<120> 用于自体抗体相关疾病的适体
<130> 7161-X-29454WO
<150> EP14179715.9
<151> 2014-08-04
<160> 50
<170> BiSSAP 1.3
<210> 1
<211> 14
<212> DNA
<213> 人工序列
<220>
<223> 适体序列
<400> 1
gttgtttggg gtgg 14
<210> 2
<211> 15
<212> DNA
<213> 人工序列
<220>
<223> 适体序列
<400> 2
gttgtttggg gtggt 15
<210> 3
<211> 25
<212> DNA
<213> 人工序列
<220>
<223> 适体序列
<400> 3
ggttggggtg ggtggggtgg gtggg 25
<210> 4
<211> 28
<212> DNA
<213> 人工序列
<220>
<223> 适体序列
<400> 4
tttggtggtg gtggttgtgg tggtggtg 28
<210> 5
<211> 29
<212> DNA
<213> 人工序列
<220>
<223> 适体序列
<400> 5
tttggtggtg gtggttgtgg tggtggtgg 29
<210> 6
<211> 29
<212> DNA
<213> 人工序列
<220>
<223> 适体序列
<400> 6
tttggtggtg gtggttttgg tggtggtgg 29
<210> 7
<211> 29
<212> DNA
<213> 人工序列
<220>
<223> 适体序列
<400> 7
tttggtggtg gtggtggtgg tggtggtgg 29
<210> 8
<211> 29
<212> DNA
<213> 人工序列
<220>
<223> 适体序列
<400> 8
tttggtggtg gtggtttggg tggtggtgg 29
<210> 9
<211> 13
<212> DNA
<213> 人工序列
<220>
<223> 适体序列
<400> 9
tggtggtggt ggt 13
<210> 10
<211> 11
<212> DNA
<213> 人工序列
<220>
<223> 适体序列
<400> 10
ggtggtggtg g 11
<210> 11
<211> 14
<212> DNA
<213> 人工序列
<220>
<223> 适体序列
<400> 11
ggtggttgtg gtgg 14
<210> 12
<211> 26
<212> DNA
<213> 人工序列
<220>
<223> 适体序列
<400> 12
ggtggtggtg gttgtggtgg tggtgg 26
<210> 13
<211> 56
<212> DNA
<213> 人工序列
<220>
<223> 适体序列
<400> 13
ggtggtggtg gttgtggtgg tggtggttgt ggtggtggtg gttgtggtgg tggtgg 56
<210> 14
<211> 32
<212> DNA
<213> 人工序列
<220>
<223> 适体序列
<400> 14
ggtggttgtg gtggttgtgg tggttgtggt gg 32
<210> 15
<211> 32
<212> DNA
<213> 人工序列
<220>
<223> 适体序列
<400> 15
tttggtggtg gtggttgtgg tggtggtggt tt 32
<210> 16
<211> 28
<212> DNA
<213> 人工序列
<220>
<223> 适体序列
<400> 16
ggtggtggtg ttgtggtggt ggtggttt 28
<210> 17
<211> 28
<212> DNA
<213> 人工序列
<220>
<223> 适体序列
<400> 17
tttggtggtg gtggtgtggt ggtggtgg 28
<210> 18
<211> 10
<212> DNA
<213> 人工序列
<220>
<223> 适体序列
<400> 18
tggtggtggt 10
<210> 19
<211> 35
<212> DNA
<213> 人工序列
<220>
<223> 适体序列
<400> 19
tcgagaaaaa ctctcctctc cttccttcct ctcca 35
<210> 20
<211> 24
<212> DNA
<213> 人工序列
<220>
<223> 适体序列
<400> 20
ttagggttag ggttagggtt aggg 24
<210> 21
<211> 26
<212> DNA
<213> 人工序列
<220>
<223> 适体序列
<400> 21
gactgtaccg aggtgcaagt actcta 26
<210> 22
<211> 15
<212> DNA
<213> 人工序列
<220>
<223> 适体序列
<400> 22
ggttggtgtg gttgg 15
<210> 23
<211> 12
<212> DNA
<213> 人工序列
<220>
<223> 适体序列
<400> 23
ggttggtgtg gt 12
<210> 24
<211> 26
<212> DNA
<213> 人工序列
<220>
<223> 适体序列
<400> 24
cgcctaggtt gggtagggtg gtggcg 26
<210> 25
<211> 26
<212> DNA
<213> 人工序列
<220>
<223> 适体序列
<400> 25
gcggtggtgg gatgggttgg atccgc 26
<210> 26
<211> 21
<212> DNA
<213> 人工序列
<220>
<223> 适体序列
<400> 26
gggtcgggat ctagggtcag g 21
<210> 27
<211> 18
<212> DNA
<213> 人工序列
<220>
<223> 适体序列
<400> 27
ggtgggtcgg tagggttt 18
<210> 28
<211> 18
<212> DNA
<213> 人工序列
<220>
<223> 适体序列
<400> 28
ttggctggat cggacggt 18
<210> 29
<211> 18
<212> DNA
<213> 人工序列
<220>
<223> 适体序列
<400> 29
ggtcgggttc ggtggtta 18
<210> 30
<211> 29
<212> DNA
<213> 人工序列
<220>
<223> 适体序列
<400> 30
gggatcggtt cggtaggtgg gtgggttgg 29
<210> 31
<211> 15
<212> DNA
<213> 人工序列
<220>
<223> 适体序列
<400> 31
ggccggcgcg gccgg 15
<210> 32
<211> 15
<212> DNA
<213> 人工序列
<220>
<223> 适体序列
<400> 32
ggaaggatcg gaagg 15
<210> 33
<211> 15
<212> DNA
<213> 人工序列
<220>
<223> 适体序列
<400> 33
ggtaggctcg gtagg 15
<210> 34
<211> 15
<212> DNA
<213> 人工序列
<220>
<223> 适体序列
<400> 34
ggatggttag gatgg 15
<210> 35
<211> 43
<212> DNA
<213> 人工序列
<220>
<223> 适体序列
<400> 35
ccgtcggtcc gttcggtatt tttttctggg tggctgagga tcg 43
<210> 36
<211> 43
<212> DNA
<213> 人工序列
<220>
<223> 适体序列
<400> 36
gggttggtcc gttgggtatt tttttatggg ttgcctggtt ggg 43
<210> 37
<211> 47
<212> DNA
<213> 人工序列
<220>
<223> 适体序列
<400> 37
tcccatcggg tagggttatt tgggttctgg gtggctgagg atcgatc 47
<210> 38
<211> 10
<212> DNA
<213> 人工序列
<220>
<223> 适体序列
<400> 38
tggcggtggt 10
<210> 39
<211> 10
<212> DNA
<213> 人工序列
<220>
<223> 适体序列
<400> 39
tggaggtgga 10
<210> 40
<211> 10
<212> DNA
<213> 人工序列
<220>
<223> 适体序列
<400> 40
aggtggtgga 10
<210> 41
<211> 10
<212> DNA
<213> 人工序列
<220>
<223> 适体序列
<400> 41
aggtggcgga 10
<210> 42
<211> 26
<212> DNA
<213> 人工序列
<220>
<223> 适体序列
<400> 42
gtggtggtgg tgttggtggt ggtggg 26
<210> 43
<211> 29
<212> DNA
<213> 人工序列
<220>
<223> 适体序列
<400> 43
tgggttgggt tgttgttgtt gggttgggt 29
<210> 44
<211> 41
<212> DNA
<213> 人工序列
<220>
<223> 适体序列
<400> 44
ggtggtggtg gtggttggtt tttggttggt ggtggtggtg g 41
<210> 45
<211> 41
<212> DNA
<213> 人工序列
<220>
<223> 适体序列
<400> 45
ctggggttgg gtttggtttt gttttggttt gggttggggt c 41
<210> 46
<211> 35
<212> DNA
<213> 人工序列
<220>
<223> 对照序列
<400> 46
acctctcctt ccttcctctc ctctcaaaaa gagct 35
<210> 47
<211> 29
<212> DNA
<213> 人工序列
<220>
<223> 对照序列
<400> 47
tcccatctat tatttttctt ctaatcatc 29
<210> 48
<211> 28
<212> DNA
<213> 人工序列
<220>
<223> 对照序列
<400> 48
atctcatgaa cgtaaagcca ttcaaacg 28
<210> 49
<211> 20
<212> DNA
<213> 人工序列
<220>
<223> 对照序列
<400> 49
acactagtag ccacactgag 20
<210> 50
<211> 13
<212> DNA
<213> 人工序列
<220>
<223> 对照序列
<400> 50
cctgccccct aaa 13
- 还没有人留言评论。精彩留言会获得点赞!